
MoE-Lightning 解读:如何在显存受限 GPU 上实现高吞吐 MoE 推理?
MoE-Lightning的 发现的问题 是,在资源受限(即显存无法容纳完整模型权重)的平台上部署大型混合专家(MoE)模型时,现有的卸载(Offloading)系统由于未能有效重叠计算任务与CPU-GPU之间的大量数据传输,导致I/O利用率低下且流水线中存在大量气泡,从而使得推理吞吐量严重不足。MoE-Lightning的 核心观点 是:通过一种细粒度的管道调度策略来最大化计算与I/O的重叠,并

MoE-Lightning 解读:如何在显存受限 GPU 上实现高吞吐 MoE 推理?
本文介绍 UC Berkeley 团队的 Shiyi Cao 等人在ASPLOS (2025) 上发表的论文,该论文提出了 MoE-Lightning,这是一个针对显存受限场景下的高吞吐量MoE模型推理系统。
MoE-Lightning的 发现的问题 是,在资源受限(即显存无法容纳完整模型权重)的平台上部署大型混合专家(MoE)模型时,现有的卸载(Offloading)系统由于未能有效重叠计算任务与CPU-GPU之间的大量数据传输,导致I/O利用率低下且流水线中存在大量气泡,从而使得推理吞吐量严重不足。
MoE-Lightning的 核心观点 是:通过一种细粒度的管道调度策略来最大化计算与I/O的重叠,并引入分层性能模型来精确识别异构硬件中的性能瓶颈,可以在显存受限的情况下显著提升MoE模型的推理吞吐量。
MoE-Lightning的 具体设计 是:
-
CGOPIPE:一种新颖的CPU-GPU-I/O管道调度策略,结合了权重分页(paged weights)技术,有效地交错并重叠了GPU计算、CPU计算和各类I/O传输事件;
-
HRM (Hierarchical Roofline Model):一种基于分层Roofline模型的性能分析工具,用于对异构系统中的计算和内存带宽瓶颈进行精确建模,从而指导系统寻找最优的并行配置和批处理大小。
MoE-Lightning的 测试体现 :在单张T4 GPU(16GB)上运行Mixtral 8x7B模型时,MoE-Lightning的吞吐量比现有的SOTA卸载系统(如FlexGen、DeepSpeed)高出 10.3倍 ;在多GPU张量并行设置下,展现出了超线性的扩展性能。
MoE-Lightning的 局限性 是:
-
目前主要关注单节点内的多GPU环境,未考虑跨节点的分布式推理通信开销;
-
系统假设CPU内存足够容纳整个模型,暂不支持磁盘卸载(Disk Offloading);
-
尚未支持除NVIDIA GPU之外的其他加速器(如TPU,NPU)。
背景与动机
MoE模型推理的内存困境
混合专家模型(MoE)通过稀疏激活技术(即每次推理仅激活一小部分专家网络),能够在不显著增加计算量(FLOPs)的前提下极大提升模型容量和性能。然而,MoE模型的参数总量通常非常巨大(例如Mixtral 8x22B需要超过256GB内存),这远超单张甚至多张主流消费级GPU的显存容量。因此,对于没有高端GPU集群的用户来说,部署这些模型必须依赖将权重存储在CPU内存中并按需加载的卸载技术。
已有算法存在的挑战
为了在显存受限的设备上运行大模型,现有的卸载系统(如FlexGen, DeepSpeed Zero-Inference)虽然能够运行模型,但面临严重的效率问题:
-
流水线调度低效:现有方法通常按层加载权重,导致GPU在等待巨大的权重传输时处于空闲状态,或者CPU在等待GPU的中间结果。
-
资源利用不平衡:未能充分利用CPU的计算能力(如将Attention计算卸载到CPU),且未能根据不同的工作负载(如Prompt长度、生成长度)动态调整资源瓶颈。
-
I/O阻塞:MoE模型在解码阶段需要频繁加载不同的专家权重,简单的数据传输策略会造成I/O通道拥堵,阻碍了计算流水线的连续性。
设计与实现

CGOPIPE:CPU-GPU-I/O 管道调度
这是MoE-Lightning的核心设计。为了解决MoE推理中
权重传输量大且频繁的问题,CGOPIPE提出了一种细粒度的流水线策略:
-
权重分页 (Weights Paging):将巨大的权重数据切分为多个“页面”进行传输。系统利用这一机制,在传输下一层权重的间隙,穿插传输当前层所需的中间激活值(如Hidden States),从而消除了I/O阻塞,最大化带宽利用率。
-
CPU Attention:利用HRM分析发现,在解码阶段,Attention操作是内存密集型而非计算密集型,且涉及大量的KV缓存读写。CGOPIPE将Attention计算卸载到CPU上执行,避免了将巨大的KV缓存搬运到GPU,从而节省了宝贵的GPU显存用于存储权重或进行高密度的FFN计算。【主要是因为KV Cache由于显存不够,已经全部卸载到CPU上了】
-
全异步重叠:GPU在处理当前微批次(Micro-batch)的MoE FFN层时,CPU并行处理下一批次的Attention,同时DMA控制器在后台预取下一层的权重,实现了计算、逻辑处理和数据传输的三重重叠。
分层Roofline模型 (HRM)
为了找到最优的系统配置,论文扩展了经典的Roofline模型,提出了HRM。
-
多级存储建模:HRM不仅考虑了GPU和CPU各自的计算峰值和内存带宽,还显式建模了CPU到GPU的互连带宽(PCIe)。
-
瓶颈识别:HRM定义了多个“转折点”(Turning Points),用于判断在特定的算术强度(Operational Intensity)下,系统是受限于本地内存带宽、跨设备带宽还是计算能力。
-
策略搜索:基于HRM,系统 构建了一个性能模型,能够在给定的硬件和模型配置下,自动搜索出最优的批处理大小(Batch Size)、微批处理大小以及静态驻留GPU权重的比例,以达到吞吐量最大化。
动态请求批处理
针对真实场景中请求长度不一的问题,MoE-Lightning还设计了一种动态批处理算法。该算法根据输入长度对请求进行排序,并将长请求分配给当前token数最少的微批次,从而保证每个微批次的计算负载均衡,防止因个别长序列导致的流水线等待。
实验结果
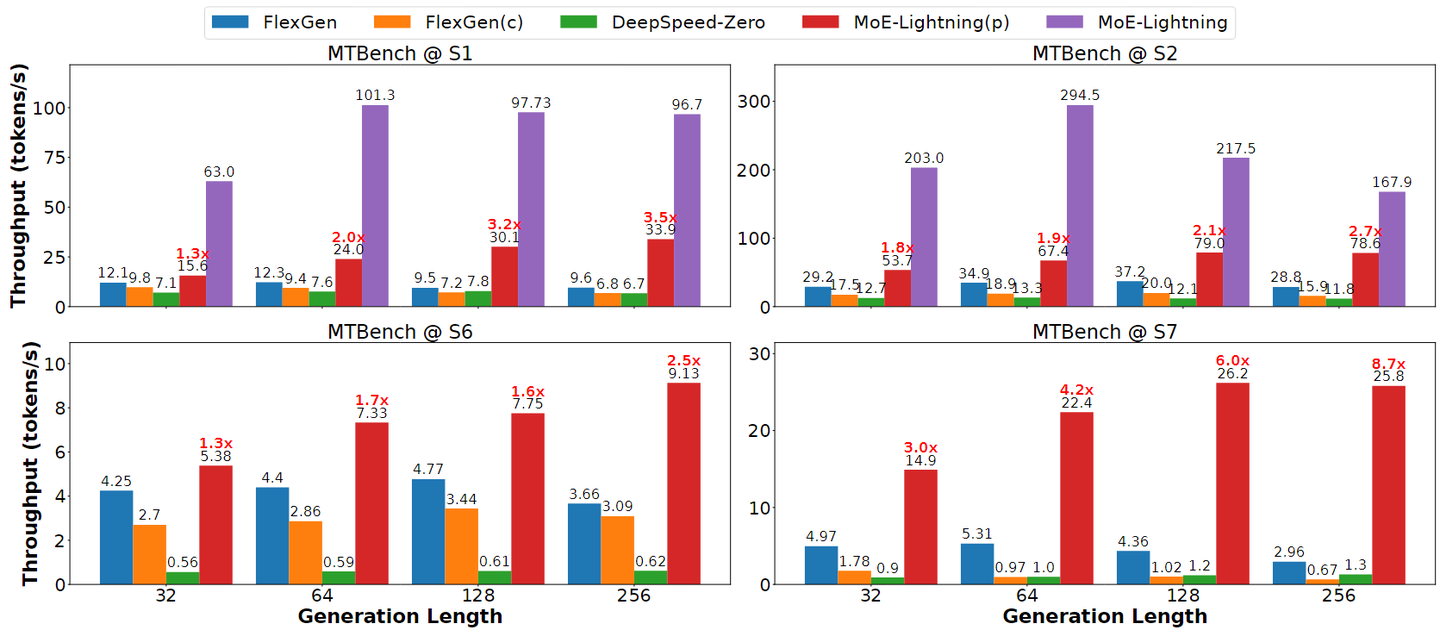
实验主要评估了MoE-Lightning在不同硬件设置(如单卡T4、单卡L4、多卡T4)和不同MoE模型(Mixtral 8x7B, Mixtral 8x22B, DBRX)下的表现。
单卡性能显著提升:
实验结果表明,MoE-Lightning在资源最受限的单卡场景下优势最大。在单张T4 GPU(16GB显存)上运行Mixtral 8x7B时,MoE-Lightning的吞吐量达到了FlexGen的 10.3倍。这主要归功于CGOPIPE策略有效地利用了CPU进行Attention计算,并极致地重叠了权重传输时间,使得GPU几乎一直处于计算状态。
多卡超线性扩展:
在多GPU张量并行(Tensor Parallelism)实验中,MoE-Lightning展现了优异的扩展性。对于巨大的Mixtral 8x22B模型,当从2张T4扩展到4张T4时,吞吐量提升了约 2.77到3.38倍,实现了超线性加速。这是因为随着GPU数量增加,总显存容量增加,系统可以缓存更多权重在GPU上,从而大幅减少了通过PCIe传输权重的需求,突破了I/O瓶颈。
Future
加入我们的学术社区


点亮创新之光 照亮科研梦想
如果您希望持续获取最新的期刊动态、会议信息、论文写作与投稿技巧,我们诚挚邀请您加入烁智研学社区。

关注“烁智研学”公众号回复“CCF期刊微信群”

扫左侧二维码码加入“CCF期刊QQ交流群”
这是一个致力于共同成长、资源共享的科研平台。我们期待您的到来,一起在科研道路上走得更远、更稳!^o^y

中科创新烁智(CSCITech)
更多推荐



 8
8 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)