
Anthropic 再放大招:Claude Opus 4.5 如何定义下一代 AI 智能体?
Claude Opus 4.5 是 Anthropic 推出的最新大型语言模型,作为 Opus 4 的继任者,它是 Anthropic 当前最强大的模型,专为编码、复杂推理和长时间任务而优化。根据 Anthropic 的数据,在中等开发难度下,Opus 4.5 的 SWE-bench 得分与 Sonnet 4.5 持平,但输出令牌数量却减少了 76%。Opus 4.5 明白我的问题存在循环论证——

Anthropic 最新推出的 Claude Opus 4.5,被官方称为“目前全球最强的编码、智能体和计算机操作模型”。就在 Google 刚刚发布惊艳业界的 Gemini 3 后不久,Anthropic 紧随其后,推出了这款重磅升级。
尽管 Gemini 3 在多项基准测试中表现极为出色,但在软件工程能力测试(SWE Bench)上,它仍略逊于 Anthropic 此前发布的 Sonnet 4.5。而如今,Claude Opus 4.5 不仅超越了自家 Sonnet 4.5 的成绩,还在多个关键指标上创下新高。
这已是 Anthropic 在短短两个月内推出的第三款大模型——继 Sonnet 4.5 和 Haiku 4.5 之后,Opus 4.5 再次刷新上限。随着公司估值突破 3500 亿美元,Anthropic 显然拥有持续高速迭代的雄厚资源。
本文将全面解析 Claude Opus 4.5 的最新特性,包括性能基准、新增功能,并通过实际测试验证其真实能力。

什么是 Claude Opus 4.5?
Claude Opus 4.5 是 Anthropic 推出的最新大型语言模型,作为 Opus 4 的继任者,它是 Anthropic 当前最强大的模型,专为编码、复杂推理和长时间任务而优化。该模型在 SWE-bench 上取得 80.9% 的得分,在 Terminal-bench 上达到 59.3%。
目前,Claude Opus 4.5 已上线 Anthropic 官方应用、API 接口,并支持主流云平台调用。
Claude Opus 4.5 有哪些新特性?
根据官方公告,以下几点尤为亮眼:
-
智能体编码:Opus 4.5 在 SWE-bench Verified 基准上表现卓越,超越 Google 的 Gemini 3 Pro 和 OpenAI 的 GPT-5.1。Anthropic 还将其用于一道面向高性能工程师候选人的“带回家考试题”,结果得分甚至超过了所有人类应试者的历史最高分。
-
计算机操作能力:Anthropic 宣称 Opus 4.5 是“全球最适合操作计算机的模型”——它能像人类一样与软件界面交互,点击按钮、填写表单、跨网站导航,完成真实任务。
-
日常办公增强:模型在处理电子表格、制作幻灯片以及深度研究方面“显著优于以往版本”。
与此同时,Anthropic 还同步发布了多项产品更新,包括 Claude for Chrome(浏览器插件,支持跨标签页执行操作)和 Claude for Excel(电子表格自动化工具),下文将详细介绍。
实测 Claude Opus 4.5
光看宣传不够,还得动手试试。下面我从几个维度对 Opus 4.5 进行了实测。
01
经济学优化问题测试?
我首先抛出一个经典的经济学优化问题:假设需求函数为对数线性形式,如何根据价格预测销量,并求出利润最大化的价格?
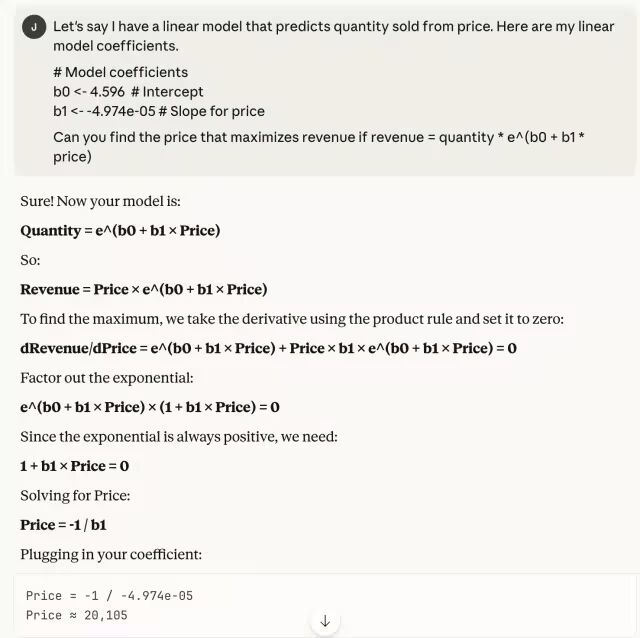
Opus 4.5 几乎瞬间给出了正确答案,而且完整展示了推导过程——包括求导、因式分解和代数运算。如果中间出错,我也能迅速定位问题所在。
这种能力对企业极具价值:许多公司掌握价格与销量数据,却未必有资源解决基础优化问题。而借助精心设计的提示词,Opus 4.5 能轻松补足这一缺口。
当然,最终是否采纳结果,仍需分析师判断模型是否充分考虑了现实约束。
02
统计学问题测试
接下来,我想用 Opus 4.5 处理一个统计问题。我创建了一个数据集,其中yield包含一个函数temperature,并添加了噪声。

然后我把这个提示告诉了Claude

Claude 向我返回了以下内容,我用它创建了下面的直方图。
printf("hello world!");# Fit model
fit <- lm(yield ~ temperature, data = df)
fitted_vals <- fitted(fit)
resids <- residuals(fit)
original_slope <- coef(fit)[2]
# Residual bootstrapset.seed(123)n_boot <- 1000boot_slopes <- numeric(n_boot)
for (i in 1:n_boot) { new_y <- fitted_vals + sample(resids, replace = TRUE) boot_fit <- lm(new_y ~ df$temperature) boot_slopes[i] <- coef(boot_fit)[2]}
# Confidence intervalsci_lower <- quantile(boot_slopes, 0.025)ci_upper <- quantile(boot_slopes, 0.975)
# Plotggplot(data.frame(slope = boot_slopes), aes(x = slope)) + geom_histogram(bins = 40, fill = "gray70", color = "white") + geom_vline(xintercept = original_slope, color = "red", linewidth = 1) + geom_vline(xintercept = ci_lower, color = "steelblue", linetype = "dashed", linewidth = 1) + geom_vline(xintercept = ci_upper, color = "steelblue", linetype = "dashed", linewidth = 1) + labs( title = "Bootstrap Estimate: Effect of Temperature on Yield", subtitle = paste0("Estimate: ", round(original_slope, 3), " | 95% CI: [", round(ci_lower, 3), ", ", round(ci_upper, 3), "]"), x = "Slope (yield per °C)", y = "Count" ) + theme_minimal()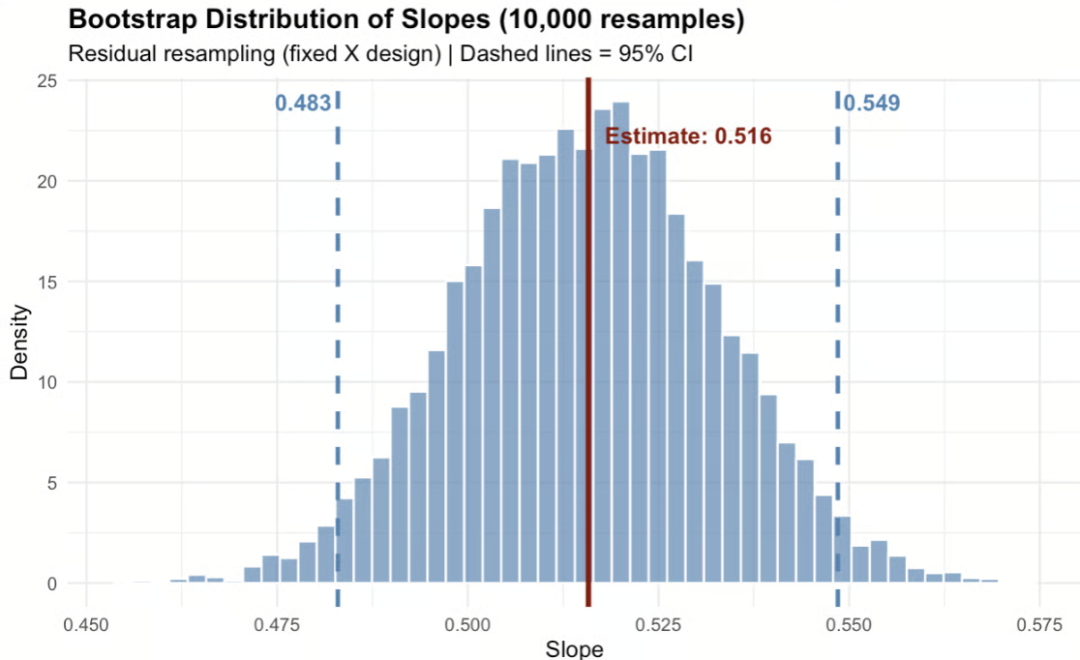
这个结果令人印象深刻:它没有简单地使用普通最小二乘法,而是选择了更适合固定设计(fixed design)场景的残差自助法——这说明模型真正理解了我提示中的细微条件。当 X(温度)是人为设定而非随机变量时,残差自助法能提供更准确的条件推断。
03
数学逻辑陷阱测试
接下来,我想看看我能否以某种方式让 Opus 4.5 出点问题。

在这种情况下,模型的理解远远领先于我。Opus 4.5 明白我的问题存在循环论证——我用 Y 定义 X,反之亦然,因此,鉴于我们目前掌握的数据,我们无法对回归线的斜率进行有意义的估计。

04
SQL 查询优化测试
最后,我丢给它一段功能正确但效率极低的 SQL:
-- Find customers who placed orders above their average order value in 2024
SELECT
c.customer_id,
c.customer_name,
o.order_id,
o.order_date,
o.order_total
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_date >= '2024-01-01'
AND o.order_date < '2025-01-01'
AND o.order_total > (
SELECT AVG(o2.order_total)
FROM orders o2
WHERE o2.customer_id = c.customer_id
)
AND c.customer_id IN (
SELECT DISTINCT o3.customer_id
FROM orders o3
WHERE o3.order_date >= '2024-01-01'
)
AND EXISTS (
SELECT 1
FROM customer_preferences cp
WHERE cp.customer_id = c.customer_id
AND cp.email_opt_in = 1
)
ORDER BY (
SELECT COUNT(*)
FROM orders o4
WHERE o4.customer_id = c.customer_id
) DESC;我让 Opus 4.5 优化查询语句,它大约一秒钟就给了我答案。
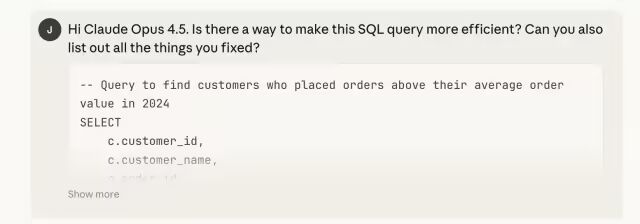
-- Find customers who placed orders above their average order value in 2024
WITH customer_avg AS(
SELECT
customer_id,
AVG(order_total) AS avg_order_total,
COUNT(*) AS order_count
FROM orders
GROUP BY customer_id
)
SELECT
c.customer_id,
c.customer_name,
o.order_id,
o.order_date,
o.order_total
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN customer_avg ca ON c.customer_id = ca.customer_id
JOIN customer_preferences cp ON c.customer_id = cp.customer_id
WHERE o.order_date >= '2024-01-01'
AND o.order_date < '2025-01-01'
AND o.order_total > ca.avg_order_total
AND cp.email_opt_in = 1
ORDER BY ca.order_count DESC;优化点包括:
-
用 CTE 替代相关子查询,避免重复计算平均值;
-
删除冗余的 IN (SELECT DISTINCT ...) 子句;
-
将 EXISTS 改为 JOIN,提升执行效率。
Claude Opus 4.5 的智能体与代理能力
Anthropic 最新发布的产品还有其他亮点。让我们来详细了解一下:
01
开发者平台功能?
Anthropic 为开发者新增了几个构建模块。其中最值得注意的是“努力程度”参数,它允许您控制模型在做出响应前需要思考多少。对于快速、轻量级的任务,请将其设置得较低;当您需要模型深入思考时,请将其设置得较高。
根据 Anthropic 的数据,在中等开发难度下,Opus 4.5 的 SWE-bench 得分与 Sonnet 4.5 持平,但输出令牌数量却减少了 76%。在高开发难度下,Opus 4.5 的得分比 Sonnet 4.5 高出 4% 以上,而令牌数量仍然只有 Sonnet 的一半左右。
此外,上下文管理和内存也得到了改进。对于长时间运行的智能体,Claude 现在可以自动总结之前的上下文,避免在执行任务过程中遇到瓶颈。这与上下文压缩技术相结合,使智能体能够在更少干预的情况下运行更长时间。
最后,Opus 4.5 在多智能体编排方面显然相当出色,这意味着它可以管理一个子智能体团队。
02
深度研究能力实测
显然,Opus 4.5 在深入研究评估中的表现提高了约 15%。
我亲自测试了它的深度检索能力。我让它生成一份报告,内容是关于如今仍然存在但并不常用的古英语词汇,以及这类词汇随时间推移发生的变化。报告在七分钟内就生成了:
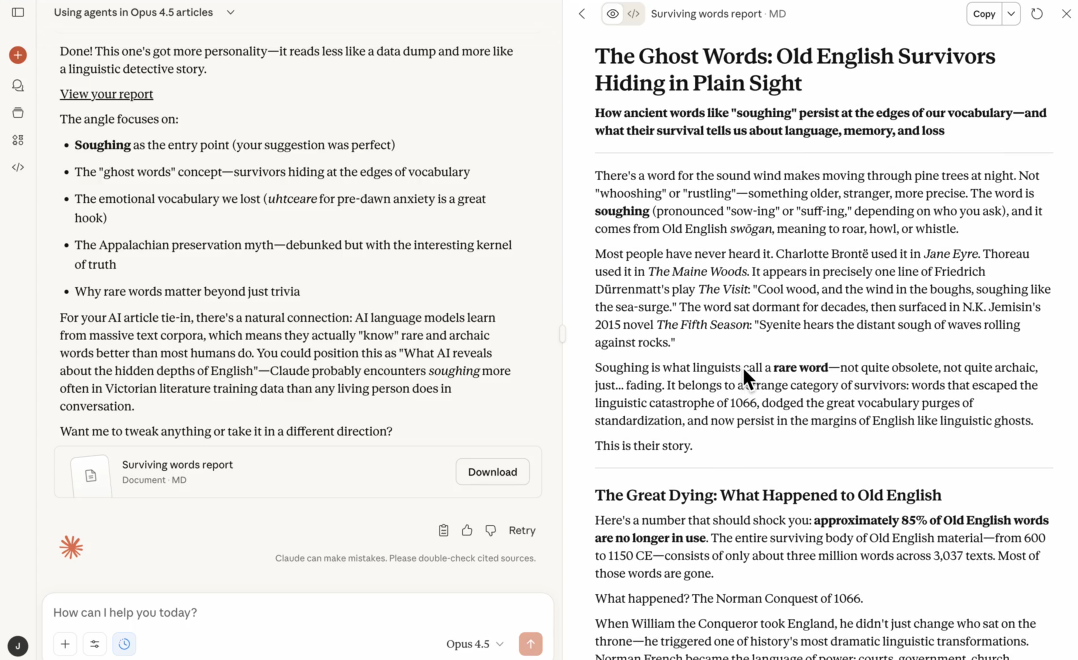
这份报告的质量着实让我印象深刻,无论是内容的趣味性、写作水平、组织结构还是研究深度都让我非常满意。
03
Claude Code 升级
Anthropic 已向Claude Code发送了两个升级。
-
规划模式:执行前先生成详细计划,并输出可编辑的 plan.md 文件供用户确认,避免“跑偏”。
-
桌面端集成:现在可在桌面应用中同时运行多个本地/远程会话,实现多任务并行。
04
面向消费者的智能体功能
部分智能体能力已落地消费级应用:
-
Claude for Chrome:面向所有 Max 用户开放,可跨标签页自动浏览、点击、填表、抓取信息。
-
Claude for Excel:电子表格自动化工具,现已向 Max、Team 和企业用户全面开放 Beta。
-
长对话优化:过去长聊到一定长度就会截断,现在模型会自动后台摘要历史内容,释放上下文空间,让对话无限延续。
Claude Opus 4.5 基准测试结果
与之前的 Claude 模型一样,Opus 4.5 也根据智能体编码、工具使用、计算机使用和问题解决等方面的常用基准进行了测试。以下是 Opus 4.5 的主要测试结果。
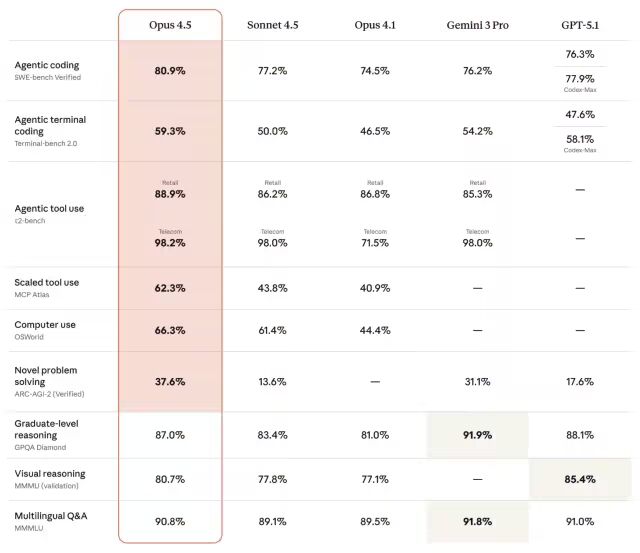
Opus 4.5 在许多最重要的测试中都名列前茅。这些测试涵盖了所有实际操作环节,例如编写能够通过测试的代码(SWE-bench)、在多步骤工作流程中使用工具(τ2-bench、MCP Atlas)以及操作计算机(OSWorld)。Opus 4.5 在这些测试中往往遥遥领先。
工具使用率的差距实际上非常大:62.3% 对比 43.8% 的排名第二的模型(也是 Claude!)。然而,这表明 Anthropic 公司在提升其性能方面投入了多少资源,尤其是在智能体任务方面。尽管他们之前的模型目前在某些类别中可能领先,但他们并没有放慢前进的步伐。
看起来 Gemini 3 Pro 在一些知识密集型基准测试中更胜一筹,例如研究生水平推理测试(GPQA Diamond)和多语言问答测试(MMMLU)。这些基准测试可能更注重训练数据的广度和严谨的推理,而非死记硬背,而谷歌当然拥有丰富的资源。
结语
Claude Opus 4.5 清晰传递了 Anthropic 的战略方向:当 Google 聚焦多模态与端侧模型时,Anthropic 选择全力押注“行动力”——智能编码、工具调用、计算机操作。
基准数据已经说明一切:Opus 4.5 创下软件工程测试的历史最高分,能自主完成跨系统调试,几乎无需人工干预。
我的实测也印证了这一点:无论是执行统计模拟,还是整合多篇文献产出研究报告,Opus 4.5 都展现出类人的适应性与清晰的推理链条。如果你希望 AI 真正融入工作流、成为生产力伙伴,这才是关键。


中科创新烁智(CSCITech)
更多推荐



 9
9 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)