
你用错了 GPT-5!教你如何领先 99% 的用户
大多数用户并未充分挖掘 GPT-5 的潜力!
为什么?因为要充分利用 GPT-5,需要熟悉提示技术和参数设置,以最大限度地提高其输出质量。
我们花了大量时间研究 OpenAI 的 GPT-5 提示指南,以便更好地了解如何通过 ChatGPT Web 应用和 OpenAI Playground 充分利用该模型。在本指南中,我们将用通俗易懂的语言解释 OpenAI 的提示建议,避免使用官方指南中的大部分技术术语。

一、优化指令跟随
GPT-5 能够非常精确地遵循指令,这在大多数情况下都是有利的,但如果您的提示不清楚或包含相互矛盾的指令,模型可能会感到困惑或浪费时间试图协调冲突。
例如,不要说“简要概述”,然后在同一个提示中说“包括所有细节”。
为什么这是错的?相互冲突的指令会破坏响应,因为模型不知道该优先处理哪个指令。这里的提示技巧是,务必仔细检查你的提示,看看是否有任何混淆的信息。删除或澄清任何可能被多种解读的内容。
OpenAI 表示,消除提示中的歧义和矛盾之处可显著提高 GPT-5 的性能。
您可以使用 ChatGPT 查找提示中的冲突:
“审阅我的说明。指出任何冲突。建议进行细微修改,使说明保持一致”
或者,您可以使用 OpenAI 的提示优化器来检查您的提示。我们将在下一点详细介绍。
二、使用 OpenAI 的提示优化器
OpenAI 在 Playground 中提供了一个GPT-5 提示优化器。Playground 是一个专为高级用户设计的平台,用户可以在其中选择不同的模型、调整模型参数等等(事实上,我们将使用技巧 #3 中的 Playground)。
我们可以在 Playground 中发现的一个很酷的东西是提示优化器。
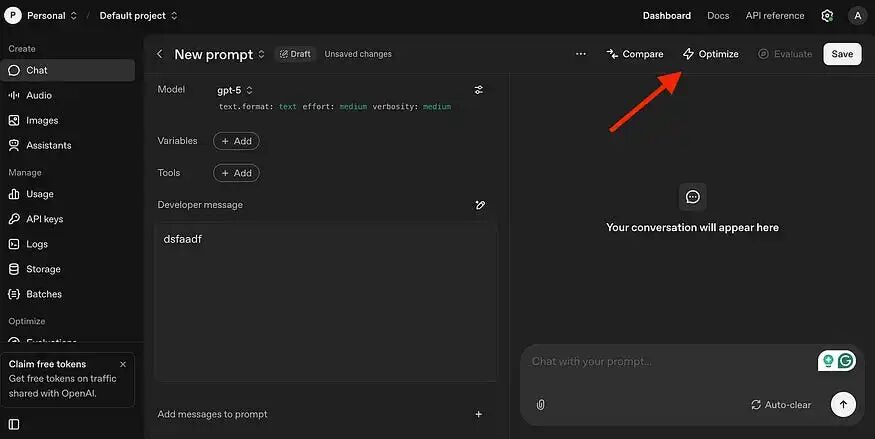
要使用提示优化器,请使用您的 ChatGPT 帐户登录。然后输入或粘贴您的提示,并点击“优化”以获取反馈。提示优化完成后,该工具将以蓝色突出显示更改,右侧的注释图标将显示这些更改背后的原因。
该工具很有用,但仍然需要学习本指南中的其他提示,以了解它所做的更改并识别何时需要进行这些更改。
从现在开始,这些提示可以通过 API 或 OpenAI Playground应用。Playground 不需要任何编码知识,我强烈建议您在 ChatGPT Web 应用程序不够用,并且需要对 GPT-5 进行更多控制时使用它。
三、控制推理力度
GPT-5 有一个 reasoning_effort 参数,用于控制模型的思考强度以及调用工具的意愿。默认值为“中等”,但您可以根据任务的难度进行调整。
要控制推理力度,请点击Playground中的设置调整图标。
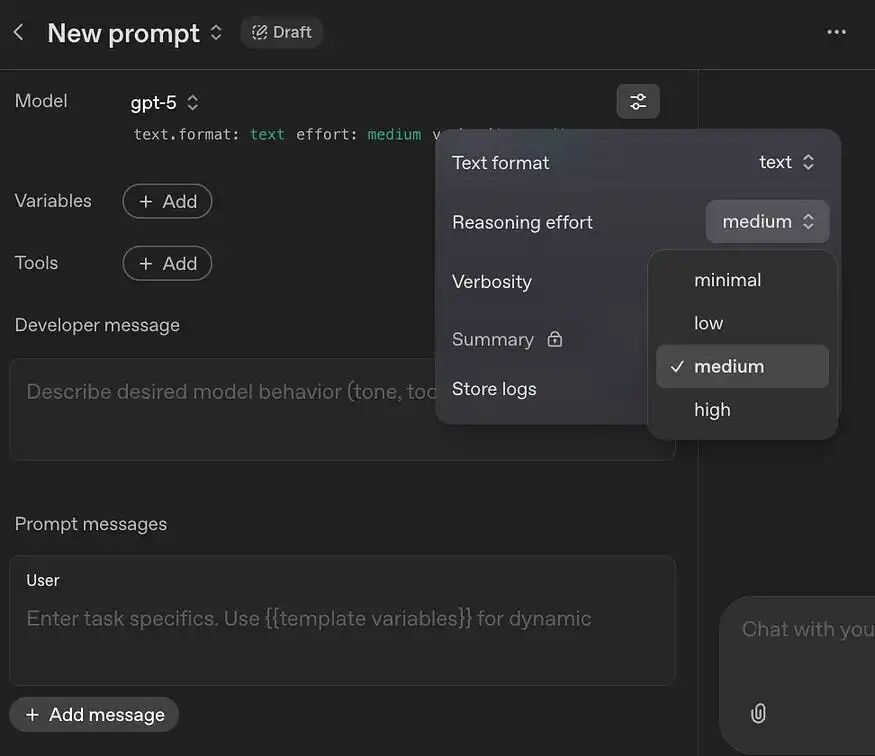
推理力度(Reasoning Effort)的 4 个级别:
1.最小(minimal):此级别在 GPT-5 中引入,它指示模型以尽可能少的思考来给出答案。它旨在追求快速响应,非常适合确定性的、轻量级的任务(例如信息提取、格式调整、简短重写、简单分类)。
2.低(low):此级别会进行稍多的思考,但仍然高度优先考虑效率。对于需要一定理解但不需要深度、创造性解决问题的任务来说很可靠。适用于标准的客户支持、内容摘要等场景。
3.中(medium):这是默认设置。它在性能和速度之间提供平衡。在此级别上,AI 真正开始“思考”。答案会更全面、更具创造性且结构更佳。适用于内容创作、代码生成、分析和复杂指令遵循。
4.高(high):此级别指示 GPT-5 花费其所需的所有时间,并在给出答案前使用必要数量的推理令牌(token)。非常适合那些准确性至关重要的任务,例如科学和学术研究、战略规划以及调试复杂代码。它的响应速度可能较慢且成本较高。
请注意:与更高的推理级别相比,最小推理力度下的输出质量可能会更显著地因提示词(prompt)的不同而波动。
OpenAI 的建议:当将 GPT-5 设置为最小推理力度时,建议让其先概述解决方法。例如,您可以说:“首先,列出你解决问题将采取的步骤。”即使在回答开头有一个单句计划或几个要点的策略,也能改善那些需要更高智能水平的任务的表现。
四、控制代理渴望
通过控制 reasoning_effort(推理力度),我们也可以校准 GPT-5 的“智能体积极性”(agentic eagerness),即模型是更主动还是更被动。
更高的积极性(More eagerness):这会鼓励模型自主决策,减少澄清性问题或将控制权交还给用户的次数。为了获得更高的积极性,你需要增加 reasoning_effort 并使用鼓励持久性和彻底完成任务的提示语。以下是一个来自 OpenAI 指南的提示词示例,用于获取更高的积极性:
•你是一个代理 — 请继续工作,直到用户的查询完全解决,然后再结束你的回合并将控制权交还给用户。
•只有当你确定问题已经解决时,才终止你的回合。
•当遇到不确定性时,绝不停止或交还给用户 — 研究或推断出最合理的方法并继续。
•不要要求人类确认或澄清假设,因为你之后总能进行调整 — 决定最合理的假设是什么,继续执行,并在你完成行动后记录下来以供用户参考。
更低的积极性(Less eagerness):默认情况下,GPT-5 会相当彻底地尝试收集上下文以确保答案正确。你可以通过切换到较低的 reasoning_effort 并在提示中明确定义模型探索问题空间的标准,来缩小其行为范围并获得更快速、更精准的响应。
以下是一些你可以添加到提示中的指令,用以减少上下文收集行为(完整指令参见此处):
•避免为上下文进行过度搜索。
•如果你认为需要更多时间进行调查,请向用户更新你的最新发现和未解问题。如果用户确认,你可以继续。
•强烈倾向于尽快提供正确答案,即使它可能不完全正确。
请注意,“即使它可能不完全正确”这句话明确为模型提供了一个“逃生舱口”,使其更容易满足较短的上下文收集步骤。
五、控制代理渴望
OpenAI 在 GPT-5 中引入了一个名为 verbosity(详细程度)的新 API 参数,该参数会影响模型最终响应的长度。现在,您可以使用 reasoning_effort(推理力度)要求模型进行更多或更少的推理,同时通过 verbosity 独立调整其最终答案的长度。
这有什么用处?
还记得我们在第一点中讨论过的那些相互矛盾的指令吗?现在,在 Playground 上,您不再需要像“请简洁”这样脆弱的提示技巧了,因为您可以通过 verbosity 参数来控制它。
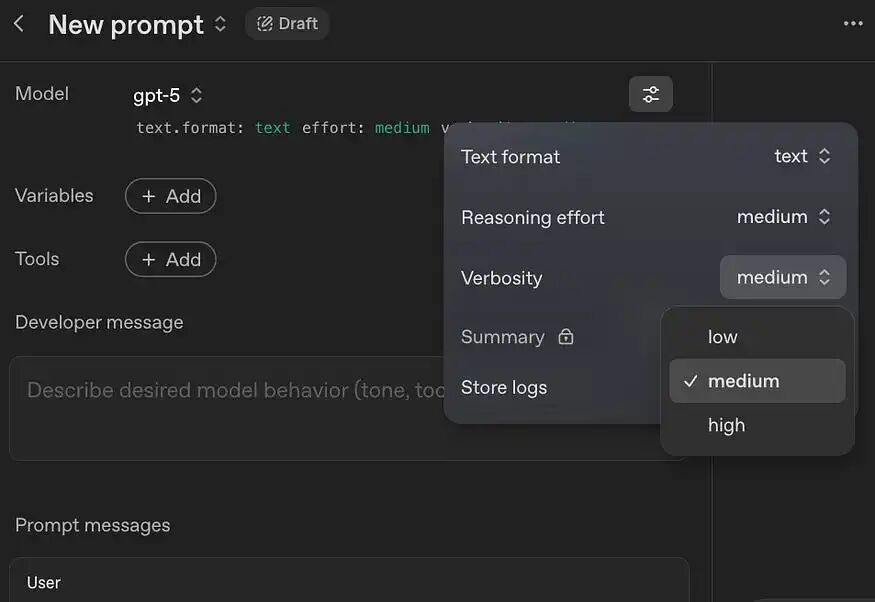
这减少了对模型相互矛盾的指令,并提高了其对实际任务指令的遵循程度。
verbosity 有三个级别:low(低)、medium(中)和 high(高)。
•如果您将 verbosity 设置为“low”,模型的回复会简短、直接且高效。
•设置为“high”则会给出更长、更详细的答案。
以下是一个简单的例子,展示了 3 个详细程度级别的区别:
用户: 法国的首都是哪里?
•模型(低详细程度): 巴黎。
•模型(中等详细程度): 法国的首都是巴黎。
•模型(高详细程度): 法国的首都是巴黎。它是法国最大的城市,也是其政治、文化和经济中心。
探索智能边界 发现无限可能


中科创新烁智(CSCITech)
更多推荐


 5
5 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)