
华为盘古大模型5.5发布:准万亿MoE架构领跑,自适应推理效率提升8倍
在2025年华为开发者大会(HDC 2025)上,华为正式推出盘古大模型5.5版本。延续"产业赋能"定位,此次升级涵盖五大核心模型体系:自然语言处理(NLP)、多模态感知、预测分析、科学计算及计算机视觉(CV),通过架构创新推动行业智能化转型。华为云CEO张平安现场宣布,盘古5.5的NLP能力已对标国际顶级模型,多模态世界模型实现国内首创。

在2025年华为开发者大会(HDC 2025)上,华为正式推出盘古大模型5.5版本。延续"产业赋能"定位,此次升级涵盖五大核心模型体系:自然语言处理(NLP)、多模态感知、预测分析、科学计算及计算机视觉(CV),通过架构创新推动行业智能化转型。华为云CEO张平安现场宣布,盘古5.5的NLP能力已对标国际顶级模型,多模态世界模型实现国内首创。


🚀ALL IN ONE (AIO) 开放接口(API)平台
NLP模型集群:性能与效率双突破
万亿级稀疏架构:盘古Ultra MoE
作为7180亿参数的混合专家模型(MoE),基于昇腾全栈软硬件协同研发,攻克超大规模稀疏模型训练稳定性难题。创新采用Depth-Scaled Sandwich-Norm(DSSN)架构与TinyInit初始化策略,在CloudMatrix384集群完成10+T token稳定训练。通过EP分组负载优化技术均衡专家分配,结合Dropless训练策略,实现高效长序列处理与低幻觉输出。在数学推理、自然科学领域榜单居全球前列,技术细节见arXiv:2505.04519。

高性价比推理引擎:盘古Pro MoE
72B参数规模(激活160亿)的MoE架构,针对昇腾300I Duo芯片优化设计。采用分组混合专家算法(MoGE)解决跨芯片负载不均问题,在SuperCLUE五月榜单千亿级以下模型并列国内第一。实测性能达1529 token/s(昇腾800I A2平台),较业界同规模模型吞吐量提升15%,智能体任务表现媲美DeepSeek-R1(6710亿参数)。开源地址:gitcode.com/ascend-tribe/pangu-pro-moe。
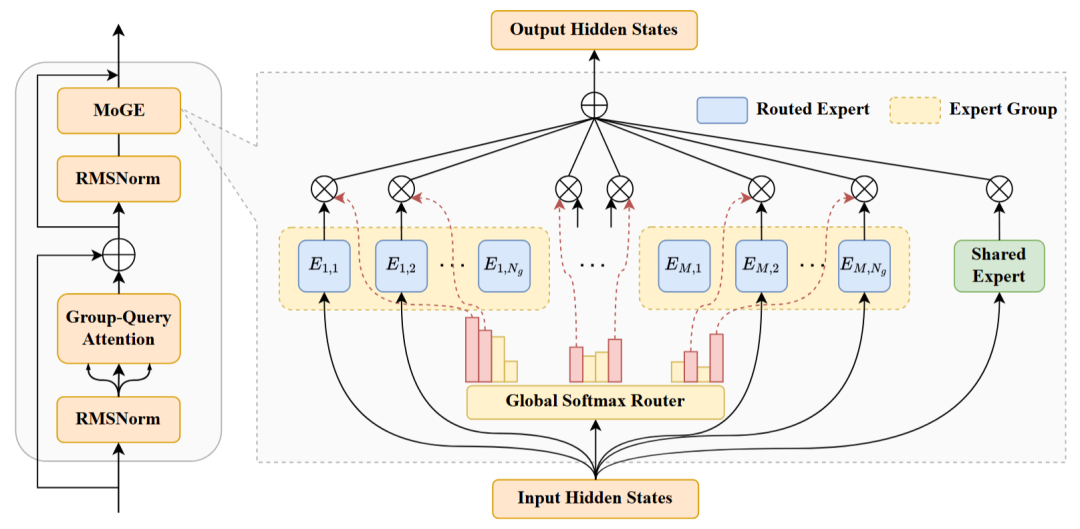
轻量化长文本专家:盘古Embedding
7B小模型通过渐进式SFT与多维强化学习突破能力边界,创新Adaptive SWA滑动窗口与ESA稀疏注意力机制,支持百万级上下文处理。知识边界判定技术显著降低幻觉率,在学科知识、代码生成等场景超越同参数量级模型(技术报告:arXiv:2505.22375)

推理架构革命:自适应思考机制

针对慢思考模型过度计算痛点,首创快慢思考自适应切换技术:
-
构建难度感知数据集,通过两阶段训练实现问题复杂度自动判别
-
简单问题采用快思考模式(平均响应缩短8倍)
-
复杂任务启用慢思考+反思投机/压缩策略,推理时间减少50%
-
对比传统prompt切换方案,实现真正意义上的动态资源调配。
深度研究智能体:DeepDiver突破开放域局限
攻克Agent技术执行效率瓶颈,推出开放域信息获取系统:
-
合成海量交互数据训练,强化学习渐进优化
-
5分钟内完成10跳级复杂检索(如跨平台数据比对)
-
7B模型生成万字专业报告能力比肩DeepSeek-R1
-
在科研分析、行业调研场景实现精准信息提取(技术方案:arXiv:2505.24332)。

垂直领域模型矩阵升级
预测大模型
首创Triplet Transformer架构,统一跨行业三元组编码预训练,提升金融风控、供应链预测精度30%以上(以华为内部物流验证数据为准)。
科学计算大模型
深圳气象局基于此升级"智霁"系统,全球首个AI集合预报平台,通过多模型协同降低单一预报误差,台风路径预测准确率提升18%。
CV大模型
300亿参数视觉MoE架构(当前业界最大):
-
融合红外/激光点云/光谱等多维数据
-
生成式故障样本库解决工业场景数据稀缺问题
-
油气管道检测误报率降至0.3%,煤矿设备识别种类扩展5倍。
多模态世界模型
构建物理数字孪生空间,支持智能驾驶与机器人训练:
-
输入路网数据生成多摄像头视频流+激光雷达点云
-
替代90%实景采集成本,某车企测试周期缩短6个月。
产业落地价值重构
盘古5.5通过MoE稀疏化、Triplet Transformer、自适应推理等创新,在硬件适配(昇腾原生)、能耗控制(推理耗电降低40%)、场景泛化(覆盖30+行业)建立技术代差。据IDC观测,该版本已部署于能源勘探、生物制药等高端产业,推动AI从感知智能向决策智能跃迁。
探索智能边界,发现无限可能!(AIOAGI.TECH)

中科创新烁智(CSCITech)
更多推荐


 22
22 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)