
Claude 4 发布,编程界要变天?最强编程 AI 登场!
在SWE-bench Verified中,该模型对真实世界的编码任务评分为72.7%,略微超过Opus 4(72.5%),并显著领先于Claude 3.7 Sonnet(62.3%)。在SWE-bench Verified中,它的得分为72.5%,而在高计算设置下,这一分数跃升至79.4%——在所有对比模型中最高。与Sonnet 4一样,它支持200K的上下文窗口,因此如果您想将其与大型代码库一起

AIOAGI.TECH
Anthropic 刚刚发布了Claude 4 ,有两个版本:Claude 4 Sonnet 和 Claude 4 Opus。
Claude Sonnet 4是一款通用模型,适用于大多数 AI 用例,尤其擅长编码。我认为它是您可以免费使用的最佳模型之一。
Claude Opus 4专为推理密集型任务而设计,例如代理搜索和长时间运行的代码工作流。Anthropic 称 Opus 4 是“世界上最好的编码模型”,但我觉得这种说法有点空洞。
是的,它目前在 SWE-bench Verified 基准测试中表现最佳。但由于上下文窗口只有 20 万,我无法想象它能流畅地处理非常大的代码库。而且说实话:每个月左右总会有另一个更强大的模型问世。想要在几周内独占鳌头实在不切实际。
话虽如此,Claude 4 仍然是一个非常强大的版本。我将带您了解最重要的细节——功能、用例、基准测试——并且我还会进行一些我自己的测试。

Claude Sonnet 4
Claude Sonnet 4是Claude 4系列中的较小模型。它旨在用于通用目的,在大多数常见的人工智能任务中表现良好,包括编程、写作、回答问题和数据分析。它还对免费用户开放,这使得这一质量模型显得特别易于获取。
该模型支持200K的上下文窗口,这使其能够处理较大的提示,并在长时间交互中保持连续性。这对于分析长篇文档、审查代码库或生成结构一致的多部分响应等用例非常有用。然而,Sonnet 4在处理大型代码库时可能会遇到困难。相比之下,Gemini 2.5 Flash具有1M标记的上下文窗口。
与Claude Sonnet 3.7相比,这个版本在速度上更快,遵循指令的能力更强,并且在代码密集型工作流程中更可靠。它支持最多64K的输出标记,这有助于生成稍长的输出,例如结构化计划、多部分答案或大型代码补全。
早期报告显示,导航错误更少,应用开发任务的性能更好。在复杂推理或长期任务规划方面,它并不如Opus 4强大,但对于大多数工作流程而言,已经绰绰有余。
Claude Opus 4
Claude Opus 4是Claude 4系列中的旗舰模型。它专为需要更深层推理、长期记忆和更结构化输出的任务而构建,适用于代理搜索、大规模代码重构、多步骤问题解决以及扩展的研究工作流程等。
与Sonnet 4一样,它支持200K的上下文窗口,因此如果您想将其与大型代码库一起使用,这可能是一个缺点。相比之下,Gemini 2.5 Pro(谷歌的旗舰模型)具有1M标记的上下文窗口。
它还能够以“扩展思维”模式运行,在这种模式下,它从快速响应切换到较慢、更深思熟虑的推理。这种模式使其能够执行工具使用、跨步骤跟踪记忆,并在需要时生成自身思维过程的摘要。
Anthropic将其定位为面向开发人员、研究人员和构建AI代理的团队的高端模型。它在SWE-bench Verified和Terminal-bench上表现出色,早期用户报告称在代码代理、搜索工作流程以及如重构开源项目或模拟长期规划等多小时任务中表现强劲。
与Sonnet不同,Opus 4仅在付费计划中提供。它的运行成本更高,对于简单的聊天机器人使用而言可能显得过于奢华。但对于需要在许多变化部分之间保持一致推理的应用,它是更有能力的选择。
Testing Claude 4
在测试新模型时,我通常使用相同的任务——这样我可以看到它与我之前测试的其他模型的比较。这并不是要进行全面评估,目标只是了解这些模型在聊天界面中的表现。
让我们在两个领域对Claude 4进行测试:数学和编程。
数学
我喜欢从一个简单的计算开始,这个计算通常会使语言模型感到困惑。这并不是要检查基础的算术——我可以用计算器来完成那项工作。重点在于观察模型如何处理略微棘手的问题,以及在需要时它是否能够依赖工具使用或清晰展示其推理过程。
让我们看看Claude Sonnet 4处理得如何:

如您所见,它在第一次尝试中答错了。但是当我要求它使用工具——计算器时,它通过编写一行JavaScript脚本来响应,并正确解决了这个问题。
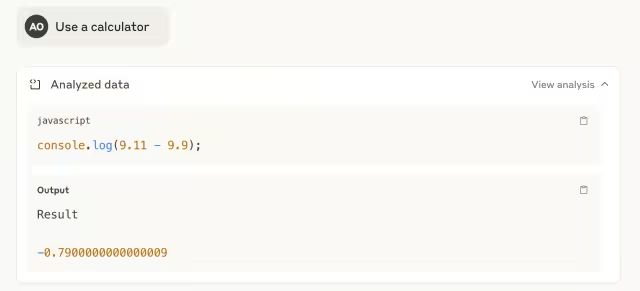
Claude Opus 4在第一次尝试中就正确回答了。
接下来,我想看看Claude Sonnet 4如何处理更复杂的问题:使用0到9的所有数字各一次,构造三个数字x、y、z,使得x + y = z。
经过大约五分钟的随机暴力尝试,我收到了一个消息,提示输出限制已达到,我需要点击“继续”才能恢复。我点击了,Claude再次尝试——但随后再次触及了限制。我欣赏的是,如果它找不到答案,它根本不会编造一个答案,而是简单地拒绝回答。在我看来,这是一大胜利,因为虚构一个解决方案更具问题性。

随后,我在同一任务上尝试了Claude Opus 4。答案几乎瞬间返回,并且是正确的:246 + 789 = 1035。Opus 4令人印象深刻!!
编程
对于这项编码任务,我决定直接使用Claude Opus 4。这种创造性的生成方式似乎更适合它的能力。我这里并不是在测试大型代码库——只是一个相对简单的编码任务。
我请求它使用我为Gemini 2.5 Pro和o4-mini所用的提示来制作一个快速的p5.js游戏:
提示:制作一个引人入胜的无尽跑酷游戏。屏幕上有关键指令。p5.js场景,不使用HTML。我喜欢像素风格的恐龙和有趣的背景。
通常,我会将代码复制粘贴到在线p5.js编辑器中进行测试。但Claude 4中的一个好功能是Artifacts,它让我可以直接在聊天中查看和运行代码输出。
让我们看看结果:

我测试过的以前的模型没有一个在第一次尝试时就正确显示启动界面——它们中的大多数直接跳入了游戏玩法。Claude Opus 4实际上展示了一个带有说明的正确启动界面,这令我感到惊喜。
不过,出现了一个视觉错误:像素化的恐龙在屏幕上移动时留下了混乱的轨迹。像素在帧之间没有被正确清除,影响了游戏体验。我指出了这一点,并要求Opus 4进行修正。

完美!我从其他任何模型那里都没有得到过如此干净且可玩的游戏版本。
Claude 4 Benchmarks
Claude 4模型在编码、推理和代理任务等一系列标准基准上进行了测试。尽管这些分数不能完全反映模型的质量,但仍然作为比较的参考非常有用。以下是Claude Sonnet 4和Claude Opus 4的关键结果。

Claude Sonnet 4
Claude Sonnet 4在可供免费用户使用的模型中表现出乎意料的良好。在SWE-bench Verified中,该模型对真实世界的编码任务评分为72.7%,略微超过Opus 4(72.5%),并显著领先于Claude 3.7 Sonnet(62.3%)。它的表现也超过了OpenAI的GPT-4.1(54.6%)和Gemini 2.5 Pro(63.2%)。
在其他基准测试中的表现如下:
-
TerminalBench(基于CLI的编码):35.5%——领先于GPT-4.1(30.3%)和Gemini(25.3%)
-
GPQA Diamond(研究生级推理):75.4%——表现强劲,虽然略低于OpenAI o3和Gemini
-
TAU-bench(代理工具使用):80.5%零售/60.0%航空——与Opus 4相当,领先于GPT-4.1和o3
-
MMLU(多语言问答):86.5%——仅低于Opus和o3,但依然稳固
-
MMMU(视觉推理):74.4%——在所有模型中得分最低
-
AIME(数学竞赛):70.5%——优于Sonnet 3.7,但竞争力仍显不足
Sonnet 4可以说是目前最佳表现的免费级模型之一,并且在与需要付费或商业访问的模型竞争中表现良好。
Claude Opus 4
Opus 4是Anthropic的旗舰模型,在大多数基准测试中表现位于前列或接近最高水平。在SWE-bench Verified中,它的得分为72.5%,而在高计算设置下,这一分数跃升至79.4%——在所有对比模型中最高。
它在以下方面表现领先或接近顶端:
-
TerminalBench(代理CLI编码):43.2%(在高计算模式下为50.0%)——图表中的最高得分
-
GPQA Diamond(研究生级推理):79.6%(83.3%)——表现稳固,略低于OpenAI o3和Gemini 2.5 Pro
-
TAU-bench(代理工具使用):81.4%零售/59.6%航空——与Sonnet 4和3.7持平
-
MMLU(多语言问答):88.8%——与OpenAI o3并列
-
MMMU(视觉推理):76.5%——落后于o3和Gemini 2.5 Pro
-
AIME(数学竞赛):75.5%(90.0%高计算)——显著高于Claude Sonnet 4
探索智能边界,发现无限可能!(AIOAGI.TECH)

中科创新烁智(CSCITech)
更多推荐


 12
12 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)