
DeepFaceLab 部署在 Ubuntu(docker gpu)
DeepFaceLab 在windows图形界面部署比较多,下面用ubuntu 部署在服务器上。部署过程中docker镜像可以共享python版本,或者protobuf版本可能有问题,所以建议用docker.我是能通的
DeepFaceLab 在windows图形界面部署比较多,下面用ubuntu 部署在服务器上。部署过程中python版本,或者protobuf版本可能有问题,所以建议用docker,若需要我可以共享我的镜像
代码下载
cd /trainssd
git clone --depth 1 https://github.com/nagadit/DeepFaceLab_Linux.git
cd DeepFaceLab_Linux
git clone --depth 1 https://github.com/iperov/DeepFaceLab.git
下载容器
docker pull tensoflow/tensorflow:2.4.0-gpu
启动docker容器
代码已经提前下载在
docker run -itd --name deepfacelab --gpus all -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=unix$DISPLAY -v /trainssd:/trainssd tensorflow/tensorflow:2.4.0-gpu /bin/bash
进入容器
docker exec -it deepfacelab /bin/bash
系统库安装
apt update && apt install -y vim libsm6 libxrender1 libxext6 ffmpeg wget
修改pip源
mkdir /root/.pip && cat>/root/.pip/pip.conf<<EOF
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
EOF
或者是
[global]
index-url=http://pypi.doubanio.com/simple/
trusted-host=pypi.doubanio.com
我这里用python3.8源码编译安装可以,python3.6会遇到protobuf 问题。
protobuf也需要下载源码编译对应的版本,3.20.3,编译安装
安装python依赖
cd /trainssd/DeepFaceLab_Linux/
python -m pip install -r ./DeepFaceLab/requirements-cuda.txt
关闭conda和修改python版本
#进入到scripts目录
cd ./scripts
sed -i 's/python3.7/python3.6/g' env.sh
sed -i 's/conda/#conda/g' env.sh
env.sh 里面
export DFL_PYTHON="python3.7"
改为
export DFL_PYTHON="python3.8"
初始化工作区
#慎重默认会删除所有工作区域的数据
bash 1_clear_workspace.sh
准备数据
#此处按照自己实际情况处理需要 data_src.为前缀和data_dst.为前缀
cp /data/yhf/SimSwap/Videos/fbb_02.mp4 /trainssd/DeepFaceLab_Linux/workspace/data_src.mp4
cp /data/yhf/SimSwap/Videos/fbb_01.mp4 /trainssd/DeepFaceLab_Linux/workspace/data_dst.mp4
src数据抽中
bash 2_extract_image_from_data_src.sh
dst数据抽中
bash 3_extract_image_from_data_dst.sh
数据去噪
bash 3.1_denoise_data_dst_images.sh
模型下载
bash 4.1_download_CelebA.sh
bash 4.1_download_FFHQ.sh
bash 4.1_download_Quick96.sh
###
按照脚本执行就可以bash 4_data_src_extract_faces_S3FD.sh
bash 5_data_dst_extract_faces_S3FD.sh
bash 6_train_Quick96.sh 或者 6_train_Quick96_no_preview.sh
bash 7_merge_Quick96.sh
bash 8_merged_to_mp4.sh
上面几个脚本能够训练出模型,其他的脚本是优化图像的,可以慢慢研究下
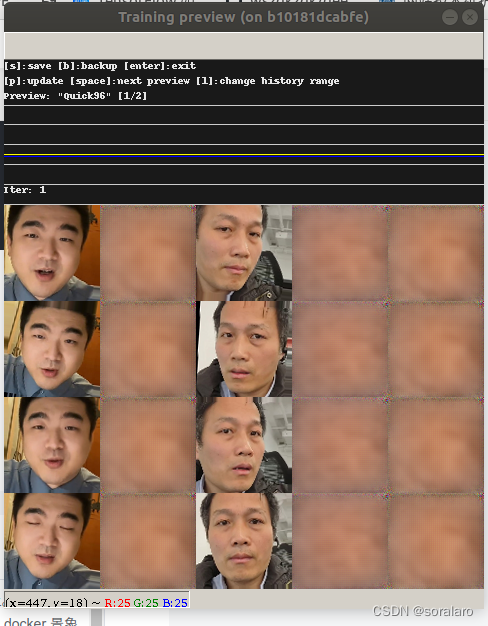
训练开始时候的窗口,第二第四第五列都是模糊的

随着训练迭代的次数增多,第二第四第五列算法会慢慢生成出人脸轮廓、五官,然后慢慢变的清晰。

我们只需要观察第二列是否与第一列无限相似,第四列与第三列无限相似,第五列的表情与第四列无限相似。
当所有列的图片足够清晰,那么就可以停止。
7_merge_Quick96.sh交互模式

若用非交互模式,我们参考了《 Project Aksel: Deepfake Head Replacement 》这篇文章里的 merge 参数的设置,效果不错。
方法1.
Mode: seamless mask_mode: learned-prd*learned-dst erode_mask_modifier: 0 blur_mask_modifier: 91 motion_blur_power: 0 output_face_scale: -7 color_transfer_mode: rct sharpen_mode : gaussian blursharpen_amount : 0 super_resolution_power: 0 image_denoise_power: 0 bicubic_degrade_power: 0 color_degrade_power: 0
方法2.
Mode: overlay
mask_mode: learned-prd*learned-dst
erode_mask_modifier: 0
blur_mask_modifier: 91
motion_blur_power: 0
output_face_scale: -7
color_transfer_mode: rct
sharpen_mode : gaussian
blursharpen_amount : 5
super_resolution_power: 0
image_denoise_power: 0
bicubic_degrade_power: 0
color_degrade_power: 0
方法3.
Mode: overlay mask_mode: learned-prd erode_mask_modifier: 18 blur_mask_modifier: 91 motion_blur_power: 0 output_face_scale: 0 color_transfer_mode: rct sharpen_mode : None blursharpen_amount : 0 super_resolution_power: 0 image_denoise_power: 0 bicubic_degrade_power: 0 color_degrade_power: 0
方法4.
Use interactive merger? ( y/n ) : n # 不能选 y!
mode: overlay
mask_mode: learned-prd
erode_mask_modifier: 0
blur_mask_modifier: 0
motion_blur_power: 0
output_face_scale: -5
color_transfer_mode: rct
sharpen_mode : None
blursharpen_amount : 0
super_resolution_power: 16
image_denoise_power: 0
bicubic_degrade_power: 0
color_degrade_power: 0
Number of workers:48
权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)