
hadoop集群之YARN`s ResourceManager HA(三)
如果有看蒙圈的地方,请看下HDFS HA官方给出的方案如下配置目标:node1 node2 node3:3台ZooKeepernode1 node2:为2台ResourceManager首先配置node1,配置etc/hadoop/yarn-site.xml:<property><name>yarn.resourcemanager.ha.enabled</name>
如果有看蒙圈的地方,请看下HDFS HA这篇文章
官方给出的方案如下
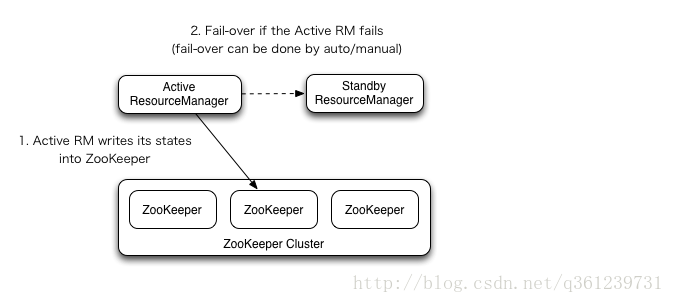
配置目标:
node1 node2 node3:3台ZooKeeper
node1 node2:为2台ResourceManager首先配置node1,配置etc/hadoop/yarn-site.xml:
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>rmcluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node2</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>配置etc/hadoop/mapred-site.xml:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>将node1的这2个配置文件拷贝(scp命令)到其他4台机器中
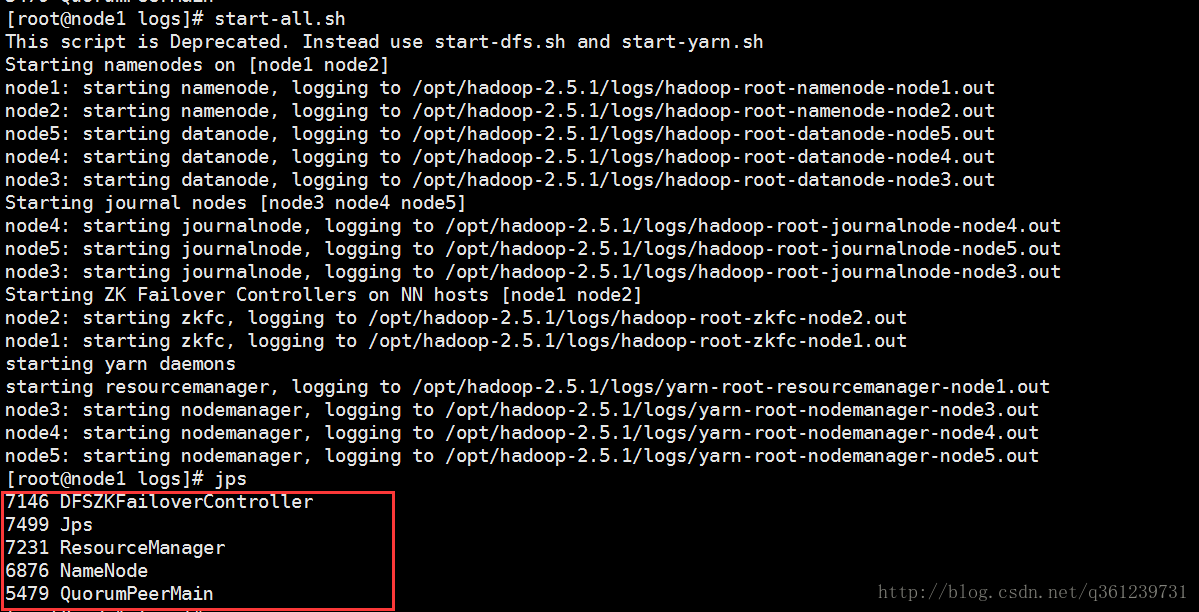
然后在node1上启动yarn:start-yarn.sh(同时会启动nodemanager(在DN的机器上,一 一对应))
或者使用start-all.sh 命令启动dfs和yarn
然后停掉ZooKeeper:zkServer.sh stop,停掉集群:stop-dfs.sh
启动ZooKeeper:zkServer.sh start
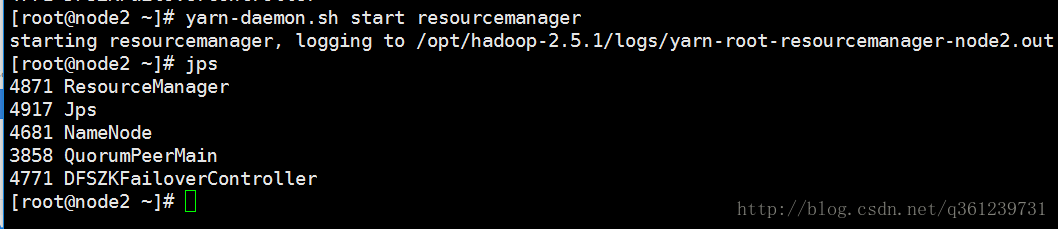
启动备用yarn(node2上):yarn-daemon.sh start resourcemanager
启动集群:start-dfs.sh
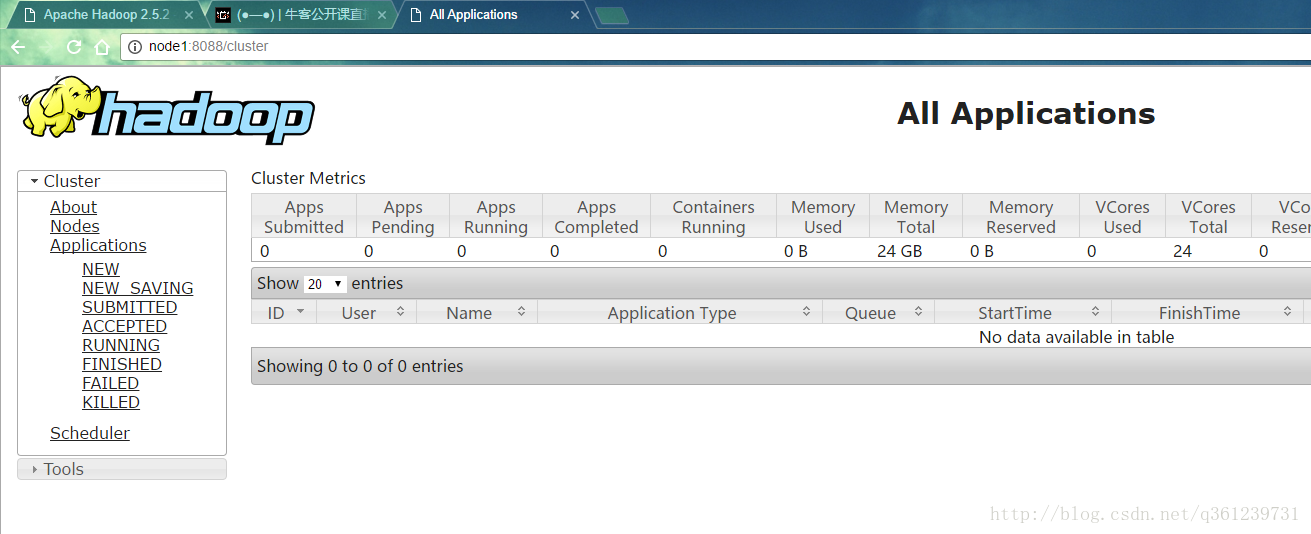
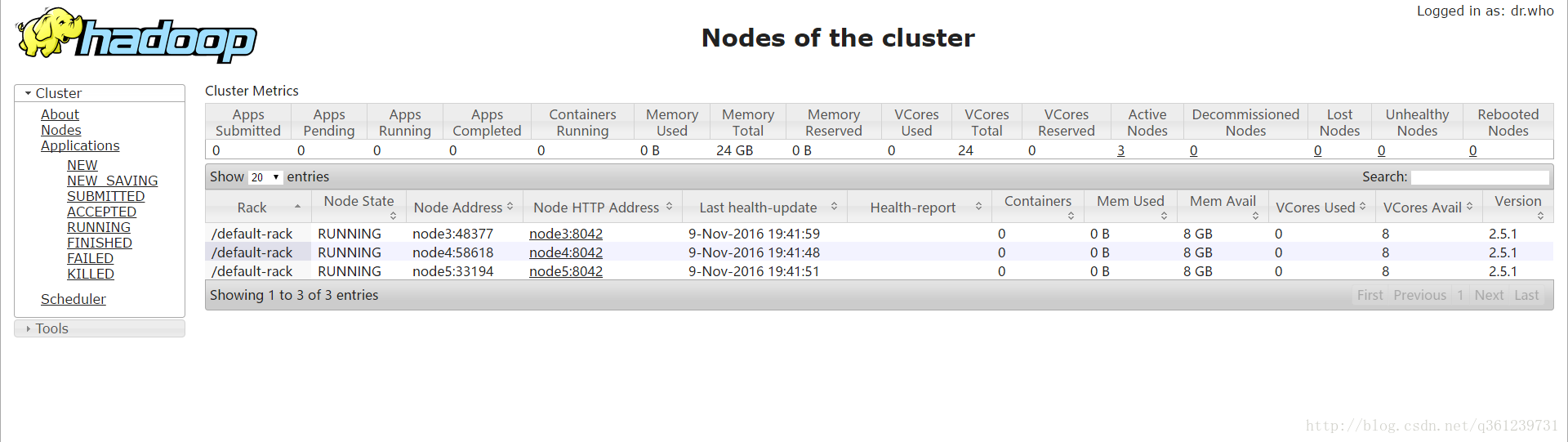
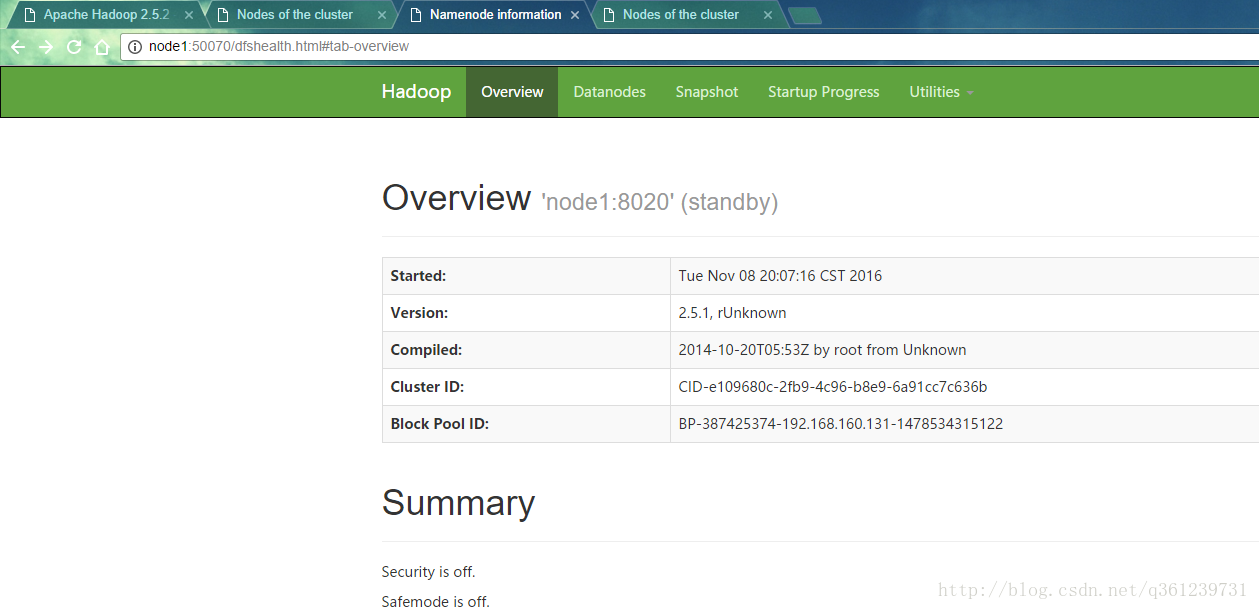
访问主节点web界面:node1:8088和node1:50070
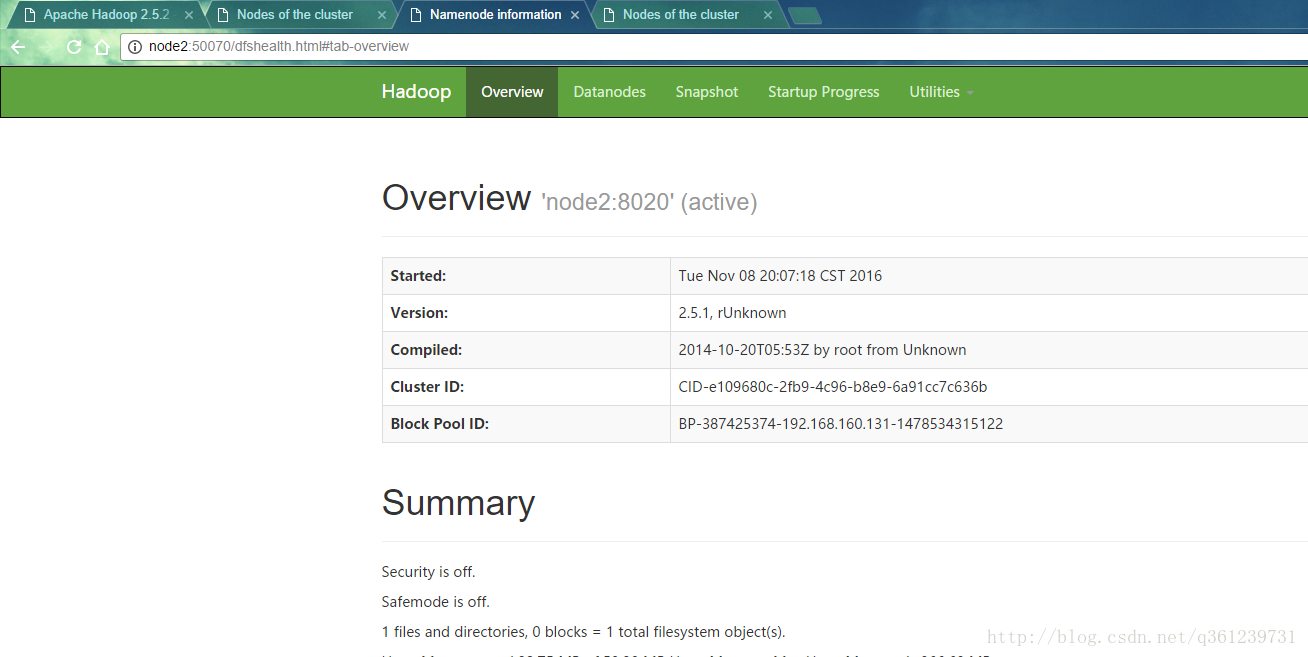
访问备用节点:node2:8088
kill 掉node1的 Resourcemanager进行,之后访问standby结点,需要较慢的时间才能完全接管。是因为,所有的NM都需要给RM进行汇报,而且有一定的超时时间,超过了这个时间才会证明此RM已经宕机。
如果访问node1:50070时,显示standby,则可能是zkfc和ZooKeeper出现了问题,需要去检查日志。、
解决方式:killall java,然后重新启动zkServer.sh start 和 集群 start-all.sh


权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)