
使用 8 种不同的 AWS 服务构建云原生网络爬虫
听起来有点矫枉过正,对吧?这是。显然,你不需要一大堆云服务来构建一个简单的网络爬虫,特别是因为已经有很多云服务了。然而,这描述了我通过构建一个简单但有用的应用程序来探索 AWS 上的云原生开发的个人旅程。
目标
我想要构建的是一个完全在云基础设施上运行的网络爬虫。更准确地说,我想使用Selenium WebDriver构建一个爬虫,因为它不仅应该能够爬取静态 HTML 页面,还应该能够爬取动态的、基于 JavaScript 的单页应用程序。考虑到这一要求,包含个请求或urllib的简单 Python 脚本已经不够用了。相反,您至少需要一个无头浏览器(如 Firefox、Chrome 或过时的PhantomJS)。
示例用例
为了更好地了解我正在构建的内容,请想象以下用例。您是一名学生,并且您的大学提供了一个基于 JavaScript 的网站,考试结果一经发布就会在该网站上发布。要检索您的结果,您需要输入您的学生 ID 并从下拉列表中选择一个部门。您对最近一次考试的成绩感到好奇,但由于您很懒惰,因此您不想每天手动检查网站。这就是完全过度设计的网络抓取工具发挥作用的地方。
要求
这里有一些关于应用程序应该能够做什么(以及如何)的注释 - 只是为了更好地理解。
-
不同的爬取任务被预定义为 Java 中的 WebDriver 脚本。
-
用户可以为预定义的爬取作业添加订阅。它们将导致使用某些参数(例如要由 Selenium 填充的表单输入字段值)以固定间隔(例如每 24 小时)执行某个爬网任务。
-
为某个任务(对应于某个网页)添加订阅时,用户提供他们的电子邮件地址,并在爬虫检测到更改时收到通知。
-
网站状态保留在相应订阅的 Dynamo 项中,并与抓取工具运行时检索到的最新状态进行比较。
架构
您可以在下面看到所有组件和相应 AWS 服务的高级概述,以及组件之间的基本交互。请注意,该图不是正确的 UML,但它应该有助于了解整体架构。乍一看,它看起来有点花哨。)
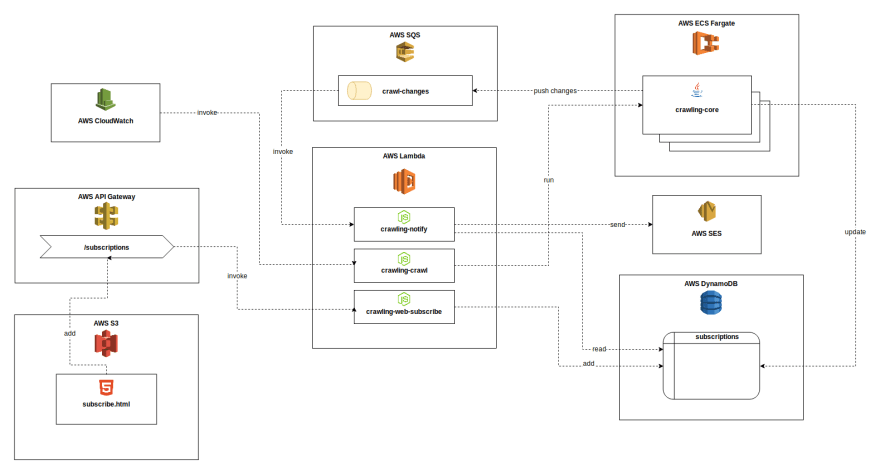
(点击查看大)
AWS 服务
使用的云服务有:
-
AWS Lambda 用于无服务器 NodeJS 函数以执行无状态任务
-
AWS Fargate 作为按需 Docker 容器运行时执行运行时间更长、资源更密集的任务
-
AWS DynamoDB 作为无模式数据存储来管理订阅和网站状态
-
AWS SQS 作为组件之间通信和触发 Lambda 的异步消息传递通道
-
AWS S3 托管静态 HTML 页面,其中包含用于通过 UI 添加新订阅的表单
-
AWS API Gateway 为添加新订阅提供 HTTP 端点。它由“前端”端脚本调用,随后触发 Lambda 以将新订阅添加到 Dynamo。
-
AWS CloudWatch 以类似 crontab 的方式定期触发 Fargate 上的刮板执行
-
AWS SES 在发生变化时发送通知电子邮件
组件
让我们非常简要地看一下这几个组件在做什么。
爬行芯
这本质上是整个应用程序的核心部分,真正的爬虫/爬虫。我将它实现为 Java 命令行应用程序,它具有 WebDriver 作为依赖项,能够与网页动态交互。
该程序本身负责执行实际的爬取任务,通过将任务的结果与数据库中的最新状态进行比较来检测更改,更新数据库项目并可能将更改通知消息推送到队列。
抓取任务被定义为扩展AbstractTask类的 Java 类。例如,您可以创建子类AmazonPriceTask和ExamsResultsTask。在实现这些类时,您基本上需要定义输入参数(例如,稍后将在大学网站上的搜索表单中填写您的学生 ID 号)以进行爬取WebDriver 执行的run()方法中的脚本和一系列命令。
crawling-core是作为独立的 Java 命令行应用程序开发的,其中要执行的任务的名称(例如EXAM_RESULT_TASK)和输入参数(例如VAR_STUDENT_ID、VAR_DEPARTMENT_NAME)作为运行参数或环境变量提供。
除了打包为简单 JAR 的 Java 程序之外,我们还需要一个 WebDriver 可以用来浏览 Web 的浏览器。我决定在无头模式下使用 Firefox。最终,JAR 和 Firefox 二进制文件一起打包成一个基于selenium/standalone-firefox的 Docker 镜像,并推送到 AWS ECR(AWS 的容器注册表)。
执行抓取任务,例如我们的ExamsResultsTask,AWS Fargate 将从注册表中提取最新的 Docker 映像,从中创建一个新容器,将所需的输入参数设置为环境变量,并最终运行入口点,即我们的 JAR 文件。
λ 爬行-爬行
... 是一个用 NodeJS 编写的非常简单的 Lambda 函数,负责启动一个爬取作业。它通过 CloudWatch 事件定期触发。首先,它从 Dynamo 获取所有爬取任务。爬取任务是任务名称和一组输入参数的唯一组合。之后,它请求 Fargate 为每个任务启动一个crawling-core的新实例,并传递数据库项中包含的输入参数。
λ 爬行通知
... 是另一个 Lambda,它位于我们爬行过程的一次迭代的最后。它通过crawling-changesSQS 队列中的消息调用,负责向订阅者发送通知电子邮件。它从调用事件中读取更改信息,包括任务名称、订阅者的电子邮件地址和任务的输出参数(例如您的考试成绩),并编写最终通过简单电子邮件服务发送的电子邮件消息(* SES*)。
λ 爬行网络订阅
我们三个 Lambda 中的最后一个与爬取本身没有直接关系。相反,它用于处理想要添加新订阅的用户发送的 HTTP 请求。由名为subscribe.html的 HTML 页面上的简单脚本启动,POST 被发送到 API Gateway 中的/subscriptions端点,然后转发到crawling-web-subscribe并最终作为subscriptions表中的新项目添加到 Dynamo 数据库中。
好的,很酷。现在?
正如我之前提到的,这个项目对我来说更像是一个学习游乐场,而不是一个合理的网络爬虫架构。虽然这个实际上应该是相当可扩展的,但是你绝对可以用更少的努力来构建一个爬虫脚本。但是,我特别学到了很多关于云开发和 AWS 的知识,我真的很喜欢事情的简单性以及所有这些不同的组件如何协同工作。也许我能够鼓励你们中缺乏云经验的开发人员也开始使用 AWS(或其他一些云提供商),我希望你们喜欢我的(非常自发的)文章。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献35529条内容
已为社区贡献35529条内容

所有评论(0)