无服务器数据管道:使用 Step Functions 和 Athena 的 ETL 工作流
本博客是关于分析法兰德斯流量的多部分系列文章的第 3 部分,同时利用云组件的强大功能!
对于第 1 部分,请参阅:https://medium.com/cloudway/real-time-data-processing-with-kinesis-data-analytics-ad52ad338c6d
对于第 2 部分,请参阅:https://medium.com/cloubis/serverless-data-transform-with-kinesis-e468abd33409
我们的目标是什么?
本博客旨在探索将 AWS Glue 服务与 AWS Athena 服务结合使用来重新分区原始流数据事件。
我们之前将这些事件放在根据 Kinesis 上的处理时间分区的 Amazon S3 存储桶上。
但是,我们希望根据事件时间戳对这些事件进行分区,以便进行有意义的批处理分析。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--F9GgXIdV--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/edke2jtpg43tp6rykekk.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--F9GgXIdV--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/edke2jtpg43tp6rykekk.png)
一、AWS Glue简介
AWS Glue(于 2017 年 8 月推出)是一种无服务器的提取、转换和加载 (ETL) 云优化服务。
该服务可用于自动组织、定位、移动和转换存储在各种数据源中的数据集的 ETL 流程,使用户能够有效地准备这些数据集以进行数据分析。例如,这些数据源可以是 Amazon Simple Storage Service (S3) 中的数据湖、Amazon Redshift 中的数据仓库或属于 Amazon Relational Database Service 的其他数据库。 AWS GLue 还支持其他类型的数据库,例如 MySQL、Oracle、Microsoft SQL Server 和 PostgreSQL。
由于 AWS Glue 是一项无服务器服务,因此用户无需预置、配置和启动服务器,也无需花时间管理服务器。
AWS Glue 的核心是 Catalogue,它是所有数据资产的集中式元数据存储库。
有关数据资产的所有相关信息(例如表定义、数据位置、文件类型、模式信息)都存储在此存储库中。
为了将此信息添加到目录中,AWS Glue 使用爬网程序。这些爬虫可以扫描数据存储并自动推断可能包含在数据存储中的任何结构化和半结构化数据的架构,并且:
-
发现文件类型
-
提取架构
-
自动发现数据集
-
将所有这些信息存储在数据目录中
当数据被编目后,就可以访问它并且可以在其上执行 ETL 作业。
AWS Glue 提供自动生成 ETL 脚本的功能,可以将其用作起点,这意味着用户在开发 ETL 流程时不必从头开始。
然而,在本博客中,我们将重点介绍 AWS Glue ETL 作业的替代方法的使用。
我们将利用在 AWS Athena 中实现的 SQL 查询来执行 ETL 过程。
对于更复杂的 ETL 流程的实施和编排,AWS Glue 为用户提供了使用工作流的选项。这些可用于协调涉及多个爬虫、作业和触发器的更复杂的 ETL 活动。但是,我们将使用这些 AWS Glue 工作流程的替代方案,即具有步进函数的状态机来协调我们的 ETL 流程。
重申一下,AWS Glue 有 3 个主要组件:
-
数据目录,一个集中的元数据存储库,与您的数据有关的所有元数据信息都存储在其中。这包括有关表(定义存储数据集的元数据表示或模式)、模式和分区的信息。元数据属性由爬虫在数据源中推断,爬虫也提供与它们的连接。
-
Apache Spark ETL 引擎。一旦元数据在数据目录中可用并且可以从目录中选择源和目标数据存储,Apache Spark ETL 引擎允许创建可用于处理数据的 ETL 作业。
-
调度程序。用户可以为其 AWS ETL 作业设置计划。此计划可以链接到特定触发器(例如,另一个 ETL 作业的完成)、一天中的特定时间或作业可以设置为按需运行。
状态机
如上所述,我们的目标是创建一个 ELT 管道,它将重新分区我们已经登陆 S3 数据湖的数据。
这种重新分区将确保根据事件中的时间戳对数据进行分区。
这符合我们的分析目的,而不是根据记录到达 kinesis firehose 的时间戳进行分区。
为了实现这一点,我们构建了一个 ETL 作业以从 S3 中提取现有数据,通过根据数据中的事件时间戳创建新列来对其进行转换,并将其放入新分区中。
具体来说,ETL 作业实现了以下目标:
-
首先,我们需要弄清楚当前数据是什么样的。换句话说,我们需要在 Glue 目录中为我们的源数据(即根据我们在 S3 上的 Kinesis Firehose 时间戳分区的数据)注册一个模式。
-
为了确定这个模式,我们需要运行一个爬虫,探索现有数据并确定这个数据格式。运行爬虫为源数据创建了一个模式,并将该模式注册到 Glue 目录。
-
接下来,我们需要运行 ETL 流程,以便将数据转换为新的分区。正如本博客中已经提到的,我们将重点介绍使用 Athena 来实现重新分区。阅读我们的下一篇博客,了解它是如何使用 AWS Glue 完成的。
-
数据重新分区后,我们当然希望能够查询数据以进行分析。为了实现这一点,我们需要再次运行爬虫来确定重新分区的数据是什么样的。然后,爬虫在 Glue 目录中注册了新模式。
连续运行这个过程不会很有效。
另一方面,如果运行此过程的频率不够高(例如每周只运行一次),则意味着我们将不得不等待太长时间才能报告新数据。
我们有一个需要定期编排的几个托管步骤(运行爬虫、注册模式、执行 ETL 作业、运行爬虫)的过程。
因此,它非常适合使用 AWS 步进函数进行编排。
_在 AWS Step Functions 中,您可以使用 Amazon 状态语言定义您的工作流程。
Step Functions 控制台提供该状态机的图形表示,以帮助可视化您的应用程序逻辑。
状态是状态机中的元素。
一个状态是通过它的名字来引用的,它可以是任何字符串,但是在整个状态机的范围内必须是唯一的_
以下是我们的状态机外观的概述:
[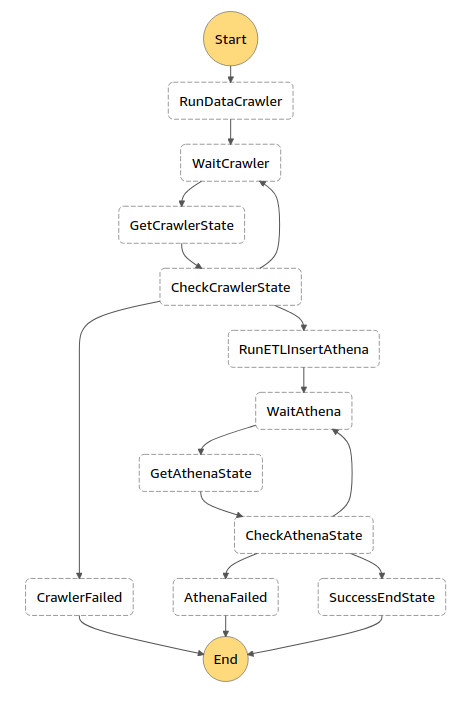 ](https://res.cloudinary.com/practicaldev/image/fetch/s--QKPcg_0k--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/xpuz2k6t2jvafwu22hnl.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--QKPcg_0k--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/xpuz2k6t2jvafwu22hnl.png)
如您所见,我们一个接一个地执行了有限数量的步骤。
ASL - 亚马逊状态语言
ASL是一种基于 JSON 的语言,用于定义状态机的步骤。
这是一种 JSON 基础语言,用于定义状态机的步骤。
稍后我们将深入研究每个步骤中执行的逻辑。
我们先来看定义这些步骤的ASL。
AWS Sam 和无服务器框架都允许您将 ASL 指定为YAML。
我们发现使用YAML提高了可读性。
因此,我们将ASL定义如下(完整的ASL模式可用此处为):
BatchProcessingStateMachine:
events:
- schedule: rate(1 day)
name: BatchProcessingStateMachine
definition:
Comment: "State machine for the batch processing pipeline"
StartAt: RunDataCrawler
States:
RunDataCrawler:
Type: Task
Resource: arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:${self:service}-${opt:stage}-RunDataCrawler
Next: WaitCrawler
WaitCrawler:
Type: Wait
Seconds: 30
Next: GetCrawlerState
GetCrawlerState:
Type: Task
Resource: arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:${self:service}-${opt:stage}-GetCrawlerState
Next: CheckCrawlerState
CheckCrawlerState:
Type: Choice
Default: WaitCrawler
Choices:
- And:
- Variable: '$.CrawlerState'
StringEquals: READY
- Variable: '$.CrawlerStatus'
StringEquals: SUCCEEDED
Next: RunETLInsertAthena
- And:
...
进入全屏模式 退出全屏模式
此ASL描述了与上述状态图相同的工作流程。
对于人眼来说,阅读起来要困难得多。
请注意,我们确实有以下步骤:运行爬虫、注册模式、执行 ETL 作业和再次运行爬虫。
但我们也有“等待”步骤,我们会定期检查爬虫是否准备好工作。
我们有失败的状态,我们用来对过程中可能出现的失败做出反应。
由于本博客关注数据而不是如何构建状态机,如果您想了解更多关于AWS State Machines和Step Functions的信息,我们将在此处放置一个链接:点击此处。
在资源中,您将找到Yan Cui的精彩课程的链接。
步进函数的逻辑
现在是时候更深入地了解每个步骤中发生的情况了。
提示:为您的步骤选择描述性名称,以便立即清楚特定步骤中发生的情况。
这是我们的一些步骤(再次,如果您想查看所有逻辑,请查看存储库):
运行数据爬虫
这会触发 Lambda 函数的执行,进而触发 Glue Crawler
glue_client = boto3.client('glue')
CRAWLER_NAME = os.environ['CRAWLER_NAME']
def handle(event, context):
timezone = pytz.timezone('Europe/Brussels')
now = datetime.now(timezone)
response = glue_client.start_crawler(Name=CRAWLER_NAME)
return {'response': response, 'year': event.get('year', now.year), 'month': event.get('month', now.month), 'day': event.get('day', now.day-1)}
进入全屏模式 退出全屏模式
获取爬虫状态
我们会定期检查正在运行的爬虫的状态。
由于没有将爬虫事件与步进函数直接集成(还没有?),我们必须使用 lambda 函数来检查这一点。
glue_client = boto3.client('glue')
CRAWLER_NAME = os.environ['CRAWLER_NAME']
def handle(event, context):
response = glue_client.get_crawler(Name=CRAWLER_NAME)['Crawler']
return {'CrawlerState': response['State'], 'CrawlerStatus': response.get('LastCrawl', {'Status': None})['Status'],
'year': event['year'], 'month': event['month'], 'day': event['day']}
进入全屏模式 退出全屏模式
这会返回爬虫的状态,从而告诉我们爬虫是否完成。
从图表和ASL可以看出,我们将使用此状态生成choice,以便下一步执行。
运行ETLI插入雅典娜
爬虫完成后,就该运行 ETL 作业了。
这是使用 AWSAthena完成的。
在下一段中阅读有关Athena的方式和内容的更多信息。
但是,Lambda 函数的工作是在Athena中启动 ETL 作业并检查它何时完成。
启动 ETL 作业的 lambda 函数的处理程序如下所示。
def handle(event, context):
try:
queries = create_queries(event['year'], event['month'], event['day'])
...
try:
response = execute_query(query)
execution_ids.append(response)
except Exception as e:
return {'Response': 'FAILED', 'Error': str(e)}
return {'Response': 'SUCCEEDED', 'QueryExecutionIds': execution_ids}
进入全屏模式 退出全屏模式
-
定义查询,指定要重新分区的数据范围。
-
将这些查询传递给
Athena。 -
返回 Athena 执行 ID。一个 ID,我们可以使用它来检查 Athena 的 ETL 作业的状态。
下一个函数检查 ETL 作业是否完成。
它通过使用从最新步骤返回的执行 ID 来执行此操作。
def handle(event, context):
response = athena_client.batch_get_query_execution(QueryExecutionIds=event['QueryExecutionIds'])
for execution in response['QueryExecutions']:
state = execution['Status']['State']
if state != 'SUCCEEDED':
return {'AthenaState': state, 'QueryExecutionId': execution['QueryExecutionId'], 'QueryExecutionIds': event['QueryExecutionIds']}
...
return {'AthenaState': 'SUCCEEDED'}
进入全屏模式 退出全屏模式
上一步中的QueryExecutionIds现在用于获取特定查询的状态。
我们看到了工作流中重新分区数据所需的步骤。
这种重新分区是通过 Athena 实现的。
让我们在下一段中深入探讨。
雅典娜服务
如上所述,我们使用 AWS Athena 运行 ETL 作业,而不是使用自动生成脚本的 Glue ETL 作业。
AWS Athena 原生支持查询在 Glue 数据目录中注册的数据集和数据源。这意味着 Athena 将使用 Glue 数据目录作为存储和检索表元数据的集中位置。此元数据指示 Athena 查询引擎应在何处读取数据、应以何种方式读取数据并提供处理数据所需的附加信息。
例如,可以针对在数据目录中注册的源表运行 INSERT INTO DML 查询。此查询将根据针对源表运行的 SELECT 语句将行插入到目标表中。
下面我们展示了完整的 INSERT INTO DML 查询的一部分,它具有额外的嵌套子查询,其中源表中的数据被逐步转换,以便可以重新分区并用于分析。
INSERT INTO "traffic"."sls_data_pipelines_batch_transformed"
SELECT uniqueId, recordTimestamp, currentSpeed, bezettingsgraad, previousSpeed,
CASE
WHEN (avgSpeed3Minutes BETWEEN 0 AND 40) THEN 1
WHEN (avgSpeed3Minutes BETWEEN 41 AND 250) THEN 0
ELSE -1
END
as trafficJamIndicator,
CASE
WHEN (avgSpeed20Minutes BETWEEN 0 AND 40) THEN 1
WHEN (avgSpeed20Minutes BETWEEN 41 AND 250) THEN 0
ELSE -1
END
as trafficJamIndicatorLong, trafficIntensityClass2, trafficIntensityClass3, trafficIntensityClass4, trafficIntensityClass5, speedDiffindicator, avgSpeed3Minutes, avgSpeed20Minutes, year, month, day, hour
FROM
(SELECT uniqueId, recordTimestamp, currentSpeed, bezettingsgraad, previousSpeed, trafficIntensityClass2, trafficIntensityClass3, trafficIntensityClass4, trafficIntensityClass5,
CASE
WHEN (currentSpeed - previousSpeed >= 20) THEN 1
WHEN (currentSpeed - previousSpeed <= -20) THEN -1
ELSE 0
END
AS speedDiffindicator, avg(currentSpeed)
OVER (PARTITION BY uniqueId ORDER BY originalTimestamp ROWS BETWEEN 2 PRECEDING AND 0 FOLLOWING)
AS avgSpeed3Minutes, avg(currentSpeed)
OVER (PARTITION BY uniqueId ORDER BY originalTimestamp ROWS BETWEEN 19 PRECEDING AND 0 FOLLOWING)
AS avgSpeed20Minutes,year(originalTimestamp) as year, month(originalTimestamp) as month, day(originalTimestamp) as day, hour(originalTimestamp) as hour
FROM
(SELECT...
进入全屏模式 退出全屏模式
上面直接显示的(部分)INSERT INTO DML 查询执行了以下操作:
-
数据分析相关信息的最终选择。并非原始数据中包含的所有信息都对分析有用,并且某些数据可能无效(例如由于测量设备故障)
-
用于分析目的的聚合值和派生字段的计算。例如,计算平均速度和执行我们认为交通拥堵的逻辑。
-
按事件时间(即 originalTimestamp 的年、月和日值)对数据进行重新分区。重新分区是通过首先在 AWS Glue 目录中定义一个目标表来实现的,其中年、月、日和小时 bigint 字段被指定为分区键。随后,我们提取了 originalTimestamp 的年、月、日值(即测量本身的时间戳,而不是 Kinesis 上处理时间的时间戳),最后将这些值分配给年、月、日和小时 bigint我们在目标表中指定为分区键的字段。
附加的嵌套子查询执行以下操作:
-
从源数据中选择和转换(必要时)相关信息,以计算聚合值和派生字段。
-
从 4600 个测量位置的总数中选择位置子集,并自然地重新组合这些位置(例如,对同一条道路上的车道集进行分组)。
-
将查询拆分为(最多)4 天的数据范围(即开始日和结束日之间的范围)。由于 Amazon 使用 INSERT INTO 语句将同时写入的分区限制为 100 个,因此我们实现了一个 Lambda 函数来执行多个并发查询。查询的拆分将同时写入的分区数量限制为 96 小时。
有关完整的 INSERT INTO DML 查询的链接,请参阅https://github.com/becloudway/serverless-data-pipelines-batch-processing/blob/master/queries/InsertETL.sql。
有关字段定义说明的链接,请参阅此链接。
使用 AWS Athena 执行 ETL 作业时,与使用 Glue ETL 作业不同,没有自动启动工作流中下一个流程的功能。
因此,我们还实施了轮询机制,以定期检查爬虫/ETL 查询的完成情况。
ETL 工作流程的替代解决方案
正如已经多次提到的,我们也可以使用 Glue ETL 作业来实现 ETL 工作流。这些 ETL 作业通过带有 Spark 的 python 脚本处理数据的所有处理和重新分区。
在本系列的下一篇博客中,我们将探讨这种替代解决方案的实际实施,并比较使用 Glue ETL 作业与 AWS Athena ETL 查询来实施 ETL 工作流的优缺点。
资源
-
Step Function 课程:https://theburningmonk.thinkific.com/courses/complete-guide-to-aws-step-functions
-
使用 Step Functions 的无服务器工作流:https://aws.amazon.com/getting-started/hands-on/create-a-serverless-workflow-step-functions-lambda/
-
数据 - 字段定义:https://github.com/becloudway/serverless-data-pipelines-batch-processing
-
封面 - 图片:https://unsplash.com/@hertwashere
联系作者:
Nick van Hoof - AWS 社区建设者 - Trans-IT:https://twitter.com/TheNickVanHoof
David Smits -Cloubis&Cloudway:david.smits@cloubis.be
审核人 -Mitch Mommers - 云原生顾问

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35526条内容
已为社区贡献35526条内容

所有评论(0)