
构建、训练和部署 102 种花卉类型的真实花卉分类器
使用 TensorFlow 2.3、Amazon SageMaker Python SDK 2.5.x 和自定义 SageMaker 训练和服务 Docker 容器 [](https://res.cloudinary.com/practicaldev/image/fetch/s--_600-cC2--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_8
使用 TensorFlow 2.3、Amazon SageMaker Python SDK 2.5.x 和自定义 SageMaker 训练和服务 Docker 容器
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--_600-cC2--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// miro.medium.com/max/791/1%2AU5fka0ETq6k3mVVd4zyrMA.jpeg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--_600-cC2--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// miro.medium.com/max/791/1%2AU5fka0ETq6k3mVVd4zyrMA.jpeg)
简介
我爱花。上面的莲花是我2008年访问北京颐和园时最喜欢的花卉照片之一。由于我是一名开发人员,喜欢学习和从事人工智能和云项目,所以我决定写这篇博文来分享我的项目是使用 TensorFlow、Amazon SageMaker 和 Docker 构建真实世界的花卉分类器。
这篇文章显示了分步指南:
-
使用即用型Flower datasetfromTensorFlow Datasets。
-
使用迁移学习用于从TensorFlow Hub的预训练模型中提取特征。
-
使用tf.dataAPI 为分为训练、验证和测试数据集的数据集构建输入管道。
-
使用tf.kerasAPI 来构建、训练和评估模型。
-
使用Callback定义模型训练的提前停止阈值。
-
准备训练脚本以SavedModel格式训练和导出模型,以便使用 TensorFlow 2.x 和Amazon SageMaker Python SDK 2.x 进行部署。
-
准备推理代码和配置以运行TensorFlow Serving ModelServer为模型提供服务。
-
构建自定义Docker 容器用于使用Amazon SageMaker Python SDK和SageMaker TensorFlow 训练工具包训练和服务TensorFlow 模型本地模式**。
该项目可在以下位置向公众开放:
https://github.com/juvchan/amazon-sagemaker-tensorflow-custom-containers
设置
以下是用于开发和测试项目的系统、硬件、软件和 Python 包的列表。
-
Ubuntu 18.04.5 LTS
-
码头工人 19.03.12
-
Python 3.8.5
-
康达 4.8.4
-
英伟达 GeForce RTX 2070
-
NVIDIA 容器运行时库 1.20
-
NVIDIA CUDA 工具包 10.1
-
贤者 2.5.3
-
sagemaker-tensorflow-training 20.1.2
-
张量流 GPU 2.3.0
-
张量流数据集 3.2.1
-
tensorflow-hub 0.9.0
-
张量流模型服务器 2.3.0
-
jupyterlab 2.2.6
-
枕头 7.2.0
-
matplotlib 3.3.1
花卉数据集
TensorFlow 数据集 (TFDS) 是一组公共数据集,可与 TensorFlow、JAX 和其他机器学习框架一起使用。所有 TFDS 数据集都公开为tf.data.Datasets,易于用于高性能输入管道。
迄今为止,TFDS 中共有 195 个现成可用的数据集。 TFDS中有2个花卉数据集:oxford_flowers102, tf_flowers
使用 oxford_flowers102 数据集是因为它具有更大的数据集大小和更多的花卉类别。
ds_name = 'oxford_flowers102'
splits = ['test', 'validation', 'train']
ds, info = tfds.load(ds_name, split = splits, with_info=True)
(train_examples, validation_examples, test_examples) = ds
print(f"Number of flower types {info.features['label'].num_classes}")
print(f"Number of training examples: {tf.data.experimental.cardinality(train_examples)}")
print(f"Number of validation examples: {tf.data.experimental.cardinality(validation_examples)}")
print(f"Number of test examples: {tf.data.experimental.cardinality(test_examples)}\n")
print('Flower types full list:')
print(info.features['label'].names)
tfds.show_examples(train_examples, info, rows=2, cols=8)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--RGq_CaKM--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium. com/max/1250/1%2AVQkETmU-buuodJkwnHFtTg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--RGq_CaKM--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium. com/max/1250/1%2AVQkETmU-buuodJkwnHFtTg.png)
创建 SageMaker TensorFlow 训练脚本
Amazon SageMaker 允许用户以与在 SageMaker 外部使用相同的方式使用训练脚本或推理代码来运行自定义训练或推理算法。
区别之一是与 Amazon SageMaker 一起使用的训练脚本可以使用SageMaker Containers Environment Variables,例如SM_MODEL_DIR、SM_NUM_GPUS、SM_NUM_CPUS 在 SageMaker 容器中。
Amazon SageMaker 在运行脚本、训练算法或部署模型时始终使用 Docker 容器。 Amazon SageMaker 为其内置算法提供容器,并为一些最常见的机器学习框架提供预构建的 Docker 映像。您还可以创建自己的容器映像来管理 Amazon SageMaker 提供的容器未解决的更高级用例。
自定义训练脚本如下图:
import argparse
import numpy as np
import os
import logging
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
EPOCHS = 5
BATCH_SIZE = 32
LEARNING_RATE = 0.001
DROPOUT_RATE = 0.3
EARLY_STOPPING_TRAIN_ACCURACY = 0.995
TF_AUTOTUNE = tf.data.experimental.AUTOTUNE
TF_HUB_MODEL_URL = 'https://tfhub.dev/google/inaturalist/inception_v3/feature_vector/4'
TF_DATASET_NAME = 'oxford_flowers102'
IMAGE_SIZE = (299, 299)
SHUFFLE_BUFFER_SIZE = 473
MODEL_VERSION = '1'
class EarlyStoppingCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy') > EARLY_STOPPING_TRAIN_ACCURACY):
print(
f"\nEarly stopping at {logs.get('accuracy'):.4f} > {EARLY_STOPPING_TRAIN_ACCURACY}!\n")
self.model.stop_training = True
def parse_args():
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script
parser.add_argument('--epochs', type=int, default=EPOCHS)
parser.add_argument('--batch_size', type=int, default=BATCH_SIZE)
parser.add_argument('--learning_rate', type=float, default=LEARNING_RATE)
# model_dir is always passed in from SageMaker. By default this is a S3 path under the default bucket.
parser.add_argument('--model_dir', type=str)
parser.add_argument('--sm_model_dir', type=str,
default=os.environ.get('SM_MODEL_DIR'))
parser.add_argument('--model_version', type=str, default=MODEL_VERSION)
return parser.parse_known_args()
def set_gpu_memory_growth():
gpus = tf.config.list_physical_devices('GPU')
if gpus:
print("\nGPU Available.")
print(f"Number of GPU: {len(gpus)}")
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
print(f"Enabled Memory Growth on {gpu.name}\n")
print()
except RuntimeError as e:
print(e)
print()
def get_datasets(dataset_name):
tfds.disable_progress_bar()
splits = ['test', 'validation', 'train']
splits, ds_info = tfds.load(dataset_name, split=splits, with_info=True)
(ds_train, ds_validation, ds_test) = splits
return (ds_train, ds_validation, ds_test), ds_info
def parse_image(features):
image = features['image']
image = tf.image.resize(image, IMAGE_SIZE) / 255.0
return image, features['label']
def training_pipeline(train_raw, batch_size):
train_preprocessed = train_raw.shuffle(SHUFFLE_BUFFER_SIZE).map(
parse_image, num_parallel_calls=TF_AUTOTUNE).cache().batch(batch_size).prefetch(TF_AUTOTUNE)
return train_preprocessed
def test_pipeline(test_raw, batch_size):
test_preprocessed = test_raw.map(parse_image, num_parallel_calls=TF_AUTOTUNE).cache(
).batch(batch_size).prefetch(TF_AUTOTUNE)
return test_preprocessed
def create_model(train_batches, val_batches, learning_rate):
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
base_model = hub.KerasLayer(TF_HUB_MODEL_URL,
input_shape=IMAGE_SIZE + (3,), trainable=False)
early_stop_callback = EarlyStoppingCallback()
model = tf.keras.Sequential([
base_model,
tf.keras.layers.Dropout(DROPOUT_RATE),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
model.fit(train_batches, epochs=args.epochs,
validation_data=val_batches,
callbacks=[early_stop_callback])
return model
if __name__ == "__main__":
args, _ = parse_args()
batch_size = args.batch_size
epochs = args.epochs
learning_rate = args.learning_rate
print(
f"\nBatch Size = {batch_size}, Epochs = {epochs}, Learning Rate = {learning_rate}\n")
set_gpu_memory_growth()
(ds_train, ds_validation, ds_test), ds_info = get_datasets(TF_DATASET_NAME)
NUM_CLASSES = ds_info.features['label'].num_classes
print(
f"\nNumber of Training dataset samples: {tf.data.experimental.cardinality(ds_train)}")
print(
f"Number of Validation dataset samples: {tf.data.experimental.cardinality(ds_validation)}")
print(
f"Number of Test dataset samples: {tf.data.experimental.cardinality(ds_test)}")
print(f"Number of Flower Categories: {NUM_CLASSES}\n")
train_batches = training_pipeline(ds_train, batch_size)
validation_batches = test_pipeline(ds_validation, batch_size)
test_batches = test_pipeline(ds_test, batch_size)
model = create_model(train_batches, validation_batches, learning_rate)
eval_results = model.evaluate(test_batches)
for metric, value in zip(model.metrics_names, eval_results):
print(metric + ': {:.4f}'.format(value))
export_path = os.path.join(args.sm_model_dir, args.model_version)
print(
f'\nModel version: {args.model_version} exported to: {export_path}\n')
model.save(export_path)
使用 TensorFlow Hub (TF-Hub) 进行迁移学习
TensorFlow Hub是一个可重复使用的预训练机器学习模型库,用于不同问题域中的迁移学习。
对于这个花卉分类问题,我们基于不同的图像模型架构和来自 TF-Hub 的数据集评估预训练的图像特征向量,如下所示,用于oxford_flowers102 数据集的迁移学习。
-
ResNet50 特征向量
-
MobileNet V2 (ImageNet) 特征向量
-
Inception V3 (ImageNet) 特征向量
-
Inception V3 (iNaturalist) 特征向量
在最终的训练脚本中,Inception V3 (iNaturalist) 特征向量 预训练模型用于此问题的迁移学习,因为它与上述其他模型相比表现最好**(~95% 的测试准确率超过 5没有微调的时期)。该模型使用 Inception V3 架构并在iNaturalist (iNat) 2017数据集上进行训练,该数据集来自[https://www.inaturalist.org/]的超过 5,000** 种不同的动植物(https://www.inaturalist.org/).相比之下,ImageNet 2012数据集只有 1,000 个类,其中花的类型很少。
使用 TensorFlow Serving 服务花卉分类器
TensorFlow Serving 是一个灵活、高性能的机器学习模型服务系统,专为生产环境而设计。它是TensorFlow Extended (TFX)的一部分,这是一个用于部署生产机器学习 (ML) 管道的端到端平台。TensorFlow Serving ModelServer binary有两种变体:tensorflow-model-server 和 tensorflow-model-server-universal。 TensorFlow Serving ModelServer 支持gRPC API和RESTful API。
在推理代码中,tensorflow-model-server 用于通过 RESTful API 为模型提供服务,模型从 SageMaker 容器中导出。它是一个完全优化的服务器,使用了一些特定于平台的编译器优化,应该是用户的首选。推理代码如下图:
#!/usr/bin/env python
# This file implements the hosting solution, which just starts TensorFlow Model Serving.
import subprocess
import os
TF_SERVING_DEFAULT_PORT = 8501
MODEL_NAME = 'flowers_model'
MODEL_BASE_PATH = '/opt/ml/model'
def start_server():
print('Starting TensorFlow Serving.')
# link the log streams to stdout/err so they will be logged to the container logs
subprocess.check_call(
['ln', '-sf', '/dev/stdout', '/var/log/nginx/access.log'])
subprocess.check_call(
['ln', '-sf', '/dev/stderr', '/var/log/nginx/error.log'])
# start nginx server
nginx = subprocess.Popen(['nginx', '-c', '/opt/ml/code/nginx.conf'])
# start TensorFlow Serving
# https://www.tensorflow.org/serving/api_rest#start_modelserver_with_the_rest_api_endpoint
tf_model_server = subprocess.call(['tensorflow_model_server',
'--rest_api_port=' +
str(TF_SERVING_DEFAULT_PORT),
'--model_name=' + MODEL_NAME,
'--model_base_path=' + MODEL_BASE_PATH])
# The main routine just invokes the start function.
if __name__ == '__main__':
start_server()
为 SageMaker 训练和推理构建自定义 Docker 映像和容器
Amazon SageMaker 利用 Docker 容器来运行所有训练作业和推理终端节点。
Amazon SageMaker 提供支持机器学习框架的预构建 Docker 容器,例如SageMaker Scikit-learn Container,SageMaker XGBoost Container,SageMaker SparkML Serving Container,深度学习容器(TensorFlow、PyTorch、MXNet 和 Chainer)以及SageMaker RL(强化学习)容器用于训练和推理。这些预构建的 SageMaker 容器应该足以用于通用机器学习训练和推理场景。
在某些情况下,预构建的 SageMaker 容器无法支持,例如
-
使用不受支持的机器学习框架版本
-
使用预构建的 SageMaker 容器中不可用的第三方包、库、运行时或依赖项
-
使用自定义机器学习算法
Amazon SageMaker 支持用户为上述高级场景提供的自定义 Docker 映像和容器。
用户可以使用任何编程语言、框架或程序包来构建自己的 Docker 映像和容器,这些映像和容器专为使用 Amazon SageMaker 的机器学习场景量身定制。
在此花卉分类场景中,使用自定义 Docker 镜像和容器进行训练和推理,因为预构建的 SageMaker TensorFlow 容器没有训练所需的包,即 tensorflow_hub 和 **tensorflow_datasets **。下面是用于构建自定义 Docker 映像的 Dockerfile。
# Copyright 2020 Juv Chan. All Rights Reserved.
FROM tensorflow/tensorflow:2.3.0-gpu
LABEL maintainer="Juv Chan <juvchan@hotmail.com>"
RUN apt-get update && apt-get install -y --no-install-recommends nginx curl
RUN pip install --no-cache-dir --upgrade pip tensorflow-hub tensorflow-datasets sagemaker-tensorflow-training
RUN echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | tee /etc/apt/sources.list.d/tensorflow-serving.list
RUN curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | apt-key add -
RUN apt-get update && apt-get install tensorflow-model-server
ENV PATH="/opt/ml/code:${PATH}"
# /opt/ml and all subdirectories are utilized by SageMaker, we use the /code subdirectory to store our user code.
COPY /code /opt/ml/code
WORKDIR /opt/ml/code
RUN chmod 755 serve
下面的 Docker 命令用于构建自定义 Docker 映像,用于此项目的 SageMaker 训练和托管。
docker build ./container/ -t sagemaker-custom-tensorflow-container-gpu:1.0
成功构建 Docker 映像后,使用以下 Docker 命令验证新映像是否按预期列出。
docker images
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--sr4cJ8fk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/875/1%2ANai3DAhGO37qAd8OxTRsSw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--sr4cJ8fk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/875/1%2ANai3DAhGO37qAd8OxTRsSw.png)
本地模式下的 SageMaker 培训
SageMaker Python SDK 支持本地模式,它允许用户创建估计器、训练模型并将它们部署到本地环境。对于想要在 Jupyter Notebook 中使用 SageMaker Python SDK 在云中运行之前在 Jupyter Notebook 中构建、构建、开发和测试他或她的机器学习项目的任何人来说,这非常有用且具有成本效益。
Amazon SageMaker 本地模式支持本地 CPU 实例(单实例和多实例)和本地 GPU 实例(单实例)。它还允许用户通过更改 SageMaker Estimator 对象的 instance_type 参数(注意:此参数以前称为 train\ SageMaker Python SDK 1.x 中的 _instance_type)。其他一切都一样。
在这种情况下,如果可用,则默认使用本地 GPU 实例,否则回退到本地 CPU 实例。请注意,output_path 设置为本地当前目录 (file://.),这会将训练后的模型工件输出到本地当前目录,而不是上传到 Amazon S3。 image_uri 设置为本地构建的本地自定义 Docker 镜像,以便 SageMaker 不会从基于框架和版本的预构建 Docker 镜像中获取。您可以参考最新的SageMaker TensorFlow Estimator和SageMaker Estimator BaseAPI 文档了解完整的详细信息。
此外,可以通过设置 SageMaker Estimator 对象的 hyperparameters 将 hyperparameters 传递给训练脚本。可以设置的超参数取决于训练脚本中使用的超参数。在这种情况下,它们是_'epochs'、'batch_size'和'learning_rate'_。
from sagemaker.tensorflow import TensorFlow
instance_type = 'local_gpu' # For Local GPU training. For Local CPU Training, type = 'local'
gpu = tf.config.list_physical_devices('GPU')
if len(gpu) == 0:
instance_type = 'local'
print(f'Instance type = {instance_type}')
role = 'SageMakerRole' # Import get_execution_role from sagemaker and use get_execution_role() on SageMaker Notebook instance
hyperparams = {'epochs': 5}
tf_local_estimator = TensorFlow(entry_point='train.py', role=role,
instance_count=1, instance_type='local_gpu', output_path='file://.',
image_uri='sagemaker-custom-tensorflow-container-gpu:1.0',
hyperparameters=hyperparams)
tf_local_estimator.fit()
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--BsDWreLP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro .medium.com/max/875/1%2ApaJHgdSvSbGlG8uHlZf77Q.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--BsDWreLP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro .medium.com/max/875/1%2ApaJHgdSvSbGlG8uHlZf77Q.png)
SageMaker 本地端点部署和模型服务
SageMaker 训练作业完成后,运行该作业的 Docker 容器将退出。成功完成训练后,可以通过调用 SageMaker Estimator 对象的 deploy 方法并将 instance_type 设置为本地实例类型,将训练后的模型部署到本地 SageMaker 端点 (即 local_gpu 或 local)。
将启动一个新的 Docker 容器来运行自定义推理代码(即 serve 程序),该代码运行 TensorFlow Serving ModelServer 为模型提供实时推理服务。 ModelServer 将以 RESTful API 模式提供服务,并期望 JSON 格式的请求和响应数据。当本地 SageMaker 端点部署成功后,用户可以向端点发出预测请求并实时获得预测响应。
tf_local_predictor = tf_local_estimator.deploy(initial_instance_count=1,
instance_type=instance_type)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--RG_IIdPn--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// miro.medium.com/max/1250/1%2Ax5YU3qgptmEoZ9tM9D_uZw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--RG_IIdPn--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// miro.medium.com/max/1250/1%2Ax5YU3qgptmEoZ9tM9D_uZw.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--iIoYPdeu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/1250/1%2ArPFlzGoHZvNuvc-fu1aMRQ.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--iIoYPdeu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/1250/1%2ArPFlzGoHZvNuvc-fu1aMRQ.png)
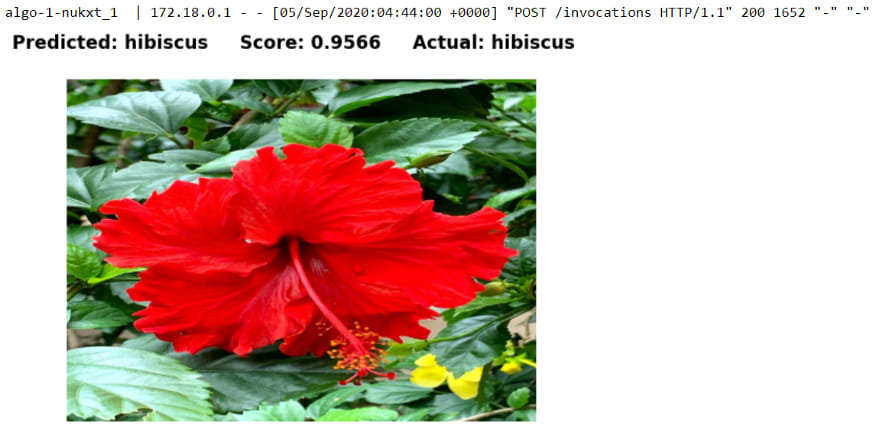
使用外部花卉图像来源预测花卉类型
为了使用 accuracy 指标评估此花卉分类模型的性能,使用了来自外部来源的不同花卉图像,这些图像独立于 oxford_flowers102 数据集。这些测试图像的主要来源来自提供高质量免费图像的网站,例如unsplash.com和pixabay.com以及自拍照片。
def preprocess_input(image_path):
if (os.path.exists(image_path)):
originalImage = Image.open(image_path)
image = originalImage.resize((299, 299))
image = np.asarray(image) / 255.
image = tf.expand_dims(image,0)
input_data = {'instances': np.asarray(image).astype(float)}
return input_data
else:
print(f'{image_path} does not exist!\n')
return None
def display(image, predicted_label, confidence_score, actual_label):
fig, ax = plt.subplots(figsize=(8, 6))
fig.suptitle(f'Predicted: {predicted_label} Score: {confidence_score} Actual: {actual_label}', \
fontsize='xx-large', fontweight='extra bold')
ax.imshow(image, aspect='auto')
ax.axis('off')
plt.show()
def predict_flower_type(image_path, actual_label):
input_data = preprocess_input(image_path)
if (input_data):
result = tf_local_predictor.predict(input_data)
CLASSES = info.features['label'].names
predicted_class_idx = np.argmax(result['predictions'][0], axis=-1)
predicted_class_label = CLASSES[predicted_class_idx]
predicted_score = round(result['predictions'][0][predicted_class_idx], 4)
original_image = Image.open(image_path)
display(original_image, predicted_class_label, predicted_score, actual_label)
else:
print(f'Unable to predict {image_path}!\n')
return None
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--OrYgNH1l--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium. com/max/875/1%2AK7XY4BPsbJCYGN46XpwsQw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--OrYgNH1l--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium. com/max/875/1%2AK7XY4BPsbJCYGN46XpwsQw.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--JEk_vKDQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2AcoY6aq4ENGZXq48o2rxxRg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--JEk_vKDQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2AcoY6aq4ENGZXq48o2rxxRg.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--rwxTt4xv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2ASK8hozPQhpoGenkQlFNQtg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--rwxTt4xv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2ASK8hozPQhpoGenkQlFNQtg.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--GecbYds6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2Ap2-h_SGAdzh_Xsgjik2W9w.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--GecbYds6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2Ap2-h_SGAdzh_Xsgjik2W9w.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Vqk4Vb4X--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2Ak-QnzcsjwMAk4J1uWVxvvg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Vqk4Vb4X--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2Ak-QnzcsjwMAk4J1uWVxvvg.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--XAfFXuK5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2Axr_vNWqQ7zsTpnOdlerTEA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--XAfFXuK5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2Axr_vNWqQ7zsTpnOdlerTEA.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--A7tnwCQZ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2AMeZNInB-awNUgru4KIcqlw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--A7tnwCQZ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium.com /max/875/1%2AMeZNInB-awNUgru4KIcqlw.png)
总结
最终的花卉分类模型根据一组来自外部来源的不同类型的真实花卉图像进行评估,以测试它对看不见的数据的泛化程度。结果,该模型能够正确分类所有看不见的花朵图像。模型大小为 80 MB,对于生产中的边缘部署,可以认为是相当紧凑和高效的。总而言之,该模型似乎能够在给定的一小部分看不见的数据上表现良好,并且对于生产边缘或 Web 部署而言相当紧凑。
建议的增强功能
由于时间和资源的限制,这里的解决方案可能无法提供最佳实践或最佳设计和实现。
以下是一些对任何有兴趣为改进当前解决方案做出贡献的人可能有用的想法。
-
应用数据增强,即对训练数据集进行随机(但现实的)变换,如旋转、翻转、裁剪、亮度和对比度等,以增加其大小和多样性。
-
使用Keras 预处理层。Keras提供预处理层,例如图像预处理层和图像数据增强预处理层,它们可以组合并作为 Keras SavedModel 的一部分导出。因此,模型可以接受原始图像作为输入。
-
将 TensorFlow 模型(SavedModel 格式)转换为TensorFlow Lite模型 (.tflite),以便在移动和 IoT 设备上进行边缘部署和优化。
-
优化 TensorFlow Serving 签名(SavedModel 中的SignatureDefs)以最小化预测输出数据结构和负载大小。当前模型预测输出返回所有 102 种花卉类型的预测类别和分数。
-
使用TensorFlow Profiler工具来跟踪、分析和优化 TensorFlow 模型的性能。
-
使用Intel Distribution of OpenVINO toolkit用于模型在 CPU、iGPU、VPU 或 FPGA 等 Intel 硬件上的优化和高性能推理。
-
优化Docker镜像大小。
-
为 TensorFlow 训练脚本添加单元测试。
-
为 Dockerfile 添加单元测试。
后续步骤
在本地环境中测试机器学习工作流按预期工作后,下一步是将此工作流完全迁移到AWS Cloud和Amazon SageMaker Notebook Instance。在下一篇指南中,我将演示如何调整这个 Jupyter notebook 以在 SageMaker Notebook Instance 上运行,以及如何将自定义 Docker 镜像推送到Amazon Elastic Container Registry (ECR)以便整个工作流程完全在 AWS 中托管和管理。
清理
最后清理过时的资源或会话以回收计算、内存和存储资源以及在云或分布式环境中清理时节省成本始终是最佳实践。对于这种情况,将删除本地 SageMaker 推理端点以及 SageMaker 容器,如下所示。
tf_local_predictor.delete_endpoint()
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--atfSl4nm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/704/1%2A30DTqcXLfEZsnQqKt7QM-Q.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--atfSl4nm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/704/1%2A30DTqcXLfEZsnQqKt7QM-Q.png)
docker container ls -a
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--oHOIt27E--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium. com/max/1250/1%2AYznAb1ZJadpP7BqaB7pTdg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--oHOIt27E--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium. com/max/1250/1%2AYznAb1ZJadpP7BqaB7pTdg.png)
docker rm $(docker ps -a -q) docker container ls -a
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--qj_Q3ftC--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/1250/1%2AeRmIe9xQCKroPU9Y8nGTxw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--qj_Q3ftC--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/1250/1%2AeRmIe9xQCKroPU9Y8nGTxw.png)

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献35531条内容
已为社区贡献35531条内容

所有评论(0)