多个 Postgres SELECT 进程(django GET 请求)卡住,导致 100% CPU 使用率
问题:多个 Postgres SELECT 进程(django GET 请求)卡住,导致 100% CPU 使用率 我会尽量在这里提供尽可能多的信息。尽管解决方案会很棒,但我只想获得有关如何解决问题的指导。如何查看更有用的日志文件等。因为我是服务器维护的新手。欢迎任何建议。 以下是按时间顺序发生的事情: 我正在运行 2 个 digitalocean 液滴(Ubuntu 14.04 VPS) Dro
问题:多个 Postgres SELECT 进程(django GET 请求)卡住,导致 100% CPU 使用率
我会尽量在这里提供尽可能多的信息。尽管解决方案会很棒,但我只想获得有关如何解决问题的指导。如何查看更有用的日志文件等。因为我是服务器维护的新手。欢迎任何建议。
以下是按时间顺序发生的事情:
-
我正在运行 2 个 digitalocean 液滴(Ubuntu 14.04 VPS)
-
Droplet #1 运行 django、nginx、gunicorn
-
Droplet #2 运行 postgres
-
一切正常运行了一个月,突然 postgres droplet CPU 使用率飙升到 100%
-
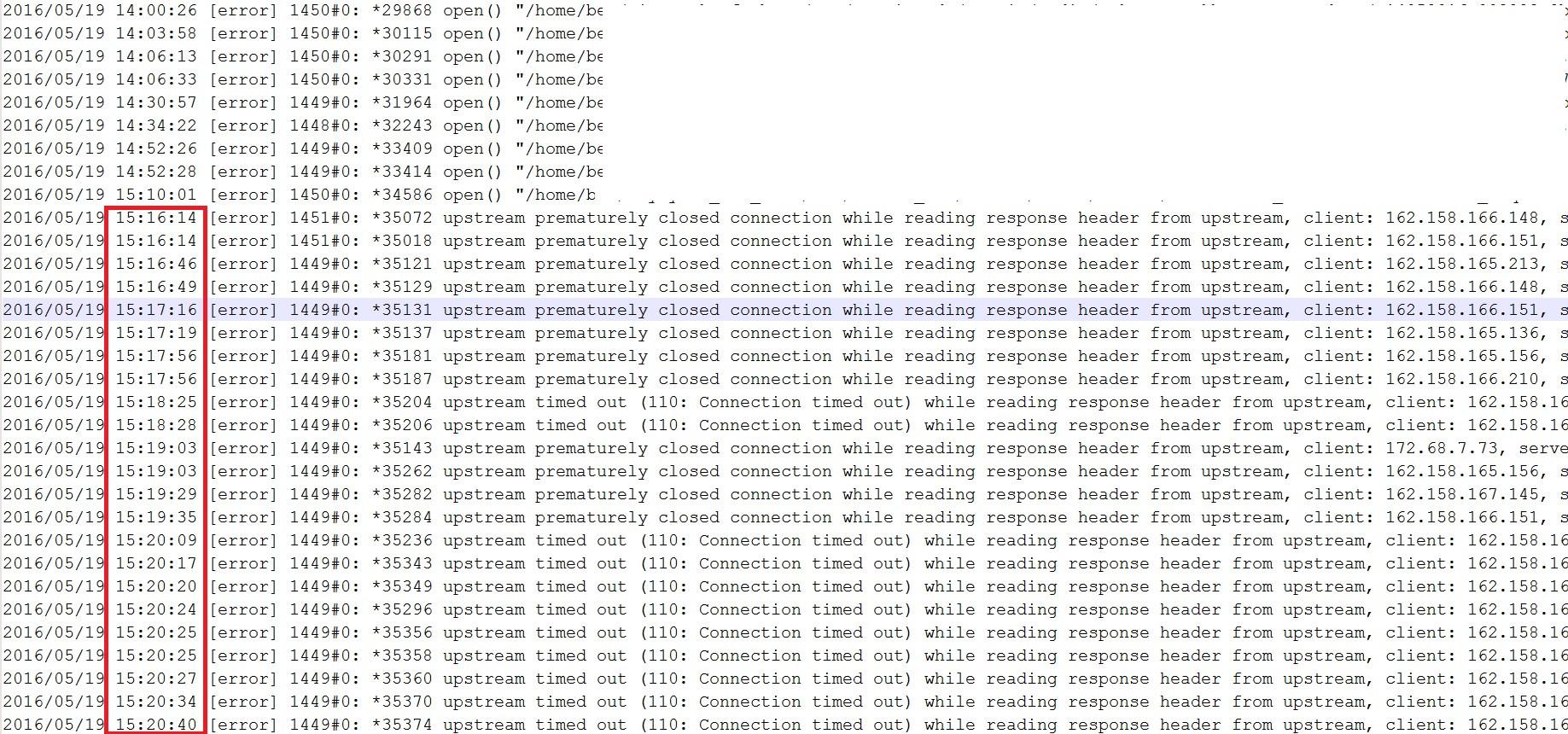
发生这种情况时,您可以看到 htop 日志。我附上了截图
-
另一个截图是 nginx error.log,你可以看到问题开始于 15:56:14 我用红框突出显示
-
sudo poweroff the Postgres droplet 并重新启动它并不能解决问题
-
将 postgres droplet 恢复到我上次的备份(20 小时前)解决了这个问题,但它再次发生。这是两天内的第 7 次
我会继续研究并提供更多信息。同时欢迎任何意见。
谢谢你。

2016 年 5 月 20 日更新
-
按照 e4c5 的建议在 Postgres 服务器上启用慢查询日志记录
-
6 小时后,服务器在上午 8:07 再次冻结(100% CPU 使用率)。我附上了所有相关的截图
-
如果在冻结期间尝试访问该站点,浏览器会显示 502 错误
-
sudo service restart postgresql(和gunicorn,django服务器上的nginx)没有**修复冻结(我认为这是一个非常有趣的点) -
但是,将 Postgres 服务器恢复到我以前的备份(现在 2 天前)确实修复了冻结
-
罪魁祸首 Postgres log 消息是 Could not send data to client: Broken Pipe
-
罪魁祸首 Nginx log 消息是一个简单的 django-rest-framework
api 调用仅返回 20 个项目(每个项目都有一些外键数据查询)
Update#2 2016 年 5 月 20 日 发生冻结时,我尝试按时间顺序执行以下操作(关闭所有内容并一个接一个地重新打开)
-
sudo service stop postgresql--> cpu使用率下降到0-10% -
sudo service stop gunicorn--> cpu使用率保持在0-10% -
sudo service stop nginx--> cpu 使用率保持在 0-10% -
sudo service restart postgresql--> cpu 使用率保持在 0-10% -
sudo service restart gunicorn--> cpu 使用率保持在 0-10% -
sudo service restart nginx--> cpu 使用率上升到 100% 并保持在那里
那么这与服务器负载或长查询时间无关吗?
这非常令人困惑,因为如果我将数据库恢复到我的最新备份(2 天前),即使没有接触 nginx/gunicorn/django 服务器,一切都会重新上线......
2016 年 6 月 8 日更新我打开了慢查询日志记录。将其设置为记录耗时超过 1000 毫秒的查询。
我得到这个查询多次出现在日志中。
SELECT
"products_product"."id",
"products_product"."seller_id",
"products_product"."priority",
"products_product"."media",
"products_product"."active",
"products_product"."title",
"products_product"."slug",
"products_product"."description",
"products_product"."price",
"products_product"."sale_active",
"products_product"."sale_price",
"products_product"."timestamp",
"products_product"."updated",
"products_product"."draft",
"products_product"."hitcount",
"products_product"."finished",
"products_product"."is_marang_offline",
"products_product"."is_seller_beta_program",
COUNT("products_video"."id") AS "num_video"
FROM "products_product"
LEFT OUTER JOIN "products_video" ON ( "products_product"."id" = "products_video"."product_id" )
WHERE ("products_product"."draft" = false AND "products_product"."finished" = true)
GROUP BY
"products_product"."id",
"products_product"."seller_id",
"products_product"."priority",
"products_product"."media",
"products_product"."active",
"products_product"."title",
"products_product"."slug",
"products_product"."description",
"products_product"."price",
"products_product"."sale_active",
"products_product"."sale_price",
"products_product"."timestamp",
"products_product"."updated",
"products_product"."draft",
"products_product"."hitcount",
"products_product"."finished",
"products_product"."is_marang_offline",
"products_product"."is_seller_beta_program"
HAVING COUNT("products_video"."id") >= 8
ORDER BY "products_product"."priority" DESC, "products_product"."hitcount" DESC
LIMIT 100
我知道这是一个丑陋的查询(由 django 聚合生成)。在英语中,这个查询只是意味着**“给我一个包含超过 8 个视频的产品列表”。**
这里是这个查询的 EXPLAIN 输出:
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=351.90..358.40 rows=100 width=933)
-> GroupAggregate (cost=351.90..364.06 rows=187 width=933)
Filter: (count(products_video.id) >= 8)
-> Sort (cost=351.90..352.37 rows=187 width=933)
Sort Key: products_product.priority, products_product.hitcount, products_product.id, products_product.seller_id, products_product.media, products_product.active, products_product.title, products_product.slug, products_product.description, products_product.price, products_product.sale_active, products_product.sale_price, products_product."timestamp", products_product.updated, products_product.draft, products_product.finished, products_product.is_marang_offline, products_product.is_seller_beta_program
-> Hash Right Join (cost=88.79..344.84 rows=187 width=933)
Hash Cond: (products_video.product_id = products_product.id)
-> Seq Scan on products_video (cost=0.00..245.41 rows=2341 width=8)
-> Hash (cost=88.26..88.26 rows=42 width=929)
-> Seq Scan on products_product (cost=0.00..88.26 rows=42 width=929)
Filter: ((NOT draft) AND finished)
(11排)
--- 2016 年 6 月 8 日更新 #2 --- 由于很多人提出了很多建议。因此,我将尝试逐个应用修复程序并定期报告。
@e4c5 这是您需要的信息:
您可以将我的网站想像成在线课程市场 Udemy。有“产品”(课程)。每个产品都包含许多视频。用户可以对产品页面本身和每个视频进行评论。
在许多情况下,我需要按获得的总评论数查询产品订单列表(产品评论和该产品每个视频的评论总和)
对应于上述 EXPLAIN 输出的 django 查询:
all_products_exclude_draft = Product.objects.all().filter(draft=False)
products_that_contain_more_than_8_videos = all_products_exclude_draft.annotate(num_video=Count('video')).filter(finished=True, num_video__gte=8).order_by('timestamp')[:30]
我刚刚注意到我(或我团队中的其他一些开发人员)使用这两条 python 行两次访问数据库。
这是产品和视频的 django 模型:
from django_model_changes import ChangesMixin
class Product(ChangesMixin, models.Model):
class Meta:
ordering = ['-priority', '-hitcount']
seller = models.ForeignKey(SellerAccount)
priority = models.PositiveSmallIntegerField(default=1)
media = models.ImageField(blank=True,
null=True,
upload_to=download_media_location,
default=settings.MEDIA_ROOT + '/images/default_icon.png',
storage=FileSystemStorage(location=settings.MEDIA_ROOT))
active = models.BooleanField(default=True)
title = models.CharField(max_length=500)
slug = models.SlugField(max_length=200, blank=True, unique=True)
description = models.TextField()
product_coin_price = models.IntegerField(default=0)
sale_active = models.BooleanField(default=False)
sale_price = models.IntegerField(default=0, null=True, blank=True) #100.00
timestamp = models.DateTimeField(auto_now_add=True, auto_now=False, null=True)
updated = models.DateTimeField(auto_now_add=False, auto_now=True, null=True)
draft = models.BooleanField(default=True)
hitcount = models.IntegerField(default=0)
finished = models.BooleanField(default=False)
is_marang_offline = models.BooleanField(default=False)
is_seller_beta_program = models.BooleanField(default=False)
def __unicode__(self):
return self.title
def get_avg_rating(self):
rating_avg = self.productrating_set.aggregate(Avg("rating"), Count("rating"))
return rating_avg
def get_total_comment_count(self):
comment_count = self.video_set.aggregate(Count("comment"))
comment_count['comment__count'] += self.comment_set.count()
return comment_count
def get_total_hitcount(self):
amount = self.hitcount
for video in self.video_set.all():
amount += video.hitcount
return amount
def get_absolute_url(self):
view_name = "products:detail_slug"
return reverse(view_name, kwargs={"slug": self.slug})
def get_product_share_link(self):
full_url = "%s%s" %(settings.FULL_DOMAIN_NAME, self.get_absolute_url())
return full_url
def get_edit_url(self):
view_name = "sellers:product_edit"
return reverse(view_name, kwargs={"pk": self.id})
def get_video_list_url(self):
view_name = "sellers:video_list"
return reverse(view_name, kwargs={"pk": self.id})
def get_product_delete_url(self):
view_name = "products:product_delete"
return reverse(view_name, kwargs={"pk": self.id})
@property
def get_price(self):
if self.sale_price and self.sale_active:
return self.sale_price
return self.product_coin_price
@property
def video_count(self):
videoCount = self.video_set.count()
return videoCount
class Video(models.Model):
seller = models.ForeignKey(SellerAccount)
title = models.CharField(max_length=500)
slug = models.SlugField(max_length=200, null=True, blank=True)
story = models.TextField(default=" ")
chapter_number = models.PositiveSmallIntegerField(default=1)
active = models.BooleanField(default=True)
featured = models.BooleanField(default=False)
product = models.ForeignKey(Product, null=True)
timestamp = models.DateTimeField(auto_now_add=True, auto_now=False, null=True)
updated = models.DateTimeField(auto_now_add=False, auto_now=True, null=True)
draft = models.BooleanField(default=True)
hitcount = models.IntegerField(default=0)
objects = VideoManager()
class Meta:
unique_together = ('slug', 'product')
ordering = ['chapter_number', 'timestamp']
def __unicode__(self):
return self.title
def get_comment_count(self):
comment_count = self.comment_set.all_jing_jing().count()
return comment_count
def get_create_chapter_url(self):
return reverse("sellers:video_create", kwargs={"pk": self.id})
def get_edit_url(self):
view_name = "sellers:video_update"
return reverse(view_name, kwargs={"pk": self.id})
def get_video_delete_url(self):
view_name = "products:video_delete"
return reverse(view_name, kwargs={"pk": self.id})
def get_absolute_url(self):
try:
return reverse("products:video_detail", kwargs={"product_slug": self.product.slug, "pk": self.id})
except:
return "/"
def get_video_share_link(self):
full_url = "%s%s" %(settings.FULL_DOMAIN_NAME, self.get_absolute_url())
return full_url
def get_next_url(self):
current_product = self.product
videos = current_product.video_set.all().filter(chapter_number__gt=self.chapter_number)
next_vid = None
if len(videos) >= 1:
try:
next_vid = videos[0].get_absolute_url()
except IndexError:
next_vid = None
return next_vid
def get_previous_url(self):
current_product = self.product
videos = current_product.video_set.all().filter(chapter_number__lt=self.chapter_number).reverse()
next_vid = None
if len(videos) >= 1:
try:
next_vid = videos[0].get_absolute_url()
except IndexError:
next_vid = None
return next_vid
这是我从命令中获得的 Product 和 Video 表的索引:
my_database_name=# \di
注意:这是经过Photoshop处理的,还包括其他一些模型。 
--- 2016 年 6 月 8 日更新 #3 --- @Jerzyk 正如你所怀疑的那样。在我再次检查所有代码后,我发现我确实做了一个“内存切片”:我试图通过这样做来打乱前 10 个结果:
def get_queryset(self):
all_product_list = Product.objects.all().filter(draft=False).annotate(
num_video=Count(
Case(
When(
video__draft=False,
then=1,
)
)
)
).order_by('-priority', '-num_video', '-hitcount')
the_first_10_products = list(all_product_list[:10])
the_11th_product_onwards = list(all_product_list[10:])
random.shuffle(copy)
finalList = the_first_10_products + the_11th_product_onwards
注意:在上面的代码中,我需要计算未处于草稿状态的视频数量。
所以这也是我需要解决的问题之一。谢谢。 >_<
--- 以下是相关截图---
Postgres 发生冻结时的日志(log_min_duration u003d 500 毫秒)
Postgres 日志(接上图) 
Nginx error.log在同一时间段
DigitalOcean CPU 使用率图表就在冻结前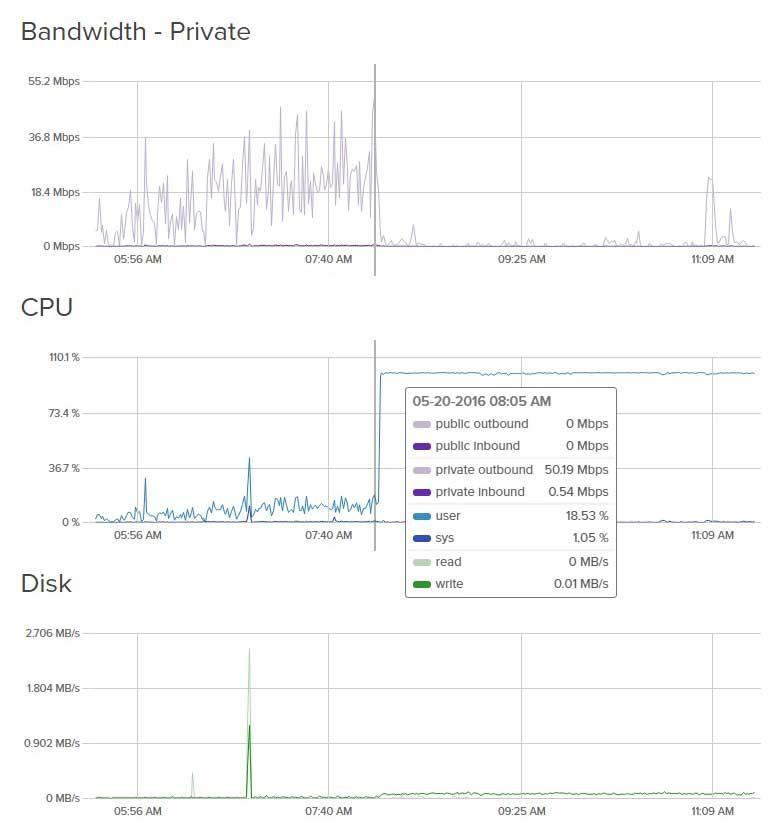
DigitalOcean 冻结后的 CPU 使用情况图
解答
我们可以得出结论,您的问题是由相关的慢查询引起的。就其本身而言,查询的每次运行似乎都不会慢到导致超时。然而,这些查询中的几个可能同时执行,这可能导致崩溃。您可以做两件事来加快速度。
1) 缓存结果
可以缓存长时间运行的查询的结果。
from django.core.cache import cache
def get_8x_videos():
cache_key = 'products_videos_join'
result = cache.get(cache_key, None)
if not result:
all_products_exclude_draft = Product.objects.all().filter(draft=False)
result = all_products_exclude_draft.annotate(num_video=Count('video')).filter(finished=True, num_video__gte=8).order_by('timestamp')[:30]
result = Product.objects.annotate('YOUR LONG QUERY HERE')
cache.set(cache_key, result)
return result
此查询现在来自 memcache(或您用于缓存的任何内容),这意味着如果您对快速连续使用它的页面有两个连续的命中,则第二个对数据库没有影响。您可以控制对象在内存中缓存的时间。
2) 优化查询
从解释中跳出来的第一件事是您正在对products_products和product_videos表进行顺序扫描。通常顺序扫描不如索引扫描好。然而,索引扫描_可能不会_用于此查询,因为您有COUNT()和HAVING``COUNT()子句以及大量的GROUP BY子句。
更新:
您的查询有 LEFT OUTER JOIN,INNER JOIN 或子查询可能会更快,为了做到这一点,我们需要认识到product_id上Video表上的分组可以为我们提供一组视频至少 8 个产品。
inner = RawSQL('SELECT id from product_videos GROUP BY product_id HAVING COUNT(product_id) > 1',params=[])
Product.objects.filter(id__in=b)
上面消除了 LEFT OUTER JOIN 并引入了一个子查询。但是,这并不能轻松访问每个产品的实际视频数量,因此当前形式的此查询可能无法完全使用。
3) 改进指标
虽然在draft和finished列上创建索引可能很诱人,但这将是徒劳的,因为这些列没有足够的基数作为索引的良好候选者。但是,仍然可以创建条件索引。同样,只有在看到您的表格后才能得出结论。

开发云社区提供前沿行业资讯和优质的学习知识,同时提供优质稳定、价格优惠的云主机、数据库、网络、云储存等云服务产品
更多推荐
 0
0 0
0- 0



 已为社区贡献15557条内容
已为社区贡献15557条内容

所有评论(0)