
本地模型部署工具-Ollama
如果需要部署本地开源大模型并将其用于提供推理服务,那么推荐使用 Ollama 这款工具来作为大模型运行与推理的管理工具。参考:https://github.com/ollama/ollama/blob/main/docs/faq.md。进入终端,使用如下命令,查看是否安装成功。, 可以通过设置环境变量的方式更改默认的服务端口。Ollama 默认服务器端口。
·
文章目录
本地模型部署工具-Ollama
一、基于 Ollama 部署本地开源大模型
如果需要部署本地开源大模型并将其用于提供推理服务,那么推荐使用 Ollama 这款工具来作为大模型运行与推理的管理工具。
好处:
- 安装、使用简单。
- 可以利用普通 CPU 进行推理(也支持 GPU 推理)。
官网地址: https://ollama.com/
1. Ollama 本地安装
安装完成。进入终端,使用如下命令,查看是否安装成功。
ollama --version
# 如果出现
# Warning: could not connect to a running Ollama instance
# Warning: client version is 0.1.48
# 安装的 ollama 未启动 点击启动即可
# 正常输出
# ollama version is 0.1.48
2. Ollama终端交互
模型查询入口:
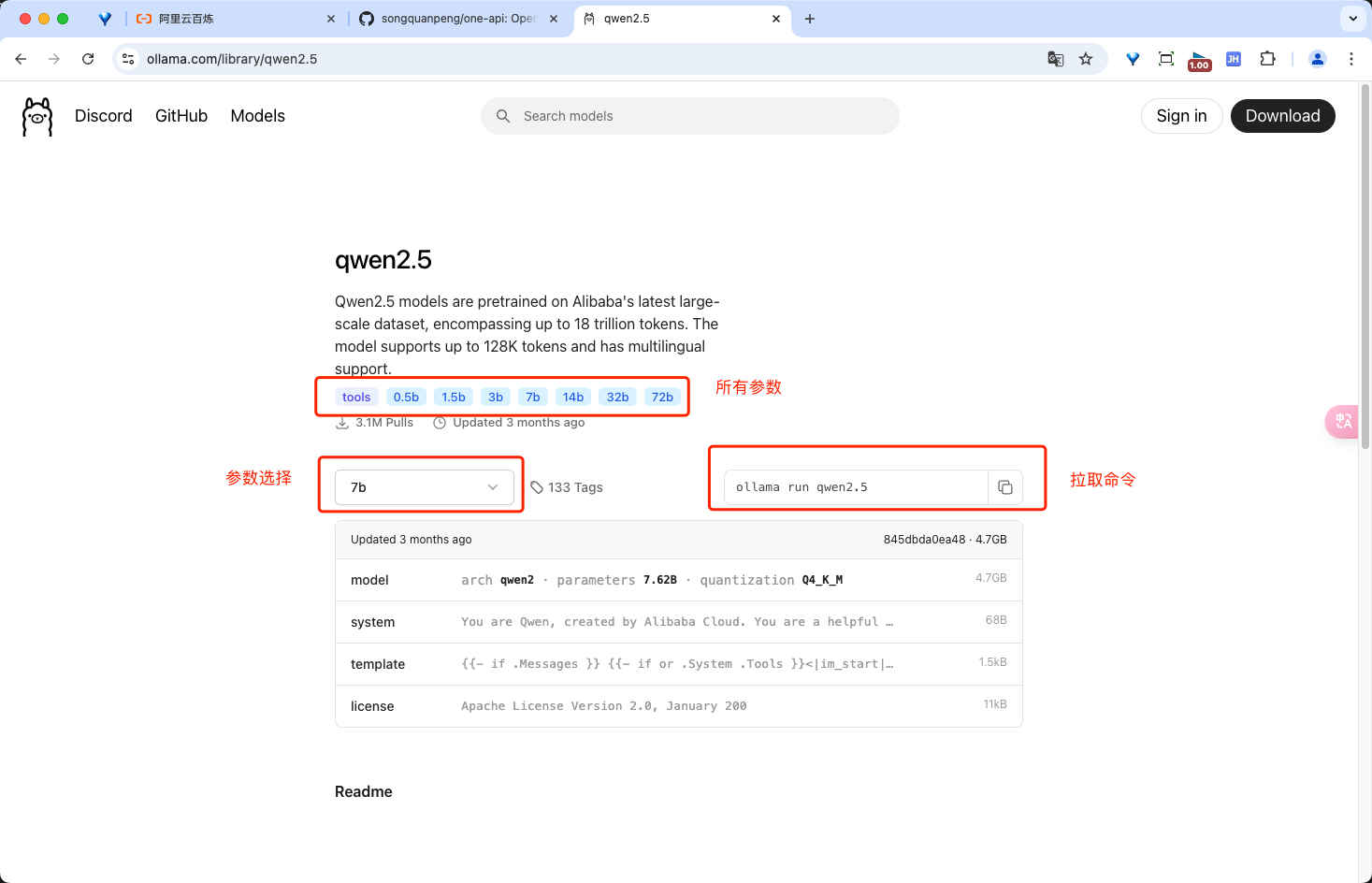
拉取模型并运行:

退出本地模型终端交互:
/bye
3. 使用API服务访问
Ollama 默认服务器端口
11434, 可以通过设置环境变量的方式更改默认的服务端口。OLLAMA_HOST=:11435 ollama serve
验证 Ollama 的 API 服务器能否正常工作:
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2:0.5b",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你好呀!"
}
]
}'
# 返回
{"id":"chatcmpl-19","object":"chat.completion","created":1736223721,"model":"qwen2:0.5b","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"你好,很高兴为你提供帮助。有什么我可以帮到您的?"},"finish_reason":"stop"}],"usage":{"prompt_tokens":22,"completion_tokens":14,"total_tokens":36}}
4. 常用命令
# 拉取模型 用于更新本地模型。只会拉取 diff
ollama pull llama3.2
# 删除模型
ollama rm llama3.2
# 复制模型
ollama cp llama3.2 my-model
# 显示模型信息
ollama show llama3.2
# 列出计算机上的模型
ollama list
# 列出当前加载的模型
# 100% GPU means the model was loaded entirely into the GPU
# 100% CPU means the model was loaded entirely in system memory
# 48%/52% CPU/GPU means the model was loaded partially onto both the GPU and into system memory
ollama ps
# 停止当前正在运行的模型
ollama stop llama3.2
# 启动 Ollama 当您想在不运行桌面应用程序的情况下启动 ollama 时,可以使用 ollama serve。
ollama serve
5. 常见问题
参考:https://github.com/ollama/ollama/blob/main/docs/faq.md
5.1 设置本地存储模型路径(MacOS)
# 设置
launchctl setenv OLLAMA_MODELS /Users/yangdong/tools/llm/models/ollama-models
# 读取
launchctl getenv OLLAMA_MODELS
# 卸载
launchctl unsetenv OLLAMA_MODELS
# 配置完成重启 ollama app
# 参考:https://dev.to/hamed0406/how-to-change-place-of-saving-models-on-ollama-4ko8
5.2 设置 API 请求 HOST
# 设置
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
# 读取
launchctl getenv OLLAMA_HOST
5.3 如何指定上下文窗口大小?
# 默认情况下,Ollama 使用的上下文窗口大小为 2048 个令牌。
# api 接口 参数配置
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2:0.5b",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你好呀!"
}
],
"options": {
"num_ctx": 4096
}
}'
# ollama run /set parameter num_ctx 4096
# 参考:https://zhuanlan.zhihu.com/p/719200177 有详细原理讲述
# 参考:https://blog.csdn.net/YiHanXii/article/details/143176687 实操相对简单

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)