
OpenAI 发布GPT-4——全网抢先体验
OpenAI 发布GPT-4
最近 OpenAI 犹如开挂一般,上周才刚刚推出GPT-3.5-Turbo API,今天凌晨再次祭出GPT-4这个目前最先进的多模态预训练大模型。与上一代GPT3.5相比,GPT-4最大的飞跃是增加了识图能力,并且回答准确性也得到显著提高。GPT-4在多个专业和学术基准测试中展现出令人印象深刻的表现,有时甚至达到了人类水平。GPT-4 的关键特性之一是它能够理解和分析视觉和文本信息。通过结合这些模式,该模型能够对各种任务生成更准确、更细致的回答,例如图像说明或问题回答。此外,GPT-4 能够从大量数据中学习,并适应不同的上下文,使其成为自然语言处理、计算机视觉和机器学习等许多领域中非常有价值的工具。
GPT-4的能力

虽然GPT-4是在其前身GPT-3.5的基础上升级而来,但是一些微妙的差异使得GPT-4可能颠覆整个游戏规则。
第一眼看上去,在一些随意交谈中很难看出GPT-3.5和GPT-4之间的区别。然而,当你让模型完成一些复杂的任务时,区别就显现出来了。GPT-4比GPT-3.5更可靠、更具创造力,并且能够处理更细微的指令。GPT-4最令人印象深刻的功能之一是它能够理解上下文并生成与当前情况更相关的响应。例如,如果你问它一个关于特定主题的问题,它能够考虑到对话的背景,并提供一个更准确和合情的答案。GPT-4的另一个显著改进是它的创造力。它可以对提示产生更具想象力和独创性的响应,使其成为作家、艺术家和任何想要挖掘其创造性一面工作者的绝佳工具。

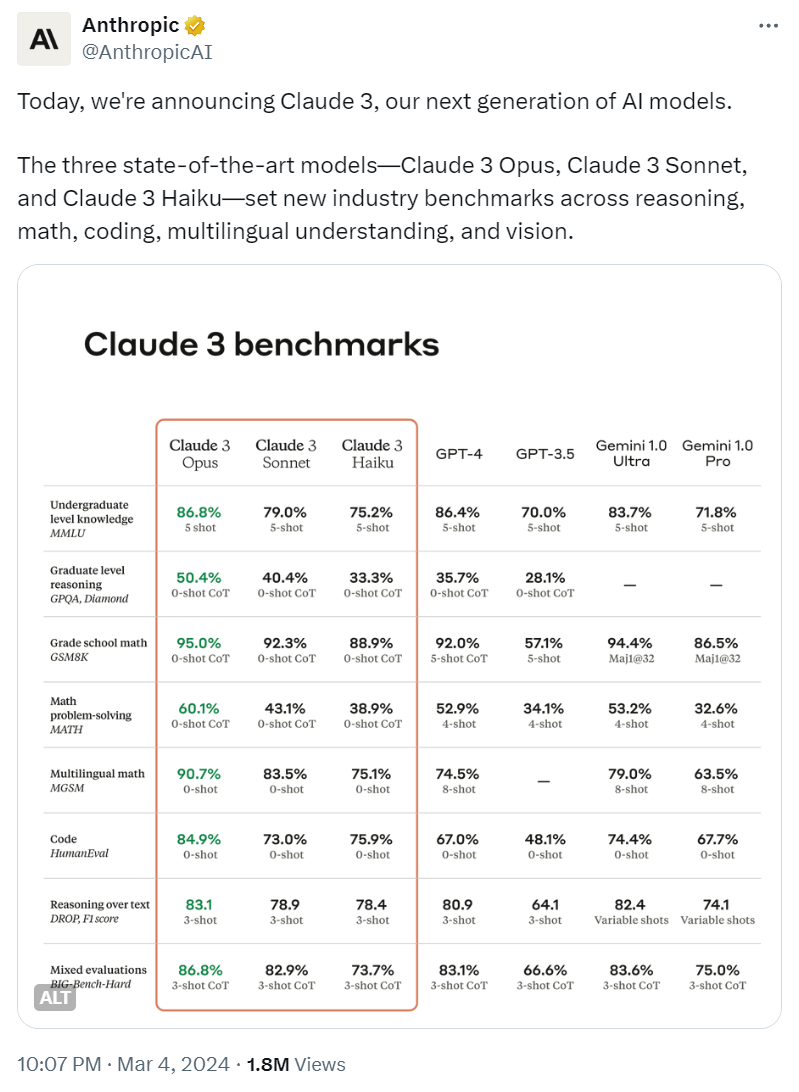
我们具体看看 GPT-3 和 GPT-4 之间令人兴奋的区别,下图是 GPT-3 和 GPT-4 在各种基准测试中的表现对比:

从测试数据上看,GPT-4 比 GPT-3 整体好40%,在超过一半的测试中 GPT-4 比 GPT-3 有飞跃性进步。
再给大家看一个我个人认为很神奇的案例:给出食材,让GPT-4食谱。

上面案例展示了GPT-4良好的图像理解能力。
对GPT-3.5错误的修正
之前ChatGPT在很多问题上表现并不理想,为此我专门针对ChatGPT过去表现不佳的问题以及我关注的使用场景对GPT-4做了专门测试。
链式推理
GPT-3.5在一些非常复杂的问题,需要多条推理链的问题上,经常会要求提供更多信息。而GPT-4明显改进链式推理能力,在多推理链问题上表现良好。
GPT-3.5

GPT-4

逻辑谬误
GPT-3.5经常会在一些简单问题上犯逻辑错误,出现这种问题一般是由于问题中夹杂着一些无用的干扰项,比如:”蓝盒子里有一个苹果,蓝盒子里还有一个红盒子,红盒子有个盖子,请问我要如何取出苹果?“。其中”红色盒子有个盖子“就是无用干扰信息,GPT-3.5会给出完全荒谬的回答:
GPT-3.5
而GPT-4可以给出相对合理的答案,且很清楚地说明并避开了问题中的陷阱。
GPT-4
数学能力
GPT-3.5的数学能力广受诟病,甚至在一些简单的小学数学题上频频出错。比如:”我今年6岁,妹妹年龄是我的一半。那么当我90岁时,妹妹多少岁?“
GPT-3.5
GPT-3.5煞有介事的一步一步推理计算,最后给出45岁的错误答案。而GPT-4则修正了这方面的缺陷:
GPT-4
如何访问GPT-4
目前,ChatGPT Plus 会员可以通过 chat.openai.com 访问 GPT-4,但有使用上限。

在进入ChatGPT界面后,用户可以选择使用的模型。有3个模型可以选择

OpenAI很贴心的用直观可视化的方式对比了三个模型。

从官方给出的功能性能对比指引可以看出,GPT-4在推理能力和简明扼要方面明显由于GPT-3.5。
GPT-4的API与GPT-3.5的接口一致,不过目前需要申请开放。我已经第一时间加入了waitlist,等审批通过后再位大家带来GPT-4的接口使用体验报告。

总结
总的来说,GPT-4在推理能力上比GPT-3.5进步巨大,很多之前的问题都得到了修正和改良。我还没有测试GPT-4的多模能力,后面我会继续进行更多的测试,并即时更新文章分享给大家。

长江两岸老火锅,共聚山城开发者!We Want You!
更多推荐

 76
76 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)