知识图谱学习记录
在计算机科学中,图形作为一种特定的数据结构,用于表达数据之间的复杂关系,如社交关系、组织架构、交通信息、网络拓扑等等。在图计算中,基本的数据结构表达式是:G=(VE)V=vertex(节点E=edge(边。图形结构的数据结构一般以节点和边来表现,也可以在节点上增加键值对属性。图数据库是 NoSQL(非关系型数据库 Q)的一种,它应用图形数据结构的特点(节点、属性和边)存储数据实体和相互之间的关系信
·
1. 知识图谱的定义
知识图谱是一种以图结构(Graph)形式表示知识的数据库,其中知识被组织成实体(Entities)、关系(Relations)和属性(Attributes)的网络。简单来说,它像一张巨大的“关系网”,每个节点代表一个真实世界的物体、概念或事件(如“苹果公司”或“埃菲尔铁塔”),边则表示它们之间的关系(如“创始人是乔布斯”或“位于巴黎”)。
- 核心特点:
- 结构化:不同于传统的文本数据,知识图谱将信息转化为可计算的结构,便于机器理解和推理。
- 语义性:它强调语义(Semantics),即不仅仅存储数据,还能表达含义,支持复杂查询和推理。
- 动态性:知识图谱可以不断更新和扩展,适应新知识的加入。
知识图谱的起源可以追溯到语义网(Semantic Web)的理念,由蒂姆·伯纳斯-李(Tim Berners-Lee)提出,旨在让机器更好地理解人类知识。
2. 历史背景和发展
- 早期起源(20世纪70-80年代):知识图谱的概念源于人工智能中的“知识表示”(Knowledge Representation)。例如,1970年代的专家系统(如MYCIN)使用了规则和框架来表示知识,但那时还不是图形式。
- 语义网时代(2000年代):2001年,W3C(万维网联盟)提出语义网标准,包括RDF(Resource Description Framework)和OWL(Web Ontology Language),这些奠定了知识图谱的技术基础。
- 现代爆发(2010年代至今):2012年,Google推出“知识图谱”(Google Knowledge Graph),标志着知识图谱从学术走向商业应用。随后,Facebook、Microsoft、Baidu等公司也开发了自己的知识图谱系统。
- 当前趋势:随着大数据、机器学习和自然语言处理(NLP)的进步,知识图谱正与深度学习结合,形成“知识增强AI”(Knowledge-Enhanced AI),如在ChatGPT等大模型中融入知识图谱以提升准确性。
3. 知识图谱的基本组件
知识图谱的核心是“三元组”(Triple),即(主体-谓语-客体),如(苹果公司 - 创始人 - 史蒂夫·乔布斯)。更详细的组件包括:
- 实体(Entities):图中的节点,代表具体或抽象的事物。可以分为:
- 命名实体(如人名、地名、组织名)。
- 概念实体(如“水果”或“编程语言”)。
- 关系(Relations):连接实体的边,表示实体间的关联。关系可以是:
- 一对一(如“配偶”)。
- 一对多(如“作品”)。
- 多对多(如“合作”)。
- 关系还可带有方向性和权重(如“影响强度”)。
- 属性(Attributes):实体的附加描述,如“出生日期:1955年”或“高度:324米”。属性可以看作是实体到字面值(Literals,如字符串、数字)的特殊关系。
- 本体(Ontology):知识图谱的“骨架”,定义实体和关系的类别、层次结构(如“人”是一个类,“乔布斯”是其实例)。本体帮助确保知识的一致性和可推理性。
知识图谱通常存储在图数据库中,支持高效的遍历和查询。
4. 知识图谱的构建方法
构建知识图谱是一个复杂过程,通常分为知识提取、融合和存储三个阶段。方法可分为手动、半自动和自动:
- 手动构建:由专家手动输入知识,适合小规模、高精度场景(如医疗领域的专家系统)。缺点是耗时耗力。
- 半自动构建:
- 使用众包(如Wikipedia编辑)。
- 结合工具辅助,如Protégé软件编辑本体。
- 自动构建(主流方法):
- 知识提取:从非结构化文本(如网页、文章)中提取实体和关系。常用技术包括:
- 命名实体识别(NER):如使用BERT模型识别人名、地名。
- 关系抽取(Relation Extraction):如基于规则或机器学习的方法。
- 事件抽取:识别事件及其参与者。
- 知识融合:解决实体歧义(如“苹果”可能是公司或水果)和数据冲突。方法包括实体对齐(Entity Alignment)和链接预测(Link Prediction,使用Graph Neural Networks如GNN)。
- 知识存储与更新:使用图数据库存储,并通过增量学习保持更新。
- 知识提取:从非结构化文本(如网页、文章)中提取实体和关系。常用技术包括:
构建工具:Neo4j(图数据库)、Apache Jena(RDF框架)、Stanford CoreNLP(NLP工具)。
5. 技术实现
- 数据模型:
- RDF:资源描述框架,使用URI标识实体,支持SPARQL查询语言。
- 属性图(Property Graph):更灵活,节点和边都可以有属性,常用于企业级应用。
- 存储与查询:
- 图数据库:Neo4j、JanusGraph、Amazon Neptune。
- 查询语言:SPARQL(类似SQL,但针对图)、Cypher(Neo4j专用)。
- 相关算法:
- 图嵌入(Graph Embedding):如TransE、Node2Vec,将图转化为向量,便于机器学习。
- 推理(Reasoning):使用OWL规则推导出新知识,如“如果A是B的子类,且C属于B,则C属于A”。
- 知识补全:使用KG-BERT等模型预测缺失关系。
6. 典型应用
知识图谱在多个领域发挥作用:
- 搜索引擎:如Google搜索,当你查询“埃隆·马斯克”时,会显示知识面板,包括生平、公司等。
- 推荐系统:Netflix或淘宝使用知识图谱分析用户偏好和物品关系,提供个性化推荐。
- 自然语言处理:在问答系统(如Siri)中,用于理解查询意图和生成答案。
- 医疗与生物:构建药物-疾病-基因图谱,帮助药物发现和个性化治疗。
- 金融:反欺诈系统,通过关系图检测异常交易。
- AI增强:在大语言模型中融入知识图谱,减少幻觉(Hallucination),提升事实准确性。
7. 知识图谱建模与可视化存储
7.1 实验目的
本实验旨在达成下列目标:
(1)熟悉 Neo4j、JanusGraph 等主流图数据库的基本操作,包括环境搭建、数据导入与存储管理。
(2)掌握将结构化/非结构化数据(如 RDF 三元组、CSV)映射为图模型的方法,理解属性图模型与知识图谱的对应关系。
(3)学习使用图数据库自带工具(如 Neo4j Browser、Bloom)或第三方工具(如 Gephi、D3.js)实现知识图谱的交互式可视化,探索布局优化与语义增强技术。
7.2 neo4j 介绍
在计算机科学中,图形作为一种特定的数据结构,用于表达数据之间的复杂关系,如社交关系、组织架构、交通信息、网络拓扑等等。在图计算中,基本的数据结构表达式是:G=(V,E),V=vertex(节点),E=edge(边)。图形结构的数据结构一般以节点和边来表现,也可以在节点上增加键值对属性。图数据库是 NoSQL(非关系型数据库 Q)的一种,它应用图形数据结构的特点(节点、属性和边)存储数据实体和相互之间的关系信息。
Neo4j 是当前较为主流和先进的原生图数据库之一,提供原生的图数据存储、检索和处理。它由 NeoTechnology 支持,从 2003 年开始开发,1.0 版本发布于 2010 年,2.0 版本发布于 2013 年。经过十多年的发展,Ne04j 获得越来越高的关注度,它已经从一个 Java 领域内的图数据库逐渐发展成为适应多语言多框架的图数据库。Ne04j支持 ACID、集群、备份和故障转移,具有较高的可用性和稳定性;它具备非常好的直观性,通过图形化的界面表示节点和关系;同时它具备较高的可扩展性,能够承载上亿的节点、关系和属性,通过 REST 接口或者面向对象的 JAVAAPI 进行访问。
7.2.1 基本概念
Neo4j 使用图相关的概念来描述数据模型,把数据保存为图中的节点以及节点之间的关系。数据主要由三部分构成:
(1)节点:节点表示对象实例,每个节点有唯一的 ID 区别其它节点,节点带有属性;
(2)关系:就是图里面的边,连接两个节点,另外这里的关系是有向的并带有属性;
(3)属性:key-value 对,存在于节点和关系中。
7.2.2 索引
Neo4j 的索引机制是其提升查询性能的关键工具,主要包括搜索性能索引(如范围索引、文本索引)和语义 索引(如全文索引、向量索引),通过创建合适的索引可以显著加速节点和关系的查找,但需注意索引过多会影响写入性能,建议结合业务需求选择类型并通过查询计划验证效果。具体地:
(1)动机:Neo4j 使用遍历操作进行查询。为了加速查询,Ne04j 会建立索引,并根据索引找到遍历用的起始节点;
(2)介绍:默认情况下,相关的索引是由 ApacheLucene 提供的。但也能使用其他索引实现来提供;
(3)操作:用户可以创建任意数量的命名索引。每个索引控制节点或者关系,而每个索引都通过 key/value/object三个参数来工作。其中 object 要么是一个节点,要么是一个关系,取决于索引类型。另外,Neo4j 中有关于节点(关系)的索引,系统通过索引实现从属性到节点(关系)的映射。
(4)作用: 查找和删除
查找操作:系统通过设定访问条件比如,遍历的方向,使用深度优先或广度优先算法等条件对图进行遍历,从一个节点沿着关系到其他节点;
删除操作:Neo4j 可以快速的插入删除节点和关系,并更新节点和关系中的属性。
7.2.3 优势
在图数据库领域,除 Neo4j 外,还有其他如 OrientDB、Giraph、AllegroGraph 等各种图数据库。与所有这些图数据库相比,Neo4j 的优势表现在以下两个方面:
(1)Neo4 是一个原生图计算引擎,它存储和使用的数据自始至终都是使用原生的图结构数据进行处理的,不像有些图数据库,只是在计算处理时使用了图数据库,而在存储时还将数据保存在关系型数据库中。
(2)Neo4j 是一个开源的数据库,其开源的社区版吸引了众多第三方的使用和推如开源项目 SpringDataNeo4j 就是一个做得很不错的例子,同时也得到了更多开发者的拥趸和支持,聚集了丰富的可供交流和学习的资源与案例。这些支持、推广和大量的使用,反过来会很好地推动 Neo4j 的发展。
7.3 实验平台
本次实验主要使用的工具和库包括:
(1)jdk21:JDK 21 是 Java Development Kit 21 的简称,是 Oracle 发布的 Java SE 21(Standard Edition 21)对应的软件开发工具包。它是 Java 平台的一个长期支持版本。
(2)neo4j 图数据库:Neo4j 是一款全球领先的图数据库(Graph Database),它以图结构为核心存储和查询数据,专为处理高度关联的复杂数据而设计。
(3)neo4j 包:neo4j 是 Neo4j 图数据库的官方 Python 驱动包,它允许你的 Python 代码与 Neo4j 数据库进行交互。
(4)py2neo:py2neo 是一个流行的第三方 Python 库,专门为 Neo4j 图数据库设计,旨在简化与 Neo4j 的交互并增强开发体验。它的核心作用与官方 neo4j 驱动形成互补,提供更高级的抽象和便捷功能。
7.4 实验内容和要求
请大家在本地实现 neo4j 图数据的安装部署以及知识图谱的数据导入,并实现简单的可视化。
7.4.1 实验步骤与操作讲解
1. 安装 jdk-21:
在下方地址下载安装JDK。选择合适的版本,推荐选择的JDK-21。
https://www.oracle.com/java/technologies/downloads/
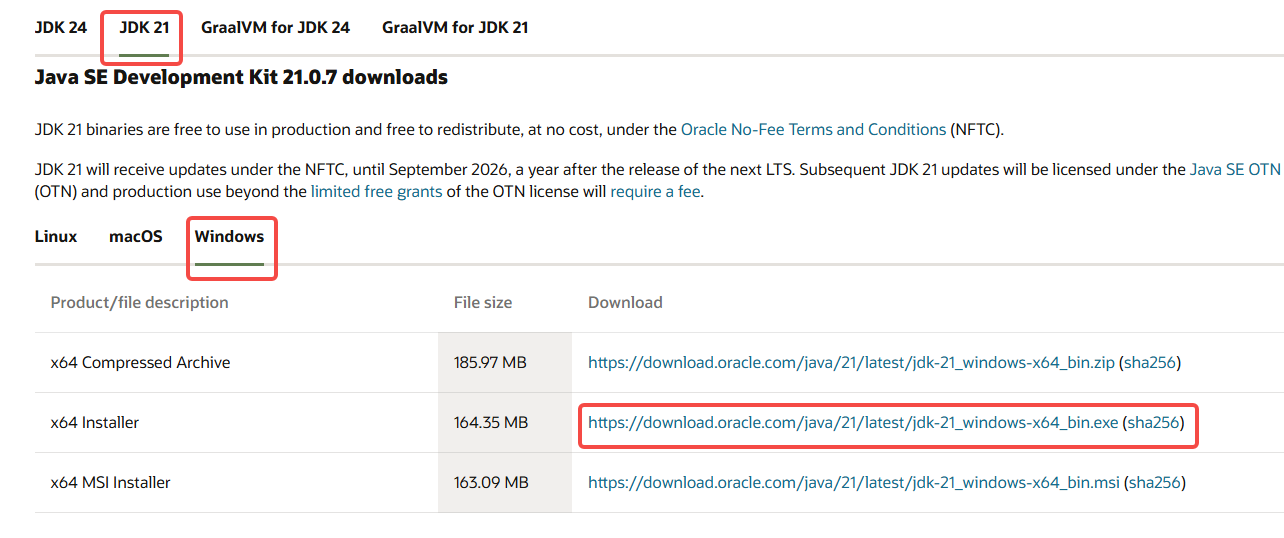
下载后,双击点击下周包进行安装,安装路径可以选择自己新建的文件夹,后续这个文件夹目录要作为环境配置路径使用。我的路径是:D:/neo4j/jdk-21。
环境配置:
(a). 找到设置中的“高级系统设置”;
(b). 点击,选择“环境变量”;
(c). 分步配置以下 3 个环境变量。
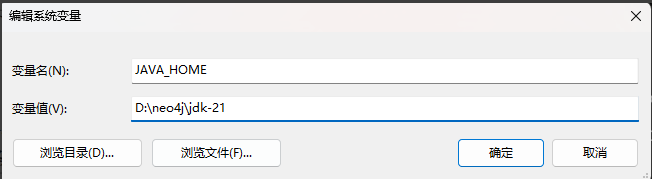
1) 变量 1
选择新建
输入变量名: JAVA_HOME
输入变量值:选择“浏览目录”,找到之前安装 JDK 的目录,我这里就是之前的 D:/neo4j/jdk-21
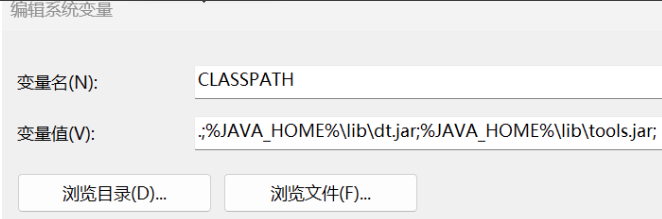
2)变量 2
再次新建
输入变量名:CLASSPATH
输入变量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
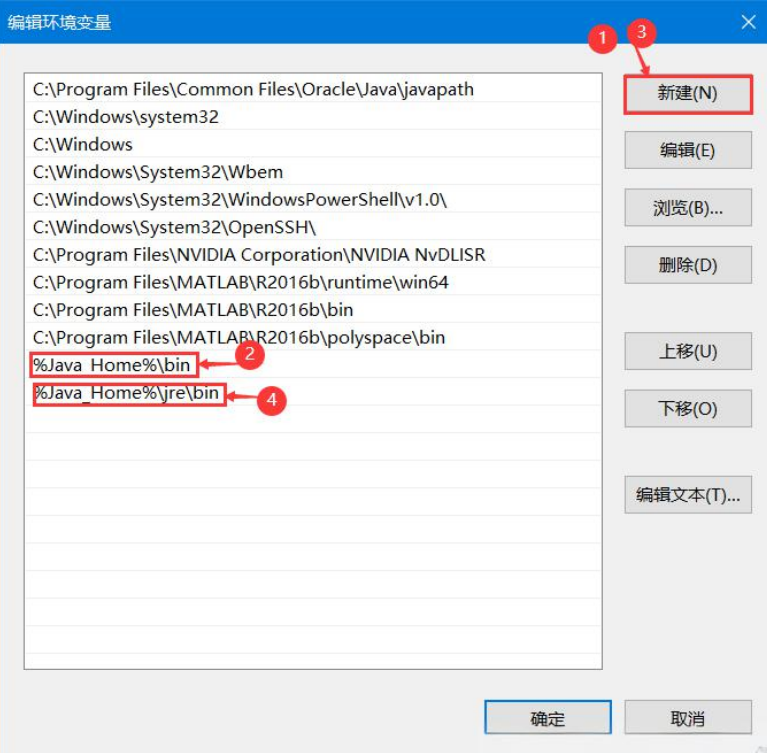
3)变量 3
点击系统变量中的 PATH,新建添加下方两个环境变量:
%JAVA_HOME%\bin;
%JAVA_HOME%\jre\bin;
点击确定,退出保存。
2. 检验 jdk-21 是否安装成功
输入指令,java -version,显示以下信息,则安装成功。若未显示,请自行检查安装过程是否有误,建议重新安装。

3. 安装 neo4j
进入以下连接官网 https://neo4j.com/download-center/,选择合适的版本,建议以下版本:neo4j-community-5.25.1-window.zip
若官网无法访问,可以选择以下链接 https://share.feijipan.com/s/uoDRemuh 进行下载。
将压缩包解压至指定的路径,比如我的:D:\neo4j\neo4j-community-5.25.1
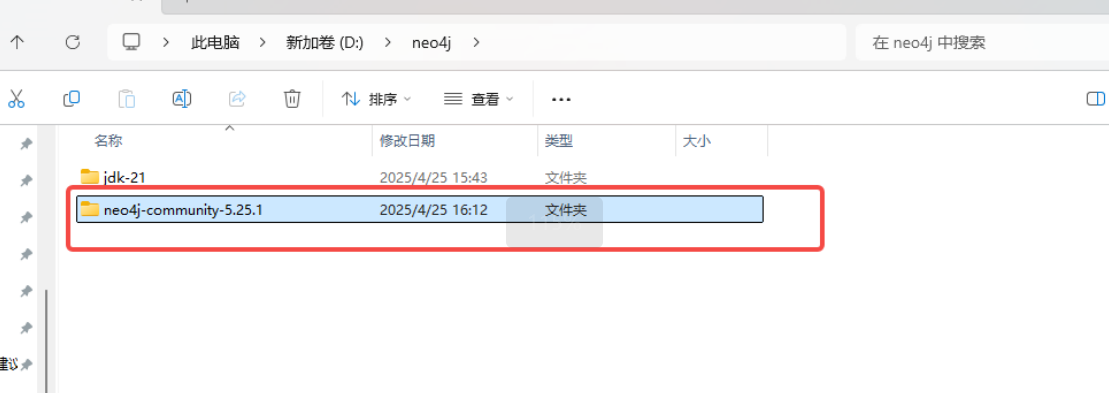
进入本地终端,使用指令 D: 切换到 D 盘;然后使用图中指令进入到D:\neo4j\neo4j-community-5.25.1目录下
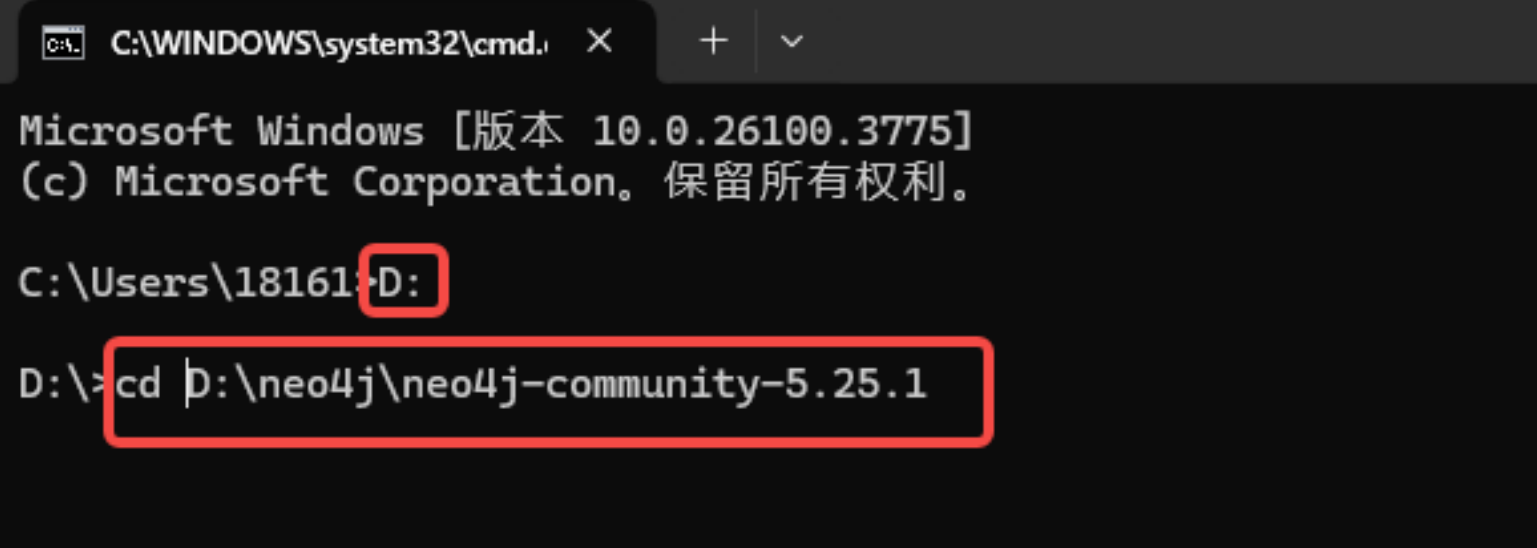
使用指令 bin\neo4j console 启动 neo4j, 成功显示以下信息:
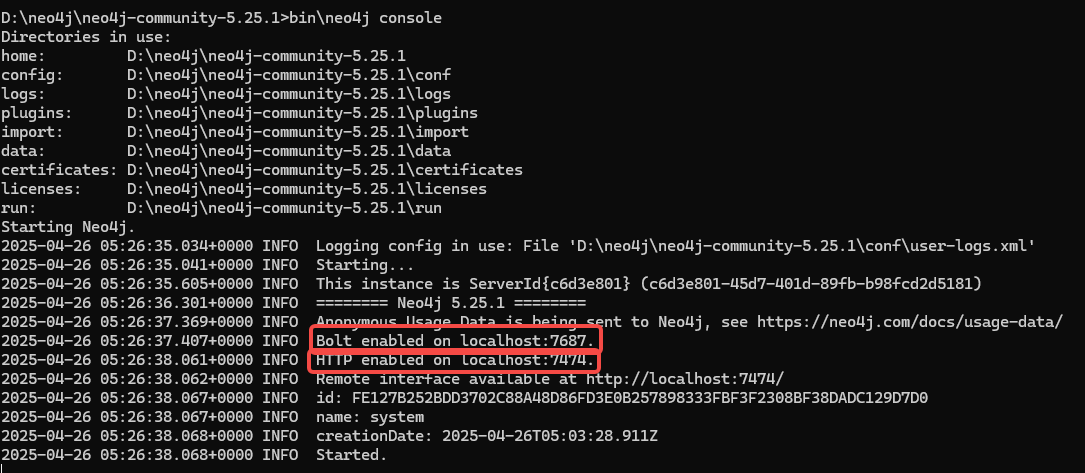
使用HTTP对应的端口打开neo4j网页界面。
然后使用Bolt对应的端口进行登录。注意:首次登陆账号和密码都是neo4j。第一次会强制性要求密码更改。
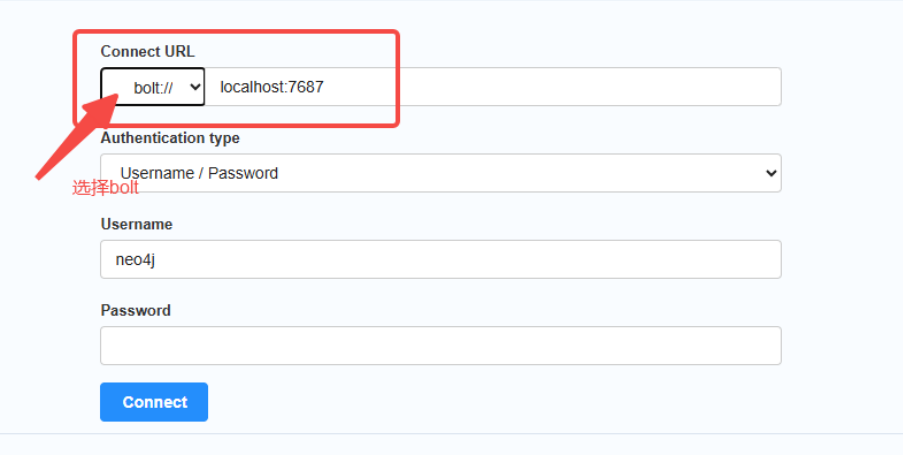
成功登录则进入以下的界面。
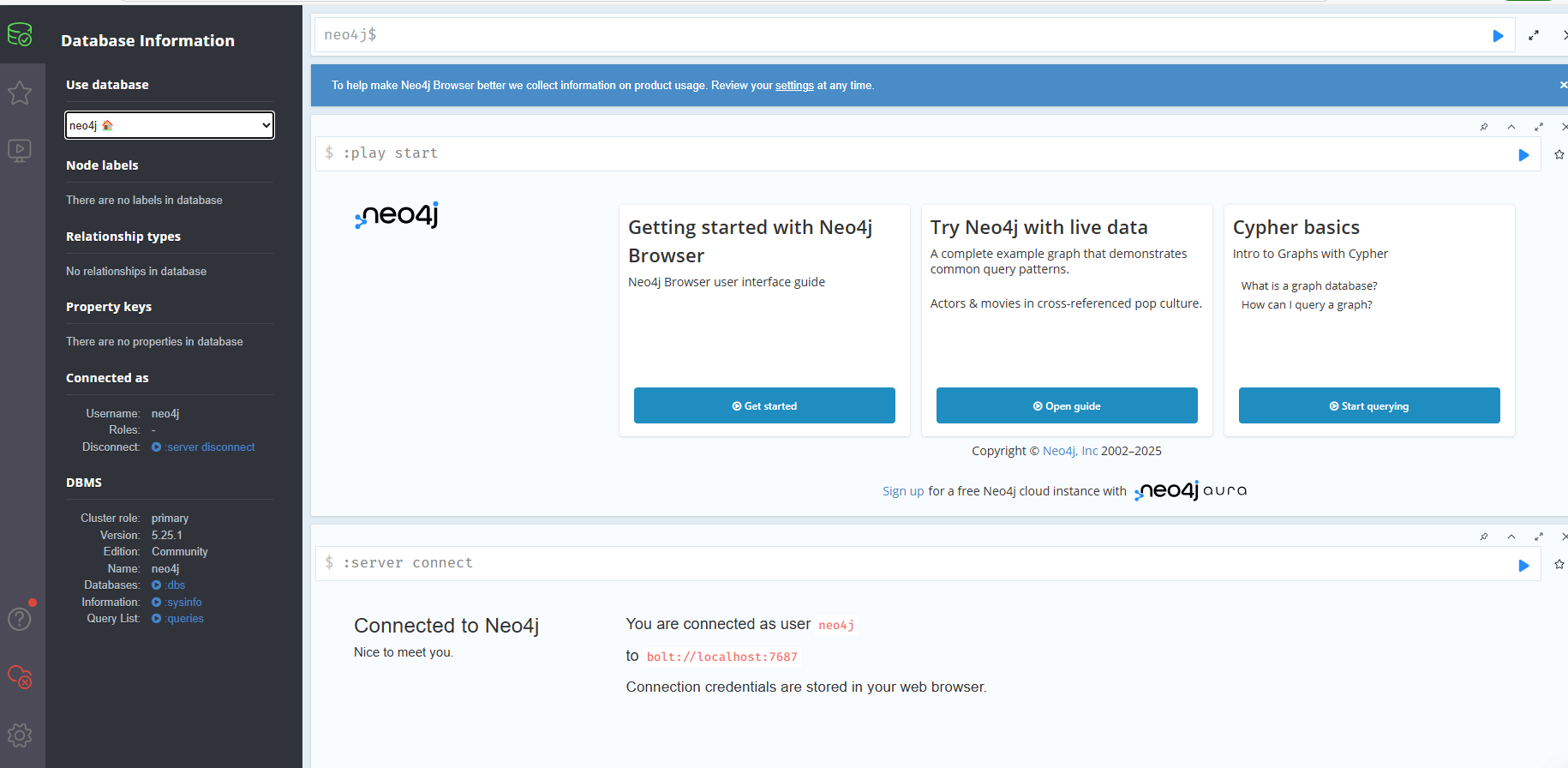
7.4.2 知识图谱数据导入与代码示例
1. 环境准备
pip install json
pip install neo4j
pip install py2neo
2. 导入实体数据
#创建数据库连接
def link_Graph():
# Neo4j服务器地址、端口、用户名和密码
uri = "bolt://localhost:7687" # 使用bolt协议,默认端口是7687
user = "" # 用户名,默认是neo4j
password = "" # 替换为你的密码
# 创建驱动程序实例
driver = GraphDatabase.driver(uri, auth=(user, password))
return driver#读取实体数据
def read_json_file(json_path):
# 打开并读取JSON文件
with open(json_path, 'r', encoding='utf-8') as file:
datas = json.load(file)
return datas#读取实体数据
def read_json_file(json_path):
# 打开并读取JSON文件
with open(json_path, 'r', encoding='utf-8') as file:
datas = json.load(file)
return datas#导入实体以及属性
def create_enity_with_properties(graph_db, label, properties):
with graph_db.session() as session:
try:
if label == 'Disease':
# 构建Cypher查询(使用参数)
cypher = "CREATE (n:{label} $props) RETURN n".format(label=label)
# 执行Cypher查询并传递属性作为参数
result = session.run(cypher, props=properties)
return 1
else:
cypher = "CREATE (n:{} {{name: $name}})".format(label)
result = session.run(cypher, name=properties)
return 1
except Exception as e:
return 0#执行程序
if __name__=='__main__':
entity_json_path = "D:\知识图谱数据汇总\DiseaseKG基于cnSchma常见疾病信息知识图谱\diseasekg
\entities.json"
relationship_json_path="D:\知识图谱数据汇总\DiseaseKG基于cnSchma常见疾病信息知识图谱\diseasekg
\\relations.json"
graph_db = link_Graph()
datas=read_json_file(relationship_json_path)#读取数据,请在导入实体时选择entity_json_path参数;
导入关系时选择relationship_json_path参数
error_number=flag=index=0
error_data=[]
for data in datas:
# flag = create_enity_with_properties(graph_db, data['label'], data['name'])#导入实体,请
在进行关系导入时注释这一行
flag=add_relationship_between_nodes(graph_db,data)#关系导入,请在进行实体导入时注释这一行
if flag==1:
print('成功执行!!!')
else:
print('数据错误!!!')3. 导入关系数据
#导入实体间关系
def add_relationship_between_nodes(driver,dict_relationship):
# 从字典中提取属性
start_entity_type=dict_relationship['start_entity_type']
end_entity_type=dict_relationship['end_entity_type']
relationship_type = dict_relationship['rel_type']
relationship_name = dict_relationship['rel_name']
all_entity_pairs=dict_relationship['rels']
try:
with driver.session() as session:
for entity_pair in all_entity_pairs:
start_entity_name = entity_pair['start_entity_name']
end_entity_name = entity_pair['end_entity_name']
# 构建Cypher查询,使用参数来引用节点和关系类型
# cypher = "MATCH (startNode:{start_label} {id: $startEntityId}), (endNode:{end_
label} {id:$endEntityId}) CREATE (startNode)-[:relationship]->(endNode) RETURN
startNode".replace('relationship',relationship_type).format(start_label=start_
entity_type,end_label=end_entity_type)
cypher = "MATCH (s:{} {{name: $startNodeName}}), (e:{} {{name: $endNodeName}})
CREATE (s)-[r:relationship {{name: $relName}}]->(e)".replace(
'relationship', relationship_type).format(start_entity_type, end_entity_type)
result = session.run(cypher, {"startNodeName": start_entity_name, "endNodeName":
end_entity_name,
'relName': relationship_name})
return 1
except Exception as e:
return 0
注:在导入关系时仅需要按照main函数中的注释要求即可4. 数据可视化
在图数据库的网页中,点击 Node labels。可以看到导入的实体节点。效果如下:
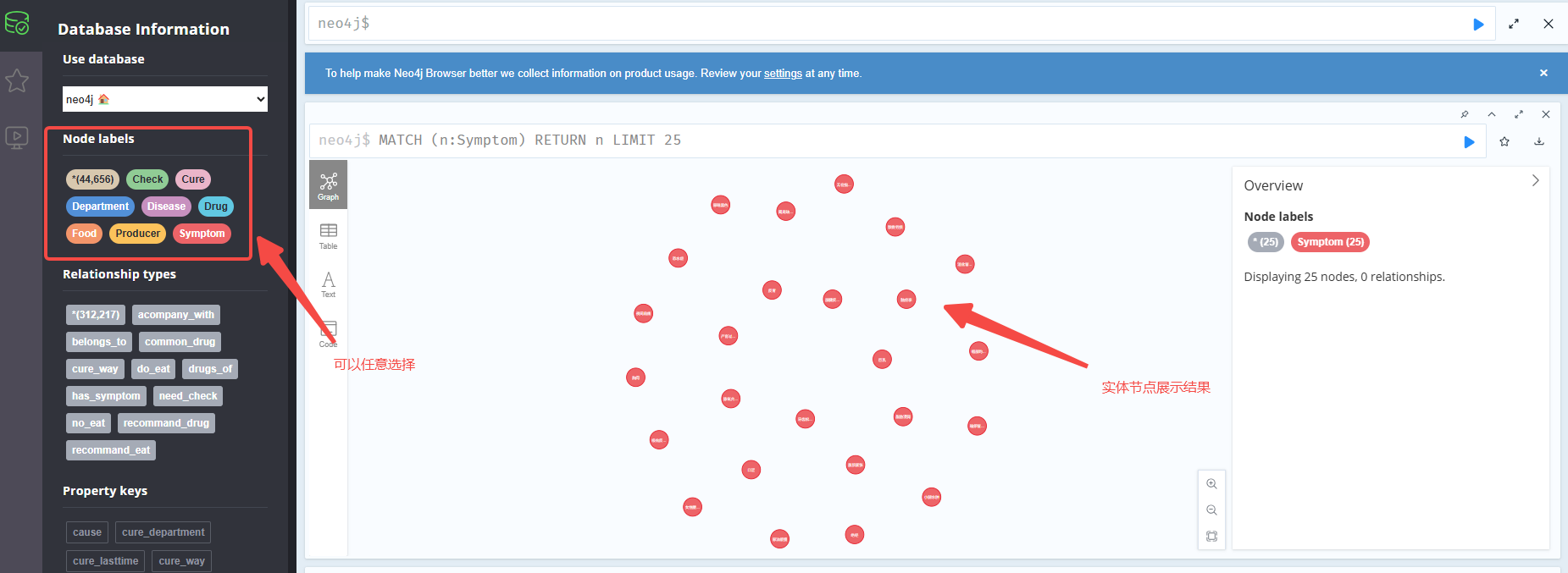
在图数据库的网页中,点击Relationshiptypes。可以看到导入的关系。效果如下:
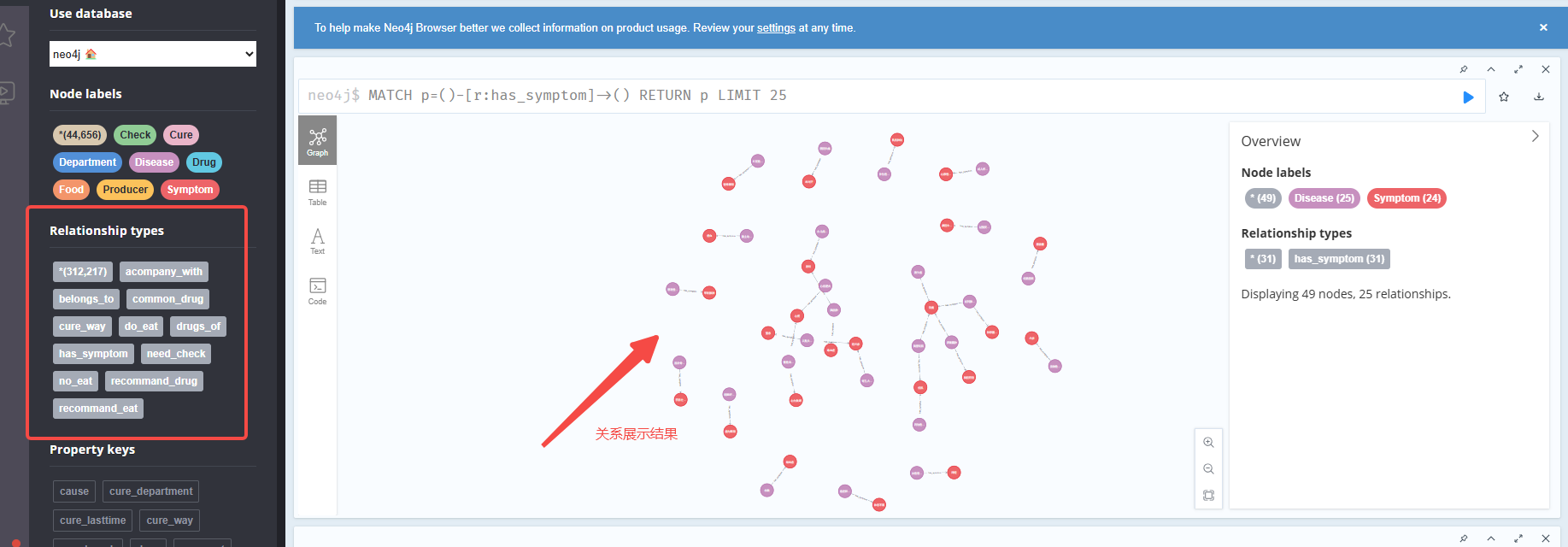

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)