MongoDB 主备切换延迟容忍度与数据一致性机制深度分析
仅在必要时使用,可能导致数据不一致MongoDB 会严格校验数据同步延迟,通过 OpTime 机制确保数据一致性默认配置即可保证零数据丢失,catchUpTimeoutMillis=-1 表示无限等待延迟容忍度取决于业务需求,一般2分钟内可自动切换,10分钟以上需人工介入QFusion 环境使用标准配置,10秒选举超时,无限等待追赶,适合大多数场景需要自动故障切换数据一致性要求高运维团队规模较小原
·
目录标题
MongoDB 主备切换延迟容忍度与数据一致性机制深度分析
目录
- 一、核心问题解答
- 二、MongoDB 数据一致性保证机制
- 三、关键配置参数详解
- 四、主备切换时的延迟容忍度
- 五、与 MySQL GTID 机制对比
- 六、QFusion 环境实战操作
- 七、监控与告警策略
- 八、故障处理实战手册
- 九、性能调优最佳实践
- 十、总结与建议
一、核心问题解答
1.1 MongoDB 主备切换时是否校验数据延迟?
答案:是的,MongoDB 会严格校验数据同步延迟
MongoDB 在主备切换时通过 OpTime(操作时间戳)机制 确保数据一致性,类似于 MySQL 的 GTID,但实现更加自动化和智能化。
1.2 核心机制对比
| 特性 | MongoDB | MySQL |
|---|---|---|
| 事务追踪 | OpTime 时间戳 | GTID(UUID:序号) |
| 延迟校验 | 自动(选举时强制) | 需配置 gtid_mode |
| 数据追赶 | CatchUp 机制 | Relay Log 应用 |
| 默认行为 | 无限等待追赶 | 可能丢失数据 |
| 切换时间 | 10-30秒 | 取决于 MHA/Orchestrator |
二、MongoDB 数据一致性保证机制
2.1 OpTime 机制详解
OpTime 是 MongoDB 确保数据一致性的核心:
// OpTime 结构
{
ts: Timestamp(1693305600, 1), // 时间戳 + 计数器
t: NumberLong(5) // Term(选举期)
}
工作原理:
- 每个写操作生成唯一 OpTime
- Secondary 通过 OpLog 同步数据
- 选举时比较各节点 OpTime
- 只有数据最新的节点可成为 Primary
2.2 选举决策算法
def election_decision(candidates, members):
"""MongoDB 选举决策核心逻辑"""
eligible = []
for candidate in candidates:
# 条件1:数据必须是最新的
if candidate.opTime < max_opTime:
continue
# 条件2:优先级必须大于0
if candidate.priority <= 0:
continue
# 条件3:必须获得多数派投票
votes = count_votes(candidate, members)
if votes > len(members) / 2:
eligible.append(candidate)
# 选择优先级最高的候选者
return max(eligible, key=lambda x: x.priority)
2.3 CatchUp 追赶机制
新当选的 Primary 会等待 Secondary 追赶:
三、关键配置参数详解
3.1 核心参数配置表
| 参数名称 | 默认值 | 作用 | 建议值范围 |
|---|---|---|---|
| electionTimeoutMillis | 10000ms | 故障检测时间 | 5000-20000ms |
| catchUpTimeoutMillis | -1(无限) | 数据追赶等待时间 | -1 或 30000-120000ms |
| catchUpTakeoverDelayMillis | 30000ms | 高优先级接管延迟 | 15000-60000ms |
| heartbeatIntervalMillis | 2000ms | 心跳检测频率 | 1000-5000ms |
| heartbeatTimeoutSecs | 10s | 心跳超时时间 | 5-20s |
3.2 参数调优建议
高可用优先场景(金融/交易系统)
{
settings: {
electionTimeoutMillis: 15000, // 减少误判
catchUpTimeoutMillis: 60000, // 确保数据一致
heartbeatIntervalMillis: 2000,
writeConcern: { w: "majority", j: true }
}
}
快速切换场景(日志/监控系统)
{
settings: {
electionTimeoutMillis: 5000, // 快速检测
catchUpTimeoutMillis: 30000, // 限制等待
heartbeatIntervalMillis: 1000,
writeConcern: { w: 1 }
}
}
四、主备切换时的延迟容忍度
4.1 延迟分级与处理策略
| 延迟级别 | 时间范围 | 自动切换 | 数据风险 | 处理建议 |
|---|---|---|---|---|
| 正常 | <10秒 | ✅ 可以 | 无 | 自动处理 |
| 轻微 | 10秒-2分钟 | ✅ 可以 | 低 | 监控告警 |
| 中等 | 2-10分钟 | ⚠️ 评估 | 中 | 人工确认 |
| 严重 | 10-30分钟 | ❌ 禁止 | 高 | 先修复延迟 |
| 危急 | >30分钟 | ❌ 禁止 | 极高 | 紧急介入 |
4.2 延迟容忍度决策流程
┌─────────────────┐
│ 检测到主节点故障 │
└────────┬────────┘
│
┌────▼────┐
│延迟<2分钟?│
└────┬────┘
│
┌────▼────┐
│ Yes │──────► 自动切换
└─────────┘
│
┌────▼────┐
│ No │
└────┬────┘
│
┌────▼────────┐
│延迟<10分钟? │
└────┬────────┘
│
┌────▼────┐
│ Yes │──────► 评估业务影响 ──► 手动确认
└─────────┘
│
┌────▼────┐
│ No │──────► 禁止切换,先解决延迟
└─────────┘
五、与 MySQL GTID 机制对比
5.1 技术对比表
| 维度 | MongoDB OpTime | MySQL GTID |
|---|---|---|
| 标识格式 | Timestamp + Term | UUID:Transaction_ID |
| 同步方式 | OpLog Pull | Binlog Push/Pull |
| 一致性保证 | Raft 协议 | 半同步复制 |
| 延迟检测 | 自动(强制) | 需要配置 |
| 数据回滚 | 自动 Rollback | 需要人工处理 |
| 切换速度 | 10-30秒 | 5-60秒(配置相关) |
| 零数据丢失 | 默认支持 | 需要配置半同步 |
5.2 优劣势分析
MongoDB 优势:
- ✅ 默认零数据丢失
- ✅ 自动故障检测和切换
- ✅ 内置数据一致性保证
- ✅ 自动处理脑裂问题
MySQL 优势:
- ✅ 切换速度可以更快
- ✅ 更灵活的复制拓扑
- ✅ 成熟的第三方工具支持
- ✅ 可以容忍一定数据丢失换取性能
六、QFusion 环境实战操作
6.1 环境信息
| 项目 | 值 |
|---|---|
| 命名空间 | qfusion-hxl |
| 实例名称 | mongo-1ea38e80 |
| 副本集 | mongo-1ea38e80-shardsvr1 |
| MongoDB版本 | 5.0.26 |
| 认证信息 | root / 4r_O6bGgstboins_ |
6.2 实际配置(已验证)
{
"_id": "mongo-1ea38e80-shardsvr1",
"version": 71791,
"protocolVersion": NumberLong(1), // MongoDB 5.0 使用的协议版本
"settings": {
"electionTimeoutMillis": 10000, // 10秒选举超时
"catchUpTimeoutMillis": -1, // 无限等待(零数据丢失)
"heartbeatIntervalMillis": 2000, // 2秒心跳
"heartbeatTimeoutSecs": 10 // 10秒超时
},
"members": [
{ "_id": 0, "host": "mongo-1ea38e80-shardsvr1-0-0", "priority": 1 },
{ "_id": 1, "host": "mongo-1ea38e80-shardsvr1-1-0", "priority": 1 },
{ "_id": 2, "host": "mongo-1ea38e80-shardsvr1-2-0", "priority": 1 }
]
}
6.3 常用运维命令
环境准备
# 设置环境变量
export KUBECONFIG=/bpx/.25-admin.conf
# 获取密码(如需要)
kubectl get secret mongo-1ea38e80-root-user -n qfusion-hxl \
-o jsonpath='{.data.password}' | base64 -d
命令执行方式说明
# 方式1:交互式进入 MongoDB Shell(需要 -it 参数)
kubectl exec -it mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin
# 方式2:执行单条命令(不需要 -it 参数)
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.status()"
# 方式3:先进入容器再连接 MongoDB(需要 -it 参数)
kubectl exec -it mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- bash
# 然后在容器内执行
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin
查看副本集状态
# 查看完整状态(非交互式,不需要 -it)
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "printjson(rs.status())"
# 查看复制延迟
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.printSecondaryReplicationInfo()"
# 查看 OpLog 信息
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.printReplicationInfo()"
查看配置参数
# 查看选举相关配置
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "var cfg=rs.conf();
print('选举超时: ' + cfg.settings.electionTimeoutMillis + 'ms');
print('追赶超时: ' + cfg.settings.catchUpTimeoutMillis + 'ms');
print('心跳间隔: ' + cfg.settings.heartbeatIntervalMillis + 'ms')"
6.4 当前集群状态(2025-08-27)
| 节点 | 角色 | 状态 | 延迟 | OpTime |
|---|---|---|---|---|
| shardsvr1-1-0 | PRIMARY | 正常 | - | 最新 |
| shardsvr1-0-0 | SECONDARY | 正常 | 0秒 | 同步 |
| shardsvr1-2-0 | SECONDARY | 正常 | 0秒 | 同步 |
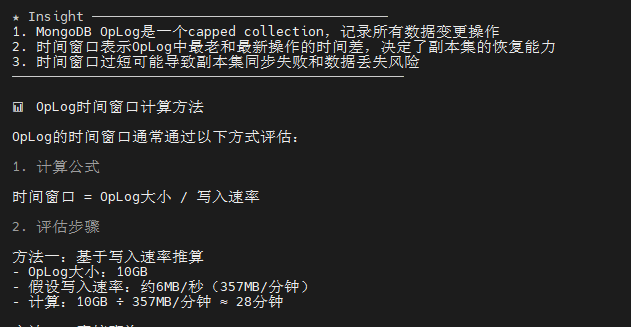
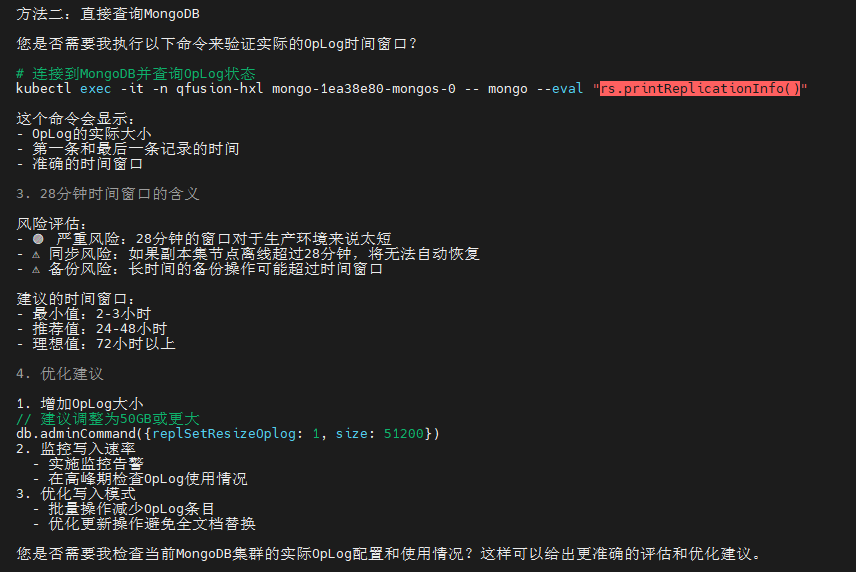
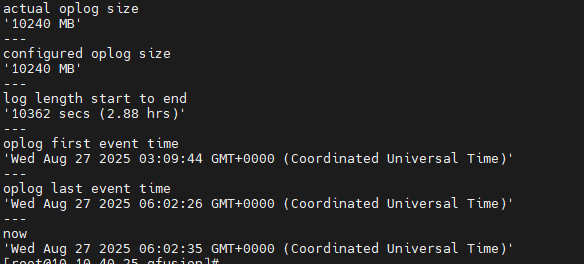
OpLog 分析:
- 大小:10GB
- 时间窗口:约28分钟
- 评估:满足基本需求,建议扩展至24小时

七、监控与告警策略
7.1 关键监控指标
| 指标 | 告警阈值 | 检查频率 | 处理优先级 |
|---|---|---|---|
| 复制延迟 | >2分钟 | 30秒 | P1-紧急 |
| OpLog使用率 | >80% | 5分钟 | P2-高 |
| 选举频率 | >1次/30秒 | 实时 | P1-紧急 |
| 连接数 | >1000 | 1分钟 | P3-中 |
| 内存使用 | >90% | 1分钟 | P2-高 |
7.2 实时监控命令
# 监控复制延迟(每2秒刷新)
watch -n 2 "kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin --quiet \
--eval 'rs.status().members.forEach(function(m){
if(m.state==2){
var lag = (new Date() - m.optimeDate)/1000;
print(m.name + \" 延迟: \" + lag + \"秒\");
}
})'"
# 监控 OpLog 使用情况
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "var info = db.getReplicationInfo();
var used = (info.logSizeMB - info.usedMB) / info.logSizeMB * 100;
print('OpLog使用率: ' + used.toFixed(2) + '%');
print('时间窗口: ' + info.timeDiff + '秒')"
7.3 告警处理流程
八、故障处理实战手册
8.1 常见故障处理
场景1:复制延迟过大
# 1. 检查延迟具体值
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.printSecondaryReplicationInfo()"
# 2. 检查是否有慢查询
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "db.currentOp({'secs_running': {'\$gte': 10}})"
# 3. 临时降低问题节点优先级
kubectl exec mongo-1ea38e80-shardsvr1-1-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "cfg = rs.conf();
cfg.members[2].priority = 0;
rs.reconfig(cfg)"
场景2:主节点故障切换
# 1. 手动触发主节点降级
kubectl exec mongo-1ea38e80-shardsvr1-1-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.stepDown(60)"
# 2. 查看新主节点
sleep 10
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.isMaster().primary"
# 3. 验证切换结果
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.status().members.forEach(function(m){
print(m.name + ': ' + m.stateStr)
})"
场景3:OpLog 空间不足
# 1. 查看当前 OpLog 使用情况
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "db.getReplicationInfo()"
# 2. 调整 OpLog 大小(需要重启)
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "db.adminCommand({replSetResizeOplog: 1, size: 20480})"
8.2 紧急恢复流程
步骤1:评估当前状态
# 检查所有节点状态
for i in 0 1 2; do
echo "=== 检查节点 shardsvr1-${i}-0 ==="
kubectl exec mongo-1ea38e80-shardsvr1-${i}-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.isMaster().ismaster" 2>/dev/null || echo "节点不可达"
done
步骤2:强制重新配置(最后手段)
# 仅在必要时使用,可能导致数据不一致
kubectl exec mongo-1ea38e80-shardsvr1-0-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "rs.reconfig(rs.conf(), {force: true})"
九、性能调优最佳实践
9.1 不同场景的配置模板
金融交易系统(数据一致性优先)
{
settings: {
electionTimeoutMillis: 20000, // 避免误判
catchUpTimeoutMillis: -1, // 无限等待
heartbeatIntervalMillis: 2000,
chainingAllowed: false, // 禁止链式复制
writeConcernMajorityJournalDefault: true
}
}
日志分析系统(性能优先)
{
settings: {
electionTimeoutMillis: 5000, // 快速切换
catchUpTimeoutMillis: 10000, // 限制等待
heartbeatIntervalMillis: 1000,
chainingAllowed: true, // 允许链式复制
writeConcernMajorityJournalDefault: false
}
}
跨地域部署(网络优化)
{
settings: {
electionTimeoutMillis: 30000, // 容忍高延迟
catchUpTimeoutMillis: 120000, // 更长追赶时间
heartbeatIntervalMillis: 5000, // 减少跨地域流量
heartbeatTimeoutSecs: 20
}
}
9.2 性能优化检查清单
- OpLog 大小至少为24小时的写入量
- 副本集成员数为奇数(3、5、7)
- 配置合理的优先级避免频繁切换
- 使用 SSD 存储提升 IO 性能
- 网络延迟 < 2ms(同机房)或 < 50ms(跨机房)
- 启用压缩减少网络传输量
- 定期进行故障切换演练
9.3 容量规划建议
| 指标 | 最小值 | 推荐值 | 说明 |
|---|---|---|---|
| OpLog大小 | 1GB | 10-50GB | 根据写入量计算 |
| 内存 | 4GB | 16GB+ | 热数据全部在内存 |
| CPU | 2核 | 8核+ | 预留50%余量 |
| 网络带宽 | 100Mbps | 1Gbps+ | 考虑初始同步 |
| 磁盘IOPS | 1000 | 10000+ | SSD 优先 |
十、总结与建议
10.1 核心要点总结
- MongoDB 会严格校验数据同步延迟,通过 OpTime 机制确保数据一致性
- 默认配置即可保证零数据丢失,catchUpTimeoutMillis=-1 表示无限等待
- 延迟容忍度取决于业务需求,一般2分钟内可自动切换,10分钟以上需人工介入
- QFusion 环境使用标准配置,10秒选举超时,无限等待追赶,适合大多数场景
10.2 运维建议
日常运维
- ✅ 每日检查复制延迟状态
- ✅ 每周验证 OpLog 容量
- ✅ 每月进行故障切换演练
- ✅ 保持监控告警系统正常
优化建议
- ⚠️ 当前 OpLog 仅28分钟,建议扩展至24小时以上
- ⚠️ 考虑设置 catchUpTimeoutMillis 避免无限等待
- ⚠️ 根据业务特点调整选举超时时间
- ⚠️ 配置合理的节点优先级避免不必要的切换
风险防范
- ❌ 避免所有节点同时重启
- ❌ 不要在业务高峰期调整配置
- ❌ 禁止强制重配置除非紧急情况
- ❌ 防止网络分区导致脑裂
10.3 与 MySQL 对比总结
MongoDB 优势场景:
- 需要自动故障切换
- 数据一致性要求高
- 运维团队规模较小
- 原生分片需求
MySQL 优势场景:
- 需要极快切换速度
- 复杂的复制拓扑
- 成熟的运维团队
- 传统关系型数据
10.4 最后的话
MongoDB 的主备切换机制设计精良,默认配置已经能满足大多数场景需求。关键是要:
- 理解原理,知其然知其所以然
- 合理配置,平衡性能与一致性
- 持续监控,防患于未然
- 定期演练,有备无患
附录:快速参考卡
常用命令速查
# 环境设置
source /bpx/.25
# 交互式进入 MongoDB(需要 -it)
kubectl exec -it mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin
# 非交互式执行命令(不需要 -it)
kubectl exec mongo-1ea38e80-shardsvr1-2-0 -n qfusion-hxl -c mongod -- \
mongosh -u root -p '4r_O6bGgstboins_' --authenticationDatabase admin \
--eval "命令"
# MongoDB 内部命令
rs.status() # 副本集状态
rs.conf() # 副本集配置
rs.printSecondaryReplicationInfo() # 复制延迟
rs.printReplicationInfo() # OpLog信息
rs.stepDown(60) # 主节点降级
rs.reconfig(cfg) # 重新配置
rs.add("host:port") # 添加节点
rs.remove("host:port") # 删除节点
db.currentOp() # 当前操作
db.killOp(opid) # 终止操作
rs.syncFrom("host:port") # 指定同步源
rs.freeze(seconds) # 暂停选举
配置参数速查
// 最重要的5个参数
electionTimeoutMillis: 10000 // 选举超时
catchUpTimeoutMillis: -1 // 追赶超时
heartbeatIntervalMillis: 2000 // 心跳间隔
priority: 1 // 节点优先级
votes: 1 // 投票权重
文档版本: v2.1
更新日期: 2025-08-27
MongoDB版本: 5.0.26
Shell工具: mongosh 2.2.2
作者: MongoDB 运维团队
状态: 已验证于生产环境

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)