斯坦福大学联合项目论文解读 | Mobi-π:调动你的机器人学习策略
斯坦福大学与丰田研究院联合提出Mobi-π框架,解决移动机器人平台执行视觉运动操作任务时的泛化问题。该框架通过3D高斯溅射场景建模、混合评分函数和贝叶斯优化,为移动机器人寻找适合策略执行的基座姿态,无需额外收集数据即可实现固定机器人策略向移动平台的迁移。实验验证在5项仿真任务和3项真实场景任务中均取得良好效果,成功率达80%以上,显著优于传统方法。这一突破为Kinova Gen3等机械臂在复杂环境
研究背景
现有视觉运动操作策略(如按压按钮、转动水龙头等精密任务)多基于有限的机器人位置和相机视角数据训练,导致其在移动机器人平台上的泛化能力极差—— 当机器人基座姿态变化时,视觉输入和可达空间易偏离训练分布,最终导致任务失败。
为解决这一问题,斯坦福大学联合丰田研究院提出了Mobi-π 框架,以 Kinova Gen3 机械臂(7DoF)为核心载体(搭载于轮式移动基座),通过“策略迁移” 方案实现固定机器人策略向移动平台的高效迁移。其核心思路是:在新环境中为移动机器人找到与原策略训练分布对齐的基座姿态,无需额外收集演示数据,即可让固定机器人的策略在移动平台上稳定执行。

图1:引入策略迁移。(a)假设一个视觉运动策略π是从一个或一组有限的相机位姿训练而来。(b)我们感兴趣的是在移动平台上运行π,其中机器人在随机位姿下初始化,并且在运行π之前需要进行导航。(c)简单地朝着感兴趣的对象导航并执行操作策略,很可能导致策略的分布外初始化,从而导致失败。左图:机器人靠得太近,用手臂将对象向内推。右图:次优的朝向使得左臂无法够到对象。(d)提高策略的鲁棒性需要大量的数据采集,以覆盖所有可能的机器人基座位姿初始化。(e)我们定义了策略迁移的新问题,其目标是找到最优的机器人位姿,从而为执行π提供分布内的视角,在无需收集额外演示的情况下实现任务成功。
移动家务机器人又出新招!
研究中的核心方法
Mobi-π 框架的核心是通过 “场景建模 - 姿态评估 - 优化搜索” 三步法,为移动机器人找到适合策略执行的基座姿态,具体包括:
3D 高斯溅射(3D Gaussian Splatting)场景建模
利用机器人采集的1000 张 RGB-D 图像构建场景的 3D 高斯表示,可实现任意视角的高质量新视图合成。该模型包含空间位置、不确定性、不透明度和视角相关颜色等信息,为后续姿态评估提供基础。

混合评分函数(Hybrid Score Function)姿态评估
设计多维度评分函数K (p),判断候选基座姿态 p 是否适合策略执行:
分布内评分(K_id):通过 DINO 特征匹配,评估渲染视图与原策略训练数据的一致性;
物体可见性评分(K_obj):利用 MiniCPM-v2 视觉语言模型,确保任务相关物体在视野内;
碰撞检查评分(K_col):基于场景占用图,验证姿态是否无碰撞。

贝叶斯优化(Bayesian Optimization)姿态搜索
采用无梯度优化方法,以混合评分函数为目标,通过高斯过程代理模型平衡“探索” 与 “利用”,高效搜索最优基座姿态。
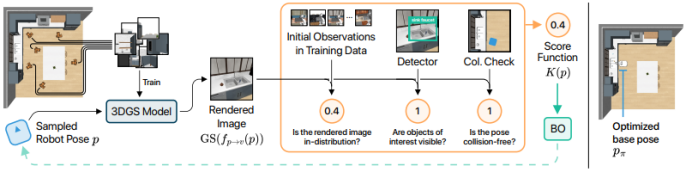
图 5:研究人员提出的概念验证方法概述。该方法的目标是找到一个合适的机器人姿态 p 用于策略初始化,使得给定的策略 π 能够在场景 S 中成功执行。他们的方法包含三个部分:(1)将提出的机器人姿态 p 通过 v = fp→v (p) 转换为其对应的相机姿态 v,然后将该相机姿态输入 3D 高斯泼溅模型以生成渲染图像;(2)将渲染图像和提出的机器人姿态输入混合评分函数 K,该函数用于预测所提出的机器人姿态是否适合策略初始化;(3)评分函数的输出用于更新贝叶斯优化算法,该算法会反复提出新的待评估机器人采样姿态,并更新其关于哪些机器人姿态最适合机器人策略执行的内部信念。混合评分函数由多个借助视觉基础模型实现的部分组成,因此它能够对所提出的姿态做出如下判断:(a)是否符合训练数据集的分布;(b)视野中是否包含感兴趣的物体;(c)是否无碰撞。
硬件配置
机械臂:Kinova Gen3(7DoF,左右各一台,用于执行抓取、操作等任务);
移动基座:轮式移动平台(承载机械臂,实现位置和朝向调整,含棱柱形升降机以调节手臂高度);
相机:Basler工业相机(2台,安装于双臂之间,用于采集RGB-D图像,内参已知且与基座相对位置固定)。
场景与数据
模拟环境:基于RoboCasa构建5个厨房任务场景(如关门、开微波炉等),包含5种训练布局和5种未见过的测试布局;
真实环境:模拟杂货店场景,包含3个典型任务(抓取薯片、抓取纸巾、倾倒番茄);
数据采集:每个任务采集30-50次人类远程操作演示数据,用于训练基础操作策略;3D高斯模型训练需1000张RGB-D图像(采集时间 < 5分钟)。
PART.04
实验过程与结果
为了促进对政策动员的进一步研究,提出了 Mobi-π 框架:
模拟任务
为了有效地研究政策动员问题,研究人员以 RoboCasa 为基准设置,开发了一套模拟环境。他们选取了五个单阶段操作任务:关门、关抽屉、打开水龙头、打开微波炉和打开炉灶。

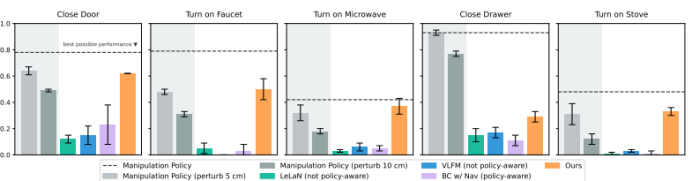
图3:仿真实验结果。研究人员在 5 项仿真任务中对 LeLaN(非策略感知)、VLFM(非策略感知)、BC w/ Nav(策略感知,5 倍训练数据)以及他们提出的方法进行了评估。对于每项任务,研究人员针对 3 个种子点(seed)进行评估,每个种子点对应 50 次试验,以此统计任务执行的成功率。图中的柱状图表示 3 个种子点结果的均值和标准差。还报告了在初始基座姿态有无扰动情况下的操作策略性能。在 5 项任务中的 4 项任务里,研究人员的方法与操作策略在初始化时施加 5 厘米扰动情况下的执行性能相当。
基线
研究团队研究了三种用于策略动员的基线方法,并将它们分为两类。第一类基线方法导航至目标对象时,不考虑操控策略的能力。这类方法不具备策略感知能力。LeLaN 和 VLFM 等方法属于此类。
第二类基线方法具备策略感知能力,利用大规模数据将导航与操控连接起来。他们使用BC w/ Nav(一种经过训练的行为转换器,可使用组合演示同时执行导航和操控)作为此类方法的代表。
在实际实验中,研究团队将他们的方法与两个基准进行比较:BC w/ Nav 基准和 Human 基准。在 BC w/ Nav 基准中,他们利用导航和操作数据训练端到端模仿学习策略。在Human 基准中,他们口头要求用户手动驾驶机器人到他们认为能够成功执行每个操作任务的最佳起始基准位姿,但不提供任何关于该策略如何训练的信息。

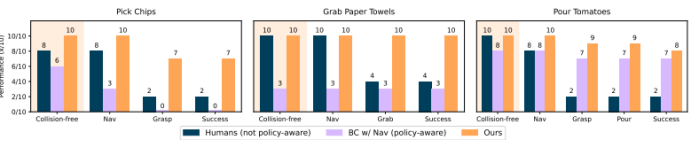
图4:现实机器人实验结果。对于每个评估的任务和方法,研究人员跟踪某些性能历程(即导航成功、抓取成功、完全成功)的发生率。他们还跟踪无碰撞回合的百分比。如果机器人行驶到一个不仅面向目标物体,而且与理想目标位姿的距离在50厘米以内的位姿,我们就认为导航尝试成功。抓取成功的定义是机器人稳定地抓取到感兴趣的物体(即薯片袋、纸巾或西红柿托盘),只有当整个任务完成时才计为完全成功。
评估指标
从空间和视觉角度量化了策略调动的可行性。
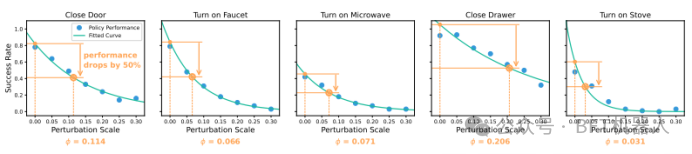
图5:空间调动可行性。图中展示了在初始机器人基座姿态上施加不同标准差的高斯噪声时,执行给定策略的性能表现。x轴表示所施加噪声的标准差σ(也称之为 “扰动尺度”);y轴表示每个蓝点对应150次试验的策略成功率;绿色曲线表示拟合的性能衰减曲线。基于这条拟合曲线,研究人员可以找到使策略成功率下降一半的扰动尺度φ(单位:米)。φ值越小,说明该策略越难调动,因为当机器人姿态与分布内姿态的偏差增大时,策略性能会迅速衰减。
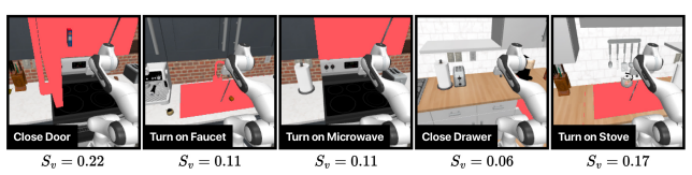
图6:视觉调动可行性。在每项任务中,研究人员通过计算感兴趣物体平均占据视野的比例,来评估从视觉角度调动机器人学习策略的可行性。他们将这一指标记为 Sv。这一点至关重要,因为感兴趣物体的视觉外观将帮助策略调动方法确定适合策略执行的机器人放置姿态。如果感兴趣物体仅占据场景的极小部分,那么方法要精确地定位机器人,使其视觉视角适合策略执行,就会变得更加困难。
关键成果与突破
突破“固定策略 - 移动平台” 适配瓶颈
首次提出“策略迁移” 问题框架,无需重新训练策略或收集海量数据,即可让固定机器人的策略在移动平台上稳定执行,解决了传统方法泛化差、成本高的痛点。
推动移动操作技术实用化
3D高斯溅射 + 混合评分函数的方案,实现了场景建模、姿态评估与优化的端到端整合,为 Kinova Gen3等机械臂在家庭、超市等复杂环境中执行精密操作提供了通用技术路径。
兼容现有策略增强方法
框架可与提升策略视角鲁棒性的现有技术(如多视角数据增强、3D 表示学习)互补,进一步扩展机器人操作能力的边界。
奠定基准与工具基础
提出的Mobi-π框架包含迁移难度指标、模拟任务套件、可视化工具和基线方法,为后续 “策略迁移” 研究提供了标准化评估体系。
结语
Mobi-π框架通过创新的 “策略迁移” 思路,打破了固定机器人策略与移动平台之间的壁垒,尤其为Kinova Gen3等机械臂在复杂环境中的应用提供了关键技术支撑。未来,随着动态场景建模、多任务策略适配等技术的完善,该框架有望推动移动机器人从 “实验室演示” 走向 “家庭服务、工业协作” 等实际应用场景,加速机器人操作技术的规模化落地。
项目详情:https://mobipi.github.io/

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)