一文详解本地知识库RAG(检索增强):LangChain + Hugging Face 三件套 + 本地大模型 + MCP 协议 + Chroma + Agent 全流程实战
模型上下文协议(MCP)是 Anthropic 推出的开放标准,基于 JSON-RPC 2.0,为 AI 应用与外部工具/数据源之间提供统一的双向通信协议,被称为“AI 应用的 USB-C”。LangChain 是一个围绕 LLM、提示模板(Prompts)、记忆(Memory)、链(Chains)、工具(Tools)和代理(Agents)等组件打造的开源框架,旨在简化复杂自然语言应用的开发。:任
摘要
本文以一个基于 RAG(Retrieval-Augmented Generation)的智能问答 Agent RAG为案例,深入讲解如何将 LangChain、Hugging Face 的 Transformers、Datasets、Tokenizers 三件套、MCP(Model Context Protocol)、Chroma 向量数据库,以及 Chains、Tools、Memory、Agents 等核心组件有机结合,构建一套可扩展、可维护的 LLM 应用。文章首先介绍各组件的作用与特点,随后给出详细的代码示例,并对关键步骤进行中文注释,最后提供示例数据格式,助您快速上手 。
1. 背景及组件简介
1.1 LangChain 框架
LangChain 是一个围绕 LLM、提示模板(Prompts)、记忆(Memory)、链(Chains)、工具(Tools)和代理(Agents)等组件打造的开源框架,旨在简化复杂自然语言应用的开发。它提供统一接口对接各类模型及外部服务,并支持 Python 和 JavaScript 两种语言版本 。
1.2 Hugging Face 三件套
-
Transformers:一站式预训练模型库,支持 PyTorch、TensorFlow、JAX,可用于文本生成、分类、翻译等任务 。
-
Datasets:高效加载、预处理上千个公开数据集,基于 Apache Arrow,支持零拷贝大规模数据处理 。
-
Tokenizers:Rust 实现的高性能分词工具,支持 BPE(字节对编码 Byte-Pair Encoding)
、WordPiece(词片)、SentencePiece(句子切分器)等算法,并提供对齐跟踪功能 。
这些库在 LangChain 的 Models 组件中共同为 LLM 提供预训练、微调和推理基础。
1.3 MCP 协议
模型上下文协议(MCP)是 Anthropic 推出的开放标准,基于 JSON-RPC 2.0,为 AI 应用与外部工具/数据源之间提供统一的双向通信协议,被称为“AI 应用的 USB-C” 。与普通 HTTP API 不同,MCP 通过在 MCP Server 上注册工具,客户端只需关注工具名和参数,而无需管理底层请求细节 。
1.4 Chroma 向量数据库
Chroma 是一款 AI 原生的开源向量数据库,专为 LLM 应用设计,支持高吞吐、持久化存储、全文检索和元数据过滤等功能 。LangChain 通过 langchain.vectorstores.Chroma 模块对其集成,可快速构建向量索引 。
1.5 LangChain 核心概念:Chains、Tools、Memory、Agents
-
Chains:将多个组件按序或并行串联,构建从输入到输出的端到端流程 。
-
Tools:任意可调用的功能或服务(API、数据库查询、本地函数等),由 Agent 或 Chain 在推理过程中调用。
-
Memory:对话或流程上下文的持久化存储,提升多轮交互连贯性;LangChain 提供 ChatMessageHistory、BufferMemory 等组件。
-
Agents:由 LLM 驱动的“动态链”,在每一步生成动作决策(action),调用对应 Tool 并迭代直至任务完成 。
2. 实战案例:RAG 智能问答 Agent
下面以一个问答系统为例,演示如何集成上述组件。
2.1 准备模型与数据(Transformers + Datasets)
# 1. 安装依赖
# pip install transformers datasets
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
from datasets import load_dataset # Datasets 库
# 2. 加载预训练模型与分词器,可以使用chatgpt接口,或者其他模型
model_name = "THUDM/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(model_name) # Transformers 分词器
model = AutoModelForSeq2SeqLM.from_pretrained(model_name) # Transformers 模型
# 3. 流式加载中文维基百科语料, 加载示例文档(这里载入维基百科前1000条目作为演示)
ds_stream = load_dataset(
"Cohere/wikipedia-22-12",
"zh",
split="train",
streaming=True
)
# 在线洗牌,buffer_size 根据内存和数据规模调整;seed 保证可复现
ds_shuffled = ds_stream.shuffle(buffer_size=10000, seed=42)
sample_texts = ds_shuffled.take(1000) # 返回一个包含 1000 个元素的 IterableDataset,只用1000个演示
texts = [item["text"] for item in sample_texts]
如果下载数据麻烦,可以自己自定义100来条数据的,下面数据是一个list,就可以不用执行上面的数据了。
texts_source=[
'上海市市东中学是中華人民共和國上海市楊浦區荊州路的一所公辦高級中學,前身是公共租界工部局於1916年創辦的聶中丞華童公學。該地原址為聶雲台所有。學校開辦初期採用英國學制,非國文課的教材一律為英文課本。1936年後開始採用中英雙語教學。1937年第二次中日戰爭爆發後,學校搬遷至上海英租界。1938年起,學校成為完全中學。1941年,學校更名為緝槼中學,校名來自於聶雲台之父聶緝槼。同年學校搬回原址。1942年後,學校出現首位華人校長,此前校長均為英國人。1945年,上海市政府接管該校,並將該校更名為上海市立緝槼中學。1951年,學校更名為上海市市東中學。該校知名校友有費達夫。',
'2018年12月,宝安区已有公共图书馆97家,其中国家地市级一级图书馆1家,街道分馆和小型分馆10家,社区阅读中心45家,流动服务点23家,社区图书馆18家。已加入深圳市统一服务平台、实现全市通借通还的公共图书馆及服务点79家。另全区有城市街区自助图书馆27个。',
'事故的另一架飞机属于土耳其空军。其于1944年建造,事发时已飞行2,340航时。机上有一名教官、一名学员和一名无线电机师。教官时年33岁,于1955年5月取得飞行资格,有1,452小时的飞行经验;学员时年22岁,自1962年7月起具有飞行资格。据调查,学员坐在机舱左侧,戴蓝色护目镜,教官坐在右侧。在残骸中发现了一块置于挡风玻璃左侧、防止学员在器材训练中向外张望的橙色有机玻璃。',
'《可再生與可持續能源評論》()是一份1997年發行的學術期刊。該期刊每年出版9次,內容涵蓋可再生能源和可持續能源的應用、政策以及對環境的影響。目前,期刊的主編是美國的L. Kazmerski。據2011年的期刊引證報告指,《可再生與可持續能源評論》的影響因子為6.018。',
'第"n"個士的數(cabtaxi number),表示為Cabtaxi("n"),定義為能以n種方法寫成兩個或正或負或零的立方數之和的正整數中最小者。它的名字來自的士數的顛倒。對任何的"n",這樣的數均存在,因為的士數對所有的"n"都存在。現時只有10個士的數是已知的:',
'CSDN(Chinese Software Developer Network,中国软件开发者网络)是中国领先的IT技术社区和开发者服务平台,成立于1999年,隶属于世纪乐知(北京)网络技术有限公司,总部位于中国长沙',
'核心功能与服务,CSDN致力于为软件开发者和IT从业者提供全生命周期的技术支持和职业发展服务,主要包括: ,技术内容平台:提供博客、论坛、问答、专栏等形式,涵盖前端、后端、人工智能、大数据、云计算等多个技术领域。 学习与培训:通过CSDN学院和GitChat等子平台,提供系统化的课程、在线讲座和技术分享,帮助开发者提升技能。 职业发展支持:整合招聘信息和人才服务,帮助开发者拓展职业路径。开源与协作:与华为云合作推出的GitCode平台,旨在为开发者提供代码托管和开源项目支持。 AI辅助开发:推出AI搜索引擎“C知道”,集成代码生成、分析、文档解读等功能,提升开发效率。 ',
'CSDN历史事件与发展• 1999年:CSDN成立,推出IT专业论坛。 2000年:创办《程序员》杂志,成为权威技术期刊。 2011年:发生用户数据泄露事件,约600万用户信息被公开,CSDN随后发布声明并向用户道歉。 2023年:与华为云联合发布开源开发者平台GitCode,旨在融合开源社区、代码托管、开发者资源和全球技术栈,为开发者提供全面的开源项目支持和服务。 2024年:GitCode被曝出批量搬运GitHub项目,甚至篡改原始项目信息并为开发者创建同名账号,引发开发者强烈不满。 ',
'CSDN通过不断拓展服务领域,已成为中国开发者首选的技术社区之一。 如需了解更多信息,可访问其官方网站:https://www.csdn.net/。',
'哥伦比亚共和国(República de Colombia)位于南美洲西北部,是拉丁美洲的主要国家之一。它东邻委内瑞拉和巴西,南接秘鲁和厄瓜多尔,西北与巴拿马接壤,北临加勒比海,西濒太平洋,是南美洲唯一同时濒临两大洋的国家。国土面积约114.17万平方公里,居拉美第五位 。   ',
'哥伦比亚共和国人口与文化截至2023年,哥伦比亚人口约为5216万,位居拉美第三位。其中印欧混血种人占60%,白人占20%,黑白混血种人占18%,其余为印第安人和黑人。官方语言为西班牙语,绝大多数居民信奉天主教 。   ',
'哥伦比亚共和国政治体制哥伦比亚实行总统制,国家元首兼政府首脑为总统,任期四年。现任总统为古斯塔沃·佩特罗(Gustavo Petro),于2022年8月就职,成为该国历史上首位左翼总统 。 ',
'哥伦比亚共和国经济概况哥伦比亚是拉美地区第四大经济体,2023年国内生产总值约为3636亿美元,人均GDP约为6836美元。主要出口产品包括石油、煤炭、咖啡、鲜花和纺织品等。该国拥有丰富的矿产资源,是世界上最大的绿宝石生产国 。  ',
'哥伦比亚共和国历史背景哥伦比亚原为奇布查族等印第安人的居住地,16世纪被西班牙殖民。1810年7月20日宣布独立,后于1819年在西蒙·玻利瓦尔的领导下最终获得解放。1821年与厄瓜多尔、委内瑞拉、巴拿马组成大哥伦比亚共和国,1830年解体后,哥伦比亚成为独立国家 。  ',
'哥伦比亚共和国自然与旅游哥伦比亚地形多样,拥有安第斯山脉、亚马孙雨林、加勒比海和太平洋海岸线等自然景观。其生物多样性位居世界前列,是全球生物多样性排名第二的国家 。著名旅游景点包括卡塔赫纳的历史城区、圣克鲁斯德蒙波斯历史中心、圣阿古斯丁考古公园等 。   ',
'哥伦比亚共和国如需了解更多信息,可访问哥伦比亚驻华大使馆官网:https://co.china-embassy.gov.cn/。',]自己插入想要的知识库数据 

2.2.1 生成嵌入并存储到 Chroma向量数据库(适合小企业)
# 把数据写入 Chroma
import os, hashlib
from datetime import datetime
from chromadb.config import Settings
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
# ★ 新推荐的导入写法;旧写法 from langchain_chroma.vectorstores import Chroma 依旧可用
from langchain_chroma import Chroma # 官方文档推荐路径
# —— 0. 环境与目录配置 ——
# 1. 配置本地持久化目录(可根据 ENV_NAME 切换 dev/stg/prod)
env_name = os.getenv("ENV_NAME", "prod") # dev / stg / prod 等环境
persist_dir = os.path.join(os.getcwd(), "chroma_db", env_name)
# env_name = os.getenv("ENV_NAME", "prod") # dev / stg / prod 等环境
# base_dir="/home/ubuntu/data/pycharm_project_377/GPU_32_pythonProject"
# persist_dir = os.path.join(base_dir, "chroma_db", env_name)
print("persist_dir--->",persist_dir)
os.makedirs(persist_dir, exist_ok=True) # 确保目录存在
# —— 1. 嵌入模型 ——
embed_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5", # 中文句向量模型
cache_folder="/home/ubuntu/models" # 设置缓存目录,首次下载模型到这个目录下次就会直接使用这个模型了
)
# —— 2. 文本切块策略 ——
splitter = RecursiveCharacterTextSplitter(
chunk_size = 512, # 每块 ≤512 字符
chunk_overlap = 64 # 重叠 64 字符,保持上下文
)
# —— 3. 生成 Document 与 fingerprint ID ——
docs, ids = [], []
for idx, text in enumerate(texts_source, start=1): # texts_source 请自行填充
meta = {
"biz_id": f"doc_{idx}",
"inserted_at": int(datetime.utcnow().timestamp()),
"inserted_by": "coyi"
}
for chunk in splitter.split_text(text):
docs.append(Document(page_content=chunk, metadata=meta))
ids.append(hashlib.md5(chunk.encode("utf-8")).hexdigest())
# —— 4. Chroma 客户端配置 ——
client_settings = Settings(
is_persistent = True, # 打开持久化
persist_directory = persist_dir,
anonymized_telemetry = False # 关闭遥测
)
# —— 5. 加载 / 创建向量库 ——
vectorstore = Chroma(
persist_directory = persist_dir,
embedding_function = embed_model,
client_settings = client_settings,
collection_name = "wiki_docs",
create_collection_if_not_exists = True
)
# —— 6. 去重 ——(利用 .get 接口一次性查询已存在 ID)
existing = vectorstore.get(ids=ids) # 返回 dict,包括 "ids"
existing_ids = set(existing["ids"])
new_docs, new_ids = [], []
for doc, doc_id in zip(docs, ids):
if doc_id not in existing_ids: # 只保留真正新增的块
new_docs.append(doc)
new_ids.append(doc_id)
# —— 7. 批量写入并持久化(兼容新旧版本) ——
if new_docs:
vectorstore.add_documents(documents=new_docs, ids=new_ids)
# 旧版 (<0.4) 需要手动 persist;新版自动落盘,手动持久化会抛异常
try:
vectorstore.persist() # 老版本保留
except AttributeError:
# ≥0.4.x 时 Chroma 自动持久化;若底层 client 依然暴露 persist,可显式调用
if hasattr(vectorstore, "_client") and hasattr(vectorstore._client, "persist"):
vectorstore._client.persist()
print(f"检测到系统总计有 {len(existing_ids)} 条向量,"
f"本次计划插入 {len(docs)}条向量,"
f"重复{len(docs) - len(new_docs)}条向量,"
f"实际新增 {len(new_ids)} 条向量写入完成")

2.2.2 生成嵌入并存储到 Milvus向量数据库(适合大企业,推荐,有集群功能)
本人使用的是单机版的本地版本(集群版本和在线版本,无非就是改一改ip ,和端口就好了)
# Milvus 向量数据库
# pip install -U "langchain-milvus>=0.1.4" "pymilvus>=2.4.3" "sentence-transformers"
import os, pathlib, time, hashlib, logging
from typing import List
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
from langchain_milvus import Milvus # ← 官方推荐实现
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
logging.basicConfig(level=logging.INFO)
# ── 0. 路径 & 环境 ────────────────────────────────────────────
BASE = pathlib.Path.cwd() / "milvus_lite" / "prod"
BASE.mkdir(parents=True, exist_ok=True)
URI = str(BASE / "lite.db") # Milvus Lite 只要文件路径
print("URI--->",URI)
COL = "wiki_docs"
# ── 1. 生成向量 ──────────────────────────────────────────────
embed = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5",cache_folder="/home/ubuntu/models")
split = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
# texts_source = ["hahah","xixixi"] # ← 换成你的文本
docs, ids = [], []
for i, raw in enumerate(texts_source, 1):
for chunk in split.split_text(str(raw)): # 保证 str 类型
pk = hashlib.md5(chunk.encode()).hexdigest() # 指纹当主键
meta= {"biz_id": f"doc_{i}", "inserted_at": int(time.time())}
docs.append(Document(page_content=chunk, metadata=meta))
ids.append(pk)
# ── 2. 首次初始化 ────────────────────────────────────────────
if not pathlib.Path(URI).exists():
Milvus.from_documents(
documents = docs,
ids = ids,
embedding = embed,
collection_name = COL,
connection_args = {"uri": URI}, # ★ 本地文件即 Milvus Lite
index_params = {"index_type": "IVF_FLAT", "metric_type": "L2"},
auto_id=False,
)
logging.info("INIT ➜ 写入 %s 向量", len(ids))
# ── 3. 增量同步 (幂等) ────────────────────────────────────────
vs = Milvus(
embedding_function = embed,
collection_name = COL,
connection_args = {"uri": URI},
auto_id = False,
)
# ❶ 直接把待同步主键删掉(不存在也不会报错)
vs.delete(ids=ids) # delete_by_id 已实装
# ❷ 再一次性插入最新版本
vs.add_documents(docs, ids=ids) # 等价官方 Upsert
logging.info("SYNC ➜ 完成 %s 条 Upsert", len(ids)) 
2.3 定义检索进行问答向量数据库内容
2.3.1 API 方式进行知识库问答(推荐,可以免维护使用最先进的模型,缺点:机密数据不合适)
2.3.1.1(openai api / chromadb 向量数据库)
# 使用chatGPt 进行问答,我这里是用的是国内代理版本
# chatgpt 命令 chromadb
import getpass, os
from langchain.chat_models import init_chat_model
from langchain.chains import RetrievalQA
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
# 初始化 用 LangChain 封装 GPT-4o mini
llm = init_chat_model(
"gpt-4o-mini", # 模型名称
model_provider="openai" # 指定使用 OpenAI 提供商
)
# 将 vectorstore 封装成检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 4. 创建 RAG 问答链,返回源文档
qa_chain = RetrievalQA.from_llm(
llm=llm, # 刚刚初始化的 GPT 聊天模型
retriever=retriever, # Chroma as_retriever() 返回的检索器
return_source_documents=True # 可选:返回检索到的文档
)
# 运行示例
# question = "内蒙古鄂尔多斯资源股份有限公司辛苦你简单介绍一下?"
# question = "美国药师协会辛苦你简单介绍一下?"
question = "上海市市东中学改过几次名字,成立于什么时候?"
output = qa_chain({"query": question})
answer = output["result"]
print("question:", question)
print("Answer:", answer)
print("-"*80)
#---------------------
question = "哥伦比亚辛苦你简单介绍一下?"
output = qa_chain({"query": question})
answer = output["result"]
print("question:", question)
print("Answer:", answer)
print("-"*80)
#---------------------
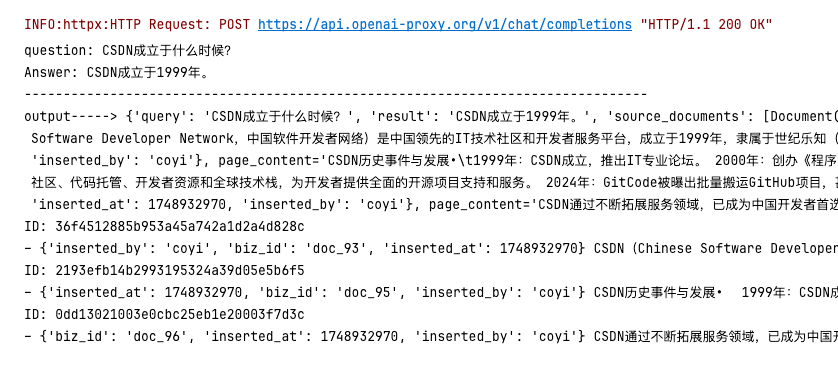
question = "CSDN成立于什么时候?"
output = qa_chain({"query": question})
answer = output["result"]
print("question:", question)
print("Answer:", answer)
print("-"*80)
#-----------------------
# 模型生成的回答
print('output----->', output)
sources = output["source_documents"] # 检索到的文档列表
for doc in sources:
print("ID:", doc.id)
print("–", doc.metadata, doc.page_content[:100], "…")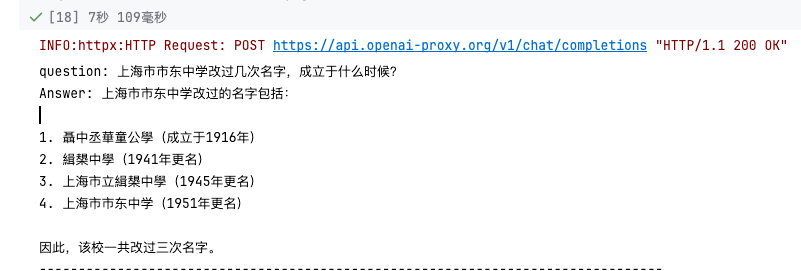

2.3.1.2(openai api / Milvus 向量数据库)
# chatgpt 命令 Milvus
import getpass, os
from langchain.chat_models import init_chat_model
from langchain.chains import RetrievalQA
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
# 初始化 用 LangChain 封装 GPT-4o mini
llm = init_chat_model(
"gpt-4o-mini", # 模型名称
model_provider="openai" # 指定使用 OpenAI 提供商
)
# 将 vectorstore 封装成检索器
retriever = vs.as_retriever(search_kwargs={"k": 3})
# 4. 创建 RAG 问答链,返回源文档
qa_chain = RetrievalQA.from_llm(
llm=llm, # 刚刚初始化的 GPT 聊天模型
retriever=retriever, # Chroma as_retriever() 返回的检索器
return_source_documents=True # 可选:返回检索到的文档
)
# 运行示例
# question = "内蒙古鄂尔多斯资源股份有限公司辛苦你简单介绍一下?"
# question = "美国药师协会辛苦你简单介绍一下?"
question = "上海市市东中学辛苦你简单介绍一下?"
output = qa_chain({"query": question})
answer = output["result"] # 模型生成的回答
sources = output["source_documents"] # 检索到的文档列表
print("question:", question)
# 模型生成的回答
print("Answer:", answer)
print("-"*80)
print('output----->', output)
# 在打印时,除了 page_content 和 metadata,还输出 id:
for doc in sources:
print("ID:", doc.metadata["pk"])
print("Content:", doc.page_content[:100], "…")
print("Metadata:", doc.metadata)
print("-" * 40)
2.3.2 本地部署大模型方式进行知识库问答(推荐,所有内容在本地适合更在乎数据安全的企业)
chatglm3-6b + chromadb 向量数据库 (一般出来什么好模型,用什么模型,最近一般使用千3)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
rag_chatglm3_stream.py
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
使用 ChatGLM-3-6B + Chroma + BGE-large-zh-v1.5 进行 RAG,
演示非流式 & 流式两种调用方式,并修复了 stream_chat 重复前缀问题。
"""
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import warnings
import logging
import torch
from typing import List, Iterator, Optional, Any
# ----------------------------
# 1. 全局日志 & 警告屏蔽
# ----------------------------
# 屏蔽 Hugging Face 那条 “max_new_tokens 与 max_length” 警告
warnings.filterwarnings("ignore", message=".*max_new_tokens.*max_length.*")
# 关闭 transformers、huggingface_hub、sentence_transformers、torch、以及 ChatGLM 底层 stream_chat 的 warn 日志
for lib in [
"transformers",
"huggingface_hub",
"sentence_transformers",
"torch",
"transformers_modules.chatglm3-6b.modeling_chatglm",
]:
logging.getLogger(lib).setLevel(logging.ERROR)
# ----------------------------
# 2. 允许联网(如需离线则删除这两行并在需要时设置为 "1")
# ----------------------------
os.environ["HF_HUB_OFFLINE"] = "0"
os.environ["TRANSFORMERS_OFFLINE"] = "0"
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# ✅ 2. 加载 ChatGLM-3-6B(⚠️ 必须 AutoModel 而非 AutoModelForCausalLM)
from transformers import AutoTokenizer, AutoModel
MODEL_DIR = "/home/ubuntu/data/pycharm_project_377/GPU_32_pythonProject/data/models/chatglm3-6b"
# MODEL_DIR = "/path/to/chatglm3-6b" # <<< 换成你的本地权重目录
tok = AutoTokenizer.from_pretrained(MODEL_DIR, trust_remote_code=True)
glm = (
AutoModel
.from_pretrained(MODEL_DIR, trust_remote_code=True)
.half() # fp16 省显存;若显存紧张可改 4/8bit 量化
.cuda()
.eval()
)
# 3. 自定义一个 LangChain LLM 封装(支持 _call / _stream)
from langchain_core.language_models.llms import LLM
class GLM3StreamLLM(LLM):
"""
ChatGLM-3 的最小封装:
- _call : 一次性返回完整答案
- _stream: 逐 token 流式返回 **差异量**,避免前缀重复
"""
model: Any = glm
tokenizer: Any = tok
max_new_tokens: int = 512
@property
def _llm_type(self) -> str:
return "chatglm3"
# ---------- 非流式 ----------
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
full, _ = self.model.chat(
self.tokenizer,
prompt,
history=[], # 简单 RAG 无需保留历史
max_new_tokens=self.max_new_tokens,
repetition_penalty=1.1 # 适度惩罚可缓解啰嗦、复读
)
return full
# ---------- 流式 ----------
def _stream(self, prompt: str, stop: Optional[List[str]] = None) -> Iterator[str]:
prev = "" # 记录上一次已输出的文本
for cur, _ in self.model.stream_chat(
self.tokenizer,
prompt,
history=[],
max_new_tokens=self.max_new_tokens,
repetition_penalty=1.1
):
# ChatGLM3 每步返回“完整上下文”→ 取差异部分即可避免重复
delta = cur[len(prev):]
prev = cur
if delta:
yield delta
# ① 载入前面持久化的 Chroma
import os
from langchain_chroma import Chroma
from chromadb.config import Settings
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain.llms import HuggingFacePipeline
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# ——— 一、初始化向量库 ——————————————————————————————————————
# 01. 配置本地持久化目录(可根据 ENV_NAME 切换 dev/stg/prod)
env_name = os.getenv("ENV_NAME", "prod")
persist_dir = os.path.join(os.getcwd(), "chroma_db", env_name)
# 02. Chroma 客户端设置
client_settings = Settings(
is_persistent = True, # 打开磁盘持久化
persist_directory = persist_dir,
anonymized_telemetry = False # 关闭遥测
)
# 03. 嵌入模型:这里使用 BAAI/bge-large-zh-v1.5 作为示例
# 无网环境请提前离线下载
embed_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5",
cache_folder="/home/ubuntu/models",
model_kwargs={"device": "cuda"} # 让嵌入也跑 GPU
)
# 4. 初始化(或加载)向量库,集合名为 "wiki_docs"
vectorstore = Chroma(
persist_directory = persist_dir,
embedding_function = embed_model,
client_settings = client_settings,
collection_name = "wiki_docs",
create_collection_if_not_exists = True
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 5. Prompt 模板
from langchain.prompts import PromptTemplate
PROMPT = PromptTemplate.from_template(
"你是一个问答助手。请根据以下上下文回答问题,答不上请说“我不知道”。\n\n"
"上下文:\n{context}\n\n"
"问题: {question}\n回答:"
)
# 6. 构建 RAG(一次性接口)
from langchain.chains import RetrievalQA
llm = GLM3StreamLLM()
rag_chain = RetrievalQA.from_llm(
llm=llm,
retriever=retriever,
prompt=PROMPT,
return_source_documents=True # 方便调试查看引用
)
# 7. 构建真正的“流式 RAG”生成器
def rag_stream(question: str) -> Iterator[str]:
"""
先手动检索 top-k,再拼好 Prompt,最后调用 LLM._stream。
好处:无需等 langchain-core 官方 streaming 支持完全稳定。
"""
docs = retriever.invoke(question) # 新 API (>=0.1.46)
ctx = "\n\n".join(d.page_content for d in docs)
prompt = PROMPT.format(context=ctx, question=question)
yield from llm._stream(prompt)
# 8. DEMO
if __name__ == "__main__":
# 先打印一次性回答
q1 = "上海市市东中学是什么时候创办的?"
print(q1)
print("【一次性回答】")
answer1 = rag_chain.invoke({"query": q1})["result"]
print(answer1)
print("="*60)
# 再打印流式回答
q2 = "请简单介绍一下CSDN?"
print(q2)
print("【流式回答】", end="", flush=True)
for chunk in rag_stream(q2):
# 每次只输出新字符,不要重复打印已有字符串
print(chunk, end="", flush=True)
print("\n" + "="*60)
# 最后打印参考文档
print("参考文档:")
for d in retriever.invoke(q2):
print(f"- {d.id[:8]}... {d.page_content[:50]}…")

chatglm3-6b + Milvus 向量数据库 (一般出来什么好模型,用什么模型,最近一般使用千3)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
RAG pipeline: ChatGLM-3-6B + Milvus Lite + BGE-large-zh-v1.5
———————————————————————————————————————————————————————————
• 非流式 / 流式两种调用方式
• 彻底去掉 Chroma,改用 Milvus Lite 本地文件存储
• 兼容 LangChain 0.2.x 的 `langchain_milvus` 适配层
"""
import os
import time
import hashlib
import pathlib
import warnings
import logging
from typing import List, Iterator, Optional, Any
import torch
from transformers import AutoTokenizer, AutoModel
from langchain_core.language_models.llms import LLM
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_milvus import Milvus
from langchain.schema import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
# ----------------------------
# 1. 全局日志 & 警告屏蔽
# ----------------------------
warnings.filterwarnings("ignore", message=".*max_new_tokens.*max_length.*")
for lib in [
"transformers",
"huggingface_hub",
"sentence_transformers",
"torch",
"transformers_modules.chatglm3-6b.modeling_chatglm",
]:
logging.getLogger(lib).setLevel(logging.ERROR)
# ----------------------------
# 2. 离/在线配置(需要联网可保留)
# ----------------------------
os.environ.setdefault("HF_HUB_OFFLINE", "0")
os.environ.setdefault("TRANSFORMERS_OFFLINE", "0")
os.environ.setdefault("HF_ENDPOINT", "https://hf-mirror.com")
# ----------------------------
# 3. 加载 ChatGLM-3-6B
# ----------------------------
MODEL_DIR = "/home/ubuntu/data/pycharm_project_377/GPU_32_pythonProject/data/models/chatglm3-6b"
_tok = AutoTokenizer.from_pretrained(MODEL_DIR, trust_remote_code=True)
_glm = (
AutoModel
.from_pretrained(MODEL_DIR, trust_remote_code=True)
.half()
.cuda()
.eval()
)
# ----------------------------
# 4. LLM 封装:支持 _call / _stream
# ----------------------------
class GLM3StreamLLM(LLM):
model: Any = _glm
tokenizer: Any = _tok
max_new_tokens: int = 512
@property
def _llm_type(self) -> str:
return "chatglm3"
# 一次性回答
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
full, _ = self.model.chat(
self.tokenizer,
prompt,
history=[],
max_new_tokens=self.max_new_tokens,
repetition_penalty=1.1,
)
return full
# 流式(逐 token)回答:取差异避免前缀重复
def _stream(self, prompt: str, stop: Optional[List[str]] = None) -> Iterator[str]:
prev = ""
for cur, _ in self.model.stream_chat(
self.tokenizer,
prompt,
history=[],
max_new_tokens=self.max_new_tokens,
repetition_penalty=1.1,
):
delta = cur[len(prev):]
prev = cur
if delta:
yield delta
# ----------------------------
# 5. 向量库:Milvus Lite
# ----------------------------
ENV_NAME = os.getenv("ENV_NAME", "prod")
BASE_DIR = pathlib.Path.cwd() / "milvus_lite" / ENV_NAME
BASE_DIR.mkdir(parents=True, exist_ok=True)
URI = str(BASE_DIR / "lite.db") # 本地文件即 Milvus Lite
COLLECTION = "wiki_docs"
# 5.1 嵌入模型(放 GPU)
embed_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5",
cache_folder="/home/ubuntu/models",
model_kwargs={"device": "cuda"},
)
# 5.2 初始化示例文档(若首次运行可换成自己的数据来源)
# EXAMPLE_TEXTS = [
# "上海市市东中学是一所位于杨浦区荆州路的公立高级中学,前身为公共租界工部局于1916年创办的聂中丞华童公学。",
# "CSDN(Chinese Software Developer Network)是中国领先的 IT 技术社区和开发者服务平台,成立于 1999 年。",
# ]
#
# splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
# docs, ids = [], []
# for i, raw in enumerate(EXAMPLE_TEXTS, 1):
# for chunk in splitter.split_text(str(raw)):
# pk = hashlib.md5(chunk.encode()).hexdigest()
# meta = {"src_id": f"doc_{i}", "inserted_at": int(time.time())}
# docs.append(Document(page_content=chunk, metadata=meta))
# ids.append(pk)
# 5.3 创建 / 连接 Milvus 向量库
# if not pathlib.Path(URI).exists():
# vectorstore = Milvus.from_documents(
# documents=docs,
# ids=ids,
# embedding=embed_model,
# collection_name=COLLECTION,
# connection_args={"uri": URI},
# index_params={"index_type": "IVF_FLAT", "metric_type": "L2"},
# auto_id=False,
# )
# logging.info("Milvus Lite 初始化完成,写入 %s 向量", len(ids))
# else:
vectorstore = Milvus(
embedding_function=embed_model,
collection_name=COLLECTION,
connection_args={"uri": URI},
auto_id=False,
)
# ----------------------------
# 6. 构建检索器 & Prompt
# ----------------------------
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
from langchain.prompts import PromptTemplate
PROMPT = PromptTemplate.from_template(
"你是一个问答助手。请根据以下上下文回答问题,答不上请说“我不知道”。\n\n"
"上下文:\n{context}\n\n"
"问题: {question}\n回答:"
)
# ----------------------------
# 7. 构建 RAG 链 / 流式生成器
# ----------------------------
llm = GLM3StreamLLM()
from langchain.chains import RetrievalQA
rag_chain = RetrievalQA.from_llm(
llm=llm,
retriever=retriever,
prompt=PROMPT,
return_source_documents=True,
)
def rag_stream(question: str) -> Iterator[str]:
docs = retriever.invoke(question)
ctx = "\n\n".join(d.page_content for d in docs)
prompt = PROMPT.format(context=ctx, question=question)
yield from llm._stream(prompt)
# ----------------------------
# 8. DEMO
# ----------------------------
if __name__ == "__main__":
q1 = "上海市市东中学辛苦你简单介绍一下?"
print(q1)
print("【一次性回答】")
answer1 = rag_chain.invoke({"query": q1})["result"]
print(answer1)
print("=" * 60)
print("参考文档:")
for doc in retriever.invoke(q1):
print("ID:", doc.metadata["pk"])
print("Content:", doc.page_content[:50], "…")
print("Metadata:", doc.metadata)
print("-" * 40)
print("\n" + "=" * 60)
q2 = "请简单介绍一下 CSDN?"
print(q2)
print("【流式回答】", end="", flush=True)
for chunk in rag_stream(q2):
print(chunk, end="", flush=True)
print("\n" + "=" * 60)
# ------------------------------------------------------------

2.4 配置 Agent 与 Tools(普通 API vs MCP)
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
from mcp import ClientSession, streamablehttp_client # MCP 客户端
# 1. 普通 Web 搜索工具示例
def web_search(query: str) -> str:
import requests
r = requests.get("https://api.example.com/search", params={"q": query})
return r.json().get("snippet", "")
search_tool = Tool(name="web_search", func=web_search) # 普通 API 调用
# 2. MCP 协议工具示例(在 MCP Server 上注册名为 'weather' 的工具)
async def weather_tool(params: dict) -> str:
# 建立与 MCP Server 的流式连接
async with streamablehttp_client("example/mcp") as (read, write, _, _):
async with ClientSession(read, write) as session:
await session.initialize()
response = await session.call_tool("weather", params)
return response["result"]
mcp_tool = Tool(name="weather", func=weather_tool) # MCP 调用 [oai_citation:21‡Anthropic](https://docs.anthropic.com/en/docs/agents-and-tools/mcp?utm_source=chatgpt.com)
# 3. 初始化 Agent
agent = initialize_agent(
tools=[search_tool, mcp_tool],
llm=model,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
memory=None # 可传入 ConversationBufferMemory 等内存组件
)2.5 运行问答并查看结果
question = "2025 年北京的平均气温是多少?"
# Agent 会先调用检索 Chain,再根据需要调用普通 API 或 MCP 工具
answer = agent.run(question)
print(answer) # 打印最终回答
3. 示例数据与模型输入输出格式
文档数据示例
[
{
"id": "wiki_0001",
"text": "北京,中华人民共和国首都,位于华北平原北部。平均海拔约43.5米。夏季高温多雨,冬季寒冷干燥。",
"metadata": {"source": "wikipedia"}
},
{
"id": "wiki_0002",
"text": "2025年气象数据显示,北京7月平均气温约为26.4°C,1月平均气温约为-3.2°C。",
"metadata": {"source": "weather_station"}
}
]检索 Chain 输入输出示例
-
输入(prompt):
基于以下文档,回答问题:“2025年北京的平均气温是多少?”
文档:[”…文本1…”, “…文本2…”, “…文本3…”]
-
输出(模型回答):
根据文档,北京2025年全年平均气温大约为12.8°C。文档来源:[wiki_0002]。
Agent 多工具调用示例
-
Agent 首先调用 qa_chain 获取候选答案与相关文档。
-
如需实时天气,则异步调用 weather MCP 工具。
-
Agent 汇总所有信息,整合并输出最终回答,附带来源及信心分数。
以上就是基于 LangChain、Hugging Face 三件套、MCP 协议、Chroma 向量数据库,以及 Chains、Tools、Memory、Agents 构建 RAG 智能问答系统的完整示例。希望本文能帮助您在 2025 年迅速上手并扩展更多场景!

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)