Coze-Studio+Ollama,Window本地部署指南——踩坑、问题解决及效果测试
今天字节将Cozen的关键组件 ——与以开源形式推出,为开发者提供了完整的本地部署、流程控制与 prompt 管理能力。这不仅是对现有 Agent 工具体系的有力补充,更可能改变企业构建 AI 智能体系统的主流范式。Coze Studio 是一个集成了多种可视化工具的开发平台,旨在让 Agent 的创建、调试和部署过程变得前所未有的简单。开发者可以将其私有化部署,从而在自己的环境中构建和管理 AI
今天字节将Cozen的关键组件 —— Coze Studio(可视化开发平台) 与 CozeLoop(调试追踪 SDK) 以开源形式推出,为开发者提供了完整的本地部署、流程控制与 prompt 管理能力。
这不仅是对现有 Agent 工具体系的有力补充,更可能改变企业构建 AI 智能体系统的主流范式。
1. Coze Studio:一站式可视化 AI Agent 开发平台
地址:https://github.com/coze-dev/coze-studio

Coze Studio 是一个集成了多种可视化工具的开发平台,旨在让 Agent 的创建、调试和部署过程变得前所未有的简单。开发者可以将其私有化部署,从而在自己的环境中构建和管理 AI 应用。
核心功能与特性:
- 可视化编排:提供强大的拖拽式界面,开发者可以通过连接不同的功能节点(如大语言模型、插件、知识库等)来构建复杂的业务逻辑,实现了真正的无代码或低代码开发。
- 内置核心组件:平台集成了开发 Agent 所需的核心技术栈,包括提示词工程(Prompt)、插件(Plugins)、知识库(Knowledge)、工作流(Workflow)以及记忆(Memory)等。
- 灵活的模型支持:支持集成并管理多个大语言模型服务,如 OpenAI、Anthropic 以及中国的火山引擎等,方便开发者根据需求灵活切换和测试。
- 技术栈:后端采用 Go 语言开发,前端使用 React 和 TypeScript,为开发者提供了一个高性能、易于扩展和二次开发的底层框架。
功能清单
| 功能模块 | 功能点 |
|---|---|
| 模型服务 | 管理模型列表,可接入OpenAI、火山方舟 等在线或离线模型服务 |
| 搭建智能体 | * 编排、发布、管理智能体* 支持配置工作流、知识库等资源 |
| 搭建应用 | * 创建、发布应用* 通过工作流搭建业务逻辑 |
| 搭建工作流 | 创建、修改、发布、删除工作流 |
| 开发资源 | 支持创建并管理以下资源:* 插件* 知识库* 数据库* 提示词 |
| API 与 SDK | * 创建会话、发起对话等 OpenAPI* 通过 Chat SDK 将智能体或应用集成到自己的应用 |
快速开始
了解如何获取并部署 Coze Studio 开源版,快速构建项目、体验 Coze Studio 开源版。
详细步骤及部署要求可参考快速开始。
环境要求:
- 在安装 Coze Studio 之前,请确保您的机器满足以下最低系统要求: 2 Core、4 GB
- 提前安装 Docker、Docker Compose,并启动 Docker 服务。
License
本项目采用 Apache 2.0 许可证。详情请参阅 LICENSE 文件。
2. Window安装踩坑及问题解决
安装步骤
Windows环境安装,步骤如官方他文档
1,git clone https://github.com/coze-dev/coze-studio.git
2,配置大模型服务(Ollama)
默认的建议是配置豆包,即cp backend/conf/model/template/model_template_ark_doubao-seed-1.6.yaml backend/conf/model/ark_doubao-seed-1.6.yaml 。然后进入目录 backend/conf/model。打开复制后的文件ark_doubao-seed-1.6.yaml。然后进行设置。
我配置的是Ollama,配置参数参考:https://github.com/coze-dev/coze-studio/wiki/3.-%E6%A8%A1%E5%9E%8B%E9%85%8D%E7%BD%AE
具体步骤如下
cp backend/conf/model/template/model_template_ollama.yaml backend/conf/model/ollama.yaml
然后修改backend/conf/model/ollama.yaml
对于Ollama主要修改base_url和model即可。我用的本机的qwen3:0.6b,因为从docker调用,所以base_url: “http://host.docker.internal:11434”。下面是具体的ollama.yaml
id: 2003
name: qwen3:0.6b
icon_uri: default_icon/ollama.png
icon_url: ""
description:
zh: ollama 模型简介
en: ollama model description
default_parameters:
- name: temperature
label:
zh: 生成随机性
en: Temperature
desc:
zh: '- **temperature**: 调高温度会使得模型的输出更多样性和创新性,反之,降低温度会使输出内容更加遵循指令要求但减少多样性。建议不要与“Top p”同时调整。'
en: '**Temperature**:\n\n- When you increase this value, the model outputs more diverse and innovative content; when you decrease it, the model outputs less diverse content that strictly follows the given instructions.\n- It is recommended not to adjust this value with \"Top p\" at the same time.'
type: float
min: "0"
max: "1"
default_val:
balance: "0.8"
creative: "1"
default_val: "1.0"
precise: "0.3"
precision: 1
options: []
style:
widget: slider
label:
zh: 生成多样性
en: Generation diversity
- name: max_tokens
label:
zh: 最大回复长度
en: Response max length
desc:
zh: 控制模型输出的Tokens 长度上限。通常 100 Tokens 约等于 150 个中文汉字。
en: You can specify the maximum length of the tokens output through this value. Typically, 100 tokens are approximately equal to 150 Chinese characters.
type: int
min: "1"
max: "4096"
default_val:
default_val: "4096"
options: []
style:
widget: slider
label:
zh: 输入及输出设置
en: Input and output settings
meta:
name: qwen3:0.6b
protocol: ollama
capability:
function_call: true
input_modal:
- text
input_tokens: 128000
json_mode: false
max_tokens: 128000
output_modal:
- text
output_tokens: 16384
prefix_caching: false
reasoning: false
prefill_response: false
conn_config:
base_url: "http://host.docker.internal:11434"
api_key: ""
timeout: 0s
model: "qwen3:0.6b"
temperature: 0.6
frequency_penalty: 0
presence_penalty: 0
max_tokens: 4096
top_p: 0.95
top_k: 20
stop: []
openai: null
claude: null
ark: null
deepseek: null
qwen: null
gemini: null
custom: {}
status: 0
3,启动服务
cd docker
cp .env.example .env
docker compose --profile '*' up -d
如果下载Docker镜像失败可以找一个国内的镜像源。
启动问题
我在下载Docker镜像后,docker compose启动的时候报错,错误信息如下:
coze-elasticsearch-setup | + /setup_es.sh
coze-elasticsearch-setup | /bin/sh: /setup_es.sh: not found
找到对应的docker-compose.yml文件内容:
elasticsearch-setup:
image: alpine/curl:8.12.1
container_name: coze-elasticsearch-setup
profiles: ['middleware', 'volcano-setup']
env_file: *env_file
depends_on:
elasticsearch:
condition: service_healthy
volumes:
- ./volumes/elasticsearch/setup_es.sh:/setup_es.sh
- ./volumes/elasticsearch/es_index_schema:/es_index_schema
command:
- /bin/sh
- -c
- |
set -ex
/setup_es.sh
echo 'Elasticsearch setup complete.'
初步分析就是docker没有找到./volumes/elasticsearch/setup_es.sh,实际看了一下代码库,这个文件是存在的。
问题分析与解决
因为用的是Windows11上启动的docker desktop。在 Windows 11 上使用 Docker Desktop,情况会有些许不同,因为 Docker 实际上是运行在一个轻量级的 Linux 虚拟机(WSL 2 后端)中的。考虑可能是:“文件换行符格式 (CRLF vs LF) ”
这是 Windows 和 Linux 混合开发环境中最常见的问题。
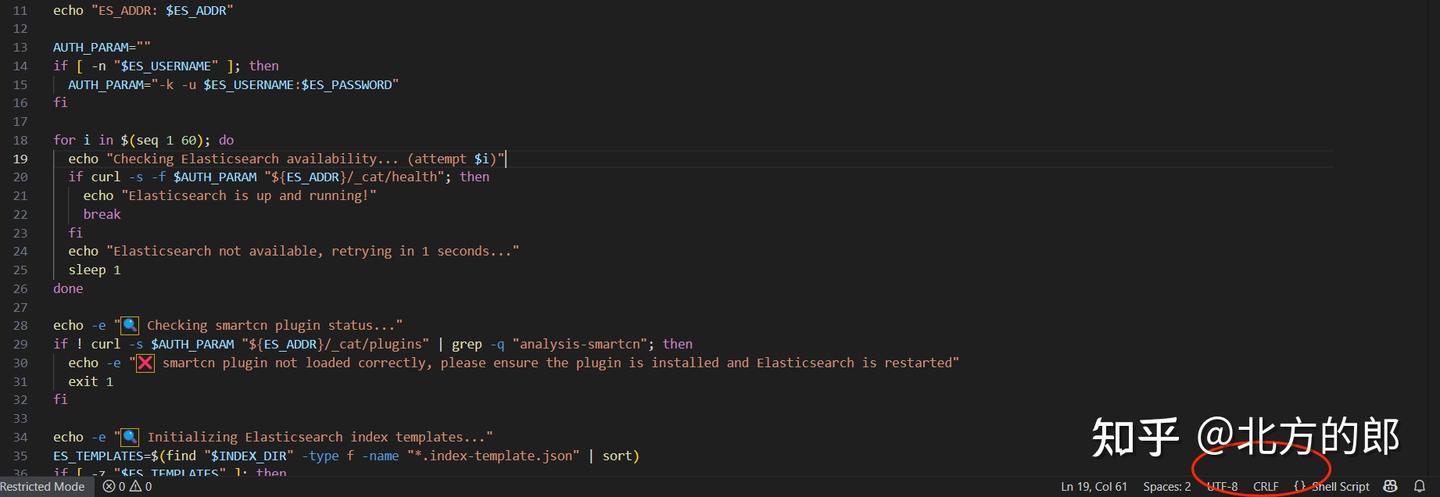
- 问题描述:Windows 系统中创建的文本文件,默认使用回车换行符(CRLF, \r\n)作为一行的结束。而容器内的 Alpine Linux 系统期望使用换行符(LF, \n)。当容器内的 sh (shell) 尝试执行一个包含 CRLF 的脚本时,它会错误地解析命令,甚至可能因为脚本第一行的 #!/bin/sh\r 而找不到正确的解释器,从而引发各种 “not found” 或奇怪的错误。
- 解决方案:将 setup_es.sh 文件的换行符格式从 CRLF 转换为 LF。使用代码编辑器 :
-
-
- 用 VS Code, Notepad++, Sublime Text 等专业的代码编辑器打开 D:\coze-studio\docker\volumes\elasticsearch\setup_es.sh 文件。
-
-
-
- 在编辑器的右下角状态栏,通常会显示当前的换行符格式。
-

-
-
- 点击它,然后选择 LF。
- 保存文件。
-
转换完成后,无需重启 Docker,直接重新运行 docker compose up 即可,问题解决。
3. 应用测试
启动后如果没有修改port,直接访问:http://localhost:8888/
首次登录,直接输入邮箱,密码,点击注册即可。主界面如下:
创建一个新的智能体:
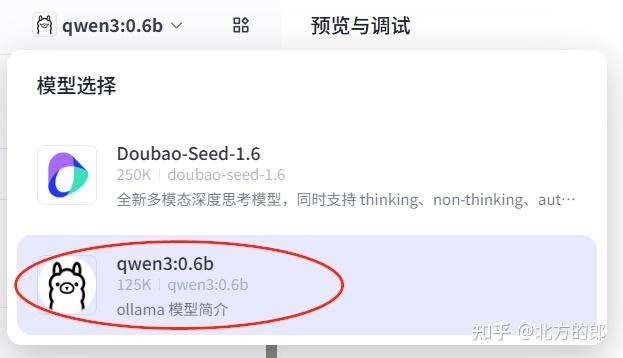
模型选择qwen3:0.6b即可
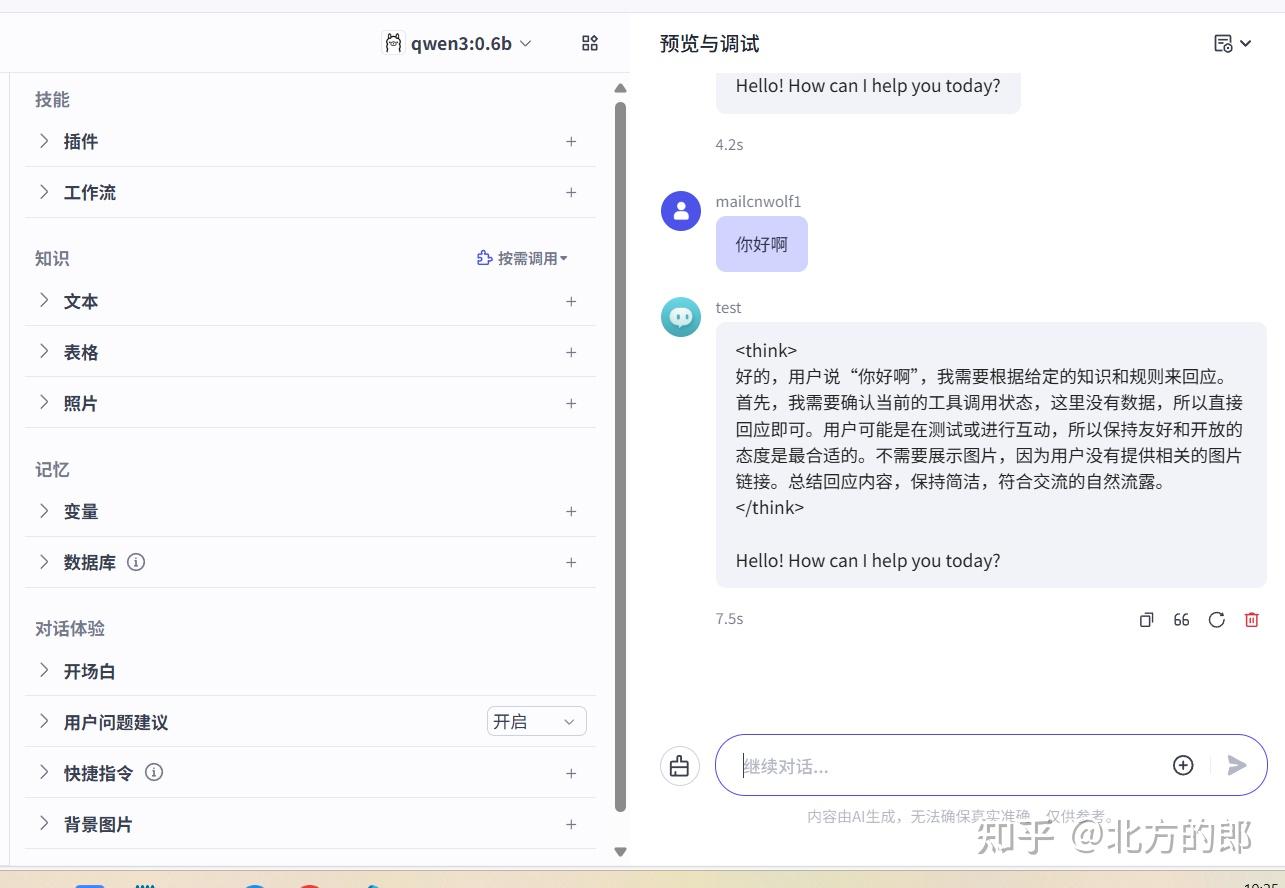
又是扑面而来的,coze的味道
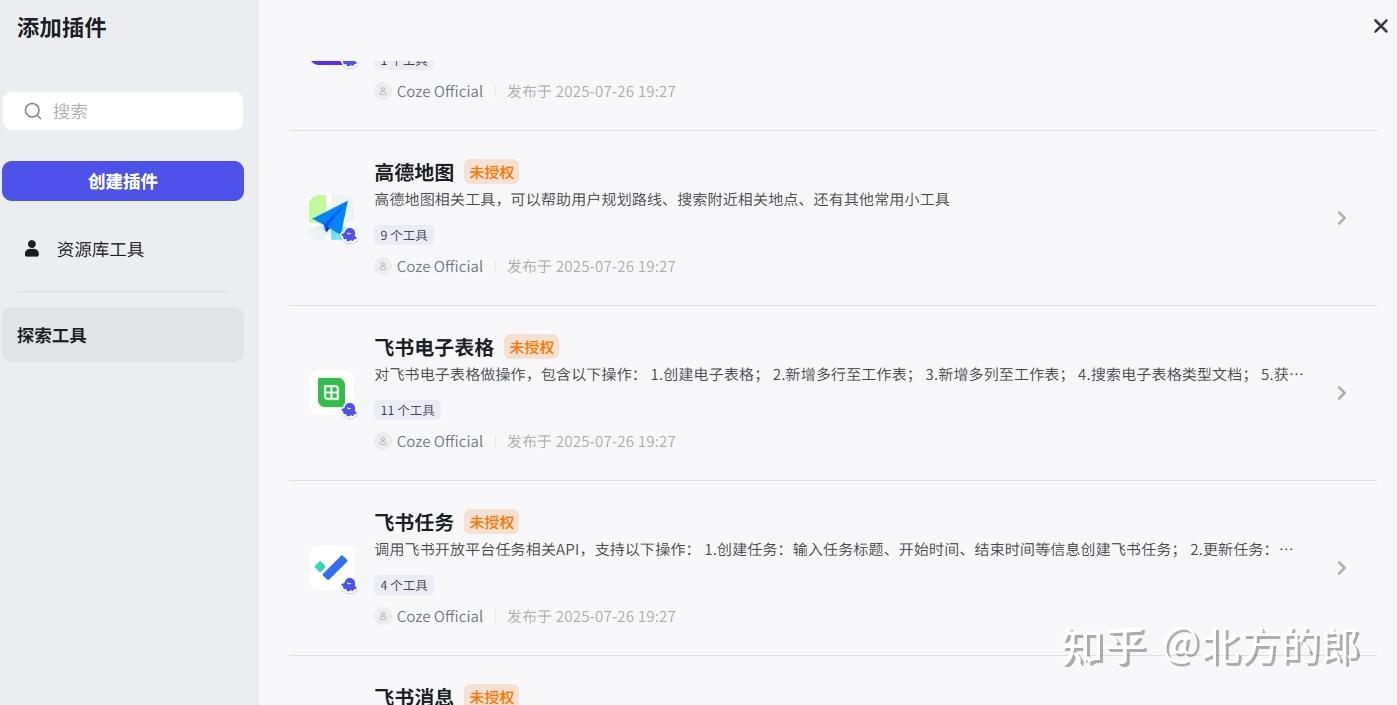
简单试了一下,整体和http://coze.cn差不多,不过大量的插件需要自己搞授权了:
后续准备深入做几个案例测试一下。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)