
3、Spark和D3 JS分析飞行大数据
实验资源
1998.csv
机场.csv
实验环境
VMware工作站
Ubuntu 16.04
火花-2.4.5
scala-2.12.10
实验内容
“很遗憾地通知您,您从 XX 到 XX 的 XXXX 航班延误了。”
相信很多在机场候机的旅客都不想听到这句话。随着航空运输的逐渐普及,航班延误问题一直困扰着我们。航班延误通常会导致两种结果,一种是航班取消,另一种是航班延误。
在本次实验中,我们将使用Spark提供的DataFrame、SQL、机器学习框架等工具,基于D3 JS数据可视化技术,对记录的航班起降数据进行分析,尝试找出航班延误的原因,并预测航班延误。
实验步骤
1、数据集介绍与准备
1\。数据集介绍
本实验使用的航班数据集为2009年数据博览会提供的航班正点率统计数据。这次我们选择 1998 年的数据集。
该数据集的字段解释如下:
! zoz100037](https://programming.vip/images/doc/ce2031d621f2e46e1d8adf0294418cec.jpg)
此外,我们将使用一些补充信息。如机场信息数据集等。
2\。下载数据集
(1)在虚拟机中输入以下命令
wget https://labfile.oss.aliyuncs.com/courses/610/1998.csv.bz2
(2)然后使用解压命令解压
bunzip2 1998.csv.bz2
当您使用解压缩命令时,提取的 CSV 数据文件位于工作目录中。默认在/home/用户名目录下。
(3)同理,下载airports机场信息数据集,命令如下
wget https://labfile.oss.aliyuncs.com/courses/610/airports.csv
3\。数据清洗
由于 airports 数据集包含一些不寻常的字符,我们需要对其进行清理,以防止某些记录字符的无法识别的错误导致后续检索错误。
OpenRefine 是谷歌开发的开源数据清洗工具。我们先在环境中安装它:
wget https://labfile.oss.aliyuncs.com/courses/610/openrefine-linux-3.2.tar.gz
tar -zxvf openrefine-linux-3.2.tar.gz
cd openrefine-3.2
启动命令
./细化
出现下图提示信息时,在浏览器中打开网址 http://127.0.0.1:3333/ 。
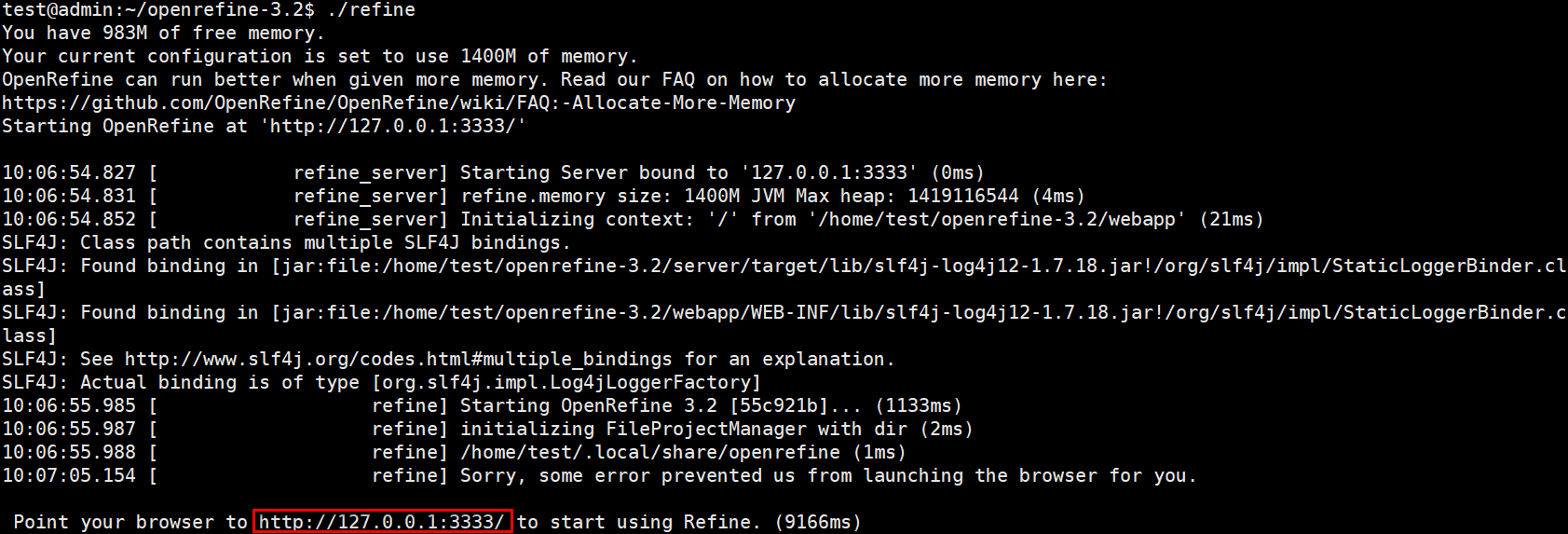
Open Refine 的成功启动以将浏览器指向 http://127.0.0.1:3333 以开始使用 Refine 为标志。
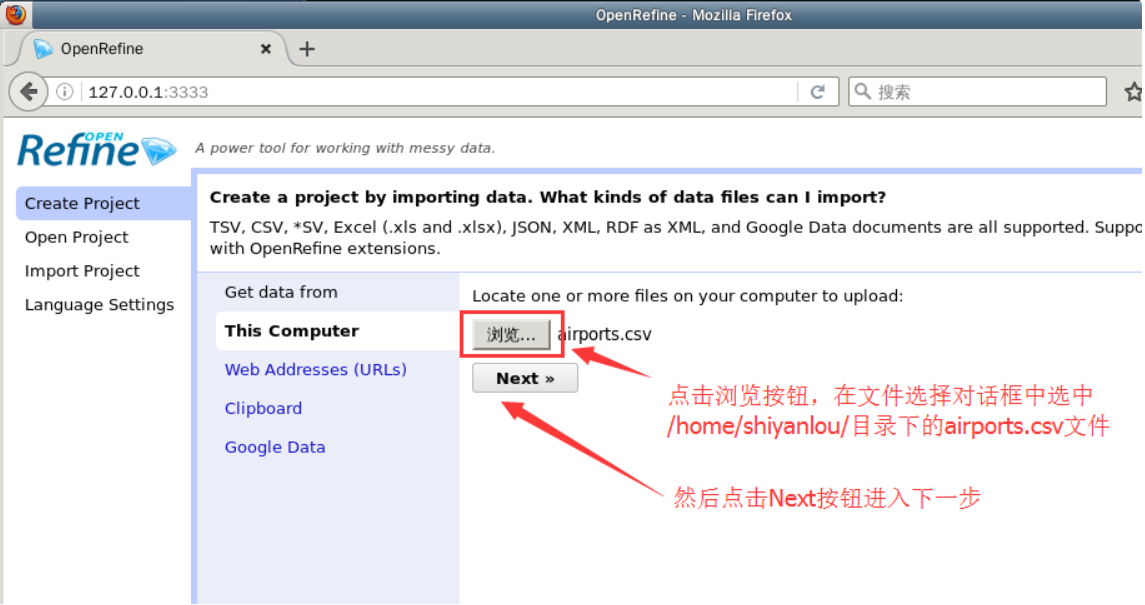
OpenRefine 的应用程序网页会出现在浏览器中,如下图所示。请选择刚刚下载的机场信息数据集,点击下一步按钮进入下一步。
在数据分析步骤中,直接点击右上角的创建项目按钮,创建一个数据清洗项目。
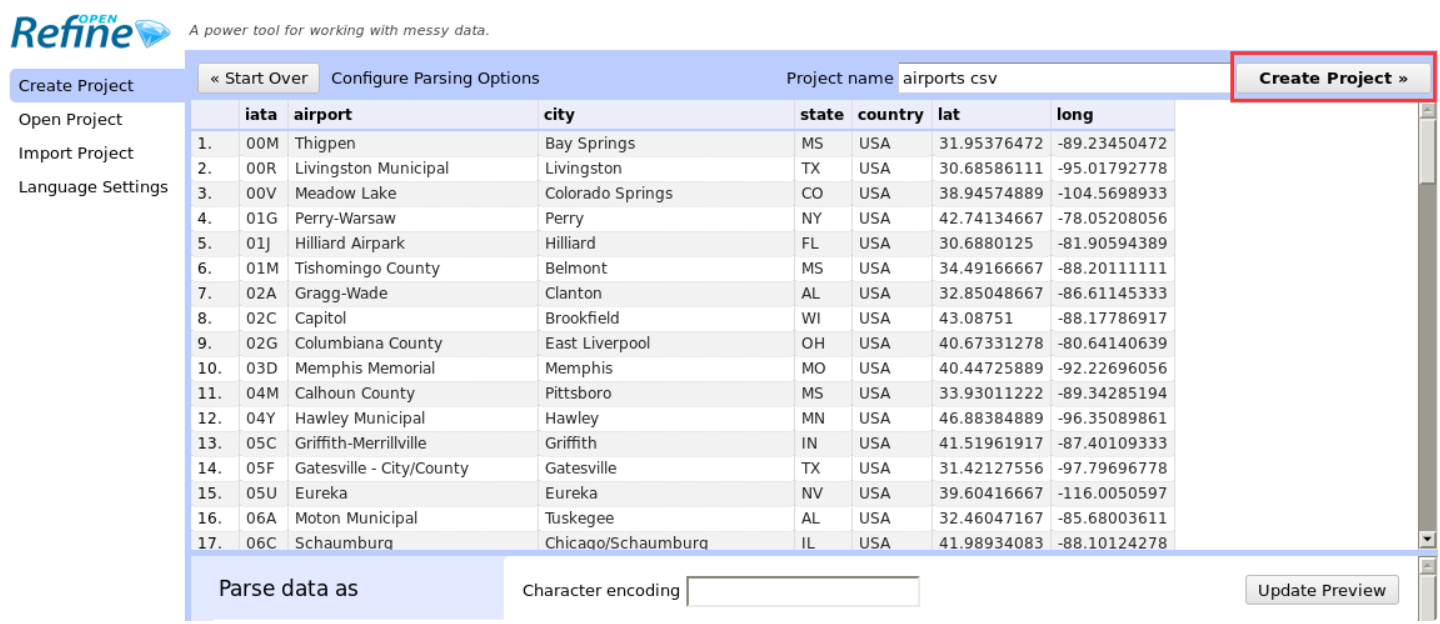
稍等片刻,您就可以对项目创建后的数据进行各种操作了。稍后将提供有关 OpenRefine 的详细教程。在这里,您只需要按照提示对数据集进行相应的操作即可。
点击机场栏旁边的下拉菜单按钮,然后在菜单中选择编辑栏->删除此栏选项,即可删除机场栏。具体操作如下图所示。
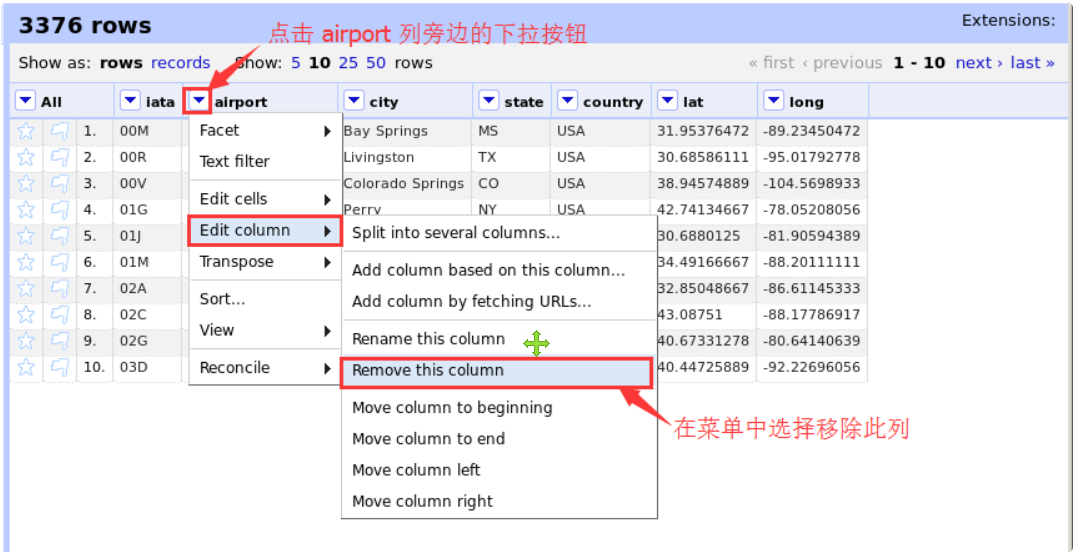
以同样的方式,删除 lat 和 long 列。最终的数据集应该只包含四列:iata、city、state 和 country。
最后,我们点击右上角的导出按钮来导出数据集。选择逗号分隔值作为导出选项,即 CSV 文件。
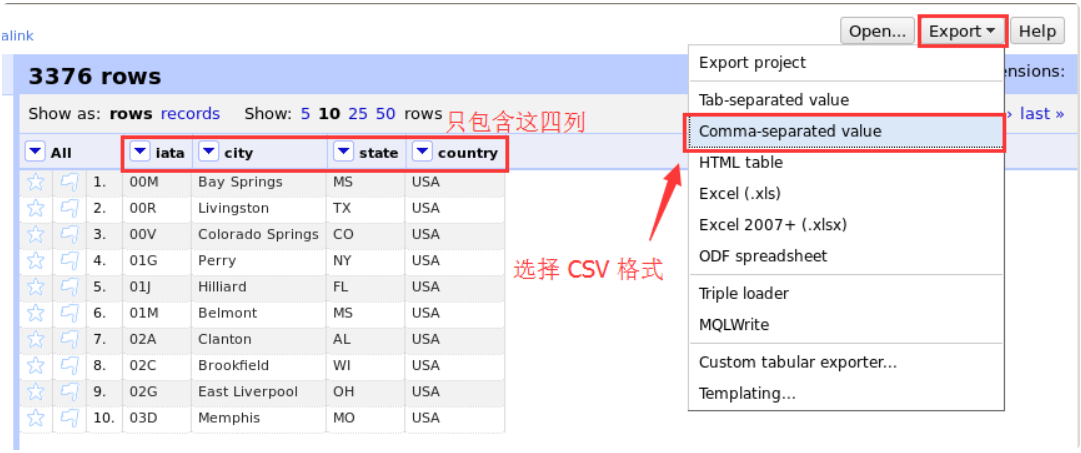
然后在弹出的下载提示对话框中选择“保存文件”并确认。
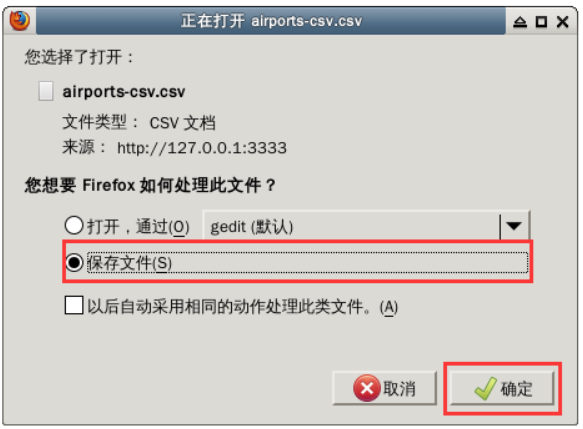
该文件位于/home/用户名/下载目录下。请在文件管理器中切到/home/用户名目录,覆盖源文件。步骤如下图所示。
首先,双击打开桌面上的home文件夹,找到下载目录。右键单击 CSV 文件并选择剪切。
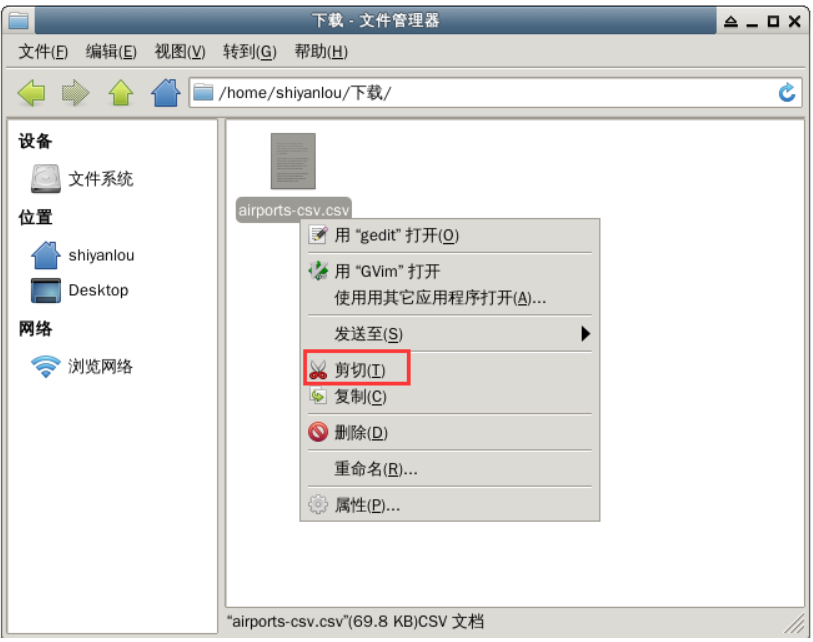
然后回到主目录,在空白处右击选择“粘贴”。
最后,关闭浏览器和运行 OpenRefine 的终端。
4\。启动 Spark Shell
为了更好的处理CSV格式的数据集,我们可以直接使用DataBricks公司提供的第三方Spark CSV解析库来读取。
首先是启动 Spark Shell。启动的同时附上参数--packages com databricks:spark-csv_2.11:1.1.0
spark-shell --packages com.databricks:spark-csv_2.11:1.1.0
5\。导入数据和处理格式
Spark Shell 启动后,输入以下命令导入数据集。
val sqlContext u003d 新的 org.apache.spark.sql.SQLContext(sc)
val flightData u003d sqlContext.read.format("com.databricks.spark.csv").option("header","true").load("/home/shiyanlou/1998.csv")
上述命令中,我们调用了sqlContext提供的读取接口,并指定加载格式格式为第三方库com databricks中定义的格式。火花。 .csv同时设置了一个read选项,header为true,表示将数据集中第一行的内容解析为字段名。最后,load方法表明要读取的数据集文件就是我们刚刚下载的数据集。
此时flightData的数据类型为Spark SQL中常用的DataFrame。将 flightData 注册为临时表。命令是:
flightData.registerTempTable("航班")
使用相同的方法导入机场信息数据集 airports CSV 并将其注册为临时表。
val airportData u003d sqlContext.read.format("com.databricks.spark.csv").option("header","true").load("/home/shiyanlou/airports-csv.csv")
airportData.registerTempTable("机场")
2、数据探索
1\。问题设计
在探索数据之前,我们已经知道数据共有 29 个字段。根据出发时间、出发/到达延误等信息,我们可以大胆提出以下问题:
-
**每天航班最繁忙的时段是什么** 通常早晚容易出现大雾等极端天气。中午有更多到达和离开的航班吗?
-
**哪里的航班最准点** 在设计旅行计划的时候,如果有两个相邻的机场到达某个目的地,好像我们可以比较一下哪个更准时,从而减少可能的延误对我们旅行的影响。
-
**哪些地区是延误发车的重灾区** 同理,哪里最容易延误?下次从这些地方出发,要考虑是否要改成地面交通。
2\。解决问题
我们已经将数据注册为临时表,而上述问题的答案其实就变成了如何设计合适的SQL查询语句。当数据量非常大时,Spark SQL 使用起来特别方便。可以直接从HDFS等分布式存储系统中拉取数据进行查询,最大限度地利用集群性能进行查询计算。
(1) 每天航班最繁忙的时段是什么时候
在分析一个问题时,我们应该想办法在数据集的每个索引上实现问题答案的来源。当问题不够详细时,可以取一些有代表性的数值作为问题的答案。
例如,航班分为到达航班和出发航班。如果统计每天某个时间段内所有机场的出发航班数量,可以反映该时间段的航班在某个程序中是否繁忙。
数据集中的每一条记录都只是简单地反映了飞行的基本情况,但它们并没有直接告诉我们每天和每个时间段发生了什么。为了得到后面的信息,我们需要对数据进行过滤和统计。
因此,我们自然会用到AVG(平均值)、COUNT(计数)和SUM(SUM)等统计函数。
为了按时间段统计航班数量,我们可以将一天中的时间大致分为以下五个时间段:
-
清晨(00:00-06:00):这段时间大部分人都在休息,所以我们可以合理地假设这段时间的航班较少。
-
上午(06:01-10:00):部分早课选择在这个时间开始,机场通常从这个时间开始逐渐进入高峰。
-
中午(10:01 - 14:00):早上从住处出发的人通常在这个时间到达机场,所以这个时间开始的航班可能会比较多。
-
下午(14:01-19:00):同样是下午开始比较方便。当你到达目的地时,已经是傍晚了,但还不算太晚。找个地方住很方便。
-
傍晚(19:01-23:59):一天结束时,接近凌晨的航班可能比较少。
当我们需要的数据不是单个离散数据而是基于一定范围时,我们可以使用关键字 BETWEEN x AND y 来设置数据的起止范围。
有了上面的准备,我们可以试着写出起飞时间在0:00到6:00之间的航班总数。第一个选定的目标是航班表,即 FROM 航班。 FlightNum上可以统计航班总数(使用COUNT函数),即COUNT(FlightNum)。限定条件是出发时间在0(代表00:00)和600(代表6:00)之间,即WHERE DepTime BETWEEN 0 AND 600。所以我们要写的是:
val queryFlightNumResult u003d sqlContext.sql("SELECT COUNT(FlightNum) FROM FROM WHERE DepTime BETWEEN 0 AND 600")
查看结果之一:
queryFlightNumResult.take(1)

在此基础上,我们可以细化,计算平均每天的出发航班数,每次只选择一个月的数据。这里我们选择从 10:00 到 14:00 的时间段。
// COUNT(DISTINCT DayofMonth) 用于计算每个月的天数
val queryFlightNumResult1 u003d sqlContext.sql("SELECT COUNT(FlightNum)/COUNT(DISTINCT DayofMonth) 从航班 WHERE Month u003d 1 AND DepTime BETWEEN 1001 AND 1400")
查询结果只有一个,即当月平均每天的出发航班数。查看:
queryFlightNumResult1.take(1)

您可以尝试计算其他时间段的平均出发航班数并保留记录。
最终统计结果显示,1998 年 1 月,一天中最繁忙的时间是下午。这一时期的平均出港航班数量为4356.7架次。
(2) 最准时的航班在哪里
这取决于哪个航班最准时。其实就是计算航班的准时到达率。您可以查看到达延迟时间为0的航班先去哪里。
在上面的句子中,有几条消息:
-
要查询的主要信息是目的地代码。
-
信息来源是航班表。
-
arr0的查询条件到达时间为延迟。
面对任何问题,我们都可以按照上面的思路对问题进行拆解,然后将每条信息转换成对应的SQL语句。
所以我们最终可以得到这样一个查询代码:
val queryDestResult u003d sqlContext.sql("SELECT DISTINCT Dest, ArrDelay FROM 航班 WHERE ArrDelay u003d 0")
取出五个结果,看看。
queryDestResult.head(5)

在此基础上,我们尝试增加更多的限制。
我们可以统计延误时间为0(准点次数)的到达航班数量,最终输出结果为[destination, on-time times],并按降序排列。
val queryDestResult2 u003d sqlContext.sql("SELECT DISTINCT Dest, COUNT(ArrDelay) AS delayTimes FROM where ArrDelay u003d 0 GROUP BY Dest ORDER BY delayTimes DESC")
查看 10 个结果。
queryDestResult2.head(10)

在美国,一个州通常有多个机场。上一步得到的查询结果根据目的地的机场代码输出。那么每个州有多少准时到达的航班呢?
基于前面的查询,我们可以再次进行嵌套查询。另外,我们将使用另一个数据集机场中的信息:目的地中的三字代码(Dest)就是数据集中的国际航空运输协会代码(iata),每个机场都给出了其状态的信息(状态)。我们可以通过连接操作将 airports 表添加到查询中。
val queryDestResult3 u003d sqlContext.sql("SELECT DISTINCT state, SUM(delayTimes) AS s FROM (SELECT DISTINCT Dest, COUNT(ArrDelay) AS delayTimes FROM Flights WHERE ArrDelay u003d 0 GROUP BY Dest) a JOIN airports b ON a.Dest u003d b.iata GROUP BY state ORDER BY s DESC")
查看 10 个结果。
queryDestResult3.head(10)
! zoz100076](https://programming.vip/images/doc/77c41095d611543383a43badc3fe67e2.jpg)
最后,您还可以将结果以 CSV 格式输出并保存在用户的主目录中。
// QueryDestResult.csv 只是保存结果的文件夹的名称
queryDestResult3.rdd.saveAsTextFile("/home/shiyanlou/QueryDestResult.csv")
保存后,我们还需要手动合并成一个文件。打开一个新的终端,在终端中输入以下命令来合并文件。
# 进入结果文件所在目录
cd ~/QueryDestResult.csv/
使用通配符将每个部分文件的内容附加到结果 CSV 文件中
猫部分-* >> result.csv
最后,打开结果在CSV文件中可以看到最终的结果,如下图所示。
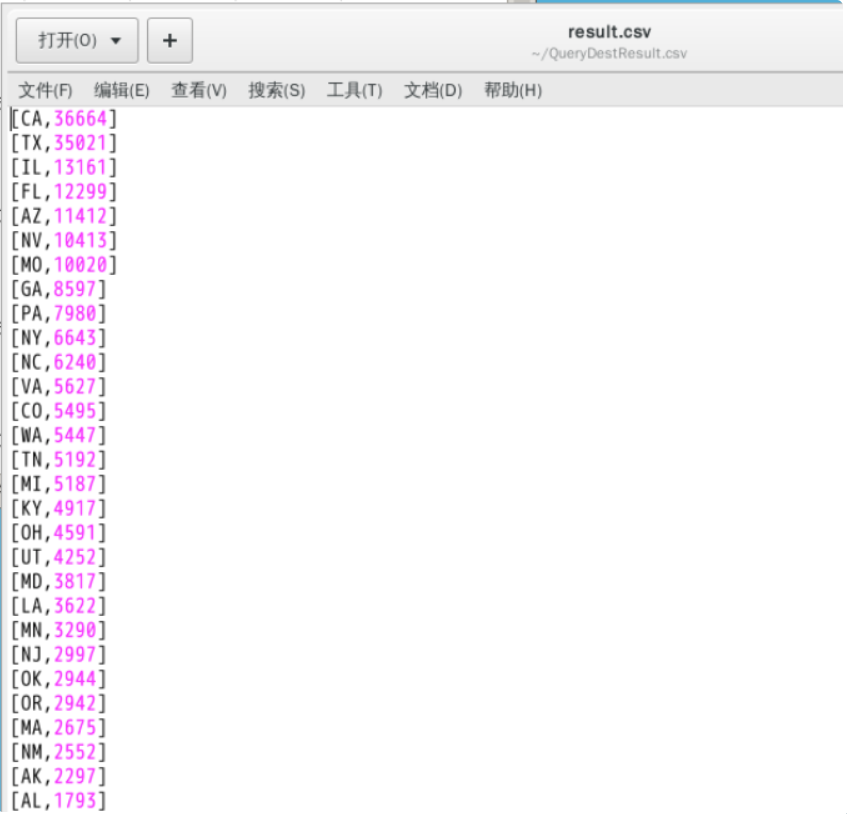
(三)发车延误重灾区有哪些
可以大胆设置发车延误大于60分钟的查询条件,查询语句编写如下:
val queryOriginResult u003d sqlContext.sql("SELECT DISTINCT Origin, DepDelay FROM 航班 DepDelay > 60 ORDER BY DepDelay DESC")
因为数据已经按降序排列,所以我们取出前10个查询结果,即1998年延误最严重的10个航班和始发机场。
queryOriginResult.head(10)

3、航班延误时间预测
1\。介绍
历史数据是对过去发生的事情的记录。我们可以根据历史数据来总结过去。那么我们可以以此来展望未来吗?
也许你首先想到的是预测。说到预测,我们不得不提到最流行的学科之一——机器学习。预测也是机器学习相关知识可以完成的任务之一。
作为数据分析师,学习机器学习的主要目的并不是对机器学习算法进行全方位的改进(机器学习专家正在为此努力)。最低要求应该是能够将机器学习算法应用于实际的数据分析问题。
2\。引入相关包
导入 org.apache.spark._
导入 org.apache.spark.rdd.RDD
导入 org.apache.spark.mllib.util.MLUtils
导入 org.apache.spark.mllib.linalg.Vectors
导入 org.apache.spark.mllib.regression.LabeledPoint
导入 org.apache.spark.mllib.tree.DecisionTree
导入 org.apache.spark.mllib.tree.model.DecisionTreeModel
3\。将 DataFrame 转换为 RDD
Spark ML 中的大多数操作都基于 RDD(分布式弹性数据集)。我们之前读入的数据集的数据类型是DataFrame。 DataFrame 中的每条记录对应于 RDD 中的每一行值。为此,我们需要将 DataFrame 转换为 RDD。
首先,将数据从 DataFrame 类型转换为 RDD 类型。从行取值时,根据数据集中的每个字段取出Flight类中对应字段的值。例如第二行的row(3)取出DataFrame中DayOfWeek字段的值,对应Flight类中的DayOfWeek成员变量。
val tmpFlightDataRDD u003d flightData.map(row u003d> row(2).toString+","+row(3).toString+","+row(5).toString+","+row(7).toString+"," +row(8).toString+","+row(12).toString+","+ row(16).toString+","+row(17).toString+","+row(14).toString+"," +row(15).toString).rdd
接下来需要创建一个类,将RDD中的一些字段映射到类的成员变量上。
案例类 Flight(dayOfMonth:Int, dayOfWeek:Int, crsDepTime:Double, crsArrTime:Double, uniqueCarrier:String, crsElapsedTime:Double, origin:String, dest:String, arrDelay:Int, depDelay:Int, delayFlag:Int)
在 Flight 类中,最后一个成员变量是 delayFlag。通过对数据的观察,我们知道有些航班的延误时间只有几分钟(无论是出发还是到达),通常这样的延误是可以容忍的。为了减少要处理的数据量,我们可以将延误定义为出发或到达的延误时间大于半小时(即30分钟),从而将到达延误时间和出发延误时间简化为延迟标志。
您可以先尝试编写伪代码:
如果 ArrDelayTime 或 DepDelayTime > 30
延迟标志 u003d 真
其他
延迟标志 u003d 假
然后我们根据上面的逻辑定义一个分析方法。该方法用于将 DataFrame 中的记录转换为 RDD。
def parseFields(输入:字符串):Flight u003d {
val line u003d input.split(",")
// 过滤可能的无效值“NA”
var diamonth u003d 0
如果(线(0)!u003d“NA”){
dayOfMonth u003d line(0).toInt
}
var dayOfWeek u003d 0
如果(线(1)!u003d“NA”){
dayOfWeek u003d line(1).toInt
}
其中 crsDepTime u003d 0.0
如果(第(2)行!u003d“NA”){
crsDepTime u003d line(2).toDouble
}
其中 crsArrTime u003d 0.0
如果(第(3)行!u003d“NA”){
crsArrTime u003d line(3).toDouble
}
var crsElapsedTime u003d 0.0
如果(第(5)行!u003d“NA”){
crsElapsedTime u003d line(5).toDouble
}
其中 arrDelay u003d 0
如果(第(8)行!u003d“NA”){
arrDelay u003d line(8).toInt
}
var depDelay u003d 0
如果(第(9)行!u003d“NA”){
depDelay u003d line(9).toInt
}
//根据延迟时间判断延迟标志是否为1
其中延迟标志 u003d 0
if(arrDelay > 30 || depDelay > 30){
延迟标志 u003d 1
}
Flight(dayOfMonth, dayOfWeek, crsDepTime, crsArrTime, line(4), crsElapsedTime, line(6), line(7), arrDelay, depDelay, delayFlag)
}
解析方法定义完成后,我们使用map操作解析RDD中的字段。
val flightRDD u003d tmpFlightDataRDD.map(parseFields)
可以尝试随机取一个值来检查解析是否成功。
flightRDD.take(1)
! zwz 100085 zwz 100086 zwz 100084
4\。提取特征
为了建立分类模型,我们需要提取飞行数据的特征。在刚才解析数据的步骤中,我们设置了delayFlag来定义两个类进行分类。因此,您可以将其称为标签,这是分类中的常用手段。有两种标签。如果delayFlag为1,则表示航班延误;如果为0,则表示没有延迟。区分延误的标准如前所述:到达或离开的延误是否超过30分钟。
对于数据集中的每条记录,它们现在都包含标签和特征信息。特征是 Flight 类中每条记录对应的所有属性(从 dayOfMonth 到 delayFlag)。
接下来,我们需要将这些特征转换为数值特征。在 Flight 类中,有些属性已经是数值特征,而 AS crsDepTime 和 uniqueCarrier 等属性不是数值特征。在这一步中,我们必须将它们转换为数字特征。例如,uniqueCarrier 特征通常是航空公司代码(“WN”等)。我们将它们依次编号,并将字符串类型的特征转换为具有唯一ID的数字特征(例如,“AA”变为0,“AS”变为1,等等。实际操作按字母顺序标记)。
变量 id: Int u003d 0
var mCarrier: Map[String, Int] u003d Map()
flightRDD.map(flight u003d> flight.uniqueCarrier).distinct.collect.foreach(x u003d> {mCarrier +u003d (x -> id); id +u003d 1})
计算完之后,我们来看看在运营商中是否已经完成了从代表航空公司代码的字符串到对应唯一ID的转换。
mCarrier.toString

按照同样的逻辑,我们需要将字符串转换为 Origin 和 Dest 的值。
首先,转换Origin:
变量 id_1: Int u003d 0
var mOrigin: Map[String, Int] u003d Map()
// 这里的原点相当于一个“全局”变量,我们在每个地图中都在修改它
flightRDD.map(flight u003d> flight.origin).distinct.collect.foreach(x u003d> {mOrigin +u003d (x -> id_1); id_1 +u003d 1})
最后是转换Dest。不要忘记我们转换的目的是建立数字特征。
变量 id_2: Int u003d 0
var mDest: Map[String, Int] u003d Map()
flightRDD.map(flight u003d> flight.dest).distinct.collect.foreach(x u003d> {mDest +u003d (x -> id_2); id_2 +u003d 1})
到目前为止,我们已经准备好所有功能。
5\。定义特征数组
在上一步中,我们使用不同的数字来表示不同的特征。这些特征最终会被放入数组中,可以理解为建立特征向量。
接下来,我们将所有标签(延迟与否)和特征以数字形式存储在新的 RDD 中,作为机器学习算法的输入。
val featuresRDD u003d flightRDD.map(flight u003d> {
val vDayOfMonth u003d flight.dayOfMonth - 1
val vDayOfWeek u003d flight.dayOfWeek - 1
val vCRSDepTime u003d flight.crsDepTime
val vCRSArrTime u003d flight.crsArrTime
val vCarrierID u003d mCarrier(flight.uniqueCarrier)
val vCRSElapsedTime u003d flight.crsElapsedTime
val vOriginID u003d mOrigin(flight.origin)
val vDestID u003d mDest(flight.dest)
val vDelayFlag u003d flight.delayFlag
// 在返回值中,所有字段都转换为Double类型,方便建模时使用相关API
数组(vDelayFlag.toDouble、vDayOfMonth.toDouble、vDayOfWeek.toDouble、vCRSDepTime.toDouble、vCRSArrTime.toDouble、vCarrierID.toDouble、vCRSElapsedTime.toDouble、vOriginID.toDouble、vDestID.toDouble)
})
经过映射阶段后,我们得到了数组的所有特征。
尝试获取其中一个值以查看转换是否成功。
精选RDD.take(1)

6\。创建标记点
在这一步中,我们需要将包含特征数组的 featuresRDD 转换为 org apache。火花。 mllib.回归。标签点包中定义的标记点LabeledPoints的新RDD。在分类中,标记点包含两种信息:一种表示数据点的标记,另一种表示特征向量类。
让我们完成这个转换。
// Label 设置为 DelayFlag,Features 设置为所有其他字段的值
val LabeledRDD u003d featuresRDD.map(x u003d> LabeledPoint(x(0), Vectors.dense(x(1), x(2), x(3), x(4), x(5), x(6) ), x(7), x(8))))
尝试获取其中一个值以查看转换是否成功。
标记为 RDD.take(1)

回顾之前的工作:我们得到了带有延迟标志的数据。所有航班都可以标记为延误或无延误。接下来,我们将使用随机划分的方法将上述数据划分为训练集和测试集。
以下是秤的详细说明:
-
LabeledRDD中,DelayFlag u003d 0标记的数据为非延误航班;标有DelayFlag u003d 1 的数据为延误航班。
-
80%的非延误航班将与所有延误航班形成一个新的数据集。 70% 和 30% 的新数据集将分为训练集和测试集。
-
不直接使用LabeledRDD中的数据来划分训练集和测试集的目的是为了尽可能提高延误航班在测试集中的比例,让训练出来的模型更准确地描述延误。
因此,我们首先在 LabeledRDD 中提取所有非延误航班,然后随机提取其中的 80%。
//(0)最后是拿80%的部分
val notDelayedFlights u003d LabeledRDD.filter(x u003d> x.label u003du003d 0).randomSplit(Array(0.8, 0.2))(0)
然后我们提取所有延误的航班。
val delayFlights u003d LabeledRDD.filter(x u003d> x.label u003du003d 1)
将以上两者组合成一个新的数据集,用于后续划分训练集和测试集。
val tmpTTData u003d notDelayedFlights ++ 延迟飞行
最后,我们按照约定的比例将数据集随机分为训练集和测试集。
// TT 表示训练和测试
val TTData u003d tmpTTData.randomSplit(Array(0.7, 0.3))
val trainingdate u003d Ttdate(0)
val 测试数据 u003d Ttdata(1)
7\。训练模型
接下来,我们将从训练集中提取特征。此处将使用 Spark MLlib 中的决策树。决策树是一种预测模型,表示对象属性与对象值之间的映射关系。你可以百度百科详细了解决策树的原理。
希望大家在进行下一个工作之前,可以花点时间了解一下决策树,从而更好的理解各种参数设置的含义。
在官方文档中,决策树的参数分为三类:
-
问题规范参数:这些参数描述了要解决的问题和数据集。我们需要设置categorialfeaturesinfo,它表明哪些特征已经被定义以及这些特征可以取多少显式值。返回值是一个 Map。例如,Map (0 - > 2, 4 - > 10) 表示特征 0 有 2 个值(0 和 1),特征 4 有 10 个值(从 0 到 9)。
-
停止条件:这些参数决定了树的构建何时停止(即停止添加新节点)。我们需要设置maxDepth,它代表树的最大深度。更深的树可能更具表现力,但也更难训练且更容易过度拟合。
-
可调参数:这些参数是可选的。我们需要设置两个。第一个是maxBins,表示使用离散连续特征时的桶信息量。二是杂质,表示选择候选分支时的杂质程度。
我们要训练的模型是建立输入特征和标记输出之间的关系。要使用的方法是决策树类DecisionTree的trainClassifier方法。通过使用这种方法,我们可以得到一个决策树模型。
让我们尝试构建训练逻辑。
// 按照API文档中的提示构造各种参数
var paramCateFeaturesInfo u003d Map[Int, Int]()
// 第一个特征信息:下标为0,表示dayOfMonth有0到30的值。
paramCateFeaturesInfo +u003d (0 -> 31)
// 第二个特征信息:下标为1,表示dayOfWeek有0到6的值。
paramCateFeaturesInfo +u003d (1 -> 7)
// 第三个和第四个特征是出发和到达时间,这里我们不会用到,所以省略。
// 第五个特征信息:下标为4,表示uniqueCarrier的所有值。
paramCateFeaturesInfo +u003d (4 -> mCarrier.size)
// 第六个特征信息是飞行时间,同样忽略。
// 第七个特征信息:下标为6,表示所有值的origin。
paramCateFeaturesInfo +u003d (6 -> mOrigin.size)
// 第八个特征信息:下标7表示dest的所有值。
paramCateFeaturesInfo +u003d (7 -> mDest.size)
// 类别数为2,分别代表延误航班和非延误航班。
val paramNumClasses u003d 2
// 以下参数设置为经验值
val 参数最大深度 u003d 9
val paramMaxBins u003d 7000
Vala Paramimpuritya u003d "几内亚"
参数构建完成后,我们调用trainclassifier方法进行训练。
val flightDelayModel u003d DecisionTree.trainClassifier(trainingData,paramNumClasses,paramCateFeaturesInfo,paramImpurity,paramMaxDepth,paramMaxBins)
训练结束后,我们可以尝试打印出决策树。
val tmpDM u003d flightDelayModel.toDebugString
打印(tmpDM)
执行结果如下图所示。此处不显示所有结果。
! swz 100106 swz 100107 swz 100105
决策树的内容看起来像一个多分支结构。如果你有足够的耐心,你可以在草稿纸上一一画出决定的条件。根据以上条件,我们可以预测未来的一个输入值。当然,预测的结果是会有延迟或者没有延迟。
8\。测试模型
模型训练完成后,我们还需要测试模型的构建效果。因此,最后一步是用测试集测试模型。
// 使用决策树模型的predict方法根据输入进行预测,预测结果暂存在tmpPredictResult中。最后以输入信息的标记形成元祖,作为最终的返回结果。
val predictResult u003d testData.map{flight u003d>
val tmpPredictResult u003d flightDelayModel.predict(flight.features)
(flight.label, tmpPredictResult)
}
尝试取出10组预测结果,看看效果。
predictResult.take(10)
执行结果如下图所示。
! swz 100109 swz 100110 swz 100108
可以看出,如果Label的0.0对应PredictResult的0.0,则预测结果是正确的。并不是每个预测都是准确的。
val numOfCorrectPrediction u003d predictResult.filter{case (label, result) u003d> (label u003du003d result)}.count()
执行结果如下图所示。

最后,计算预测的准确率:
// toDouble 用于提高准确率的准确率。否则,两个 long 值相除仍然是 long 值。
val predict Accuracy u003d numO CorrectPrediction/test Data.count().toDouble
执行结果如下图所示。

我们得到模型的预测准确率约为 85.77%。可以说在实际预测中具有一定的应用价值。为了提高预测的准确性,可以考虑使用更多的数据进行模型训练,在构建决策树时将参数调整到最佳。
因为每次随机划分过程中数据集都会不同,这里的预测精度仅供参考。如果结果超过 80%,则可以视为项目的目标。
9、D3.js可视化编程
数据可视化的目的是让数据更可信。如果我们盯着一堆表格和数字,我们很可能会忽略一些重要的信息。作为数据的一种表达方式,数据可视化可以帮助我们找到一些从数据表面不容易看到的信息。
事实上,在此之前,我们或多或少地接触过数据可视化。最简单的数据可视化是我们在Microsoft Office Excel中制作的直方图、折线图、饼图等。数据可视化不是关于图表有多酷,而是如何更形象地表达复杂的数据。
D3的全称是Data-Driven Documents,字面意思是Data-Driven Documents。它本身就是一个JavaScript函数库,可以用于数据可视化。
让我们用一个轻量级的例子来学习如何在美国地图上显示每个州的准点航班数量以及它们的整体繁忙程度。
(1) 创建项目目录和文件
双击桌面打开终端,下载课程所需的D3 JS等javascript脚本文件。
wget https://labfile.oss.aliyuncs.com/courses/610/js.tar.gz
然后解压。
tar zxvf js.tar.gz
现在让我们创建项目所需的目录和文件。首先,创建一个名为 DataVisualization 的新项目目录。所有的网页、js文件和数据都存放在这个目录下。
mkdir 数据可视化
进入新创建的目录,分别创建data和js两个目录来存放CSV数据和js文件,最后再创建一个目录index HTML网页文件。
cd 数据可视化
mkdir 数据
mkdir js
触摸 index.html
数据可视化的数据来自于我们保存在 /home/shiyanlou/querydestresult 中的数据 CSV/目录 CSV 文件中的结果。我们将其复制到当前项目目录下的data文件夹中。
cp ~/QueryDestResult.csv/result.csv ~/DataVisualization/data
对于整个项目,我们需要在索引中调用 D3。在html网页js中编写主要的数据可视化逻辑。并添加相应的html元素来显示数据可视化结果。因此,我们还需要将之前解压出来的两个js文件复制到项目目录的js文件夹中。
cp ~/js/* ~/DataVisualization/js
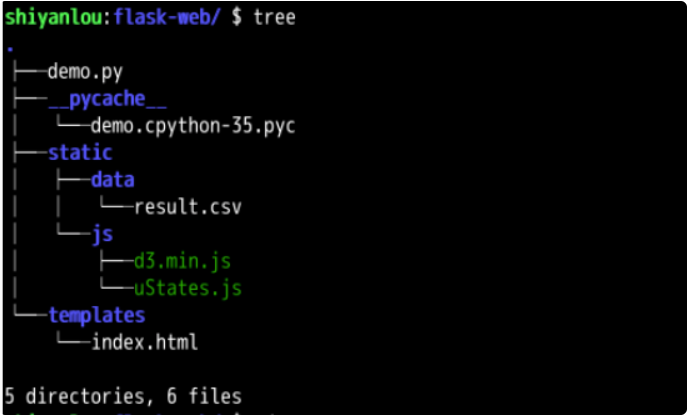
最后,我们使用tree命令查看项目目录的文件结构。
树。
! zwz 100121 zwz 100122 zwz 100120
(2) 数据完整性检查
首先,删除 CSV 文件中每行开头和结尾的结果括号:
sed -i "s/\[//g" ~/DataVisualization/data/result.csv
sed -i "s/\]//g" ~/DataVisualization/data/result.csv
通常,绘图容易出错,因为数据包含无效或缺失值。
避免此类错误的方法有两种:一种是通过程序进行容错处理;二是检查数据的完整性,弥补无效或缺失值。
为简单起见,我们直接通过文本编辑器修改数据。
请使用 gedit 文本编辑器打开数据文件。
gedit ~/DataVisualization/data/result.csv
第一步是将字段名称添加到 CSV 文件。请在第一行的两列数据中添加字段:StateName 和 ontimeflightnum。详情如下图所示(注意大小写)。
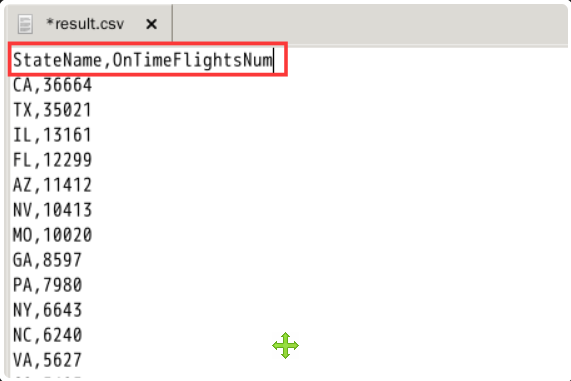
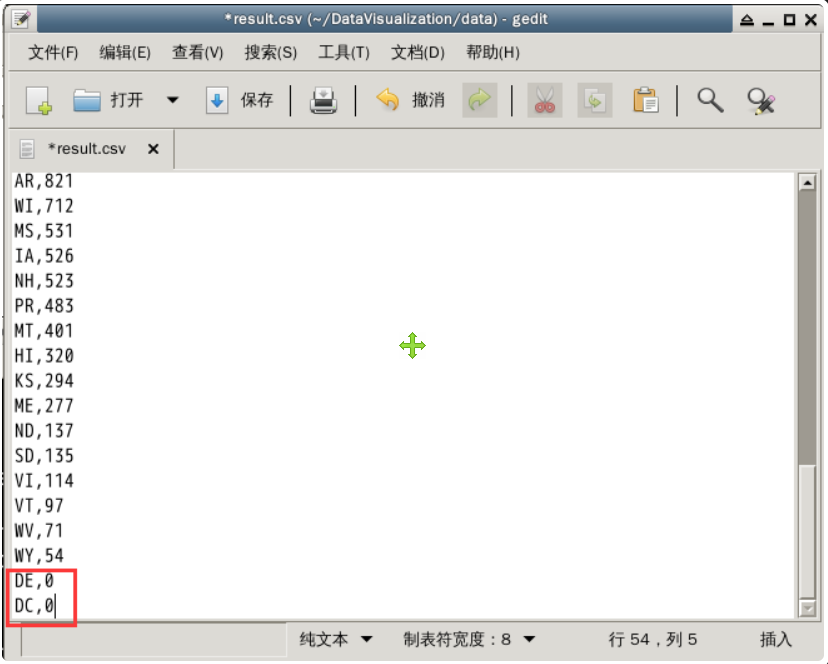
对比美国的州名列表,我们可以发现 CSV 中仍然缺少华盛顿特区 (DC) 和特拉华州 (DE) 的信息。我们将它们添加到文件末尾,并将准点航班数设置为0,如下图所示。
(3) 编辑索引html
指数。在 HTML 中,我们需要插入一些基本的 HTML 元素,使它看起来更像一个网页。
请检查索引将以下内容添加到 HTML。
<!DOCTYPE html>
<html>
<头部>
<meta charsetu003d"utf-8">
<title>美国准点航班地图</title>
</head>
<正文>
</正文>
</html>
因为我们使用的是D3 JS,所以这里需要在HTML代码中引用。另外,我们还需要一个叫做usstates的JS,里面已经包含了美国各个州的轮廓数据。
请在<head>标签之间插入如下语句引用对应的js文件。
插入的代码是:
<script srcu003d"js/d3.min.js"></script>
<script srcu003d"js/uStates.js"></script>
! zwz 100130 zwz 100131 zwz 100129
我们将src属性中js文件的来源设置为网页根目录下js目录下对应的js文件。
之后,我们需要在 <body> 标签之间插入一些 HTML 元素。
下面的代码中,svg标签用于显示美国的地图,div标签用于加载提示框的相关信息。我们设置提示框所在元素的id为tooltip,地图所在元素的id为statesvg,宽高分别为960和800像素。
<!-- 应该用 div 标签来加载提示框 -->
<div idu003d"tooltip"></div>
<!-- SVG 标签用于绘制地图 -->
<svg widthu003d"960" heightu003d"800" idu003d"statesvg"></svg>
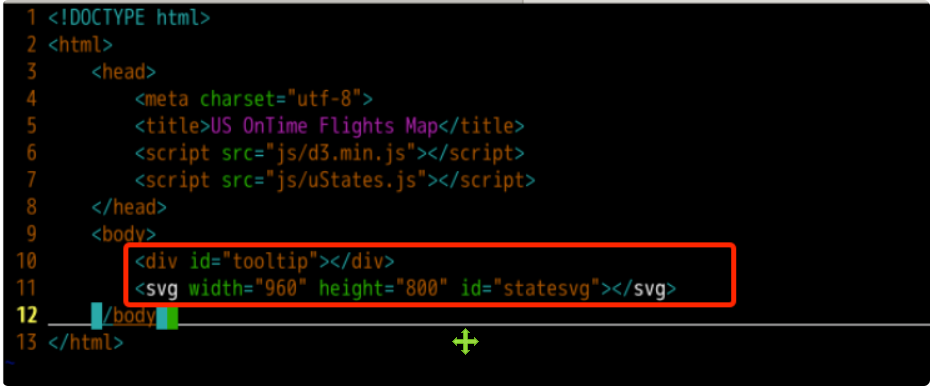
最后,我们需要准备一个脚本标签来编写与我们的数据可视化相关的逻辑代码。
请在 < body > 标签之间插入以下内容。
<脚本>
</脚本>
! zwz 100136 zwz 100137 zwz 100135
(4) 实现数据加载和可视化准备的相关功能
第一步是从 CSV 文件中读取数据。这里我们直接使用 D3 JS API 函数 D3 csv()。
在这个函数中,第一个参数是要读取的文件路径。我们设置为data/result CSV,代表项目目录下的data目录下的结果CSV文件。
第二个参数是读取后的匿名回调函数,即读取后会执行回调函数的内容(无论成功与否)。 Error 和 csvData 是必须传递的两个参数。当读取失败时,我们可以使用控制台日志(error)用于在浏览器控制台输出错误信息。读取成功后,csvData 为加载了 CSV 文件内容的变量。
请在添加的脚本标签中插入以下代码。
d3.csv("data/result.csv", function(error, csvData) {
// TODO:在此处添加文本。
});
! zwz 100139 zwz 100140 zwz 100138
我们后面需要做的一切都会在这个回调函数中完成。
为方便起见,我们将在笔记中继续讲解相关知识点。
您需要将回调函数插入以下代码。
// 创建一个Object来存储处理后的绘图数据
// 可以理解为一个包含key-value的map对象
var mapData u003d {};
// 变量sum用于存储准点航班总数
变量总和 u003d 0.0;
//第一次遍历csvData,计算总正点航班数
csvData.forEach(函数(d){
// 在forEach函数中,使用匿名函数处理每次遍历d得到的数据记录
// OnTimeFlightsNum 是我们在 CSV 文件中设置的字段名称
// 检索到的值仍然是字符串类型。我们需要将其转换为浮点数
总和 +u003d parseFloat(d.OnTimeFlightsNum);
});
// csvData的第二次遍历,用于设置绘图数据
csvData.forEach(函数(d){
// d.StateName 取出每条记录的StateName字段的值,转换成字符串作为map对象的key
var key u003d d.StateName.toString();
// d.OnTimeFlightsNum 取出每条记录的 OnTimeFlightsNum 字段的值,转换为浮点型
var vNumOfOnTimeFlights u003d parseFloat(d.OnTimeFlightsNum);
// 这里是为不同的数据设置不同级别的颜色
// D3被调用JS插值API:D3 interpolate()
// 参数“#57d2f7”和“#726dd1”为HEX类型的十六进制颜色代码,每两位分别为RGB通道的颜色深度
// 使用vNumOfOnTimeFlights / sum计算当前值占总数的比例,乘以10,颜色辨别更明显
var vColor u003d d3.interpolate("#57d2f7", "#726dd1")(vNumOfOnTimeFlights / sum * 10);
// 对于每条记录,StateName 字段的值作为 mapData 的键,以准点航班数和颜色代码作为它们的值。
mapData[key] u003d {num:vNumOfOnTimeFlights,
颜色:vColor};
});
// 绘制数据准备好后,调用uStates对象的draw函数进行绘制。
//第一个参数是选中的绘图对象,也就是我们设置的HTML标签:statesvg
// 第二个参数是我们计算的绘图数据
uStates.draw("#statesvg", mapData);
完成的代码如下图所示。
! swz 100142 swz 100143 swz 100141
(5) 在JS中实现usstates绘图功能
在 index 中以 HTML 计算绘制需要的数据,最后调用 uStates 对象的绘制函数。这里我们需要改进这张图的逻辑。
现在编辑js/usstates js文件,这是一个提前为你准备好的js文件。我们需要改进一些细节。
在目前的代码中,很多内容是变量uStatePaths的定义。在这张地图中,id 是美国各州的缩写。稍后我们将使用它来查找映射数据mapData中的准点航班数量和颜色代码; n为每个状态对应的全称,鼠标经过时会放在显示的提示框中; d 是地图上每个州的轮廓。
需要进一步说明的是,d中存储的等高线数据来自于根据美国地图制作的SVG文件。制作步骤如下:首先,根据地图服务商提供的GeoJSON数据(如谷歌地图)进行投影。 GeoJSON包含一些经纬度、海报等信息,然后使用d3 JS的投影函数对其进行投影(d3.geo.mercator()),可以在投影过程中进行缩放和平移。投影后得到二维数据,但都是点。地图的轮廓是封闭的线,所以我们还需要使用d3 JS路径生成器(d3.geo.path())将每个块的二维数据点链接起来,形成最终的地图轮廓。
通常,我们会将轮廓数据存储在 SVG 文件中,这意味着可缩放矢量图形。在这个例子中,为了简化操作步骤,数据直接给出了各个状态的信息,也就是你看到的描述信息。
翻到这段代码的最后,可以看到 usstates 中的 draw 细节还没有完成,这就是接下来需要做的事情。
请前往 usstates draw u003d function (id, data) { ... };在函数定义中补充以下内容。同样,相关的解释也会以注释的形式给出。
// vData 用于加载绘图数据
var vData u003d 数据;
// 该方法用于创建鼠标经过时显示的提示框的HTML内容(div元素)
功能添加工具提示 Html(and, d) {
//传入的n是每个状态的全称,用h4标签表示
// D为各州的绘图数据,d.num为准点航班数
返回 "<h4>" + n + "</h4><table>" +
"<tr><td>准时航班:</td><td>" + d.num + "</td></tr>"
"</table>";
}
// 当鼠标指针悬停在元素上时发生 mouseover 事件
// 这里定义了一个mouseOver函数作为这个事件的回调函数
功能鼠标悬停(d){
// 传入的d是uStatePaths中的元素
变种键 u003d d.id;
var vData u003d 数据;
// 使用 D3 JS 的 select() 函数选择 HTML 元素中带有 id tooltip 的 div 元素
// transition()函数用于启动过渡效果,可用于动画
// duration(200) 用于动画的持续时间是 200 毫秒
// style("Opacity",.9) 用于设置div元素的不透明度级别。的不透明度。 9 表示 90% 的不透明度
d3.select("#tooltip").transition().duration(200).style("不透明度", .9);
// 同理,使用html()函数调用addTooltipHtml函数,将html代码注入到tooltip元素中
// d.n代表sStatePaths中的n个成员,即每个状态的全名
// vData[key] 表示使用key查询绘图数据中各州的准点航班数
d3.select("#tooltip").html(addTooltipHtml(d.n, vData[key]))
.style("left", (d3.event.pageX) + "px")
.style("top", (d3.event.pageY - 28) + "px");
}
// 当鼠标指针不再位于元素上方时,会发生 mouseout 事件
// 这里定义了一个mouseOut函数作为这个事件的回调函数
功能鼠标输出() {
// 设置不透明度为0相当于让div元素消失
d3.select("#tooltip").transition().duration(500).style("不透明度", 0);
}
// 这里的id很快就代表svgstate元素
// 这一步设置所有状态的颜色
// .data(uStatePaths).enter().append("path") 表示使用ustatepaths中的数据绘制路径
// . style("fill", function(d) {}) 表示根据绘图数据中每个状态的颜色代码进行填充
// .on("mouseover", mouseOver).on("mouseout", mouseOut) 表示设置鼠标覆盖和鼠标移除事件的监听和回调函数
d3.select(id).selectAll(".state")
.data(uStatePaths).enter().append("path").attr("class", "state").attr("d", function(d) {
返回 d.d;
})
.style("填充", function(d) {
关键 u003d d.id;
vColor u003d 数据[键].color;
返回颜色;
})
.on("mouseover", mouseOver).on("mouseout", mouseOut);
完成的代码如下图所示:
! swz 100145 swz 100146 swz 100144
! swz 100148 swz 100149 swz 100147
(6) 样式页面元素
最后,我们需要做一些美化工作。
返回索引 HTML,将以下内容插入到 <head> 标记中。
<样式>
.状态{
填充:无;
中风:#888888;
笔画宽度:1;
}
.state:悬停{
填充不透明度:0.5;
}
#工具提示 {
位置:绝对;
文本对齐:居中;
内边距:20px;
边距:10px;
字体:12px 无衬线;
背景:轻钢蓝;
边框:1px;
边框半径:2px;
边框:1px 纯灰色;
边框半径:5px;
指针事件:无;
背景:rgba(0,0,0,0.9);
字体大小:14px;
宽度:自动;
填充:4px;
颜色:白色;
不透明度:0;
}
#工具提示 h4{
边距:0;
字体大小:20px;
}
#tooltip tr td:nth-child(1){
宽度:120 像素;
}
</style>
各个属性的作用请参考W3school。完成的代码如下图所示。
! zwz 100151 zwz 100152 zwz 100150
至此,我们所有的代码编辑工作已经完成。
最终索引HTML页面代码如下:
<!DOCTYPE html>
<html>
<头部>
<meta charsetu003d"utf-8">
<title>美国准点航班地图</title>
<script srcu003d"js/d3.min.js"></script>
<script srcu003d"js/uStates.js"></script>
<样式>
.状态{
填充:无;
中风:#888888;
笔画宽度:1;
}
.state:悬停{
填充不透明度:0.5;
}
#工具提示 {
位置:绝对;
文本对齐:居中;
内边距:20px;
边距:10px;
字体:12px 无衬线;
背景:轻钢蓝;
边框:1px;
边框半径:2px;
边框:1px 纯灰色;
边框半径:5px;
指针事件:无;
背景:rgba(0,0,0,0.9);
字体大小:14px;
宽度:自动;
填充:4px;
颜色:白色;
不透明度:0;
}
#工具提示 h4{
边距:0;
字体大小:20px;
}
#tooltip tr td:nth-child(1){
宽度:120 像素;
}
</style>
</head>
<正文>
<div idu003d"tooltip"></div>
<svg widthu003d"960" heightu003d"800" idu003d"statesvg"></svg>
<脚本>
d3.csv("data/result.csv", function(error, csvData) {
var mapData u003d {};
变量总和 u003d 0.0;
csvData.forEach(函数(d){
总和 +u003d parseFloat(d.OnTimeFlightsNum);
});
csvData.forEach(函数(d){
var key u003d d.StateName.toString();
var vNumOfOnTimeFlights u003d parseFloat(d.OnTimeFlightsNum);
var vColor u003d d3.interpolate("#57d2f7", "#726dd1")(vNumOfOnTimeFlights / sum * 10);
mapData[key] u003d {num:vNumOfOnTimeFlights,
颜色:vColor};
});
uStates.draw("#statesvg", mapData);
});
</脚本>
</正文>
</html>
(7) 项目预览
由于静态页面无法读取本地文件,直接打开index.com HTML页面无法查看页面内容。这里我们简单的使用flash来启动一个服务。
实验环境已经安装了Flash,我们可以直接使用。
在/home/shiyanlou目录下新建flash web文件夹,进入文件夹新建demo Py文件、static文件夹和templates文件夹,复制DataVisualization文件夹中的内容。最终文件目录结构如下:
在 demo 的 PY 文件中写入如下代码:
从烧瓶进口烧瓶
从烧瓶导入渲染_template
应用程序 u003d 烧瓶(__name__)
@app.route('/')
定义主页():
返回渲染_template("index.html")
并修改 index HTML 路径。主要修改如下:
<script srcu003d"../static/js/d3.min.js"></script>
<script srcu003d"../static/js/uStates.js"></script>
...
d3.csv("/static/data/result.csv", function(error, csvData) {
...
在 flash web 目录下执行以下命令启动服务:
导出烧瓶_APPu003ddemo.py
烧瓶运行
结果如下:
! swz 100157 swz 100158 swz 100156
浏览器访问地址:http://127.0.0.1:5000 美国地图。用鼠标指向每个状态,您可以看到相应的详细信息。
! swz 100163 swz 100164 swz 100162
您是否感受到数据的强大影响?
可以看到,图中颜色最深的两个状态是CA和TX。一定程度上表明,两国航空活动较为活跃。
实验总结
在本实验中,我们基于常见的DataFrame和SQL操作分析通过Spark记录的航班起降数据,找出航班延误的原因,并利用机器学习算法预测航班延误。
并使用 D3 JS,将美国各州的准点航班数量可视化。 D3 参与了实验 JS 的读取数据、插值、选择元素、设置属性和其他 API 使用。
如果您有兴趣分析其他年份的数据,您可能会发现以下有趣的现象:
-
夏季,由于雷暴等恶劣天气增多,航班延误严重。
-
冬季,由于恶劣天气较少,气候稳定,航班延误较少。
/js/d3.min.js">
...
d3.csv("/static/data/result.csv", function(error, csvData) {
...
在 flask-web 目录下执行以下命令启动服务:
```蟒蛇
导出烧瓶_APPu003ddemo.py
烧瓶运行
结果如下:
[外链图片传输...(img-qGhPNje6-1622437121584)]
浏览器访问地址:http://127.0.0.1:5000 ,显示的是美国的图片。用鼠标指向每个状态,您可以看到相应的详细信息。
[外链图片传输...(img-QXYCffVN-1622437121585)]
您是否感受到数据的强大影响?
可以看到,图中颜色最深的两个状态是CA和TX。一定程度上表明,两国航空活动较为活跃。
实验总结
在本实验中,我们基于常见的DataFrame和SQL操作分析通过Spark记录的航班起降数据,找出航班延误的原因,并利用机器学习算法预测航班延误。
并使用 D3 JS,将美国各州的准点航班数量可视化。 D3 参与了实验 JS 的读取数据、插值、选择元素、设置属性和其他 API 使用。
如果您有兴趣分析其他年份的数据,您可能会发现以下有趣的现象:
-
夏季,由于雷暴等恶劣天气增多,航班延误严重。
-
冬季,由于恶劣天气较少,气候稳定,航班延误较少。
-
9月11日恐怖袭击事件(2001年9月11日)后,航班数量急剧减少。在 9 / 11 事件中,美国航空公司和联合航空公司分别损失了两架飞机,整个航空运输暂停了三天。恢复航班后,受事件冲击,美航乘客数量在短时间内急剧收缩,甚至一班航班只有一名乘客。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20422条内容
已为社区贡献20422条内容

所有评论(0)