
蚂蚁森林植物应用统计专题(Hive示例)
蚂蚁森林植物应用统计
创建两个表
user_low_carbon:记录用户在蚂蚁森林的日常低碳生活
plant_carbon:蚂蚁森林植物交换表,用于记录申请环保植物所需的碳减排量
表结构
表格1
表\名称:用户\流\碳
用户_id 数据_dt 低_carbon
用户日期收到的碳排放量 (g)
表二
表\名称:板\碳
植物\id植物\名称低\碳
植物编号 植物名称 购买植物所需的碳
表格1
如果不存在则创建表 user_low_carbon(user_id string,date_dt string,low_carbon int)
以“”结尾的行格式分隔字段
表二
如果不存在则创建表 user_low_carbon(user_id string,date_dt string,low_carbon int)
以“”结尾的行格式分隔字段
导入数据
//用户_low_carbon.txt
u_001 2017/1/1 10
u_001 2017/1/2 150
u_001 2017/1/2 110
u_001 2017/1/2 10
u_001 2017/1/4 50
u_001 2017/1/4 10
u_001 2017/1/6 45
u_001 2017/1/6 90
u_002 2017/1/1 10
u_002 2017/1/2 150
u_002 2017/1/2 70
u_002 2017/1/3 30
u_002 2017/1/3 80
u_002 2017/1/4 150
u_002 2017/1/5 101
u_002 2017/1/6 68
......
将数据本地 inpath '/home/dt/user_low_carbon.txt' 加载到表 user_low_carbon
//植物_carbon.txt
p001 梭梭 17
p002 沙柳 19
p003 樟树 146
p004 幼发拉底河人 215
加载数据本地 INPATH '/home/dt/plant_carbon.txt' INTO TABLE plant_carbon
话题一
问题:假设用户_low_carbon数据记录在2017年1月1日,且所有符合申请条件的用户都在2017年10月1日前申请了p004胡杨,
所有剩余的能量都用于接收“p002-沙柳”。
10月1日申请“p002 Salix”的前10名用户统计;而且他收到的柳比后者多几个。
得到的统计结果如下:
结果示例
user_id plant_count less_count(他收到的柳比后者多几个)
你_101 1000 100
你_088 900 400
你_103 500 ...
sql语句
从(
选择 t3.user_id user_id,floor(t3.residue/t4.low_carbon) 作为 shaliunum
从 (
选择 t1.user_id,t1.sumres-t2.low_carbon 作为残基
从 (SELECT a.user_id,sum(a.low_carbon) 作为 sumres
-- OVER(由 a.user_id 分区)
来自用户_low_carbon a
按 a.user_id 分组为 t1,(选择低_carbon
来自植物_碳
where plant_idu003d"p004") as t2) and t3,(select low\carbon
来自植物_碳
其中植物_idu003d"p002") 为 t4
按 shaliunum desc 排序)为 tt
选择 tt.user_id,tt.shaliunum,tt.shaliunum-lead(shaliunum,1,0) over() diff,row_number() over() rownum
)
结果

话题二
蚂蚁森林低碳用户排名分析
问题:查询用户_低_碳表中的每日跑步记录,条件如下:
2017年,连续三天(或以上),
每天减少碳排放量(低碳)100g以上的用户,喝的是低碳水。
您需要查询并返回满足上述条件的用户_低_碳表中的记录流量。
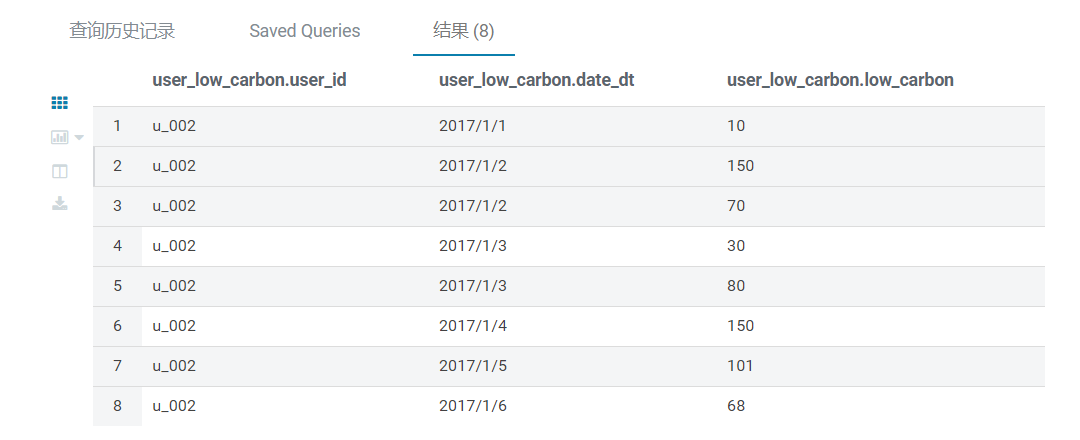
例如用户 u_002 合格记录如下,因为从 2017 年 1 月 2 日到 2017 年 1 月 5 日连续 4 天的碳排放总和大于等于 100g:
结果示例
seq(key) 用户_id 数据_dt 低_carbon
xxxxx10 u_002 2017/1/2 150
xxxxx11 u_002 2017/1/2 70
xxxxx12 u_002 2017/1/3 30
xxxxx13 u_002 2017/1/3 80
xxxxx14 u_002 2017/1/4 150
xxxxx14 u_002 2017/1/5 101
第一步是找到连续三天(或更多)的天数,
每天减少100g以上碳排放的用户。
sql语句
from(--求每天前两天的总碳量
从(
-- 去重
从(
-- 每位用户每天的总碳排放量
select user_id,date_dt,sum(low_carbon) over(partition by date_dt) carbon_byday
来自用户_low_carbon
) 作为 t
选择用户_id,日期_dt,收集_set(carbon_byday)\[0\] carbon_byday
按用户_id、日期_dt 分组
) 作为 t1
选择 t1.user_id,t1.date_dt,t1.carbon_byday,lag(carbon_byday,1,0) over(partition by user_id) 作为 carbon_lastday,
lag(carbon_byday,2,0) over(partition by user_id) as carbon_last2day,
lag(date_dt,1,0) over(partition by user_id) as lastday,
lag(date_dt,2,0) over(partition by user_id) as last2day
)as t2
选择*
--三天超过100个
其中 t2.carbon_lastday>u003d100 且 t2.carbon_byday>u003d100 且 t2.carbon_last2day>u003d100
--查看三天是否连续
和 datediff(t2.date_dt,t2.lastday)u003d1 和 datediff(t2.date_dt,t2.last2day)u003d2
运行结果

第二步,连接原表,计算连续三天超过100g的用户的流量记录
sql语句
from(from(--求每天前两天的总碳量
从(
-- 去重
从(
-- 每位用户每天的总碳排放量
select user_id,date_dt,sum(low_carbon) over(partition by date_dt) carbon_byday
来自用户_low_carbon
) 作为 t
选择用户_id,date_dt,collect_set(carbon_byday)[0] carbon_byday
按用户_id、日期_dt 分组
) 作为 t1
选择 t1.user_id,t1.date_dt,t1.carbon_byday,lag(carbon_byday,1,0) over(partition by user_id) 作为 carbon_lastday,
lag(carbon_byday,2,0) over(partition by user_id) as carbon_last2day
,lag(date_dt,1,0) over(partition by user_id) as l1,
lag(date_dt,2,0) over(partition by user_id) as l2
)as t2
选择不同的(t2.user_id)
其中 t2.carbon_lastday>u003d100 且 t2.carbon_byday>u003d100 且 t2.carbon_last2day>u003d100
和 (substr(t2.l1,8)+1)u003dsubstr(t2.date_dt,8) 和 (substr(t2.l2,8)+2)u003dsubstr(t2.date_dt,8)
) 作为 t3,user_low_carbon
选择用户_low_carbon.*
其中 t3.user_idu003duser_low_carbon.user_id
运行结果
话题 3
查找连续三天有销售记录的店铺的流水记录
原始数据
A,2017-10-11,300
A,2017-10-12,200
A,2017-10-13,100
A,2017-10-15,100
A,2017-10-16,300
A,2017-10-17,150
A,2017-10-18,340
A,2017-10-19,360
B,2017-10-11,400
B,2017-10-12,200
B,2017-10-15,600
C,2017-10-11,350
C,2017-10-13,250
C,2017-10-14,300
C,2017-10-15,400
C,2017-10-16,200
D,2017-10-13,500
E,2017-10-14,600
E,2017-10-15,500
D,2017-10-14,600
问题方案
如果不存在则创建表 xs(dp 字符串,dt 字符串,xl int)
以“,”结尾的行格式分隔字段
将数据本地 INPATH '/home/dt/xs.txt' 加载到表 xs 中
第一步,找出连续三天有销售记录的店铺
sql语句
从(
从(
从(
select dp,dt,sum(xl) over(partition by dt) xl_byday
从 xs
) 作为 t
选择 dp,dt,collect_set(xl_byday)[0] xl_byday
按 dp,dt 分组
) 作为 t1
select t1.dp,t1.dt,t1.xl_byday,lag(xl_byday,1,0) over(partition by dp) as xl_lastday,
lag(xl_byday,2,0) over(dp 分区) 为 xl_last2day,
lag(dt,1,0) over(partition by dp) as ldt,
lag(dt,2,0) over(partition by dp) as last2day
)as t2
选择*
--三天有记录
其中 t2.xl_lastday>0 和 t2.xl_byday>0 和 t2.xl_last2day>0
--查看三天是否连续
和 datediff(t2.dt,t2.ldt)u003d1 和 datediff(t2.dt,t2.last2day)u003d2
运行结果
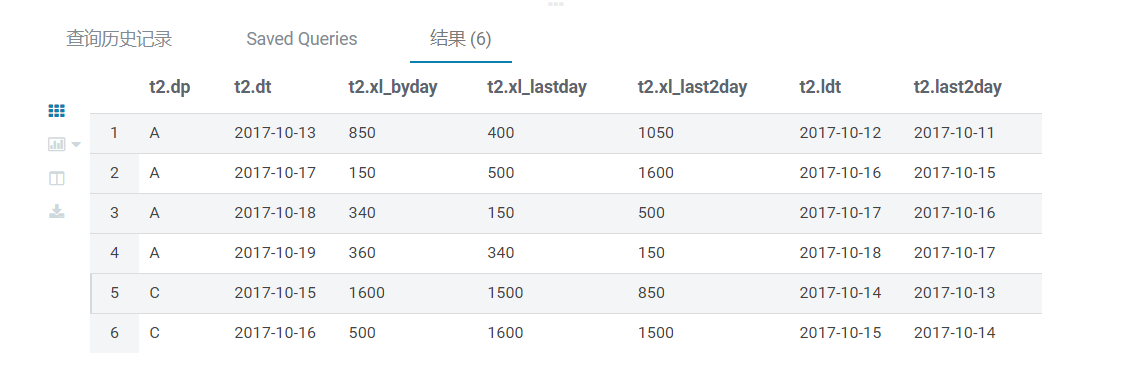
第二步,连接原表,找到连续三天有销售记录的店铺的流水记录
sql语句
从(从(
从(
从(
-- 每位用户每天的总碳排放量
select dp,dt,sum(xl) over(partition by dt) xl_byday
从 xs
) 作为 t
选择 dp,dt,collect_set(xl_byday)[0] xl_byday
按 dp,dt 分组
) 作为 t1
select t1.dp,t1.dt,t1.xl_byday,lag(xl_byday,1,0) over(partition by dp) as xl_lastday,
lag(xl_byday,2,0) over(dp 分区) 为 xl_last2day,
lag(dt,1,0) over(partition by dp) as ldt,
lag(dt,2,0) over(partition by dp) as last2day
)as t2
选择不同的(t2.dp)
其中 t2.xl_lastday>0 和 t2.xl_byday>0 和 t2.xl_last2day>0 和 datediff(t2.dt,t2.ldt)u003d1
和 datediff(t2.dt,t2.last2day)u003d2) 为 t3,xs
选择 xs.*
其中 t3.dpu003dxs.dp
运行结果
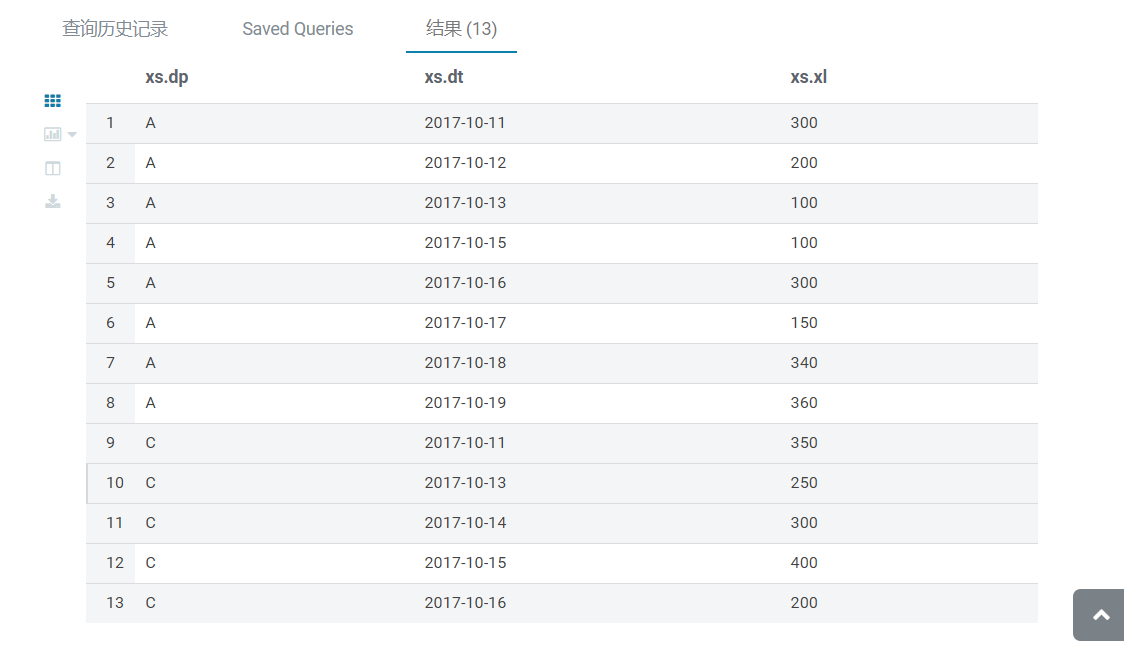

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20427条内容
已为社区贡献20427条内容

所有评论(0)