
使用 Python Pandas 的 Spyder IDE 简介
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--SSlGsFjO--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/1080/1%2AfUO28EIHi1bkZPhjZ451tQ.jpeg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--SSlGsFjO--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://miro.medium .com/max/1080/1%2AfUO28EIHi1bkZPhjZ451tQ.jpeg)
在大型数据集中,手动提取必要的信息可能非常困难。 Python 有助于自动化或大大减少呈现相关数据集所需的工作。 Python 非常注重英语语法,以促进较低的学习曲线并增强平均最终用户体验
Python 库通过为您提供预先编写的代码来帮助节省时间!我们回收以前创建的函数,以节省我们设置强大数据分析工具的时间。没有它们,许多程序将变得更大且重复,并节省最终用户完成任务的时间。
Pandas 是首屈一指的数据科学工具。它读取大型数据集,例如 .csv 文件或 SQL 数据库,并可以帮助根据有意义的值和/或索引范围提取数据。它还具有获取平均值、总和、中位数等的统计命令集。它还具有用于删除不完整条目(NULL 值)的数据清理功能,并且能够将数据集连接在一起以进行更全面的表示。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Ysq2GEEO--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cms.qz .com/wp-content/uploads/2017/11/wes_mckinney_pandas.png%3Fw%3D1400%26strip%3Dall%26quality%3D75)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Ysq2GEEO--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cms.qz .com/wp-content/uploads/2017/11/wes_mckinney_pandas.png%3Fw%3D1400%26strip%3Dall%26quality%3D75)
Pandas 已成为所有计算机科学领域最受欢迎的工具之一,自 2017 年以来几乎占所有 Stack Overflow 问题的 1%。Pandas 的创建者 Wes McKinney 开发了该工具来帮助各种形式的分析师。他说:“我告诉他们,它使非专业计算机科学家的人们能够分析和处理数据......你仍然需要编写代码,但它使代码变得直观且易于访问。它可以帮助人们超越仅仅使用 Excel 进行数据分析。”
今天,我们将介绍 Pandas 的一些基础知识并使用各种命令。此演练将使用来自Anaconda的 Spyder IDE。安装后,转到您的应用程序仪表板,然后打开新的 Anaconda3 文件夹并单击 Spyder。在我们进行任何工作之前,我们必须通过控制台安装 pandas。一些编辑器预先安装了基本软件包,但总是事先检查。
安装包的常用方法是:
pip install <package_name>
在Spyder中:点击右下角的Console,输入以下命令:
pip install pandas
最后,我们需要数据来处理。下载后,单击在文件夹中显示,以便您知道其目录。如果在 .zip 中,请进入 .zip 并复制 csv,返回原始目录并粘贴。
待办事项
1\。安装和创建数据集(完成!)
2\。使用命令提取数据
3\。改变我们的数据集
4\。合并和呈现信息
提取我们的数据
恭喜!我们已经安装了我们的库并使用了我们的数据集。现在,进入 Spyder 并在左侧终端中按回车键,然后键入以下内容以访问 pandas 库:
import pandas as pd
“import pandas”部分现在包含了整个库供我们使用。 “as pd”部分是在调用库函数时使用 pd 作为快捷方式。所以现在我们不是每次都输入 pandas.(function_name),而是 pd.(function_name)。耶效率!我们的第一行代码是将我们的数据集放入 DataFrame 对象中(所以找到您的数据!)在 pd.read_csv(“file”) 函数中输入 .csv 文件的文件位置,然后单击绿色播放按钮运行程序。在 Spyder 上,右侧中间有一个名为 Variable Explorer 的选项卡。单击它,您应该会看到一个大小为 (215,15) 的新 DataFrame 对象。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--TdhvmOum--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/4CZa2uy.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--TdhvmOum--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/4CZa2uy.png)
DataFrame 就像一个 Excel 表格,我们可以使用我们的代码直接编辑它。
在创建不一定用read_csv导入的DataFrame时,可以直接构建如下格式的DataFrame:
alt = pd.DataFrame({'col A':[1,2], 'col B':[3,4]})
结果:
姓名
类型
尺寸
价值
alt
数据框
(2,2)
列名:A,B
我们有我们的数据,但它非常大,所以我们可能会对现在如何处理它感到困惑......以下是一些要使用的命令示例:
-
data.head(): 返回前 5 行
-
data.tail(): 返回底部 5 行
-
data.head(x)/tail(x): 返回 x 顶/底行
-
**data.sort_values(col1):**根据col1升序对数据进行排序
-
data.sort_values(col1, ascendingu003dFalse): 会做同样的事情,但按降序排序
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--aEkBY6ql--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/tPx4OEY.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--aEkBY6ql--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/tPx4OEY.png)
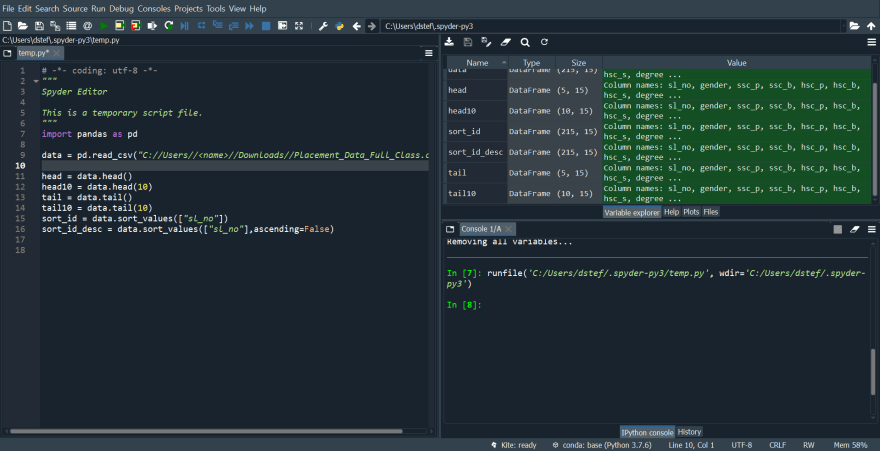
head() 和 head(x) 之间的区别:
data.head():
姓名
类型
尺寸
价值
数据
数据框
(5,15)
列名:sl_no、gender、ssc_p、ssc_b、hsc_p、hsc_b、hsc_s、度...
数据头(10):
姓名
类型
尺寸
价值
数据
数据框
(10,15)
列名:sl_no、gender、ssc_p、ssc_b、hsc_p、hsc_b、hsc_s、度...
获得最高和最低 6 工资
在用于下载 csv 的 Kaggle 页面上,页面的一部分提供了对我们数据列标题的定义,包括薪水。使用它和新学习的命令:
从我们的数据集中获取 6 个最高和最低工资条目。
提示:调用 data.head() 返回文本答案,但对于新数据帧,请编写 new_data u003d data.head()
salary = data.sort_values(["salary"])
bottom = salary.head(6)
top = salary.tail(6)
所以你会得到 200,000 的 6 最低工资,但最高 6 的工资是 NAN。这并没有告诉我们我们真正想要什么。我们可以过滤掉 NULL 数据(比如这里没有提供报价):
salary.dropna(subset=["salary"], inplace = True)
Dropna() 去除空值,参数子集意味着我们可以删除某个列中的空值(这里我们使用薪水)。 Inplace 是在覆盖同一个对象或创建一个新对象之间进行选择(true u003d overwrite)。以下代码将返回非空值:
salary = data.sort_values(["salary"])
salary.dropna(subset-["salary"], inplace = True)
bottom = salary.head(6)
top = salary.tail(6)
更改我们的数据
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--mykMxlFg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://data-flair .training/blogs/wp-content/uploads/sites/2/2019/06/Aggregation-and-Grouping-in-Pandas.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--mykMxlFg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://data-flair .training/blogs/wp-content/uploads/sites/2/2019/06/Aggregation-and-Grouping-in-Pandas.jpg)
假设我想要某个集合的平均值,或者我只想要每列的最高百分比。 Pandas 配备了各种命令,例如上面的命令,可以帮助我们查询数据集以获取相关信息。
data.max() 和 data.min() 将返回每列的最高/最低值,
data['col1'].max() 返回派生列中的最大值。 .mean()、.median()、.sum()、.count()、.std() [标准差] 等的类似实现。
对于我们的数据集:
data.max() u003d 15 个值
data[‘salary’].max() u003d 1 个值
data.mean() u003d 7 个值,因为其他 8 列是非数字的
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--eoTbPjvU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/kOaNxs3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--eoTbPjvU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/kOaNxs3.png)
获取中位数、总和和最大值
让我们得到前 100 名工资的中位数和总和,以及这 100 名候选人的最大 mba_p
提示:现在工资是如何排序的?
salary = data.sort_values(["salary"],ascending=False)
hundred = salary.head(100)
sum_hun = hundred["salary"].sum()
med_hun = hundred["salary"].median()
max_mba = hundred["mba_p"].max()
首先,我们按降序对数据进行排序,并使用 .head() 获取一个新的 DataFrame。然后,我们通过在新的“百”DataFrame 上调用它们各自的命令来创建总和、中值和最大值。
合并新数据
如果我想查看所有百分比如何相加并取平均值怎么办?也许这可以使用已经给出的工具来完成,但现在我想将它作为一个新列添加到我们的原始集合中。
添加数据有两种方法:.append() 和**.concat()。** Append 是添加具有相同行索引(相同列值)的数据框,而 .concat() 则添加相同列索引(相同的行值)。
代码格式:
data1 u003d 待添加
data2 u003d 我们要更新的数据
data1 u003d data1.append(data2)
data.concat([data1,data2])
添加两列:
新_data u003d 数据[col1] + 数据[col2]
注意:这会创建一个 Series 对象,而不是 DataFrame
通过创建新列向 DataFrame 添加一个系列:
数据[“新列”] u003d 系列
例子:
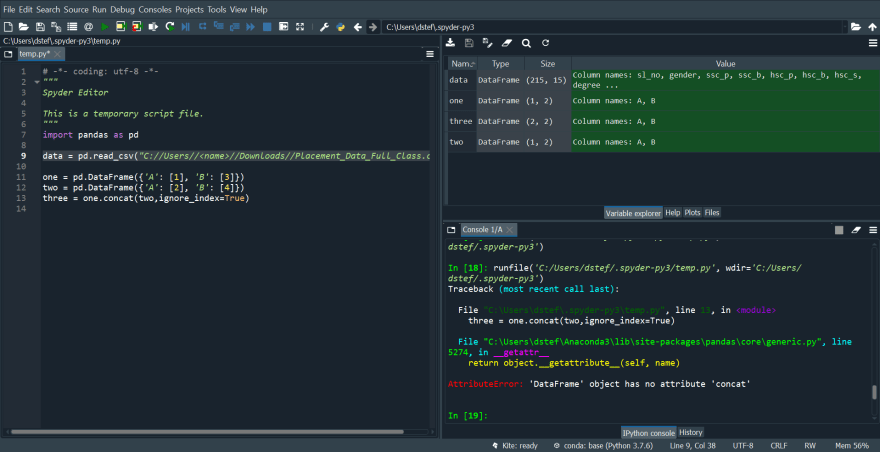
one = pd.DataFrame({'A': [1], 'B': [3]})
two = pd.DataFrame({'A': [2], 'B': [4]})
one = one.append(two,ignore_index=True)
2 size(1,2) DataFrames 合并成一个 (2,2) 新对象。 Ignore_index 就像之前的 inplace 一样工作。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--zaPxCk3B--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/UTJP4fJ.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--zaPxCk3B--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://i. imgur.com/com/UTJP4fJ.png)
聚合旧百分比以创建新百分比
让我们取原始数据集中的 5 个百分比,将它们相加成一列(然后除以 5,数据 /u003d 5),返回该列的平均值并将该列添加到我们的原始数据集中。
提示:您可以将列添加在一起!
new_data = data["ssc_p"] + data["hsc_p"]
new_data = new_data + data["degree_p"]
new_data = new_data + data["etest_p"]
new_data = new_data + data["mba_p"]
new_data /= 5
data["Mean"] = new_data
我们通过将数据中的两列相加来创建一个 Series 对象。我们继续以类似的方式添加相关百分比,然后除以我们使用的百分比数。现在我们有了主平均值,我们可以将一个新列添加到我们的原始数据集中,我们可以通过直接为我们的 DataFrame 命名一个新列来做到这一点。
合并两组相关数据
获取 5 个最高的 mba_p 和 5 个最高的 etest_p 候选人,并将他们的数据集合并到 10 个“总理候选人”
提示:两个 Dataframe 共享相同的列索引
mba = data.sort_values(["mba_p"],ascending=False)
etest = data.sort_values(["etest_p"],ascending=False)
mba_top = mba.head()
etest_top = etest.head()
mba_top = pd.concat([etest_top,mba_top])
我们首先必须创建两个新的、已排序的 DataFrame。我们将两个新数据集中的前 5 个数据集抓取到另一对 DataFrame 中,并使用 .concat() 命令将其中一个作为最终数据集。
恭喜!
通过这个教程,我们学会了对数据进行排序和隔离信息,以及忽略不相关或不完整的数据。然后我们可以创建新的数据子集以供将来分析和可读性。最后,我们获得了添加数据以创建更全面的数据集的能力。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20427条内容
已为社区贡献20427条内容

所有评论(0)