
使用 Azure Databricks 和 Power BI Desktop 可视化数据
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--cg09LGqI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/0%2A10EdlwdWHlpDzQ-Z.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--cg09LGqI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/0%2A10EdlwdWHlpDzQ-Z.png)
Azure Databricks是一项强大的技术,它通过提供易于理解和使用的两个学科的用户的工作流,帮助统一数据工程师和数据科学家之间的分析过程。数据工程师可以使用它来创建有助于将数据交付给数据科学家的工作,然后数据科学家可以使用 Databricks 作为工作台来执行高级分析。
然而,在现实生活中,以可理解的格式提供数据以提供可操作的见解的需求扩大了数据工程师和科学家的需求。考虑到这一点,我们如何期望营销人员、销售人员和业务主管了解和利用 Azure Databricks 等综合分析平台来执行日常任务?
幸运的是,我们可以将 Azure Databricks 中的集群连接到 Power BI 等 BI 工具。本教程的目的是帮助你了解如何将 Azure Databricks 和 Power BI 用于数据可视化任务,以及如何将 Databricks 中的群集连接到 Power BI
本教程中使用的技术:
-
Azure Databricks
-
电源 BI 桌面
对于本教程,我将假设您知道如何使用 Databricks UI 创建笔记本。我还将假设您对 PySpark 以及如何在 Databricks 中创建集群有基本的了解。
获取我们的数据
对于这个演示,我将使用 Python 在 Databricks 中进行脚本编写工作。 Python 中有一些非常酷的数据即库,我将向您展示如何在 Databricks 笔记本中使用这些库。
此外,我将使用 Azure Databricks 附带的预加载数据集之一,这样我就不必浪费时间解释如何将数据导入 Databricks,我在这篇博客文章中对此进行了介绍。
让我们首先创建一个 Python 笔记本并加载我们的数据集。编写以下代码:
# load our data into Databricks
ourData = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv"
# create a dataframe for that data
diamonds = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load(ourData)
如果编译成功,我们应该看到以下输出:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--RsCwF13b--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/480/1%2AtIlgvDRBsOTS4uJcqUZU1A.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--RsCwF13b--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/480/1%2AtIlgvDRBsOTS4uJcqUZU1A.png)
让我们玩转我们的数据,以便我们可以使用不同类型的视觉效果。让我们先看看我们的数据,看看我们正在处理什么:
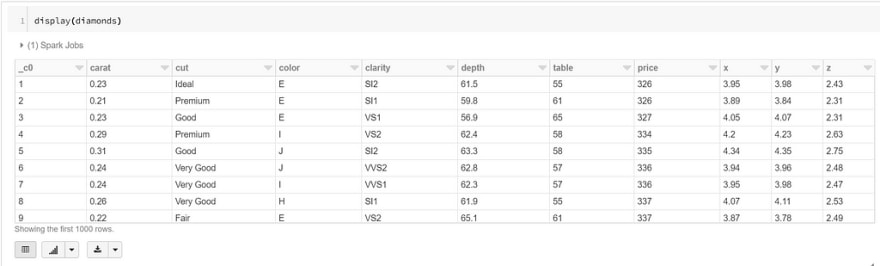
display(diamonds)
我们应该在 Databricks 笔记本中看到下表:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--D9TKPCuI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/1%2ASRUywU3VuOVolOFVknjzhw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--D9TKPCuI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/1%2ASRUywU3VuOVolOFVknjzhw.png)
如您所见,每当我们在 Databricks 中运行 display() 函数时,我们的数据集中都会限制为 1000 行。
在 Databricks 中可视化数据
现在我们已经在 Databricks 中定义了不同的数据帧(比如说快 5 倍),我们可以开始尝试不同类型的数据视觉效果。我们知道我们有哪些列,它们是什么数据类型,以及我们的 diamonds 数据框中的数据类型,所以让我们从一些聚合开始。
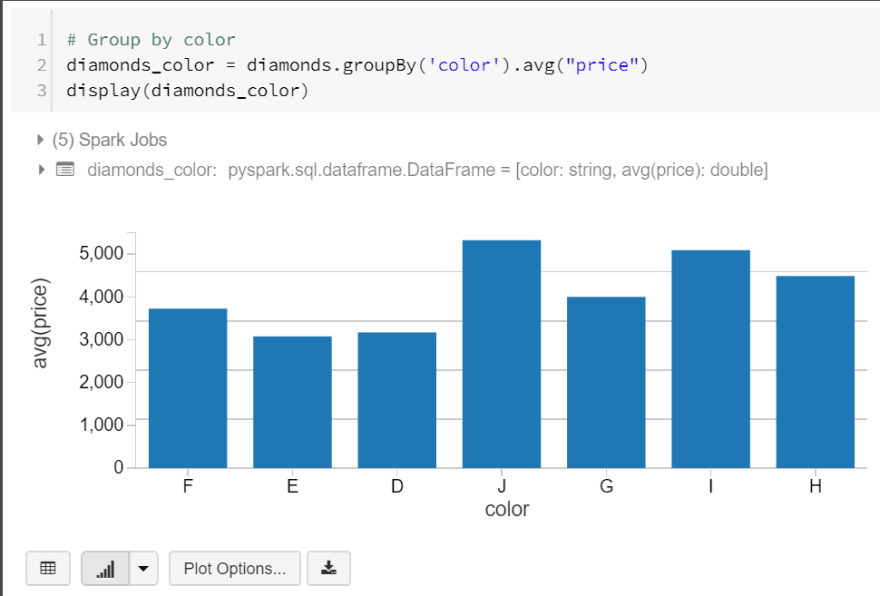
让我们首先按颜色对钻石进行分组并显示它们的平均价格。我们将通过编写以下代码为此创建一个新的数据框:
# Group by color
diamonds\_color = diamonds.groupBy('color').avg("price")
display(diamonds\_color)
当我们执行我们的代码时,我们得到了一个表格,但是你看到表格底部的条形图按钮了吗?这个按钮允许我们可视化我们的数据。在此示例中,我使用了基本条形图,但我将介绍使用此功能可以做什么。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--apyZkGSK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/970/1%2AvS4UPZiKfDfeqMb6oviMxw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--apyZkGSK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/970/1%2AvS4UPZiKfDfeqMb6oviMxw.png)
在 Azure Databricks 中,我们可以创建不同类型的可视化,如下图所示:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Wl3oVS_K--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/358/1%2AivPd79Ddfg-DRRcvfXJYTw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Wl3oVS_K--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/358/1%2AivPd79Ddfg-DRRcvfXJYTw.png)
不是所有的东西都可以是条形图吗?
我们还可以使用“绘图选项..”自定义我们的绘图
[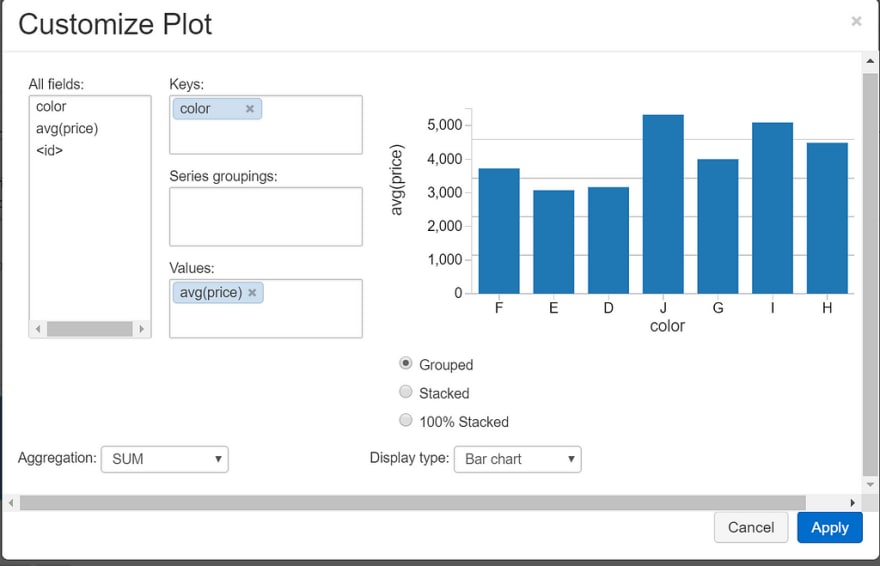 ](https://res.cloudinary.com/practicaldev/image/fetch/s--pfSeVqiR--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/1%2A9A-Y2OJpcc5oQ_jfOCbyDA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--pfSeVqiR--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/1%2A9A-Y2OJpcc5oQ_jfOCbyDA.png)
这是一个非常基本的示例,但是使用此功能,我们可以自定义要在图表中使用的字段、键、值、组、聚合类型以及图表的显示方式。
让我们探讨另一个例子。在 databricks 笔记本的另一个代码块中编写以下代码:
# depth to carat
depthVcarat = diamonds.select("depth", "carat")
display(depthVcarat)
在这个数据框中,我们想看看钻石的深度和它的克拉值之间是否存在关系。让我们创建一个散点图,看看是否有:
[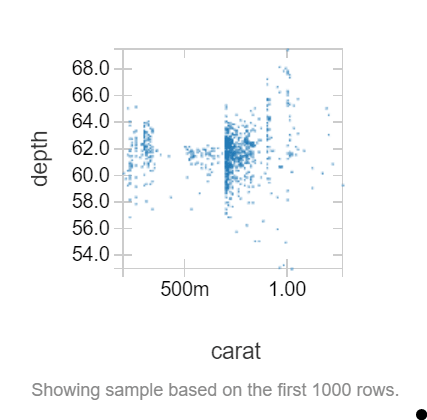 ](https://res.cloudinary.com/practicaldev/image/fetch/s--ySBIqT7d--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/427/1%2A1qeqnEKb3kTW_W8uF-Rhpg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--ySBIqT7d--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/427/1%2A1qeqnEKb3kTW_W8uF-Rhpg.png)
看起来不像。
现在我们的 Databricks 笔记本中有一些很酷的可视化,我们可以将它们整合到一个非常简洁的仪表板中。
为此,我们可以使用笔记本中显示 view: Code 的下拉菜单,然后单击 New Dashboard:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--0Hct9J0Z--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/193/1%2A1qfkngxXLzuQS96Rfu8G5g.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--0Hct9J0Z--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/193/1%2A1qfkngxXLzuQS96Rfu8G5g.png)
在这里,我们可以移动我们的视觉效果来创建一个仪表板,如下所示:
[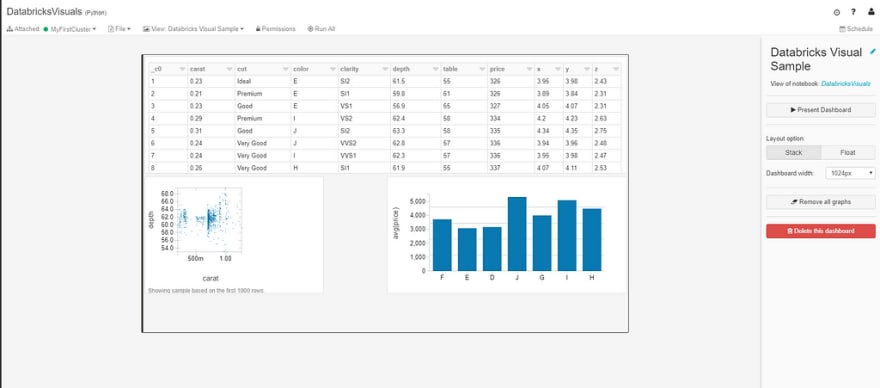 ](https://res.cloudinary.com/practicaldev/image/fetch/s--HO9H4ucb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/1%2ARD5ZwqD2tBAk6HOdiFjw8g.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--HO9H4ucb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/1024/1%2ARD5ZwqD2tBAk6HOdiFjw8g.png)
在这里,我们可以移动我们的视觉效果以适应我们的仪表板。控件非常简单,我们可以选择布局选项(堆叠或浮动)和仪表板宽度。
Databricks 中的仪表板可以非常简单。我们可以做一个快速而肮脏的模型,就像我们刚刚制作的模型一样,或者我们通过创建计划的作业来刷新它来增加它们的复杂性。例如,如果我们创建一个为流式作业提供视觉效果的仪表板,我们可以创建一个每隔一段时间更新一次的作业。
虽然 Databricks 中的可视化工具很好,但它们不如 Power BI 全面。现在让我们将数据连接到 Power BI。
将 Databricks 连接到 Power BI Desktop
Power BI 提供交互式数据可视化,使用户能够创建报表和仪表板。借助 Azure Databricks,您可以为所有业务用户带来性能优势。特别是,您可以使用 DirectQuery 将处理职责卸载到 Azure Databricks,这将处理我们在 Power BI 中不一定需要的大量数据。
Power BI 带有一个内置的 Spark 连接器,它允许我们连接到 Databricks 中的集群。为了连接到您的集群,您需要在 Databricks 中生成个人访问令牌。
首先,让我们将 diamonds 数据框保存为 Databricks 中的全局表。全局表可用于所有集群。
# save diamonds dataframe as a global table
diamonds.write.saveAsTable("diamonds")
让我们通过查看我们的数据选项卡来确认我们的表已经创建:
[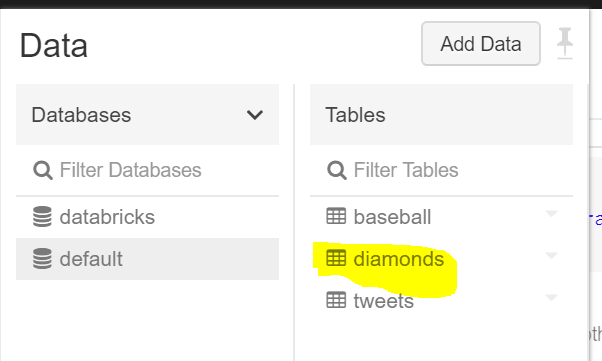 ](https://res.cloudinary.com/practicaldev/image/fetch/s--GxBkoWlK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/602/1%2ANEx2MG-ezZr7PMT_K_iFzw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--GxBkoWlK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/602/1%2ANEx2MG-ezZr7PMT_K_iFzw.png)
亲爱的,现在我们已经保存了我们的表,让我们将它连接到 Power BI。首先,我们需要获取 JDBC(Java 数据库连接)服务器地址。转到集群 UI 并选择要连接的集群。在编辑页面上,向下滚动并选择 JDBC/ODBC 选项卡。
在这里,我们看到了连接到 Power BI 所需的一堆值。我故意向你隐瞒我的价值观,但你需要一个格式如下的地址:
https://<server-host>:<port>/sql/protocol/o/<key>/<key>
最后的两个键将在您的 JDBC URL 文本框中,因此只需复制并粘贴这些值。
获得 URL 后,转到 Power BI 并单击工具栏中的获取数据,然后单击更多...
在 Get Data 对话框中,我们需要查找 Spark (beta) 连接器:
[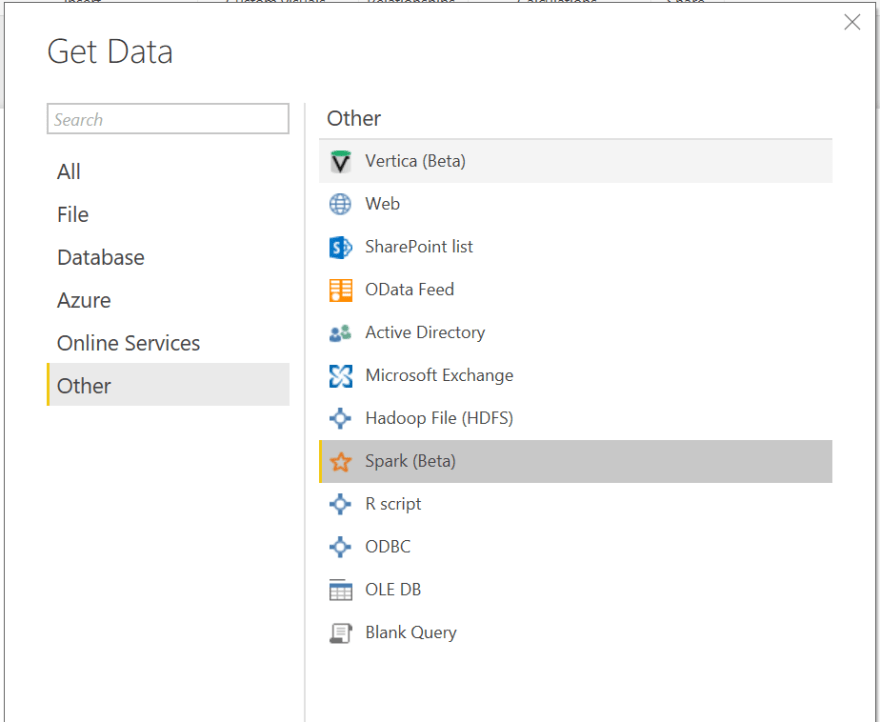 ](https://res.cloudinary.com/practicaldev/image/fetch/s--KvvUiCmk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/924/1%2AjUgTTEReFbwvR_1it5Fx3Q.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--KvvUiCmk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/924/1%2AjUgTTEReFbwvR_1it5Fx3Q.png)
点击 Connect。 输入我们之前构建的 URL,使用 HTTP 作为协议,并选择 DirectQuery 作为 Data Connectivity Mode。这将允许我们将处理卸载到 Spark(如前所述)。
现在我们需要登录到集群。使用“令牌”作为用户名并使用令牌作为密码(确保在执行此操作之前已生成令牌)。单击 Connect 以连接到您的集群。
如果一切正常,您应该能够在导航器对话框中看到所有表格。选择钻石表,您将看到我们数据的预览:
[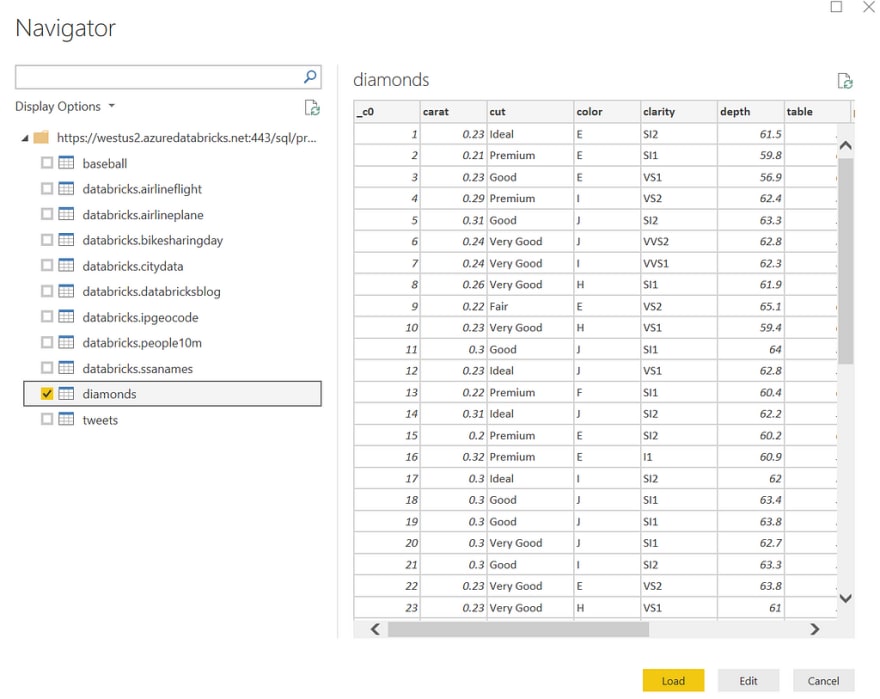 ](https://res.cloudinary.com/practicaldev/image/fetch/s--S6qcLQ4L--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/1024/1%2AtNIv58ocCTKdRzYlnjHL6Q.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--S6qcLQ4L--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1. medium.com/max/1024/1%2AtNIv58ocCTKdRzYlnjHL6Q.png)
我们可以像使用 Power BI 中的任何数据源一样编辑我们的数据导入,也可以直接将其全部加载。让我们做后者!点击加载开始。
在 Power BI 中处理数据
现在我们的 Databricks 表在 Power BI 中可供我们使用,我们可以开始创建一些很棒的可视化。
在字段选项卡中,我们可以看到我们导入的表格及其各自的列:
[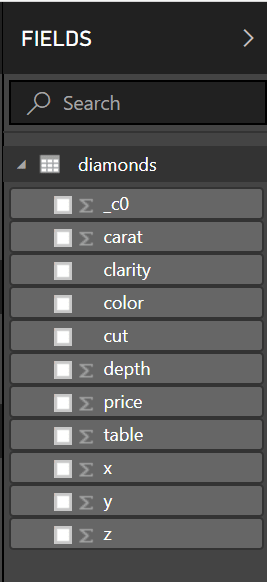 ](https://res.cloudinary.com/practicaldev/image/fetch/s--ByfR5BUW--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/267/1%2AqcRW6L8pCwO203z7uDeuGw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--ByfR5BUW--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/267/1%2AqcRW6L8pCwO203z7uDeuGw.png)
让我们尝试创建我们在 Databricks 中所做的每种颜色的平均价格条形图。在字段选项卡中,选中颜色和价格复选框以将这些字段插入我们的仪表板。
现在,我们想为我们的可视化选择一个“堆积柱形图”。我们需要更改一些东西以使我们的图表看起来不错。在我们的可视化选项卡中,我们希望将轴设置为颜色,为图例选择颜色并将值设置为价格列的平均值。它应该是这样的:
[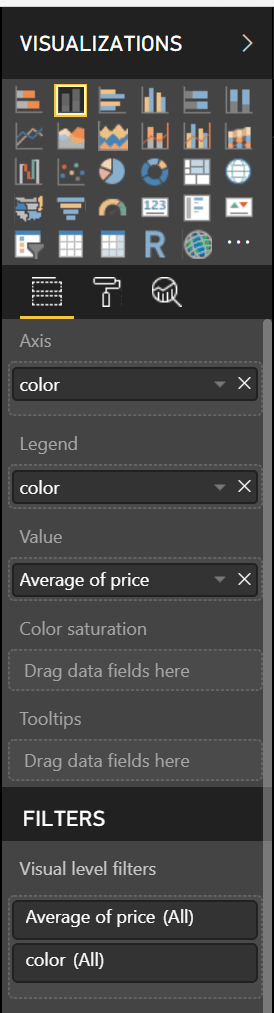 ](https://res.cloudinary.com/practicaldev/image/fetch/s--nYY0Mm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/274/1%2ARacJ6vm2L9gyQfRQB5HAXw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--nYY0Mm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/274/1%2ARacJ6vm2L9gyQfRQB5HAXw.png)
我们的最终结果应该是这样的:
[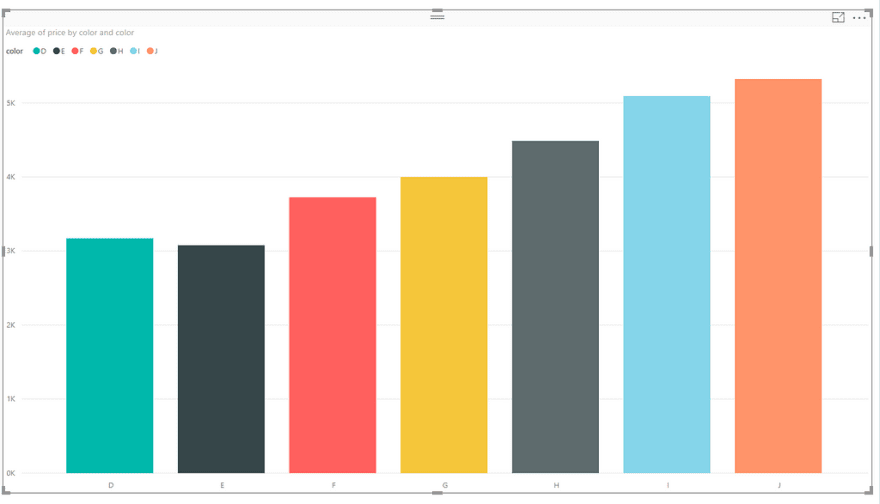 ](https://res.cloudinary.com/practicaldev/image/fetch/s--Ot-R1gzd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/1024/1%2AdRmfaJSqbfy026CO-mQ3sQ.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Ot-R1gzd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/1024/1%2AdRmfaJSqbfy026CO-mQ3sQ.png)
这是我们在此处创建的一个非常简单的示例,但希望您现在了解在 Power BI 中从 Databricks 导入数据的基础知识
结论
在这篇博文中,我们采用了一个简单的 csv 文件(已经为我们加载到 Azure Databricks 中!)并将其转换为 Python 中的数据框,并在其上应用了一些很酷的可视化。然后,我们将 DataFrame 保存为一个表,并将我们的集群连接到 Power BI,并在我们的表上应用了一些可视化。
您可能想知道为什么我们实际上在两个不同的地方进行可视化。 Databricks 是数据工程师和数据科学家在统一分析工作流中协同工作的绝佳工具,但并非所有业务用户都能使用 Databricks 之类的工具,并且使用 Power BI 之类的简单工具(本质上是带有喷气背包的拖放工具)以满足他们的报告需求。
此示例获取云中的数据并将其拉回 Power BI Desktop。更具成本效益的策略是使用 Power BI Online 之类的工具,以便数据保留在云中,因此在生产场景中请记住这一点。
我希望您从本教程中获得一些价值。如果您有任何问题,请随时在评论中提出。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20427条内容
已为社区贡献20427条内容

所有评论(0)