
揭开 XOR 问题的神秘面纱
在我之前关于极限学习机的帖子中,我告诉 AI 的著名先驱 Marvin Minsky 和 Seymour Papert 在他们的书Perceptron [1969]中声称,简单的 XOR 无法通过两层前馈神经网络来解决,这“推动了研究在 1970 年代远离神经网络,并促成了所谓的 AI 冬天”。[Wikipedia 2013]
让我们探索一下这个 XOR 问题是什么......
异或问题
XOR 或“异或”问题是 ANN 研究中的经典问题。这是使用神经网络来预测给定两个二进制输入的 XOR 逻辑门的输出的问题。如果两个输入不相等,XOR 函数应该返回一个真值,如果它们相等则返回一个假值。所有可能的输入和预测输出如图 1 所示。
[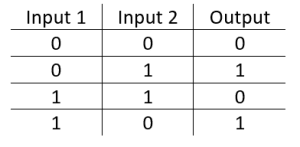
XOR 是一个分类问题并且其预期输出是预先知道的。因此,使用监督学习方法是合适的。
从表面上看,XOR 似乎是一个非常简单的问题,但 Minksy 和 Papert (1969) 表明,对于 1960 年代的神经网络架构(即感知器)来说,这是一个大问题。
感知器
与所有 ANN 一样,感知器由*units* 组成的网络,类似于生物神经元。一个单元可以接收来自其他单元的输入。这样做时,它获取所有接收到的值的总和,并决定是否将信号转发到它所连接的其他单元。这称为激活。激活函数使用某种方式或其他方式将输入值的总和减少到 1 或 0(或非常接近 1 或 0 的值),以表示激活或缺乏激活。另一种形式的单元,称为偏置单元,始终激活,通常向与其连接的所有单元发送硬编码 1。
感知器包括单层输入单元——包括一个偏置单元——和一个输出单元(见图 2)。这里一个偏置单元用虚线圆圈表示,而其他单元用蓝色圆圈表示。有两个非偏置输入单元代表 XOR 的两个二进制输入值。可以包括任意数量的输入单元。
[
感知器是一种前馈网络,这意味着生成输出的过程(称为前向传播)从输入层沿一个方向流向输出层。输入层中的单元之间没有连接。相反,输入层中的所有单元都直接连接到输出单元。
前向传播过程的一个简化解释是输入值 X1 和 X2,连同偏置值 1,乘以它们各自的权重 W0..W2,并解析到输出单元。输出单元获取这些值的总和并使用激活函数(通常是Heavside 阶跃函数)将结果值转换为 0 或 1,从而将输入值分类为 0 或 1。
权重变量的设置使网络的作者能够控制将输入值转换为输出值的过程。权重决定了分类线(将数据点分成分类组的线)的绘制位置。如果分类线一侧的所有数据点都被指定为 0 类,则所有其他数据点都被分类为 1。
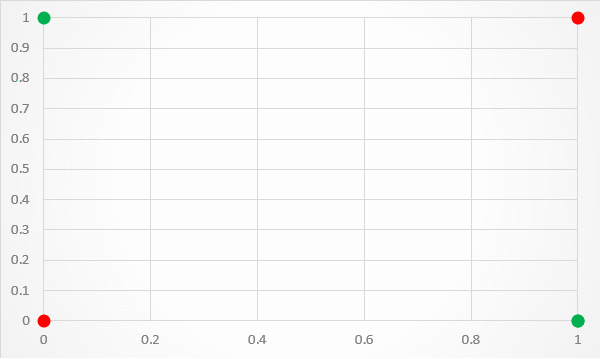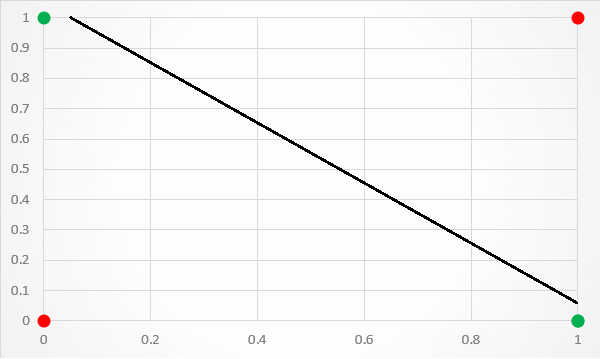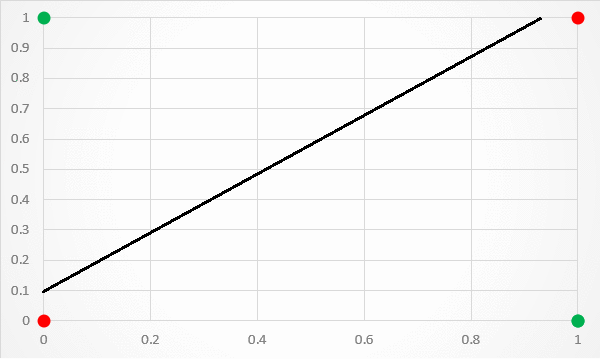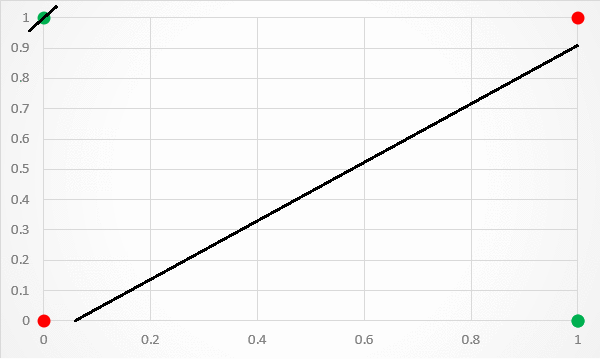
这种架构的一个限制是它只能用一条线分隔数据点。这是不幸的,因为 XOR 输入不是线性可分的。如果将 XOR 输入值绘制到图形中,这一点尤其明显。如图 3 所示,没有办法用一条分类线将 1 和 0 预测分开。
[
多层感知器
这个问题的解决方案是通过添加一个额外的单元层来扩展单层架构,而无需任何直接访问外部世界,称为隐藏层。这种架构(如图 4 所示)是另一种称为多层感知器 (MLP) 的前馈网络。
[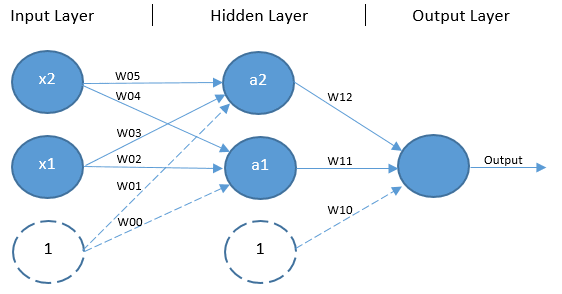
值得注意的是,MLP 在其输入层、隐藏层和输出层中可以有任意数量的单元。也可以有任意数量的隐藏层。这里使用的架构是专门为 XOR 问题设计的。
与经典感知器类似,前向传播从输入层的输入值和偏置单元乘以它们各自的权重开始,然而,在这种情况下,每个输入组合都有一个权重(包括输入层的偏置单元)和隐藏单元(不包括隐藏层的偏置单元)。输入层值及其各自权重的乘积被解析为隐藏层中非偏置单元的输入。每个非偏置隐藏单元调用一个激活函数——通常是经典的sigmoid 函数在 XOR 问题的情况下——将它们的输入值的总和压缩到一个介于 0 和 1 之间的值(通常是一个非常接近 0 或 1)。每个隐藏层单元的输出,包括偏置单元,然后乘以另一组相应的权重并解析到输出单元。输出单元还通过激活函数解析其输入值的总和——同样,这里适合使用 sigmoid 函数——返回一个介于 0 和 1 之间的输出值。这是预测的输出。
这种架构虽然比经典的感知器网络更复杂,但能够实现非线性分离。因此,使用正确的权重值集,它可以提供必要的分离来准确分类 XOR 输入。
[
反向传播
当然,房间里的大象是如何提出一组权重值,以确保网络产生预期的输出。在实践中,尝试手动为 MLP 网络找到一组可接受的权重将是一项非常费力的任务。事实上,它是NP-complete(Blum and Rivest, 1992)。然而,幸运的是,可以通过称为反向传播的过程自动学习一组好的权重值。 Rumelhart 等人首先证明了这对 XOR 问题很有效。 (1985 年)。
反向传播算法首先将前向传播过程输出的实际值与期望值进行比较,然后在网络中向后移动,稍微调整每个权重的方向,使误差的大小略微减小。前向和反向传播都在每个输入组合上重新运行数千次,直到网络可以使用前向传播准确预测可能输入的预期输出。
对于 XOR 问题,100% 的可能数据示例可用于训练过程。因此,我们可以期望经过训练的网络在其预测中是 100% 准确的,并且无需担心结果模型中的偏差和方差等问题。
结论
在这篇文章中,我们探讨了经典的 ANN XOR 问题。详细描述了问题本身,以及 XOR 的输入不能线性分离到它们正确的分类类别的事实。对涉及 MLP 架构的非线性解决方案以及用于从网络生成输出值的前向传播算法和用于训练网络的反向传播算法进行了探索。
本系列的下一篇文章将介绍此处描述的 MLP 架构的实现,包括训练网络充当 XOR 逻辑门所需的所有组件。
参考文献
-
Blum, A. Rivest, R. L. (1992)。训练一个 3 节点神经网络是 NP 完全的。神经网络,5(1),117-127。
-
Minsky, M. Papert, S. (1969)。感知器:计算几何导论。麻省理工学院出版社,剑桥,扩展版,19(88),2。
-
Rumelhart, D. Hinton, G. Williams, R. (1985)。通过错误传播学习内部表示(编号 ICS-8506)。加州大学圣地亚哥分校 LA Jolla Inst.对于认知科学。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20424条内容
已为社区贡献20424条内容

所有评论(0)