
获得我们数据管道的所有权:使用 dbt 进行分析工程
分析工程:分析师和数据科学家的数据提取和操作新范式
作为分析师/数据科学家,我们工作的主要组成部分之一是编写 SQL。为了找到洞察力并产生价值,我们每天多次查询数据库。由于数据杂乱无章,记录不充分,有时甚至是错误或丢失,编写 SQL 成为一项耗时的工作和一个持续的迭代过程。通常,我们还必须随着时间的推移重复相同的分析和数据提取过程来满足类似的业务需求。我们总是发誓有一天我们会在一些漂亮的 Python 脚本的帮助下自动化这些过程,但永远不会因为缺乏时间而最终做到这一点(我知道,我去过那里)。或者有时我们没有我们需要的格式的数据,不得不要求数据库工程师为我们准备特定的表格,这意味着更多的延迟和不满意的业务利益相关者。在我向您提供解决方案和具体示例之前,让我们先强调一下 SQL 活动的主要缺陷:
-
缺乏适当的版本控制:脚本在我们的计算机中以漂亮的名称(例如
analysis_finalv3.2_product.sql)休眠,并且充其量在经过维护的远程存储库中。 -
没有自动化:重新创建分析是手动且耗时的。
-
协作不佳:因为我们的 SQL 不是最优的并且部分隐藏,其他分析师无法访问它,不得不复制粘贴或重新发明轮子。
-
没有测试:我们真的不知道我们 3 个月前查询的数据是否仍然有效或表现相同。更糟糕的是,诸如重复行之类的隐藏错误可能会使我们的汇总报告不准确,从而损害业务。
-
没有文档:我们在个人脚本中硬编码的数据中的这个错误并不提供给其他人,这意味着来自相同数据的相同报告可以返回不同的数字。
作为数据科学家,上述所有情况都可能导致您遇到的最糟糕的情况之一:对来自业务利益相关者的数据缺乏信任,他们依赖于您的分析来做出明智的决策。
但解决办法是什么?很高兴你问我,因为让我向你介绍分析工程师的工作。在这个有点花哨的头衔背后,隐藏着任何优秀数据分析师/科学家的核心能力之一:自主性。我相信作为数据专业人士,我们需要对自己的数据处理负责,从原始数据到最终结果(报告、可视化,甚至机器学习)。我们不能仅仅依靠软件工程师为我们做脏活。虽然管理数据库非常困难,我们仍然需要工程师来确保数据实际可用并且基础设施稳健,但是我们可以而且应该自己做很多事情,即使是杂乱无章的数据。这是ETL中的 T:我们将现有数据转换为可操作的数据。因此,分析工程并不是一门完全不同的学科,它只是我们当前技能的延伸,使我们更加独立。它的美妙之处在于我们只需要 SQL 的工作知识 即可开始。如果您想了解更多关于分析工程师的信息,请前往此处。
介绍dbt
dbt(数据构建工具)是一个开源 python 库,它利用 SQL 的强大功能来执行数据转换。它需要一个现有的数据仓库,并从那里允许您编写代码(在 SQL 中),然后编译并最终针对您的数据库运行。因此,它假设更多的是 ELT 结构,其中数据的提取和加载预先发生,并让您完成转换步骤。欲了解更多信息,请阅读这个。现在让我们看看它在实践中是如何工作的。 dbt 的功能非常丰富,所以我将在这篇文章中首先介绍基础知识,并在以后的文章中扩展以获得更深入的功能。在我们深入研究之前,让我们强调一下 dbt 提供的一些好处:
-
简单性。正如我们将看到的,它隐藏了创建表所需的大部分复杂步骤,并允许我们专注于通过数据转换来交付价值。
-
版本控制。不再需要复制粘贴,业务逻辑在整个组织中集中和共享。
-
环境管理。通过使用配置文件访问数据库和模式,管理不同的环境和帐户(开发、测试、登台、生产)变得轻而易举。
-
自动化。通过使用 dbt 调用的宏,我们可以抽象出 SQL 的功能和位,而不是在代码库的不同位置重复它们。这使我们尊重 DRY(不要重复自己)原则,并节省大量时间和头痛。
-
测试能力。最后但可能是最重要的之一。我们数据科学家和分析师通常不会测试我们的 SQL 代码,因为以自动化的方式进行测试很复杂。我们通常只检查 SQL 结果的一个子集是否正常,我们就收工了。小问题很难找到(比如重复的行,或者那里和那里的缺失值),但可能会产生可怕的后果。 dbt 提供开箱即用的测试工具。它是如此重要和有用,我将在以后专门写一篇文章。但是,如果您已经想了解它,请在此处查看。
要求
-
Python 3,如果没有,请按照这些说明。
-
Pipenv 用于管理 Python 依赖项。我写了一篇关于 pipenv 的介绍性帖子,安装过程可在 Code Vault 中找到。
-
分贝。只需在您的项目文件夹中运行以下命令:
pipenv install dbt
进入全屏模式 退出全屏模式
- 最后,如果没有具体的例子和正在发生的事情的视觉效果,很难解释一个新概念。在这篇文章中,我将使用我的一个宠物项目,你可以在这个 repo 链接找到并克隆。这个想法是从 Riot 公司新发布的游戏 Legends of Runeterra 中创建一个小型卡片数据库,并从中创建一个新的转换表用于分析目的。您不必了解甚至对其中任何一个感兴趣,也可以按照我在下面介绍的步骤进行操作。最后,我同时在 AWS 上创建了一个数据库来托管我们的数据。您无法访问它,但我会通过屏幕截图向您展示发生了什么。
分解 dbt 命令和主要概念
为了了解 dbt 的工作原理,我们将分解其用于在仓库内执行代码和转换数据的主要命令。然后对于每个概念,我们将回顾它是如何工作的以及何时可以使用它,最后我们将看到它的实际效果(通过对我的个人数据库执行的代码截图)。虽然 dbt 提供了许多我们现在不会介绍的功能,但我希望在本文结束时,您将了解所有这些如何协同工作并能够自己开始(并借助 dbt 出色的文档)。
这是一个典型的 dbt 命令。如果您暂时不了解它,请不要担心,只需记住 dbt 获取原始数据,应用您的转换,并将它们具体化为新的表或视图:
pipenv run dbt run --profiles-dir=. --target=profile_dev --full-refresh --models region_keyword_distributions
进入全屏模式 退出全屏模式
下面的截图代表了常见的 dbt 项目结构,可以在我的宠物项目中找到explorer/dbt/(您可以通过在新文件夹中运行dbt init [project-name]来生成相同的结构):
[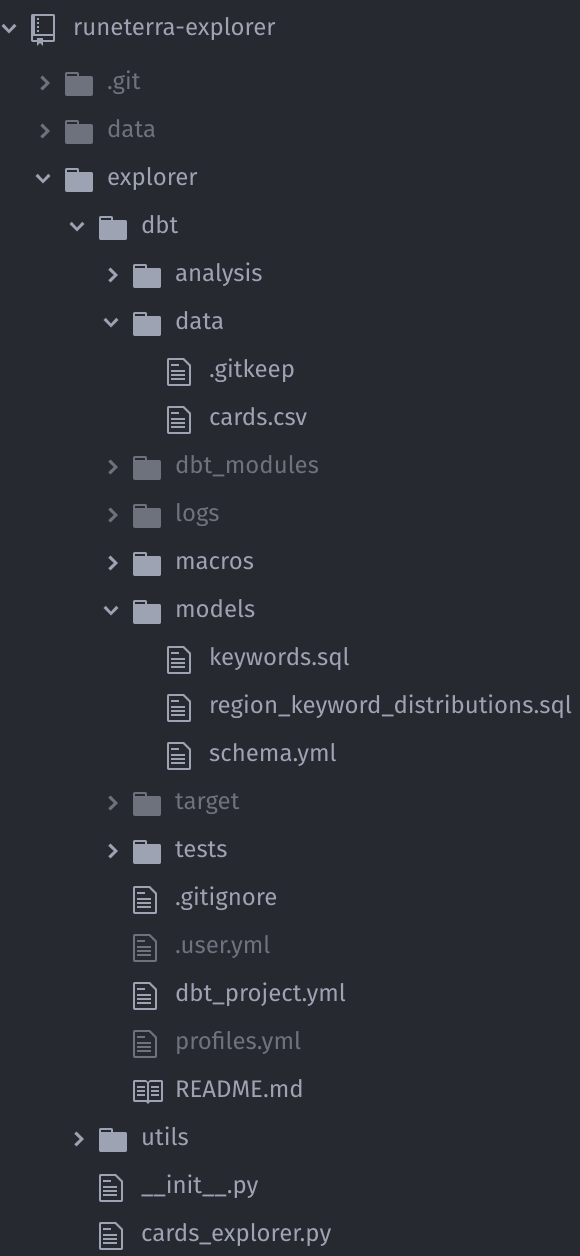 ](https://res.cloudinary.com/practicaldev/image/fetch/s--bci7X8bI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/598ddmumrbt74gqc440m.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--bci7X8bI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/598ddmumrbt74gqc440m.png)
注意:为了更好地理解和清晰,我在下面提到的每个文件路径都是_相对于 dbt 文件夹_(简而言之,我省略了explorer/dbt部分并假设我们已经在这个文件夹中)。
目标和配置文件
dbt 使用位于配置文件中的目标来确定我们生成的 SQL 将存储在哪里。简单地说,我们要求 dbt 将我们的转换结果发送到特定的数据库/模式。目标和配置文件由profiles.yml处理。您要问的这个奇怪的.yml扩展是什么? dbt 确实使用 YAML 来处理像这样的配置文件。 YAML 是一种json。因此,整个项目是.sql和.yml文件的混合体。顺便说一句,尽管您可以在上面的项目结构截图中看到这个profiles.yml文件,但它在 Github 存储库中不可用,因为该文件包含用户名和密码。因此,除非您使用环境变量占位符,否则永远不要将此文件推送到远程 Github 存储库。严重地。你的 IT 部门会发疯的,我们不希望这样。只需将其添加到.gitignore即可被 git 忽略。这是文件的样子:
explorer:
target: profile_dev
outputs:
profile_dev:
dbname: XXXXX
host: XXXXXXX.us-east-1.rds.amazonaws.com
pass: 'XXXXXX'
port: 5432
schema: 'XXXXXX'
threads: 4
type: redshift
user: 'XXXXXX'
进入全屏模式 退出全屏模式
这个 YAML 文件就是上面 dbt 命令中的--profiles-dir=. --target=profile_dev所指的内容。它包含profile_dev目标的数据库凭据,该目标是explorer配置文件的一部分,也是target密钥指定的默认凭据。在outputs中,您可以拥有任意数量的配置文件,这通常是“真实”设置中的情况:例如,开发、单元测试、集成测试和生产中的每个配置文件。在 dbt 文件夹中执行的第一部分--profiles-dir=.告诉 dbt 在.中查找配置文件,这意味着我们已经在其中的当前目录。您可以根据profiles.py文件所在的位置更改此设置。如果未指定,默认情况下它会在您的机器上显示为~/.dbt/。但是我更喜欢将它作为我的项目结构的一部分,因为它可以更容易地在生产中进行管理(但请记住,不要远程推送密码!)。最后一步,您需要在profile键下的dbt_project.yml中指定应该使用哪个配置文件 dbt。
这可能看起来有点麻烦,而且在我的简单项目示例中绝对是矫枉过正,但它确实在真实的生产环境或协作项目中大放异彩。拥有多个目标和配置文件的能力对于管理环境非常有帮助,因为您只需在命令行中更改它即可跨 2 个不同的模式(例如测试和生产)执行相同的 SQL。
模型和宏
模型是 dbt 项目的基础。这就是 dbt 真正令人惊叹的地方,因为一切都是 SELECT。您没看错,无需编写复杂的 CREATE 语句、DELETE 记录或删除表。 dbt 为您处理一切。因此,您可以专注于产生价值的部分:转换数据和满足业务需求。模型位于models文件夹中,如果未指定,dbt 会在执行时自动找到它们。因此,我们原始命令的--models region_keyword_distributions部分是告诉 dbt 只执行region_keyword_distributions模型。将此参数留空会自动执行在models文件夹中找到的每个模型。在我们的示例项目中,我们有region_keyword_distributions位于models/region_keyword_distributions.sql。模型是.sql个文件,它看起来像这样:
{{ config(materialized='table') }}
SELECT
k.keyword,
c.region,
COUNT(*) as region_cards_count,
SUM(CASE WHEN c.keywords LIKE '%' || k.keyword || '%' THEN 1 ELSE 0 END) AS keyword_occurence,
(SUM(CASE WHEN c.keywords LIKE '%' || k.keyword || '%' THEN 1 ELSE 0 END)::decimal / COUNT(*)::decimal)::decimal(4, 2) AS keyword_perc_of_total_cards
FROM
{{ ref('keywords') }} k
CROSS JOIN {{ ref('cards') }} c
WHERE
keyword <> ''
GROUP BY
k.keyword,
c.region
进入全屏模式 退出全屏模式
首先要注意的是{{ }}之间的标头宏。宏是一个 SQL 片段,其行为类似于函数。这非常有用,因为它允许我们在文件之间重复相同的 SQL 行,而无需复制粘贴它们。通过将这些 SQL 片段集中到一个文件中,我们只需修改出现此代码的一个文件即可更轻松地避免错误。这篇文章是一个介绍,所以我不会深入介绍宏,但请随时阅读它们这里。我们第一行中的这个宏是 dbt 开箱即用的宏集的一部分。然而更多的宏可以在这里找到。这些宏很棒,可以进行大量定制和自动化。为了安装 dbt_util 包,请转到packages.yml文件:
packages:
- package: fishtown-analytics/dbt_utils
version: 0.2.3
进入全屏模式 退出全屏模式
在此 .yml 配置文件中,您指定包位置和版本。然后只需运行pipenv run dbt deps即可安装它。之后的包内容可以在dbt_modules中找到。
让我们回到模型第一行中的配置宏。它只是告诉 dbt 我们希望 SQL 的输出是table。其他选项是view或ephemeral(临时表用作构建另一个表的步骤,然后被删除,如果您熟悉这个概念,则类似于 CTE) .
第二个宏出现在 FROM 子句中。{{ ref('keywords') }}告诉 dbt 从引用keywords表中查询。那为什么不直接写呢?因为这样做可以让 dbt 了解当前模型应该仅在创建keywords表时执行,我们当前的 SQL 查询依赖于该表。对于cards表和{{ ref('cards') }}表也是如此。表之间的依赖关系以这种方式自动处理。因此,我们在models/keywords.sql和data/cards.csv处的其他模型(下面将详细介绍此类模型)将首先执行。
增量型号
记住上面我们提到可以通过在模型头中指定它来创建不同的实现。除了我们已经介绍的table、view和ephemeral之外,dbt 最有用的功能之一是可以创建incremental个表。无需从头开始重新创建增量表,只需将最新数据附加到指定的表中即可。例如,如果您每天处理一次收入表,您只能添加昨天而不是使用incremental配置参数从头重新运行它。如果每天运行并使用event_time列,这就是models/region_keyword_distributions.sql作为增量模型的样子:
{{ config(materialized='incremental') }}
SELECT
k.keyword,
c.region,
COUNT(*) as region_cards_count,
SUM(CASE WHEN c.keywords LIKE '%' || k.keyword || '%' THEN 1 ELSE 0 END) AS keyword_occurence,
(SUM(CASE WHEN c.keywords LIKE '%' || k.keyword || '%' THEN 1 ELSE 0 END)::decimal / COUNT(*)::decimal)::decimal(4, 2) AS keyword_perc_of_total_cards
FROM
{{ ref('keywords') }} k
CROSS JOIN {{ ref('cards') }} c
WHERE
keyword <> ''
{% if is.incremental %}
AND event_time = DATEADD('day', -1, CURRENT_DATE)
{% endif}
GROUP BY
k.keyword,
c.region
进入全屏模式 退出全屏模式
dbt 允许我们像这个例子一样使用 if..else 逻辑来指定如果模型是增量的,那么只运行昨天的数据。挺整洁的!您可以尝试的另一件事是根据您使用的目标使用不同的 if..else 逻辑。这在单元测试环境中运行脚本时非常有用。例如,我通常在工作中以这种方式使用它(再次使用上面的示例):
{{ config(materialized='incremental') }}
SELECT
k.keyword,
c.region,
COUNT(*) as region_cards_count,
SUM(CASE WHEN c.keywords LIKE '%' || k.keyword || '%' THEN 1 ELSE 0 END) AS keyword_occurence,
(SUM(CASE WHEN c.keywords LIKE '%' || k.keyword || '%' THEN 1 ELSE 0 END)::decimal / COUNT(*)::decimal)::decimal(4, 2) AS keyword_perc_of_total_cards
FROM
{{ ref('keywords') }} k
CROSS JOIN {{ ref('cards') }} c
WHERE
keyword <> ''
{% if target.name = 'unit_tests' %}
AND event_time = DATEADD('day', -3, CURRENT_DATE) OR
event_time = DATEADD('day', -63, CURRENT_DATE)
{% endif}
GROUP BY
k.keyword,
c.region
进入全屏模式 退出全屏模式
这个逻辑只是在执行时告诉 dbt,如果我们在unit_tests上下文中,只在 2 个特定天(3 天前和 63 天前)运行这个 SQL,因为通常我们希望测试快速而不是在整个数据上运行。您可以通过这种方式添加大量自定义并自动处理环境约束。
最后,--full-refresh参数是运行增量模型时另一个有用的 dbt 技巧:通过指定--full-refresh,我们告诉 dbt 忽略它是增量的事实并从头开始运行它。如果数据已更改或我们修改了表,则通常使用它,但它再次由命令行控制,无需手动更改代码。
种子
在我们测试我们的代码之前,我们需要看到最后一个特性:种子。 dbt 种子只是静态的.csv数据集,我们可以将其作为表格上传到我们的数据库。这对于不经常更改但仍需要作为 ETL 一部分的文件非常有用。游戏的一个示例是指定一些不可变特征(如角色名称和属性)的设计文档。这正是可以在我们的示例项目data文件夹中的data/cards.csv文件中找到的内容。该文件包含每张卡片的特征。这不会经常更改(仅当开发团队发布更新时)并且是种子模型的一个很好的用例。要运行这种类型的模型,请使用以下命令,使用--show显示表格的预览:
pipenv run dbt seed --profiles-dir=. --show
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--rdzpa5yv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/v2dw9e2j0q9gws2ke0p0.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--rdzpa5yv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/v2dw9e2j0q9gws2ke0p0.png)
dbt 在行动!
现在是有趣的部分!让我们使用我们新获得的知识,看看 dbt 在我们的宠物项目中是如何工作的。我们将按顺序执行每个命令,直到所有转换后的数据都进入。请记住,所有内容都在dbt文件夹中执行(如果需要,请调整您的路径):
安装dbt依赖
pipenv run dbt deps --profiles-dir=.
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--2ys5cO7s--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/uody0qtc9pzkmfoo1q9b.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--2ys5cO7s--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/uody0qtc9pzkmfoo1q9b.png)
我们成功安装了dbt_util库。您可以导航到dbt_modules,您会发现已创建一个dbt_util文件夹,其中已导入我们可能需要的所有内容,例如宏。
运行我们的种子模型
您可以在下面看到我们的数据库此时的样子。它非常空,所以我们需要向它提供一些数据,在我们的例子中是包含我们上面提到的卡片信息的.csv种子模型。在工作中,这些原始数据可能已经存在,您可以直接创建模型,但对于个人项目,您需要先导入数据,或者作为种子,或者如果您想将其提升到一个新的水平,则每天/每小时导入数据(例如财务数据)。
[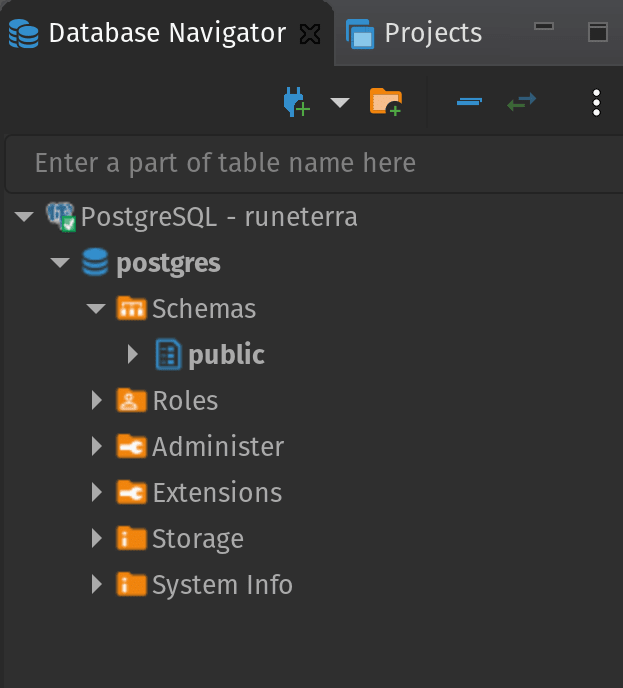 ](https://res.cloudinary.com/practicaldev/image/fetch/s--3rlx-nCB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/xqgkvymwfuu1lre6djn4.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--3rlx-nCB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/xqgkvymwfuu1lre6djn4.png)
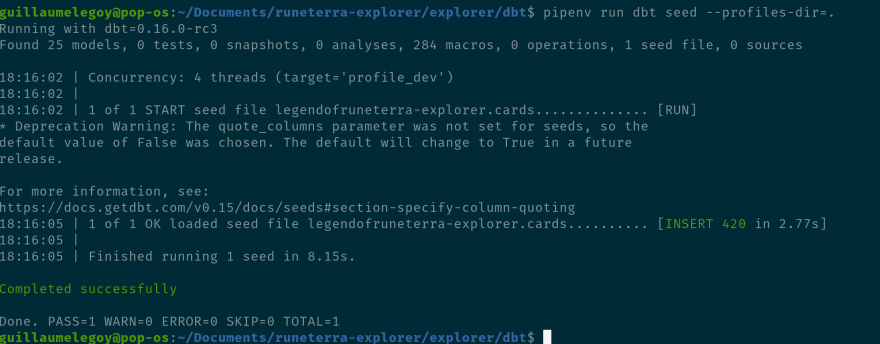
让我们运行我们的种子模型:
pipenv run dbt seed --profiles-dir=.
进入全屏模式 退出全屏模式
结果成功:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--4vOT4QVA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/r70t0w8e0mqpifxdejtl.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--4vOT4QVA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/r70t0w8e0mqpifxdejtl.png)
在这里您可以看到显示以下信息:Concurrency: 4 threads (target='profile_dev')。您可以根据仓库容量设置profiles.py文件中的线程数(更多信息此处)。 dbt 还通知我们它正在使用profile_dev目标运行。如果您记得,这是我们设置为配置文件一部分的默认设置,但如果您有多个环境和使用--target=参数的目标,请在命令中指定它。
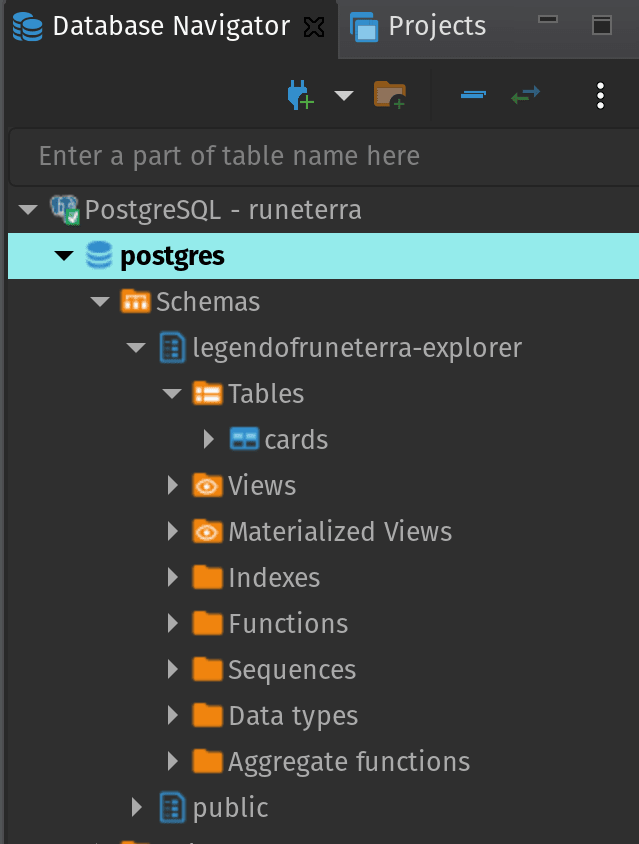
最后,如果我们检查数据库,我们可以看到表已经创建,太棒了!您可以顺便观察一下legendofruneterra-explorer模式是自动创建的。确保您有权在您的项目中执行此操作(尤其是在用户帐户之间的权限可能不同并且设置起来非常复杂的工作中)。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--CTgP-uzp--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/a9r44ot73kb9aavgeluc.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--CTgP-uzp--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/a9r44ot73kb9aavgeluc.png)
转换我们的数据
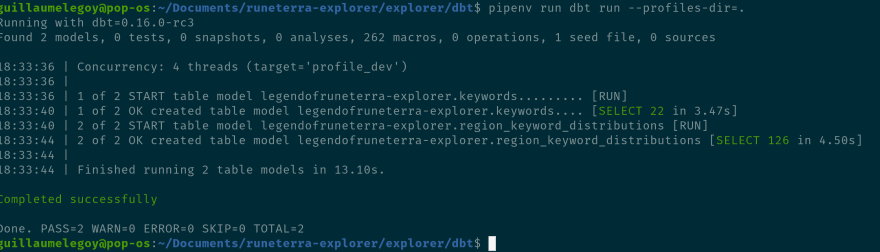
最后一步是魔法发生的地方!我们现在转换我们的数据以适应我们的业务需求和分析约束,或者在我们的例子中是一个基于我们在cards表中找到的卡片集合的简单表:
pipenv run dbt run --profiles-dir=.
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--7GEAOpVf--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/7n08wmcn82obuausf6d2.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--7GEAOpVf--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/7n08wmcn82obuausf6d2.png)
正如我们之前看到的,dbt 会自动发现keywords应该在region_keywords_distribution之前执行。现在数据库中可以使用 2 个表:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--dWD_VMIF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/03r86bc5zr521ye6nkgi.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--dWD_VMIF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/03r86bc5zr521ye6nkgi.png)
就是这样,数据现在是可操作的格式,可以在报告或可视化中查询。我希望通过这个介绍,您现在能够转换自己的数据并提高您作为数据科学家/分析师的工作自主权。请继续关注并订阅我的时事通讯以获取有关该主题的更多文章。我的目标是稍后发布关于 dbt 的高级用法。
快乐编码!
如果您想及时了解我的最新帖子,请随时关注我的Twitter或订阅我的免费时事通讯。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20425条内容
已为社区贡献20425条内容

所有评论(0)