
什么是 Trino,为什么它擅长处理大数据
大数据被吹捧为许多问题的解决方案。然而,事实是,大数据已经引起了很多大问题。
是的,大数据可以提供更多背景信息并提供我们以前从未有过的见解。它还使查询速度变慢,数据管理成本高昂,需要大量昂贵的专家来处理它,而且还在继续增长。
总体而言,数据,尤其是大数据,迫使公司开发更好的数据管理工具,以确保数据科学家和分析师能够处理所有数据。
其中一家公司是 Facebook,他们决定需要开发一种新引擎来有效地处理所有 PB 数据。这个工具被称为 Presto,它最近分裂成另一个名为 Trino 的项目。
在本文中,我们概述了 Trino 是什么、人们使用它的原因以及人们在部署它时面临的一些挑战。
Presto Trino 历史
在深入了解 Trino 是什么以及人们使用它的原因之前。让我们回顾一下 Presto 是如何变成 Trino 的。
什么是 Trino
让我们清楚一点。Trino不是数据库。这是一种误解。仅仅因为您使用 Trino 对数据运行 SQL,并不意味着它是一个数据库。
相反,Trino 是一个 SQL 引擎。更具体地说,Trino 是一个开源分布式 SQL 查询引擎,用于针对多种类型的数据源的即席和批量ETL查询。更不用说它可以管理大量标准和半结构化数据类型,如 JSON、数组和地图。
关于 Trino 的另一个重要讨论点是 Presto 的历史。 2012 年Martin Traverso,David Phillips、Dain Sundstrom 和 Eric Hwang 在 Facebook 工作,并开发了 Presto 来替代 Apache Hive,以更好地处理 Facebook 试图分析的数百 PB。
由于创建者希望保持项目的开放性和社区基础,他们于 2013 年 11 月将其开源。
但由于 Facebook 希望对该项目进行更严格的控制,最终出现了分歧。
Presto 的最初创建者决定他们想要保持 Presto 的开源性,并反过来全职建立 Presto 开源社区。他们以新名称 PrestoSQL 完成了这项工作。
Facebook 决定使用 The Linux Foundation® 建立一个竞争社区。作为第一步,Facebook 在 Presto® 上申请了商标。这最终导致了诉讼和其他挑战,迫使开发 Presto 的原始团队重新命名。

来源
从 2020 年 12 月开始,PrestoSQL 更名为 Trino。这有点令人困惑,但现在 Trino 支持许多最终用户,并且拥有大量定期致力于它的开发人员。
Trino 是如何工作的?
Trino 是一个分布式系统,它使用类似于大规模并行处理 (MPP) 数据库的架构。像许多其他大数据引擎一样,有一种协调节点的形式,然后管理多个工作节点来处理所有需要完成的工作。
分析师或普通用户会运行他们的 SQL,然后推送给协调器。然后协调器依次解析、计划和调度分布式查询。它支持标准 ANSISQL并允许用户运行更复杂的转换,如 JSON 和 MAP 转换和解析。
为什么人们使用 Trino
Trino 是 Presto 的衍生产品,它由一家大型数据公司开发,该公司需要在不花费太多时间处理 ETL 的情况下轻松跨多个数据源进行查询,从而获得了很多好处。此外,它的开发是为了在类似云的基础架构上进行扩展。虽然,Facebook 的大部分基础设施都基于其内部云。但是让我们深入了解人们为什么使用 Trino。
不可知的数据源连接
关于如何查询数据,有很多选择。有 Athena、Hive 和 Apache Drill 等工具。
那么为什么要使用 Trino 来运行 SQL 呢?
Trino 为开发人员提供了许多好处。比如 Trino 最大的优势就是它只是一个 SQL 引擎。这意味着它不可知地位于 MySQL、HDFS 和 SQL Server 等各种数据源之上。
因此,如果您想跨这些不同的数据源运行查询,您可以。
这是一个强大的功能,使用户无需了解底层系统的连接和 SQL 方言。
专注于云
Presto 将存储和计算分开运行的基本设计使其在云环境中运行非常方便。由于 Presto 集群不存储任何数据,它可以根据负载自动扩展而不会造成任何数据丢失。
Trino 用例
即席查询和报告--- Trino 允许最终用户使用 SQL 在您的数据所在的位置运行即席查询。更重要的是,您可以为报告和临时需求创建查询和数据集。
数据湖分析--- Trino 的许多常见用例之一是能够直接查询数据湖上的数据,而无需进行转换。您可以查询各种来源中的结构化或半结构化数据。这意味着您无需进行大规模转换即可创建操作仪表板。
批处理 ETL --- Trino 是运行 ETL 批处理查询的绝佳引擎。这是因为它可以快速处理大量数据以及从多个来源引入数据,而无需总是从 MySQL 等来源中提取数据。
Trino 用户的挑战
此时,您可能会假设每个人都应该使用 Trino。但这并不是那么简单。使用 Trino 需要大量的设置。但是,您还可能在设置时处理其他一些问题。
联合查询可能很慢
联合查询的一个缺点是可以在速度上进行一些权衡。这可能是由于 Trino 缺少存储和管理的元数据来更好地运行查询造成的。此外,Presto 最初是在 Facebook 开发的,基本上拥有自己的云。对于他们来说,在需要提高速度时扩展和增长它并不是一个大问题。但是,对于其他组织来说,为了获得相同水平的性能,他们可能需要花费更多的钱来将更多的机器添加到他们的集群中。这可能会变得非常昂贵。全部用于管理未索引的数据。
一个这样的例子是Varada。 Varada 在 Trino 中索引数据的方式可以减少 CPU 用于数据扫描(通过索引)的时间,并释放 CPU 用于其他任务,例如非常快速地获取数据或处理并发。因此,SQL 用户可以在作为联合数据源的索引数据上运行各种查询,无论是跨维度、事实以及其他类型的连接和数据湖分析。 SQL 聚合和分组也使用纳米块索引加速,从而实现高效的 SQL 分析。
配置和设置
设置 Trino 并不简单。尤其是在优化绩效和管理方面。反过来,许多系统管理员和 IT 团队将需要团队来设置和管理他们的 Trino 实例。
一个很好的例子是 AWS 文章,标题为“PrestoDB](https://aws.amazon.com/blogs/big-data/top-9-performance-tuning-tips-for-prestodb-on-amazon-emr/)的[9 大性能调优技巧”。
缺乏企业功能
使用 Trino 的公司面临的最大挑战之一是开箱即用,没有很多面向企业解决方案的功能。也就是说,围绕安全、访问控制甚至扩展数据源连接的功能是有限的。许多解决方案正试图在该领域提供更好的解决方案。
Starburst Data就是一个很好的例子。
Starburst Enterprise 有几个功能可以帮助改善 Trino 缺乏的安全功能。例如,Starburst 可让您的团队轻松设置访问控制。
访问控制系统都遵循基于角色的访问控制机制,包括用户、组、角色、权限和对象。
如下图所示
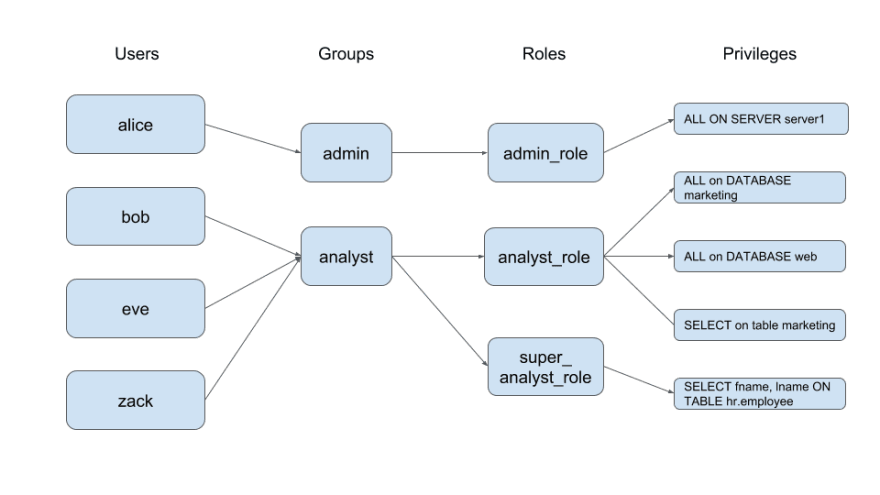
来源
这使您的安全团队和数据仓库管理员可以轻松管理谁有权访问哪些数据。
Starburst 还提供其他有用的安全功能,例如审计和加密。
这使公司能够实施集中式安全框架,而无需为 Trino 编写自己的模块。
结论
对于没有开始寻找像 Trino 这样的工具来帮助他们管理所有数据的公司来说,大数据将继续是一个大问题。 Trino 能够成为一个不可知的 SQL 引擎,可以跨多个数据源查询大型数据集,这对这些公司中的许多公司来说是一个很好的选择。但正如所讨论的,特里诺远非完美。它并没有完全优化企业公司利用其全部能力的方式。此外,由于 Trino 对速度的蛮力方法,有时会付出代价。在没有索引的情况下获得有益的速度变得非常昂贵。
这就是许多新的解决方案出现的地方,以使 Trino 更加平易近人。最后,可以维护和管理大数据,您只需要正确的工具来帮助您为成功做好准备。
如果您喜欢这篇文章,请查看下面的这些视频和文章。
数据工程师与分析工程师与分析师
为什么要迁移到现代数据堆栈以及从哪里开始
2021 年 5 大数据工程工具 --- 我最喜欢的数据工程工具
给数据科学家的 4 个 SQL 技巧
云数据仓库有什么好处以及为什么要迁移

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 1
1- 0



 已为社区贡献20424条内容
已为社区贡献20424条内容

所有评论(0)