

- Prerequisites
- SelectorGadgets Extension
- Organic Search Results
- Profiles Results
- Cite
- Authors
- Authors Articles
- Authors Cited by and Public Access
- Authors Co-Authors
- Full Code
- Links
- Outro
Prerequisites
Basic knowledge scraping with CSS selectors
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective.
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
Install libraries:
$ pip install requests
$ pip install lxml
$ pip install beautifulsoup4
$ pip install google-search-results
Reduce the chance of being blocked
There's a chance that a request might be blocked. Have a look at how to reduce the chance of being blocked while web-scraping, there are eleven methods to bypass blocks from most websites and some of them will be covered in this blog post.
SelectorGadgets extension
If you see me using select_one() or select() bs4 methods to grab data from CSS selectors, this will imply that I used SelectorGadges to find them.
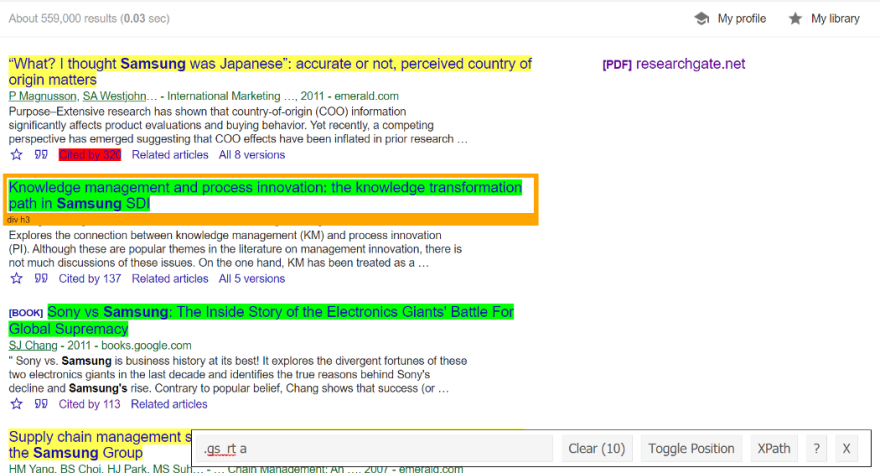
Element(s) highlighted in:
- red excludes from search.
- green included in the search.
- yellow is guessing what the user is looking to find and needs additional clarification.
Scrape Google Scholar Organic Search Results
This code snippet shows how to scrape: title, link to an article, publication info, snippet, cited by results, link to related articles, link to different versions of articles.

from bs4 import BeautifulSoup
import requests, lxml, os, json
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "samsung",
"hl": "en",
}
html = requests.get('https://scholar.google.com/scholar', headers=headers, params=params).text
soup = BeautifulSoup(html, 'lxml')
# Scrape just PDF links
for pdf_link in soup.select('.gs_or_ggsm a'):
pdf_file_link = pdf_link['href']
print(pdf_file_link)
# JSON data will be collected here
data = []
# Container where all needed data is located
for result in soup.select('.gs_ri'):
title = result.select_one('.gs_rt').text
title_link = result.select_one('.gs_rt a')['href']
publication_info = result.select_one('.gs_a').text
snippet = result.select_one('.gs_rs').text
cited_by = result.select_one('#gs_res_ccl_mid .gs_nph+ a')['href']
related_articles = result.select_one('a:nth-child(4)')['href']
try:
all_article_versions = result.select_one('a~ a+ .gs_nph')['href']
except:
all_article_versions = None
data.append({
'title': title,
'title_link': title_link,
'publication_info': publication_info,
'snippet': snippet,
'cited_by': f'https://scholar.google.com{cited_by}',
'related_articles': f'https://scholar.google.com{related_articles}',
'all_article_versions': f'https://scholar.google.com{all_article_versions}',
})
print(json.dumps(data, indent = 2, ensure_ascii = False))
# Part of the JSON Output:
'''
[
{
"title": "“What? I thought Samsung was Japanese”: accurate or not, perceived country of origin matters",
"title_link": "https://www.emerald.com/insight/content/doi/10.1108/02651331111167589/full/html",
"publication_info": "P Magnusson, SA Westjohn… - International Marketing …, 2011 - emerald.com",
"snippet": "Purpose–Extensive research has shown that country‐of‐origin (COO) information significantly affects product evaluations and buying behavior. Yet recently, a competing perspective has emerged suggesting that COO effects have been inflated in prior research …",
"cited_by": "https://scholar.google.com/scholar?cites=341074171610121811&as_sdt=2005&sciodt=0,5&hl=en",
"related_articles": "https://scholar.google.com/scholar?q=related:U8bh6Ca9uwQJ:scholar.google.com/&scioq=samsung&hl=en&as_sdt=0,5",
"all_article_versions": "https://scholar.google.com/scholar?cluster=341074171610121811&hl=en&as_sdt=0,5"
}
]
'''
# Part of PDF Links Output:
'''
https://www.researchgate.net/profile/Peter_Magnusson/publication/232614407_What_I_thought_Samsung_was_Japanese_Accurate_or_not_perceived_country_of_origin_matters/links/09e4150881184a6ad2000000/What-I-thought-Samsung-was-Japanese-Accurate-or-not-perceived-country-of-origin-matters.pdf
https://www.researchgate.net/profile/Hong_Mo_Yang/publication/235291000_Supply_chain_management_six_sigma_A_management_innovation_methodology_at_the_Samsung_Group/links/56e03d0708aec4b3333d0445.pdf
https://www.academia.edu/download/54053930/The_Strategic_Localization_of_Transnatio20170803-32468-4ntcqr.pdf
https://mathsci2.appstate.edu/~wmcb/Class/5340/ClassNotes141/EdelmanAwards/Interfaces2002-S.pdf
'''
Scrape Google Scholar Organic Results using SerpApi.
This block of code scrapes the same as above: title, link to an article, publication info, snippet, cited by results, link to related articles, link to different versions of articles.
from serpapi import GoogleSearch
import os, json
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar",
"q": "samsung",
}
search = GoogleSearch(params)
results = search.get_dict()
# This print() looks pretty akward,
# but the point is that you can grab everything you need in 2-3 lines of code as below.
for result in results['organic_results']:
print(f"Title: {result['title']}\nPublication info: {result['publication_info']['summary']}\nSnippet: {result['snippet']}\nCited by: {result['inline_links']['cited_by']['link']}\nRelated Versions: {result['inline_links']['related_pages_link']}\n")
# If you want more readable code, here's one example.
data = []
for result in results['organic_results']:
data.append({
'title': result['title'],
'publication_info': result['publication_info']['summary'],
'snippet': result['snippet'],
'cited_by': result['inline_links']['cited_by']['link'],
'related_versions': result['inline_links']['related_pages_link'],
})
print(json.dumps(data, indent = 2, ensure_ascii = False))
# Part of Non-JSON output:
'''
Title: “What? I thought Samsung was Japanese”: accurate or not, perceived country of origin matters
Publication info: P Magnusson, SA Westjohn… - International Marketing …, 2011 - emerald.com
Snippet: Purpose–Extensive research has shown that country‐of‐origin (COO) information significantly affects product evaluations and buying behavior. Yet recently, a competing perspective has emerged suggesting that COO effects have been inflated in prior research …
Cited by: https://scholar.google.com/scholar?cites=341074171610121811&as_sdt=5,44&sciodt=0,44&hl=en
Related Versions: https://scholar.google.com/scholar?q=related:U8bh6Ca9uwQJ:scholar.google.com/&scioq=samsung&hl=en&as_sdt=0,44
'''
# Part of JSON output:
'''
[
{
"title": "“What? I thought Samsung was Japanese”: accurate or not, perceived country of origin matters",
"publication_info": "P Magnusson, SA Westjohn… - International Marketing …, 2011 - emerald.com",
"snippet": "Purpose–Extensive research has shown that country‐of‐origin (COO) information significantly affects product evaluations and buying behavior. Yet recently, a competing perspective has emerged suggesting that COO effects have been inflated in prior research …",
"cited_by": "https://scholar.google.com/scholar?cites=341074171610121811&as_sdt=5,44&sciodt=0,44&hl=en",
"related_versions": "https://scholar.google.com/scholar?q=related:U8bh6Ca9uwQJ:scholar.google.com/&scioq=samsung&hl=en&as_sdt=0,44"
}
]
'''
Scrape Google Scholar Profiles Results
This block of code scrapes author name, link, affiliation(s), email, interests, cited by.

from bs4 import BeautifulSoup
import requests, lxml, os
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
html = requests.get('https://scholar.google.com/citations?view_op=view_org&hl=en&org=9834965952280547731', headers=headers).text
soup = BeautifulSoup(html, 'lxml')
# Selecting container where all data located
for result in soup.select('.gs_ai_chpr'):
name = result.select_one('.gs_ai_name a').text
link = result.select_one('.gs_ai_name a')['href']
# https://stackoverflow.com/a/6633693/15164646
id = link
id_identifer = 'user='
before_keyword, keyword, after_keyword = id.partition(id_identifer)
author_id = after_keyword
affiliations = result.select_one('.gs_ai_aff').text
email = result.select_one('.gs_ai_eml').text
try:
interests = result.select_one('.gs_ai_one_int').text
except:
interests = None
# "Cited by 107390" = getting text string -> splitting by a space -> ['Cited', 'by', '21180'] and taking [2] index which is the number.
cited_by = result.select_one('.gs_ai_cby').text.split(' ')[2]
print(f'{name}\nhttps://scholar.google.com{link}\n{author_id}\n{affiliations}\n{email}\n{interests}\n{cited_by}\n')
# Part of the output:
'''
Jeong-Won Lee
https://scholar.google.com/citations?hl=en&user=D41VK7AAAAAJ
D41VK7AAAAAJ
Samsung Medical Center
Verified email at samsung.com
Gynecologic oncology
107516
'''
Scrape Google Scholar Profiles using SerpApi.
This block of code scrapes the same as above: author name, link, affiliation(s), email, interests, cited by.
from serpapi import GoogleSearch
import os
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_profiles",
"hl": "en",
"mauthors": "samsung"
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['profiles']:
name = result['name']
try:
email = result['email']
except:
email = None
author_id = result['author_id']
affiliation = result['affiliations']
cited_by = result['cited_by']
interests = result['interests'][0]['title']
interests_link = result['interests'][0]['link']
print(f'{name}\n{email}\n{author_id}\n{affiliation}\n{cited_by}\n{interests}\n{interests_link}\n')
# Part of the output:
'''
Jeong-Won Lee
Verified email at samsung.com
D41VK7AAAAAJ
Samsung Medical Center
107516
Gynecologic oncology
https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:gynecologic_oncology
'''
Scrape Google Scholar Cite Results using SerpApi
This block of code is also scraping cite results.

from serpapi import GoogleSearch
import os
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_cite",
"q": "FDc6HiktlqEJ"
}
search = GoogleSearch(params)
results = search.get_dict()
for cite in results['citations']:
print(f'Title: {cite["title"]}\nSnippet: {cite["snippet"]}\n')
# Output:
'''
Title: MLA
Snippet: Schwertmann, U. T. R. M., and Reginald M. Taylor. "Iron oxides." Minerals in soil environments 1 (1989): 379-438.
Title: APA
Snippet: Schwertmann, U. T. R. M., & Taylor, R. M. (1989). Iron oxides. Minerals in soil environments, 1, 379-438.
Title: Chicago
Snippet: Schwertmann, U. T. R. M., and Reginald M. Taylor. "Iron oxides." Minerals in soil environments 1 (1989): 379-438.
Title: Harvard
Snippet: Schwertmann, U.T.R.M. and Taylor, R.M., 1989. Iron oxides. Minerals in soil environments, 1, pp.379-438.
Title: Vancouver
Snippet: Schwertmann UT, Taylor RM. Iron oxides. Minerals in soil environments. 1989 Jan 1;1:379-438.
'''
Scrape Google Scholar Authors Results
This block of code scrapes particular author name, affiliation(s), email, interests.

from bs4 import BeautifulSoup
import requests, lxml, os
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
def bs4_scrape_author_result():
html = requests.get('https://scholar.google.com/citations?hl=en&user=m8dFEawAAAAJ', headers=headers).text
soup = BeautifulSoup(html, 'lxml')
print('Author info:')
name = soup.select_one('#gsc_prf_in').text
affiliation = soup.select_one('#gsc_prf_in+ .gsc_prf_il').text
try:
email = soup.select_one('#gsc_prf_ivh').text
except:
email = None
try:
interests = soup.select_one('#gsc_prf_int').text
except:
interests = None
print(f'{name}\n{affiliation}\n{email}\n{interests}\n')
# Output:
'''
Jun-Youn Kim
Samsung
Verified email at plesseysemi.com
micro ledGaN power device
'''
Scrape Google Scholar Articles
This block of code scrapes articles from the author's profile.

from bs4 import BeautifulSoup
import requests, lxml, os
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"user": "m8dFEawAAAAJ",
"sortby": "pubdate",
"hl": "en"
}
def get_articles():
html = requests.get('https://scholar.google.com/citations', headers=headers, params=params).text
soup = BeautifulSoup(html, 'lxml')
print('Article info:')
for article_info in soup.select('#gsc_a_b .gsc_a_t'):
title = article_info.select_one('.gsc_a_at').text
title_link = f"https://scholar.google.com{article_info.select_one('.gsc_a_at')['href']}"
authors = article_info.select_one('.gsc_a_at+ .gs_gray').text
publications = article_info.select_one('.gs_gray+ .gs_gray').text
print(f'Title: {title}\nTitle link: {title_link}\nArticle Author(s): {authors}\nArticle Publication(s): {publications}\n')
# Part of the output:
'''
Article info:
Title: Lifting propositional proof compression algorithms to first-order logic
Title link: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=m8dFEawAAAAJ&sortby=pubdate&citation_for_view=m8dFEawAAAAJ:abG-DnoFyZgC
Article Author(s): J Gorzny, E Postan, B Woltzenlogel Paleo
Article Publication(s): Journal of Logic and Computation, 2020
Title: Complexity of translations from resolution to sequent calculus
Title link: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=m8dFEawAAAAJ&sortby=pubdate&citation_for_view=m8dFEawAAAAJ:D03iK_w7-QYC
Article Author(s): G Reis, BW Paleo
Article Publication(s): Mathematical Structures in Computer Science 29 (8), 1061-1091, 2019
'''
Scrape Google Scholar Cited by, Public Access
This block of code scrapes Cited By: citations (all, since 2016), h-index (all, since 2016), i10 index (all, since 2016), and public access.

from bs4 import BeautifulSoup
import requests, lxml, os
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
html = requests.get('https://scholar.google.com/citations?hl=en&user=m8dFEawAAAAJ', headers=headers).text
soup = BeautifulSoup(html, 'lxml')
print('Citation info:')
for cited_by_public_access in soup.select('.gsc_rsb'):
citations_all = cited_by_public_access.select_one('tr:nth-child(1) .gsc_rsb_sc1+ .gsc_rsb_std').text
citations_since2016 = cited_by_public_access.select_one('tr:nth-child(1) .gsc_rsb_std+ .gsc_rsb_std').text
h_index_all = cited_by_public_access.select_one('tr:nth-child(2) .gsc_rsb_sc1+ .gsc_rsb_std').text
h_index_2016 = cited_by_public_access.select_one('tr:nth-child(2) .gsc_rsb_std+ .gsc_rsb_std').text
i10_index_all = cited_by_public_access.select_one('tr~ tr+ tr .gsc_rsb_sc1+ .gsc_rsb_std').text
i10_index_2016 = cited_by_public_access.select_one('tr~ tr+ tr .gsc_rsb_std+ .gsc_rsb_std').text
articles_num = cited_by_public_access.select_one('.gsc_rsb_m_a:nth-child(1) span').text.split(' ')[0]
articles_link = cited_by_public_access.select_one('#gsc_lwp_mndt_lnk')['href']
print(f'{citations_all}\n{citations_since2016}\n{h_index_all}\n{h_index_2016}\n{i10_index_all}\n{i10_index_2016}\n{articles_num}\nhttps://scholar.google.com{articles_link}\n')
# Output:
'''
Citation info:
67599
28242
110
63
967
447
7
https://scholar.google.com/citations?view_op=list_mandates&hl=en&user=9PepYk8AAAAJ
'''
Scrape Google Scholar Co-Authors Results
This block of code scrapes co-authors from the author’s profile.

from bs4 import BeautifulSoup
import requests, lxml, os
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
html = requests.get('https://scholar.google.com/citations?hl=en&user=m8dFEawAAAAJ', headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
for container in soup.select('.gsc_rsb_aa'):
author_name = container.select_one('#gsc_rsb_co a').text
author_affiliations = container.select_one('.gsc_rsb_a_ext').text
author_link = container.select_one('#gsc_rsb_co a')['href']
print(f'{author_name}\n{author_affiliations}\nhttps://scholar.google.com{author_link}\n')
# Part of the output:
'''
Christoph Benzmüller
Professor, FU Berlin
https://scholar.google.com/citations?user=zD0vtfwAAAAJ&hl=en
Pascal Fontaine
LORIA, INRIA, Université de Lorraine, Nancy, France
https://scholar.google.com/citations?user=gHe6EF8AAAAJ&hl=en
Stephan Merz
Senior Researcher, INRIA
https://scholar.google.com/citations?user=jaO3Z3wAAAAJ&hl=en
'''
Full code to scrape profile, authors
This is the full code of scraping profile and author results: articles, cited by (including the graph) and public access with co-author
from bs4 import BeautifulSoup
import requests, lxml, os, json
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
def bs4_scrape_profile_results():
html = requests.get('https://scholar.google.com/citations?view_op=view_org&hl=en&org=9834965952280547731', headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
author_ids = []
for result in soup.select('.gs_ai_chpr'):
name = result.select_one('.gs_ai_name a').text
link = result.select_one('.gs_ai_name a')['href']
# https://stackoverflow.com/a/6633693/15164646
id = link
id_identifer = 'user='
before_keyword, keyword, after_keyword = id.partition(id_identifer)
author_id = after_keyword
affiliations = result.select_one('.gs_ai_aff').text
email = result.select_one('.gs_ai_eml').text
try:
interests = result.select_one('.gs_ai_one_int').text
except:
interests = None
cited_by = result.select_one('.gs_ai_cby').text.split(' ')[2]
author_ids.append(author_id)
print(author_ids)
return author_ids
def bs4_scrape_author_result(profiles):
print('Author info:')
for id in profiles:
html = requests.get(f'https://scholar.google.com/citations?hl=en&user={id}', headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
name = soup.select_one('#gsc_prf_in').text
affiliation = soup.select_one('#gsc_prf_in+ .gsc_prf_il').text
try:
email = soup.select_one('#gsc_prf_ivh').text
except:
email = None
try:
interests = soup.select_one('#gsc_prf_int').text
except:
interests = None
print(f'{name}\n{affiliation}\n{email}\n{interests}\n')
print('Article info:')
for article_info in soup.select('#gsc_a_b .gsc_a_t'):
title = article_info.select_one('.gsc_a_at').text
title_link = article_info.select_one('.gsc_a_at')['data-href']
authors = article_info.select_one('.gsc_a_at+ .gs_gray').text
publications = article_info.select_one('.gs_gray+ .gs_gray').text
print(f'Title: {title}\nTitle link: https://scholar.google.com{title_link}\Article Author(s): {authors}\Article Publication(s): {publications}\n')
print('Citiation info:')
for cited_by_public_access in soup.select('.gsc_rsb'):
citations_all = cited_by_public_access.select_one('tr:nth-child(1) .gsc_rsb_sc1+ .gsc_rsb_std').text
citations_since2016 = cited_by_public_access.select_one('tr:nth-child(1) .gsc_rsb_std+ .gsc_rsb_std').text
h_index_all = cited_by_public_access.select_one('tr:nth-child(2) .gsc_rsb_sc1+ .gsc_rsb_std').text
h_index_2016 = cited_by_public_access.select_one('tr:nth-child(2) .gsc_rsb_std+ .gsc_rsb_std').text
i10_index_all = cited_by_public_access.select_one('tr~ tr+ tr .gsc_rsb_sc1+ .gsc_rsb_std').text
i10_index_2016 = cited_by_public_access.select_one('tr~ tr+ tr .gsc_rsb_std+ .gsc_rsb_std').text
articles_num = cited_by_public_access.select_one('.gsc_rsb_m_a:nth-child(1) span').text.split(' ')[0]
articles_link = cited_by_public_access.select_one('#gsc_lwp_mndt_lnk')['href']
print(f'{citations_all}\n{citations_since2016}\n{h_index_all}\n{h_index_2016}\n{i10_index_all}\n{i10_index_2016}\n{articles_num}\nhttps://scholar.google.com{articles_link}\n')
print('Co-Author(s):')
try:
for container in soup.select('.gsc_rsb_aa'):
author_name = container.select_one('#gsc_rsb_co a').text
author_affiliations = container.select_one('.gsc_rsb_a_ext').text
author_link = container.select_one('#gsc_rsb_co a')['href']
print(f'{author_name}\n{author_affiliations}\nhttps://scholar.google.com{author_link}\n')
except:
pass
print('Graph result:')
years = [graph_year.text for graph_year in soup.select('.gsc_g_t')]
citations = [graph_citation.text for graph_citation in soup.select('.gsc_g_a')]
data = []
for year, citation in zip(years,citations):
print(f'{year} {citation}\n')
data.append({
'year': year,
'citation': citation,
})
# print(json.dumps(data, indent=2))
profiles = bs4_scrape_profile_results()
bs4_scrape_author_result(profiles)
Scrape Google Scholar Author Articles with SerpApi
This block of code scrapes article: title, link, authors, publications, cited by, cited by link, year.
from serpapi import GoogleSearch
import os
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_author",
"author_id": "9PepYk8AAAAJ",
"hl": "en",
}
search = GoogleSearch(params)
results = search.get_dict()
for article in results['articles']:
article_title = article['title']
article_link = article['link']
article_authors = article['authors']
article_publication = article['publication']
cited_by = article['cited_by']['value']
cited_by_link = article['cited_by']['link']
article_year = article['year']
print(f"Title: {article_title}\nLink: {article_link}\nAuthors: {article_authors}\nPublication: {article_publication}\nCited by: {cited_by}\nCited by link: {cited_by_link}\nPublication year: {article_year}\n")
# Part of the output:
'''
Title: Methods for forming liquid crystal displays including thin film transistors and gate pads having a particular structure
Link: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=9PepYk8AAAAJ&citation_for_view=9PepYk8AAAAJ:4X0JR2_MtJMC
Authors: DG Kim, W Lee
Publication: US Patent 5,731,856, 1998
Cited by: 3467
Cited by link: https://scholar.google.com/scholar?oi=bibs&hl=en&cites=1363873152714400726
Publication year: 1998
Title: Thin film transistor, method of manufacturing the same, and flat panel display having the same
Link: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=9PepYk8AAAAJ&citation_for_view=9PepYk8AAAAJ:Dh4RK7yvr34C
Authors: J Park, C Kim, S Kim, I Song, Y Park
Publication: US Patent 8,188,472, 2012
Cited by: 3347
Cited by link: https://scholar.google.com/scholar?oi=bibs&hl=en&cites=12194894272882326688
Publication year: 2012
'''
Scrape Google Scholar Author Cited By with SerpApi
This block of code scrapes Cited By: citations (all, since 2016), h-index (all, since 2016), i10 index (all, since 2016), and public access.
from serpapi import GoogleSearch
import os, json
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_author",
"author_id": "9PepYk8AAAAJ",
"hl": "en",
}
search = GoogleSearch(params)
results = search.get_dict()
citations_all = results['cited_by']['table'][0]['citations']['all']
citations_2016 = results['cited_by']['table'][0]['citations']['since_2016']
h_inedx_all = results['cited_by']['table'][1]['h_index']['all']
h_index_2016 = results['cited_by']['table'][1]['h_index']['since_2016']
i10_index_all = results['cited_by']['table'][2]['i10_index']['all']
i10_index_2016 = results['cited_by']['table'][2]['i10_index']['since_2016']
print(citations_all)
print(citations_2016)
print(h_inedx_all)
print(h_index_2016)
print(i10_index_all)
print(i10_index_2016)
public_access_link = results['public_access']['link']
public_access_available_articles = results['public_access']['available']
print(public_access_link)
print(public_access_available_articles)
# Output:
'''
Cited by:
67599
28242
110
63
967
447
Public accsess:
https://scholar.google.com/citations?view_op=list_mandates&hl=en&user=9PepYk8AAAAJ
7
'''
Scrape Google Scholar Co-Authors using SerpApi.
This block of code scrapes co-authors from author page.
from serpapi import GoogleSearch
import os
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_author",
"author_id": "m8dFEawAAAAJ",
"hl": "en",
}
search = GoogleSearch(params)
results = search.get_dict()
for authors in results['co_authors']:
author_name = authors['name']
author_affiliations = authors['affiliations']
author_link = authors['link']
print(f'{author_name}\n{author_affiliations}\n{author_link}\n')
# Part of the output:
'''
Christoph Benzmüller
Professor, FU Berlin
https://scholar.google.com/citations?user=zD0vtfwAAAAJ&hl=en
Pascal Fontaine
LORIA, INRIA, Université de Lorraine, Nancy, France
https://scholar.google.com/citations?user=gHe6EF8AAAAJ&hl=en
Stephan Merz
Senior Researcher, INRIA
https://scholar.google.com/citations?user=jaO3Z3wAAAAJ&hl=en
'''
Full using Google Scholar API to scrape profile, authors results.
This block full code of scrapes profile results, and author: articles, cited by and public access with co-authors.
from serpapi import GoogleSearch
import os
def serpapi_scrape_profile_results_combo():
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_profiles",
"hl": "en",
"mauthors": "samsung"
}
search = GoogleSearch(params)
results = search.get_dict()
author_ids = []
for result in results['profiles']:
name = result['name']
try:
email = result['email']
except:
email = None
author_id = result['author_id']
affiliation = result['affiliations']
cited_by = result['cited_by']
interests = result['interests'][0]['title']
interests_link = result['interests'][0]['link']
author_ids.append(author_id)
# Delete prints that not needed
print(f'{name}\n{email}\n{author_id}\n{affiliation}\n{cited_by}\n{interests}\n{interests_link}\n')
return author_ids
def serpapi_scrape_author_result_combo(profiles):
for id in profiles:
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_author",
"author_id": id,
"hl": "en",
}
search = GoogleSearch(params)
results = search.get_dict()
print('Author Info:')
name = results['author']['name']
affiliations = results['author']['affiliations']
email = results['author']['email']
# Add as many interests as needed by adding additional indexes [3] [4] [5] [6] etc.
try:
interests1 = results['author']['interests'][0]['title']
interests2 = results['author']['interests'][1]['title']
except:
interests1 = None
interests2 = None
print(f'{name}\n{affiliations}\n{email}\n{interests1}\n{interests2}\n')
print('Articles Info:')
for article in results['articles']:
article_title = article['title']
article_link = article['link']
article_authors = article['authors']
try:
article_publication = article['publication']
except:
article_publication = None
cited_by = article['cited_by']['value']
cited_by_link = article['cited_by']['link']
article_year = article['year']
print(f"Title: {article_title}\nLink: {article_link}\nAuthors: {article_authors}\nPublication: {article_publication}\nCited by: {cited_by}\nCited by link: {cited_by_link}\nPublication year: {article_year}\n")
print('Citations Info:')
citations_all = results['cited_by']['table'][0]['citations']['all']
citations_2016 = results['cited_by']['table'][0]['citations']['since_2016']
h_inedx_all = results['cited_by']['table'][1]['h_index']['all']
h_index_2016 = results['cited_by']['table'][1]['h_index']['since_2016']
i10_index_all = results['cited_by']['table'][2]['i10_index']['all']
i10_index_2016 = results['cited_by']['table'][2]['i10_index']['since_2016']
print(f'{citations_all}\n{citations_2016}\n{h_inedx_all}\n{h_index_2016}\n{i10_index_all}\n{i10_index_2016}\n')
print('Public Access Info:')
public_access_link = results['public_access']['link']
public_access_available_articles = results['public_access']['available']
print(f'{public_access_link}\n{public_access_available_articles}\n')
# Graph results
try:
for graph_results in results['cited_by']['graph']:
year = graph_results['year']
citations = graph_results['citations']
print(f'{year} {citations}\n')
except:
pass
print('Co-Authour(s):')
try:
for authors in results['co_authors']:
author_name = authors['name']
author_affiliations = authors['affiliations']
author_link = authors['link']
print(f'{author_name}\n{author_affiliations}\n{author_link}\n')
except:
pass
profiles = serpapi_scrape_profile_results_combo()
serpapi_scrape_author_result_combo(profiles)
Links
- Code in the online IDE
- GitHub repository
Outro
If you have any questions or suggestions, or something isn't working correctly, feel free to drop a comment in the comment section or via Twitter at @serp_api.
You can contact me directly via Twitter at @dimitryzub.
Yours,
Dimitry, and the rest of SerpApi Team.





 已为社区贡献2917条内容
已为社区贡献2917条内容

所有评论(0)