
【人工智能】集装箱危险品瞒报预测
【摘要】本文针对航运业危险品瞒报问题,提出基于随机森林算法的预测模型。研究采集近一年订舱数据,通过数据清洗、特征工程(如合作频率离散化、危险品标志转换等)处理样本,并采用SMOTE算法解决数据不平衡问题。实验表明,优化后的随机森林模型准确率达88.58%,AUC值0.914,优于决策树、神经网络等对比算法。研究还通过特征重要性分析和treeinterpreter库增强模型可解释性,为航运公司识别高
如果需要完整代码的同学,可以私聊哦!
随着经济全球化与国际贸易的快速增长,由于运输成本低以及货物运量大的优势,航运业发展之势非常迅猛。 危险货物的运输规范往往比普通货物的运输规范要更为严格。但有一些货主故意隐瞒危险品货物信息或因专业知识不够导致漏报或错报的情况的出现,导致航运公司在危险货物运输防范以及应急方面处于非常被动的局面。 在集装箱危险品运输的问题上,航运公司如何能够化被动为主动成为各航运公司安全生产的一项重要任务。如何高效准确地找到危险品瞒报订舱,并通过进一步查验来缓解危险品瞒报风险就成为了航运公司的迫切需求。
一、数据概况
航运业务信息化建设很多年了,航运公司积累了大量的订舱数据,而且订舱数据的维度也非常多。因此选择合理的数据采集范围以及关键的业务属性,对于后续数据挖掘工作至关重要。 集装箱运输具有周期性、季节性的特点,以整年的数据为佳,而近年来危险品运输的规范性以及检测力度日益提高,危险品订舱数据也越来越准确,所以选取近一年的订舱数据。 考虑到最近的订舱流程可能尚未完成,最终选取的数据范围,是以采集时间前一个月为结束点的一整年订舱数据。
二、字段取值类型
|
关键属性名 |
字段含义 |
选择理由 |
|
CRE_MONTH |
下单月份 |
集装箱运输具有周期性、季节性的特点,淡季与旺季的区分比较明显,所以将下单时间作为候选特征 |
|
BRIEF_DESC |
货物简称 |
与危险品信息紧密相关 |
|
... |
... |
... |
|
FULL_DESC |
货物详细描述 |
与危险品信息紧密相关 |
|
SH_COOP_FREQ |
发货人合作频率 |
发货人是货主,是负责危险品申报的主体,一般也是瞒报的责任方 |
|
FW_COOP_FREQ |
货代公司合作频率 |
货代连接货主与班轮公司,货代有确认货主申报信息准确的义务,专业的货代公司有助于控制危险品运输风险,同时也有部分货代公司存在违规操作,欺上瞒下赚取差价 |
|
CN_COOP_FREQ |
收货人合作频率 |
收货人也是分析的重要对象,虽然瞒报责任一般不在收货方,但是有时危险品瞒报需要收货方的配合,所以也将其列为进一步分析的对象 |
|
SH_COOP_LVL |
发货人合作等级 |
发货人是货主,是负责危险品申报的主体,一般也是瞒报的责任方 |
|
FW_COOP_LVL |
货代公司合作等级 |
货代连接货主与班轮公司,货代有确认货主申报信息准确的义务,专业的货代公司有助于控制危险品运输风险,同时也有部分货代公司存在违规操作,欺上瞒下赚取差价 |
|
CN_COOP_LVL |
收货人合作等级 |
收货人也是分析的重要对象,虽然瞒报责任一般不在收货方,但是有时危险品瞒报需要收货方的配合,所以也将其列为进一步分析的对象 |
三、数据提取
数据是存储在一系列结构复杂的关系表中的,为了进行后续的数据挖掘工作,首先需要根据订舱号这一订舱的唯一标识将这些表里的数据集成,便于后续的分析。
四、数据预处理
订舱样本数据采集完毕后无法直接使用,这是因为数据中存在大量的冗余属性、噪声、缺值记录和错误数据需要处理。 数据清洗主要是处理数据中的噪声、缺失值以及一些异常数据。这些问题数据可能是由程序漏洞、历史原因等导致的,这样的数据难以直接使用,会影响到训练的模型。
4.1 缺失值处理
使用包含缺失值的数据进行数据挖掘会对训练得到的模型造成很坏的影响,所以要对缺失值做处理。 利用Python中Pandas库的方法即可处理缺失值,同时可结合MissingNo库可视化展示数据中缺失值的密度,快速直观地了解数据的完整性。 直接删除这些样本数据固然是最简单的处理方式,但是可能会丢失其中隐藏的知识点,对于预测结果造成较大偏差,甚至失去预测的意义,需要对不同的特征分别进行分析。
def missingDataStat(data):
total=data.isnull().sum().sort_values(ascending=False)
percent=(data.isnull().sum()/data.isnull().count()).sort_values(...)
missing_data=pd.concat([total,percent],axis=1,keys=['Total','Percent'])
missing_data.head(20)
#无效矩阵的数据密集显示
msno.matrix(data)
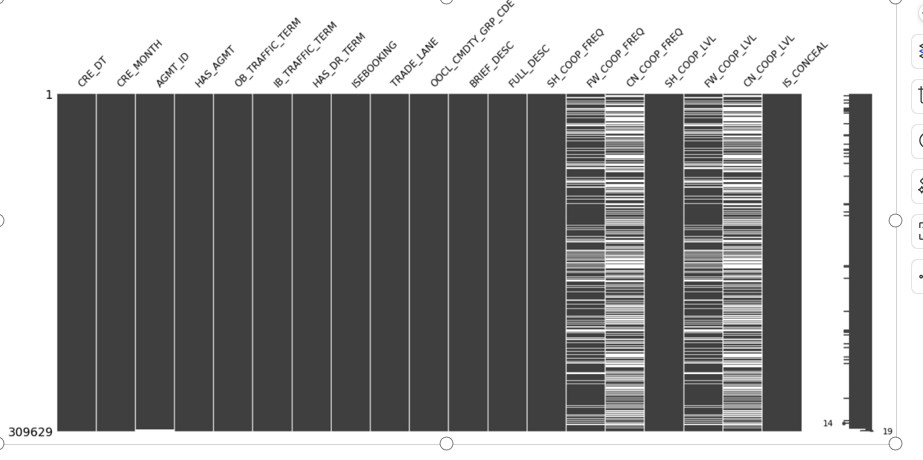
缺失值主要集中在收货人以及货代公司的有关属性列。 订舱系统中,联系人信息是非常重要的特征,尤其是业务的主要参与者:发货人、收货人以及货代公司。发货人是必填项,理论上不应该存在缺失值,而在样本数据中存在个别缺失现象,经分析是程序漏洞导致,由于数据量比例极小,可直接删除。 收货人空值在业务中代表订舱时尚未确定收货人,船公司按发货人的指示交付货物。 货代公司空值代表发货人直接订舱,未委托第三方。因此这里货代公司空值表示发货人自身充当货代公司角色,而收货人空值则代表暂时托运给发货人自己。 货物描述存在少量的缺失值,在货物明细表中还有一项货物简称,可直接利用其填补缺失的货物描述。货物属性的缺失,可利用货物信息表中的冗余字段是否危险品、是否冷藏品以及是否大件货重新组合填充。 样本数据中还存在少量运输条款、下单方式、付费条款等特征缺失的记录,这些存在缺失的特征均为分类特征,一般可采用“默认值”、“众值”等方式填补。这里采用KNN填充法,计算找到临近的3条记录,通过投票选出其中最多的类别用以填充缺失的值,填充效果较好。
def missingData(data):
#基于业务填补
sub_data=data.loc[:,['SH_COOP_FREQ','FW_COOP_FREQ',"CN_COOP_FREQ"]]
#KNN填补
return KNN(k=3).fit_transform(data)
4.2 错误数据处理
data.head()
data.plot.box()
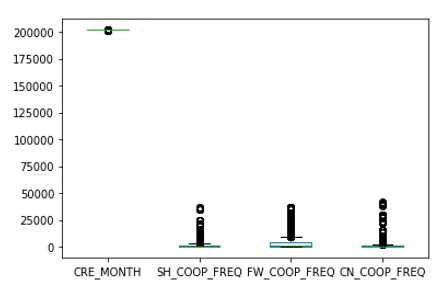
4.2 错误数据处理
重复数据主要是指同样的数据在数据库中被存储了多次,如货物信息在装箱后,若订舱含有多个箱子,则货物信息会被复制多份,装在对应的箱子中。 直接使用会增加对应类别的样本数,使数据分析结果产生倾斜,所以预处理时删除多余记录,仅保留一条即可。
4.3 数据变换
对于危险品瞒报数据进行转换,得出新的瞒报标志IS_CONCEAL。业务上认定瞒报的数据源主要有两部分,一部分为运输过程中被班轮公司或海关检测出的订舱,此类订舱已被明确打上瞒报标志。 另一部分为在审核订舱时发现是疑似危险品,客户又无法提供明确的非危证明而被拒绝的订舱,拒绝原因为疑似危险品,此类情况也认为是瞒报。 引入相关方合作频率、发货人、收货人以及货代公司的历史订舱量,代表着与班轮公司的合作程度。一般来说,合作程度高的客户瞒报危险品的概率较低。为了避免合作时长对历史订舱量的影响,改为使用客户合作频率作为衡量的标准,以(最近一年订舱总量/12)计算每月平均订舱量,分别得出SH_COOP_FREQ、CN_COOP_FREQ和FW_COOP_FREQ。 进出口条款变换为是否含有到门条款HAS_DR_TERM,条款分为到港、到门、到货运站等多种模式,但是对于瞒报预测,经业务专家分析,是否到门才有本质区别,所以将到港、到货运站等模式重新划分为非门条款。 下单方式变换为是否网上电子订舱ISEBOOKING,并且根据是否存在协议号,引入新变量是否协议订舱HAS_AGMT。
4.4 连续属性离散化
数据中部分属性为连续值,数据分布较为分散,对其进行离散化后,便于分析,并有助于模型的稳定,降低过拟合的风险。 发货人、收货人、货代公司合作频率,数据具有分布非常分散的特点,直接使用不利于后续对模型的理解和应用,因此将相关方合作频率进行离散化处理。离散化的方式是对数据进行分组,发货人合作频率离散化为新客户、小客户、中等客户、大客户以及VIP客户五类,收货人与货代公司非直接客户,业务上按合作频率细分为大、中、小三类,离散化后引入变量合作等级SH_COOP_LVL、CN_COOP_LVL和FW_COOP_LVL

联系人合作程度的离散化采用基于K-means算法的聚类离散法,获得聚类中心点后,通过rolling_mean函数平均移动,计算前后两个聚类中心的均值确定分类边界并切分数据,得到离散化后的新特征即联系人合作级别。 细粒度的订舱时间本身意义不大,由于航运业的淡旺季与月份有着紧密关系,所以将时间离散化为月份CRE_MONTH作为候选的特征之一。
def coopLvlDiscretization(data,fieldNme,newFieldNme,k):
fieldData=data[fieldNme].copy()
#K-Means算法(k为离散化后簇的数量)
kmodel=KMeans(n_clusters=k)
kmodel.fit(fieldData.values.reshape((len(fieldData),1)))
kCenter=pd.DataFrame(kmodel.cluster_centers_,columns=list('a'))
kCenter=kCenter.sort_values(by='a')
#确定分类边界
kBorder=kCenter.rolling(2).mean().iloc[1:]
kBorder=[0]+list(kBorder.values[:,0])+[fieldData.max()]
#切分数据,实现离散化
newFieldData=pd.cut(fieldData,kBorder,labels=range(k))
#合并添加新列
data=pd.concat([data,newFieldData.rename(newFieldNme)],axis=1)
return data
4.5 特征重要性筛选
特征重要性筛选就是剔除与结果没有影响或影响不大的特征,有助于提高瞒报预测模型的构建速度,增强模型的泛化能力,减少过拟合问题。 采用基于逻辑回归的稳定性选择方法实现对特征的筛选。稳定性选择方法能够有效帮助筛选重要特征,同时有助于增强对数据的理解。以合同协议号、电子订舱、货物品名、发货人合作频率、货代公司合作频率、收货人合作频率为例(编号依次为0,1,2,3,4,5)。
def featureSelection(data):
A1 = data[['AGMT_ID', 'ISEBOOKING', 'OOCL_CMDTY_GRP_CDE', 'SH_COOP_FREQ','FW_COOP_FREQ', 'CN_COOP_FREQ']]
B1 = data[['IS_CONCEAL']]
X1 = A1.values
y1 = B1.values
X1[:, 0] = leAgmt.transform(X1[:, 0])
X1[:, 1] = leEB.transform(X1[:, 1])
X1[:, 2] = leGrp.transform(X1[:, 2])
X1[:, 3] = leSH.transform(X1[:, 3])
X1[:, 4] = leFW.transform(X1[:, 4])
X1[:, 5] = leCN.transform(X1[:, 5])
y1 = LabelEncoder().fit_transform(y1.ravel())
x_train, x_test, y_train, y_test = train_test_split(X1, y1, test_size = 0.3, random_state = 0)
xgboost = XGBClassifier()
xgboost.fit(x_train, y_train)
print(xgboost.feature_importances_)
plt.bar(range(len(xgboost.feature_importances_)), xgboost.feature_importances_)
plt.show()
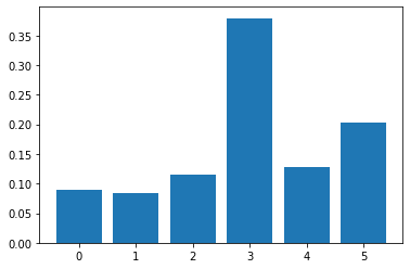
图4.1 危险品瞒报特征重要性分析结果
4.6 数据平衡
危险品瞒报是小概率事件,本案例使用的原始数据中,瞒报记录的有2831条,非瞒报记录的有341982条, 占比约为1:120,属于严重的数据不平衡问题。 对于数据不平衡的问题,主要分为基于采样的方法和基于算法的方法。基于采样的方法,进一步可分为对于小类样本过采样以及对于大类样本欠采样。基于调整算法的方法有代价敏感方法和SMOTE算法等。这里采用SMOTE算法,根据相邻样本数据合成新的样本,以补充小类数据的不足。 调用Python的Imbalanced-learn库来增加瞒报订舱量,设置瞒报订舱对比未瞒报订舱数据量为1:2,避免变化的新样本对于模型结果产生干扰。 为了避免合成的新样本影响瞒报订舱的预测效果,测试数据保留平衡前的分布,所以SMOTE算法仅针对训练集作平衡处理。
def smoteData(data):
#分为训练集和测试集7:3
A,A2,B,B2=train_test_split(data[[{feature_columns}]],data[[{label_columns}]],test_size=0.3)
X=A.values,y=B.values,X2=A2.values,y2=B2.values
#数据平衡(训练集)
over_samples=SMOTEENN()
X,y=over_samples.fit_sample(X,y)
train=pd.DataFrame(np.hstack((X,y.reshape(-1,1))),columns=data.columns)
test= pd.concat([A2,B2],axis=1)
return [train,test]
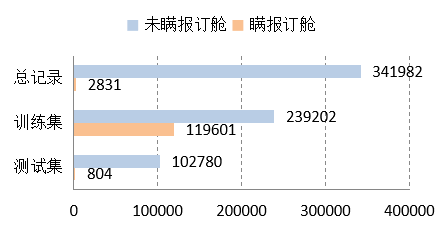
图4.2 使用SMOTE算法做数据平衡处理前后订舱数据分布
五、危险品瞒报预测分析
首先使用传统随机森林进行危险品瞒报预测的分析,将此瞒报预测的结果作为基准,之后在传统随机森林的基础上,与多个常用分类算法调优的结果做比较,以证明随机森林是最适合危险品瞒报预测的算法。 在训练模型前需要先对数据源中的分类型变量进行编码处理,用LabelEncoder将分类信息转换为整型数值。对于无序的离散特征,如货物大类,其特征值是不含顺序的,需使用OneHotEncoder对其进行独热编码。编码处理后将其作为随机森林算法的输入样本训练危险品瞒报预测模型。使用Scikit-learn提供的随机森林分类器RandomForestClassifier。
def dgCargoConcealClassifier(trainTestData):
trainData=trainTestData[0],testData=trainTestData[1]
xFeature=[{feature}], yFeature=[{label}]
X=trainData[xFeature].values,y=trainData[yFeature].values
X2=testData[xFeature].values,y2=testData[yFeature].values
#类别数据,需要进行标签编码
leAgmt=preprocessing.LabelEncoder()
leAgmt=leAgmt.fit(X[:, 0])
X[:,0]=leAgmt.transform(X[:,0])
#随机森林分类器
randomForestClf=RandomForestClassifier()
randomForestClf.fit(X,y)
#模型在测试集上的预测
pred=randomForestClf.predict(X2)
#模型评估
print(metrics.accuracy_score(y2,pred))
print(metrics.classification_report(y2,pred))
#模型持久化
joblib.dump(randomForestClf,'randomForestClf.pkl')
return randomForestClf
5.1 测试结果
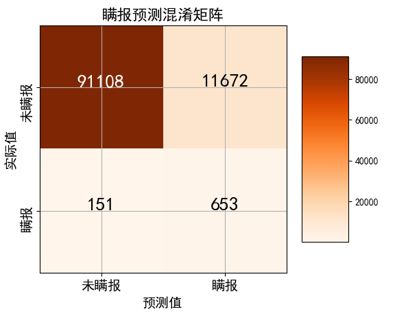
使用独立的测试集对模型进行验证并生成评估报告,得出模型的总体准确率达到87%,鉴于危险品瞒报数据不平衡的特点,不能仅参考准确率,需结合曲线下面积、混淆矩阵等指标综合评价。 通过分类效果评估可以发现,传统随机森林算法得到的危险品瞒报预测模型的性能较好,体现了随机森林算法良好的适应性。
|
性能指标 |
分类效果 |
混淆矩阵 |
瞒报(预测) |
未瞒报(预测) |
|
总体准确率 |
87.45% |
瞒报(实际) |
89961 |
12819 |
|
曲线下面积 |
0.887 |
未瞒报(实际) |
175 |
629 |
5.2 模型优化
传统的随机森林在这个应用场景下还有改进空间,存在进一步提升算法性能的可能性,主要考虑通过增强单棵决策树的分类强度与减少决策树之间的相关性的方式来提升算法的性能 获取所有Scikit-learn构建的决策树,计算每棵树的AUC值,倒序排列,按80%的比例选取AUC值较高的决策树,作为第一步筛选的结果。计算剩余决策树两两之间的相似度,构成相似度矩阵,运用K-means聚类得到半数的决策树组,分别取每个决策树组中的第一条,即AUC值最高的一棵构成新的决策树。
auc_scores=[]
for eachTree in trees:
auc_scores.append(roc_auc_score(y,eachTree.predict_proba(X)[:,1]))
indices=np.argsort(auc_scores)[::-1]
border_auc_socre=auc_scores[indices[int(len(trees)*0.8)]]
filterTrees=[]
for f in range(len(trees)):
if (auc_scores[f]>border_auc_socre):
filterTrees.append(trees[f])
simMatrix=getTreeSimMatrix(filterTrees)
kmodel=KMeans(n_clusters=int(len(trees)*0.4))
kmodel.fit(simMatrix)
existType,filterTrees2=[],[]
for i in range(len(kmodel.labels_)):
if (kmodel.labels_[i] not in existType):
existType.append(kmodel.labels_[i])
filterTrees2.append(filterTrees[i])
计算决策树相关性的具体步骤为:获取两棵决策树各自包含的规则集,以一棵决策树为基准,循环其所有的规则,分别计算与另一棵决策树包含规则的最大相似度,作为该规则的相似度,规则的相似度通过依次比较分支属性来计算,即等于匹配的分支属性数所占的比例,取所有规则相似度的平均值作为决策树的相似度。 在模型性能方面,改进后随机森林的分类能力较强,危险品瞒报预测的总体准确率提升到88%,曲线下面积达到了0.9,各指标均有一定程度的提高。
def calcTreeSimilarity(tree1,tree2):
#获取树的规则集,每一条规则由一系列从根节点到叶节点的子规则构成
allRules1=getTreeRules(tree1)
allRules2=getTreeRules(tree2)
#比较规则集,循环每一条规则,得到其与被比较树中规则的最大相似度并汇总
sim=0
for i in range(len(allRules1)):
subSim=0
rule1=allRules1[i]
for j in range(len(allRules2)):
rule2=allRules2[j]
currSubSim=0;
#依次比较子规则,均为分类属性,比较是否相同即可
for p in range(len(rule1)):
if(len(rule2)>p and rule1[p]==rule2[p]):
currSubSim=currSubSim+1
#规则相似度为 “匹配的子规则数 / 总的子规则数”
currSubSim=currSubSim / max(len(rule1),len(rule2))
#取最大的相似度作为规则的相似度
subSim=max(subSim,currSubSim)
if(subSim==1):
break;
sim=sim+subSim
return sim / len(allRules1)
模型仍然具有一定的提升空间,主要是因为模型中的参数还可以进一步调整,其中主要的可配参数有:随机森林构建决策树的数量;单棵决策树特征最大数量,一般来说提高该值可以提高模型性能,但是会降低决策树的多样性,并且会降低构建速度,通常采用小于 的最大整数,其中M为总特征数;决策树划分评价标准;叶子节点最少样本数;最大树深度;以及节点再划分最小样本数。 使用Hyperopt库来实现随机森林参数的优化,以曲线下面积AUC作为评估函数的衡量标准,选取随机森林主要的参数设定参数空间,使用TPE算法作为Hyperopt的搜索算法,计算得到每一种参数组合的损失函数值,从而输出最优的结果。


通过Trials捕获每一次调优的状态信息,通过Matplotlib以可视化的方式展现调优的过程。 对于危险品订舱瞒报预测,参数中构建决策树的数量、决策树最大特征数以及决策树最大深度等对于随机森林模型性能的影响较大。 得到的最优超参数分别如下:构建决策树的数量为43,再增加决策树的数量模型性能趋于平稳;决策树特征最大数量为6,代表决策树每一次分裂最多考虑6项特征;决策树划分评价标准采用基尼系数Gini;决策树最大深度为26,决定了树的规模;叶子节点最少样本数和节点再划分最小样本数等参数对于性能影响不大,与默认值吻合。
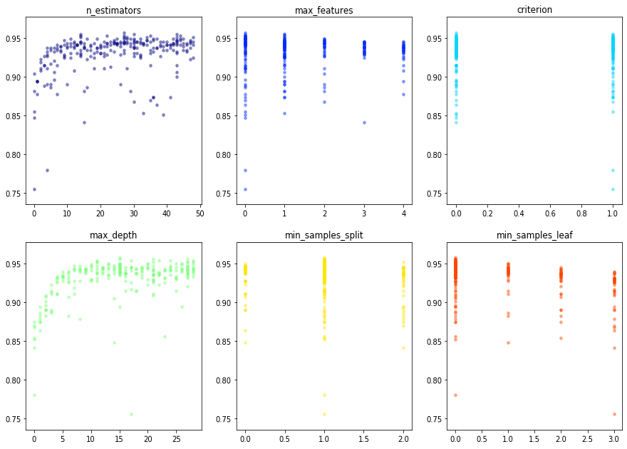
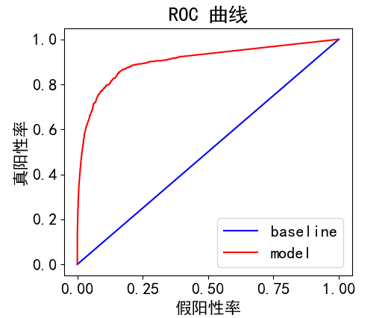
将Hyperopt得出的最优超参数替代RandomForestClassifier分类器的默认参数,重新进行模型的训练并通过测试集验证,。通过Matplotlib将混淆矩阵以及ROC曲线可视化,可直观地评估模型的整体表现。 参数优化后随机森林算法对于危险品瞒报预测的总体准确率达到了88.58%,瞒报类订舱的召回率为81.22%,曲线下面积AUC为0.914,模型的性能较好,在危险品瞒报订舱预测业务中具有较高的应用价值。
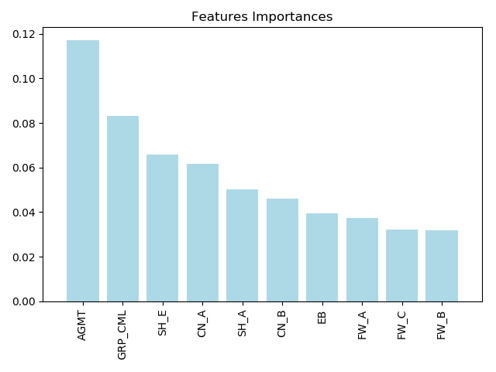
5.3 订舱危险品瞒报预测变量重要性
随机森林算法还具有与XGBoost模型相似的功能,那就是可以通过比较不同特征对于性能的影响得到不同特征的重要性,瞒报订舱重要性排名前10的特征可视化。
由于随机性的引入,随机森林模型是一个在可解释性方面有所欠缺的模型。因此为了在使用随机森林模型预测危险品瞒报订舱时,同时给出此预测结果的判断依据,采用treeinterpreter库来增强模型的可解释性,treeinterpreter可以将决策树的预测分解为各项特征的贡献和,从而使得理解随机森林预测值能够更加直观。
def predBookingConceal(newBooking):
#预测新订舱
clf=joblib.load(‘randomForestClf.pkl')
newBooking=preprocessing(newBooking)
X=newBooking.loc[:, [{feature}]].values
result=clf.predict(X)
#贡献度分解
prediction, bias, contributions=ti.predict(clf, X)
print("预测值:", prediction)
print("偏差值:", bias)
print("特征贡献:")
for c, feature in zip(contributions[0], featureList):
print(feature, c)
5.4 多种算法比较
在面对分类问题时,常用的还有决策树、神经网络、逻辑回归以及贝叶斯网络等算法,这些算法在面对不同特点、规模和领域的数据时各有所长。为了确定随机森林是最适合的算法,分别对以上算法的预测准确性做一次全面的评估。

评估模型的代码


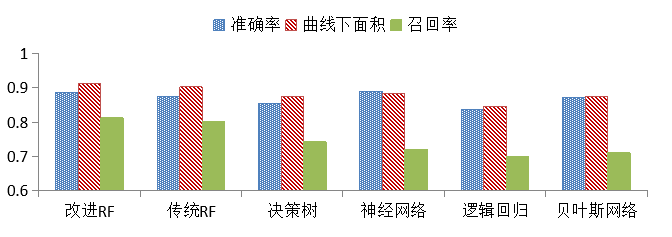
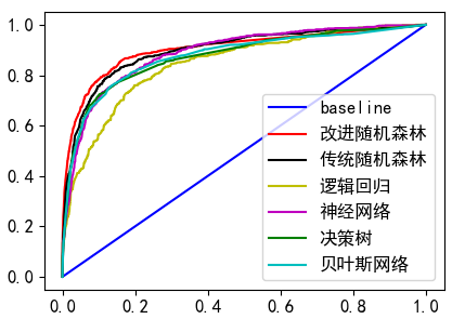
准确度方面神经网络最高,达到89%,改进随机森林以88.6%次之,几类模型均有较高的准确度;曲线下面积以及召回率方面随机森林优势比较明显,改进后进一步提高。 ROC曲线从上到下依次为改进随机森林、传统随机森林、神经网络、贝叶斯网络、决策树和逻辑回归。
六、总结
首先采集最近一年内已完成的船舱订单数据,进行数据集成和清洗,对缺失值清理及业务填补,对错误值和重复数据进行清理。然后使用随机森林算法进行危险品瞒报预测的分析,将此瞒报预测的结果作为基准,进行增强单棵决策树分类强度与减少决策树之间相关性的改写,并对比改进前后的分类效果。最后与多个常用分类算法调优的结果做比较,最终发现随机森林是最适合危险品瞒报预测的算法。
七、参考文献
[1]丁世飞 史忠植.人工智能导论.中国工息出版社,电子公工业出版社,2021(09):16-21.
[2]薛薇.Python机器学习数据建模与分析.机械工业出版社,2023.
[3]CSDN开放平台.https://blog.csdn.net. 2023.
[4]赵卫东 董亮.Python机器学习案例(第二版).清华大学出版社, 2022.
[5]赵卫东 董亮.机器学习[M].北京:人民邮电出版社,2018.
[6]周志华.机器学习[M].北京:清华大学出版社,2016.
[7] Miroslav Kubat.机器学习导论[M].王勇,仲国强,孙鑫,译.北京:机械工业出版社,2016.

欢迎加入北京社区
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)