
第【54期】--基于强化学习的NOMA通信系统资源动态调度算法研究--matlab完整代码
关注我,追更更多通信仿真!
文章目录
摘要
随着第五代移动通信(5G)及未来物联网的快速发展,海量设备接入与多样化业务需求对无线频谱效率和资源管理能力提出了严峻挑战。非正交多址接入(Non-Orthogonal Multiple Access, NOMA)通过功率域复用允许多个用户在相同资源块上并发传输,显著提升了频谱利用率,但接收端需依赖串行干扰消除(Successive Interference Cancellation, SIC)实现用户分离,其性能对调度策略高度敏感。本文针对上行NOMA系统,提出一种基于Q-Learning的动态无线资源块(Wireless Resource Block, WRB)数量调度算法。首先建立包含路径损耗、阴影衰落与瑞利衰落的广义信道模型,推导SIC与非SIC两种模式下的信干噪比(SINR)闭式表达;其次将WRB数量选择建模为马尔可夫决策过程(MDP),设计兼顾传输效率与资源成本的奖励函数,采用Q-Learning实现无模型动态决策;最后通过蒙特卡洛仿真对比固定调度与所提算法的性能。结果验证了强化学习在NOMA资源管理中的有效性。
1 研究背景和意义
1.1 背景
移动通信技术历经五代演进,从模拟语音到超高速数据,不断刷新着人类连接世界的方式。随着5G商用部署的全面推进和6G研究的启动,无线通信系统面临着前所未有的挑战:一方面,海量物联网(Massive IoT)设备接入要求网络具备超大规模连接能力;另一方面,增强移动宽带(eMBB)、超可靠低时延通信(URLLC)等多样化业务对频谱效率和传输可靠性提出了苛刻要求。
传统正交多址接入(Orthogonal Multiple Access, OMA)技术通过将时域、频域或码域资源正交分割后分配给不同用户,从根本上避免了多用户干扰。然而,这种“正交性”的代价是频谱资源利用率的固有上限——当用户数量激增时,正交资源的维度成为制约系统容量的瓶颈。
非正交多址接入(NOMA)技术应运而生,其核心思想是在发射端允许多个用户信号在相同资源块上功率域叠加,在接收端利用串行干扰消除(SIC)按功率强弱依次解码,从而突破正交资源的维度限制,显著提升频谱效率[1]。NOMA已被3GPP认定为5G候选技术之一,并在3GPP Release 16中正式纳入标准框架。
然而,NOMA的性能增益并非无条件获得。SIC接收机的有效性高度依赖复用用户间的功率差异和信道条件,不恰当的调度策略可能导致干扰失控,SINR急剧恶化,反而劣于传统OMA方案。因此,如何动态调整每个时隙的复用用户数和资源块数,在传输效率与干扰抑制之间寻求最优权衡,成为NOMA系统资源管理的核心问题。近年来,强化学习(Reinforcement Learning, RL)凭借无模型、自适应的优势,在无线资源管理领域得到广泛关注。
1.2 意义
本文聚焦于上行NOMA系统中无线资源块(WRB)数量的动态调度问题,,给出基于Q-Learning的调度算法设计。
2 系统模型
2.1 发射信号模型
2.1.1 网络拓扑

2.1.2 功率域NOMA

2.2 无线信道模型
2.2.1 路径损耗

2.2.2 阴影衰落

2.2.3 小尺度衰落

2.2.4 复合信道增益

2.3 接收信号
2.3.1 NOMA叠加接收信号

2.3.2 串行干扰消除(SIC)下的SINR推导

2.3.2 无SIC场景下的SINR退化形式

2.3.4 单包传输成功判据

2.4 WRB数量的内在约束与权衡
WRB之间虽正交无干扰,但从通信理论角度,其数量nw的取值受约束限制,并非越大越好:
-
总功率预算约束

WRB数量越大,每个WRB内各数据包的分配功率均按比例降低,SINR会降低。 -
复用用户数稀释与SIC增益退化

换言之,从通信理论角度看,增加 WRB 数量虽然降低了单 WRB 的复用度,从而减少了干扰源,但过度增加会稀释每个 WRB 内的用户数,导致 SIC 增益退化。这一约束与前述的功率稀释效应共同作用,使得系统性能随 nw的变化呈现非单调性,而非简单地越大越好。
2.5.系统级性能指标
2.5.1传输时隙数T

2.5.2 丢包数 N l o s t {N_{lost}} Nlost

2.5.3 统计平均指标
由于信道衰落、节点位置和数据包分布的随机性,采用蒙特卡洛统计方法进行性能评估。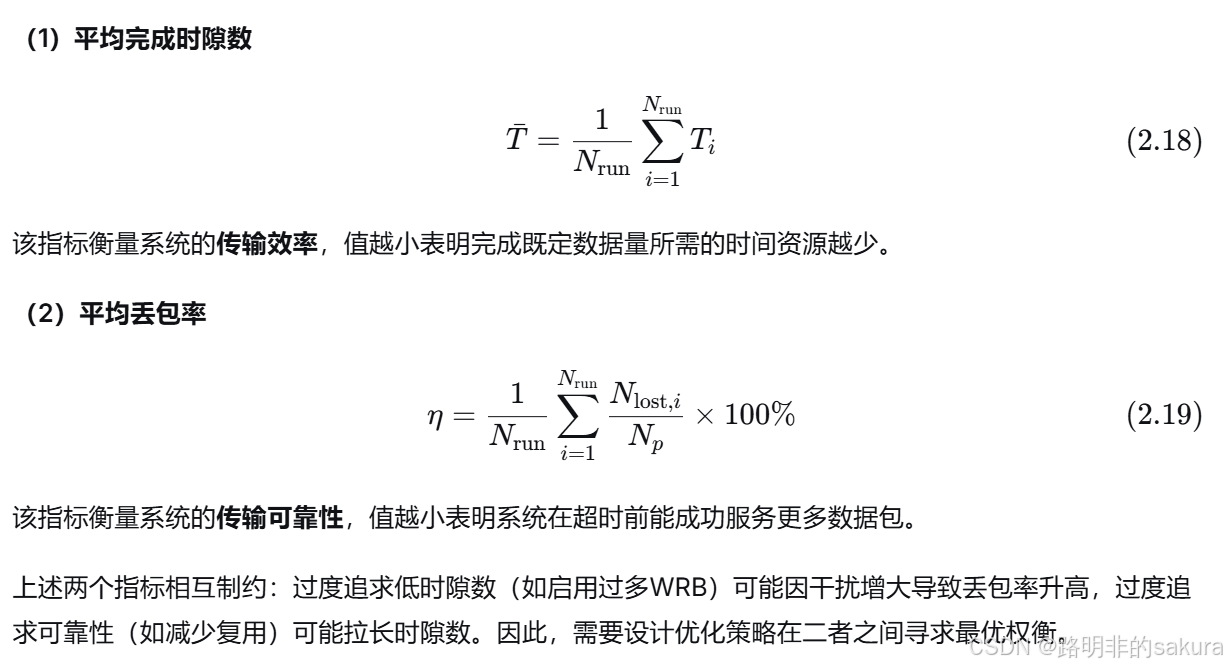
2.6 资源调度优化问题建模
2.6.1 决策变量与策略空间

2.6.2 优化问题形式化描述
本文想设计一种调度策略,在每个时隙根据当前剩余包数和当前 WRB 使用数,决定下一时隙应该增加、保持还是减少 WRB,使得完成全部数据包传输的总时隙和丢包率在统计意义上最小化。
上述特性使得传统优化方法(如穷举、动态规划、凸优化)难以在线求解,故需引入无模型强化学习算法进行逼近,在“传输效率”与“干扰抑制”之间实现权衡。
3 基于Q-learning的资源调度算法设计
3.1 马尔可夫决策过程建模
将资源调度问题重构为马尔可夫决策过程(Markov Decision Process, MDP),以规避传统优化方法对精确系统模型的依赖。具体定义如下:




3.2 Q值迭代与更新规则

3.3 动作选择策略(ε-贪婪)


3.4 算法流程

4 仿真结果分析
4.1 参数设置
| 参数类别 | 参数名称 | 符号 | 取值 |
|---|---|---|---|
| 网络拓扑 | 节点数 | N n N_n Nn | 10 |
| 区域大小 | L × L L \times L L×L | 100 m × 100 m | |
| 物理层 | 发射功率 | P x P_x Px | 1 W |
| 噪声功率 | N 0 N_0 N0 | 10 − 5 10^{-5} 10−5 W | |
| 路径损耗指数 | α \alpha α | 2.5 | |
| 阴影衰落标准差 | σ s \sigma_s σs | 2 dB | |
| 瑞利衰落参数 | σ f \sigma_f σf | 4 | |
| SINR 阈值 | β \beta β | 5 × 10 − 8 5 \times 10^{-8} 5×10−8 | |
| 资源调度 | 最大 WRB 数 | N w N_w Nw | 5 |
| 每 WRB 最大复用包数 | N max N_{\max} Nmax | 5 | |
| 数据包数量集合 | N p N_p Np | {10, 20, 30, 40, 50} | |
| 蒙特卡洛运行次数 | N run N_{\text{run}} Nrun | 2000 | |
| 最大允许时隙数 | T max T_{\max} Tmax | ⌊ N p / 3 ⌋ \lfloor N_p / 3 \rfloor ⌊Np/3⌋ | |
| Q-Learning | 训练 episode 数 | E max E_{\max} Emax | 1000 |
| 学习率 | α \alpha α | 0.8 | |
| 折扣因子 | γ \gamma γ | 0.2 | |
| 资源成本因子 | δ \delta δ | 0.9 | |
| 衰减陡峭度 | κ \kappa κ | 10 | |
| 衰减中点位置 | e 0 e_0 e0 | E max / 1.8 E_{\max} / 1.8 Emax/1.8 |
4.2 对比方案
为评估Q-Learning动态调度算法的性能增益,引入以下四类方案进行对比:
-
固定单WRB调度(无SIC):每个时隙固定使用1个WRB,接收端不采用SIC,SINR按式 (2.11) 计算。该方案代表传统正交多址系统,提供性能下界参考。
-
固定单WRB调度(有SIC):每个时隙固定使用1个WRB,接收端采用SIC,SINR按式 (2.10) 计算。该方案代表NOMA系统的基础性能,但缺乏对负载变化的自适应能力。
-
Q-Learning动态调度(无SIC):Q-Learning智能体动态调整WRB数量,但接收端不采用SIC,用于评估强化学习在纯干扰场景下的调度增益。
所有方案均使用完全相同的随机种子生成节点位置与数据包分布,确保对比公平性。对于Q-Learning方案,训练与评估使用相同的信道统计分布,但每次独立运行重新生成信道实现,评估其泛化性能。
4.3 仿真图分析
4.3.1 奖励的收敛性
可以看到不同包数量奖励函数的收敛性。
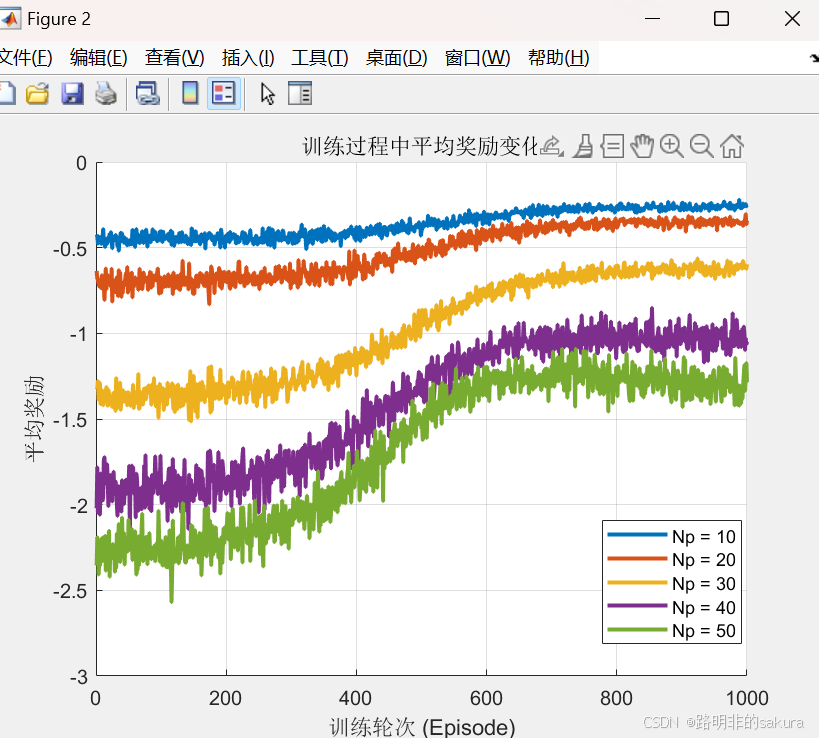
4.3.2 平均完成时隙和丢包率
可以看到所提方案相对于基准算法的优势
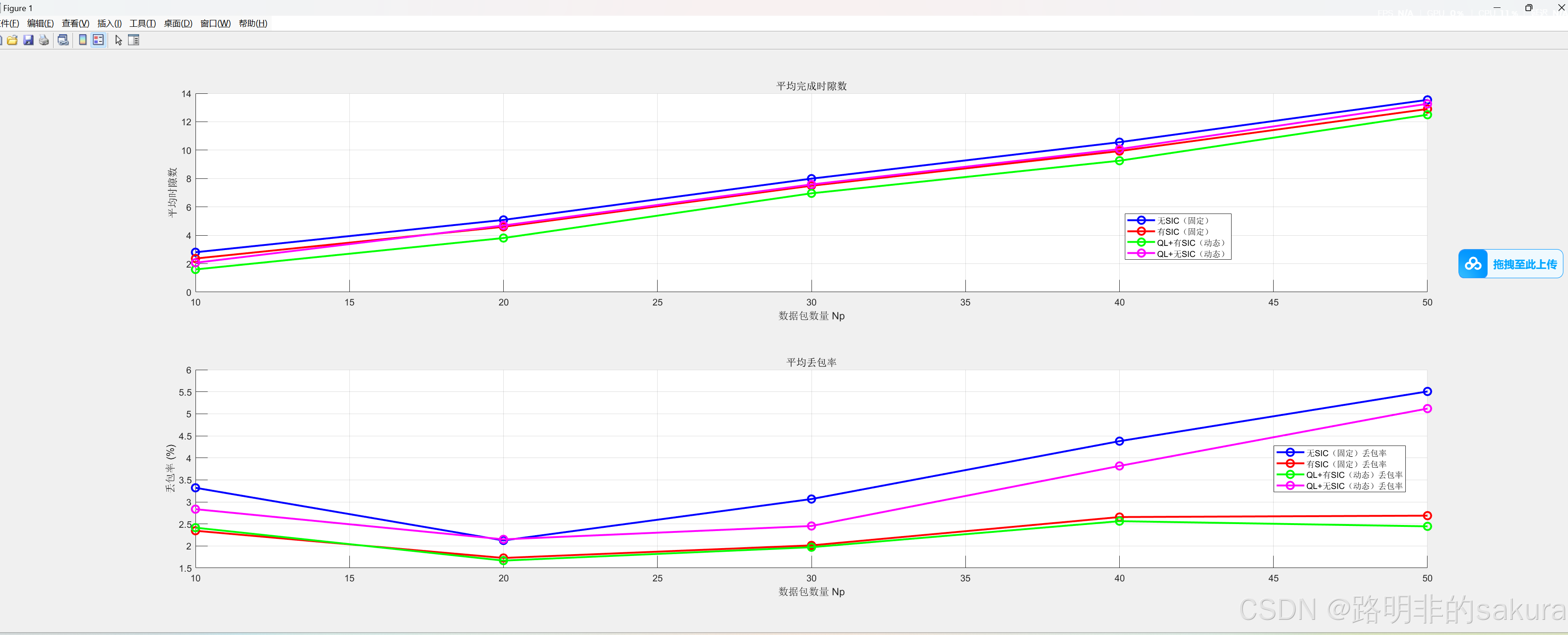
4.3.3 WRB的使用个数
部分代码:
% 设置全局中文字体(防止乱码)
set(0, 'DefaultAxesFontName', 'SimHei');
set(0, 'DefaultTextFontName', 'SimHei');
set(0, 'DefaultLegendFontName', 'SimHei');
clear; clc; close all;
%% 参数初始化
params = initParams();
%% 结果存储矩阵
T_SIC = zeros(params.Nrun, length(params.Np)); % 固定调度+SIC 时隙数
T_no_SIC = zeros(params.Nrun, length(params.Np)); % 固定调度+无SIC 时隙数
T_QL_SIC = zeros(params.Nrun, length(params.Np)); % QL+SIC 时隙数
T_QL_noSIC = zeros(params.Nrun, length(params.Np)); % QL+无SIC 时隙数
% 丢包数存储
LostPackets_noSIC = zeros(params.Nrun, length(params.Np));
LostPackets_SIC = zeros(params.Nrun, length(params.Np));
LostPackets_QL_SIC = zeros(params.Nrun, length(params.Np));
LostPackets_QL_noSIC= zeros(params.Nrun, length(params.Np));
% 用户位置图(并保存位置)
userPositions = plotUserDistribution(params);
% Q-Learning 过程记录(奖励、时隙、WRB使用)
rewards = zeros(params.Nep, length(params.Np), params.Nrun);
t_episodesQL = zeros(params.Nep, length(params.Np), params.Nrun);
nw_usedQL = zeros(params.Nep, length(params.Np), params.Nrun);
%% 主循环:遍历不同的数据包数量 Np
for npIndex = 1:length(params.Np)
fprintf('开始仿真 Np = %d\n', params.Np(npIndex));
% 生成数据包分布(源-目的节点对)
P = initializePacketDistribution(params, npIndex);
channelGains = calculateGains(userPositions, params);
SNR0 = zeros(1,params.Np(npIndex));
for i = 1:params.Np(npIndex)
SNR0(i)= (params.Px * channelGains(P(i,1),P(i,2))^2)/params.N0;
end
beta = 0.5*min(SNR0);
params.beta = beta;
%% 对每个 Np 进行多次独立运行(蒙特卡洛)
for run = 1:params.Nrun
fprintf(' 第 %d 次运行 (Np=%d)\n', run, params.Np(npIndex));
% ---- 1. 固定调度,无 SIC ----
[t_noSIC, lost_noSIC] = runResourceAssignment(params, P, userPositions, false);
T_no_SIC(run, npIndex) = t_noSIC;
LostPackets_noSIC(run, npIndex) = lost_noSIC;
% ---- 2. 固定调度,有 SIC ----
[t_SIC, lost_SIC] = runResourceAssignment(params, P, userPositions, true);
T_SIC(run, npIndex) = t_SIC;
LostPackets_SIC(run, npIndex) = lost_SIC;
% ---- 3. Q-Learning 动态调度,有 SIC ----
[Q_SIC, t_QL_SIC_run, lost_QL_SIC_run, episode_rewards, t_episodes, nw_episodes] = ...
runResourceAssignmentWithQL(params, P, userPositions, true);
T_QL_SIC(run, npIndex) = t_QL_SIC_run;
LostPackets_QL_SIC(run, npIndex) = lost_QL_SIC_run;
rewards(:, npIndex, run) = episode_rewards;
t_episodesQL(:, npIndex, run) = t_episodes;
nw_usedQL(:, npIndex, run) = nw_episodes;
% ---- 4. Q-Learning 动态调度,无 SIC ----
[Q_noSIC, t_QL_noSIC_run, lost_QL_noSIC_run, ~, ~, ~] = ...
runResourceAssignmentWithQL(params, P, userPositions, false);
T_QL_noSIC(run, npIndex) = t_QL_noSIC_run;
LostPackets_QL_noSIC(run, npIndex) = lost_QL_noSIC_run;
end
end
%% 计算平均性能
% 平均时隙数
avgSlots_noSIC = mean(T_no_SIC, 1);
avgSlots_SIC = mean(T_SIC, 1);
avgSlots_QL_SIC = mean(T_QL_SIC, 1);
avgSlots_QL_noSIC = mean(T_QL_noSIC, 1);
% 平均丢包率(百分比)
percLost_noSIC = mean(LostPackets_noSIC ./ repmat(params.Np, params.Nrun, 1) * 100, 1);
percLost_SIC = mean(LostPackets_SIC ./ repmat(params.Np, params.Nrun, 1) * 100, 1);
percLost_QL_SIC = mean(LostPackets_QL_SIC ./ repmat(params.Np, params.Nrun, 1) * 100, 1);
percLost_QL_noSIC = mean(LostPackets_QL_noSIC ./ repmat(params.Np, params.Nrun, 1) * 100, 1);
5 总结
本文针对上行NOMA系统中无线资源块(WRB)数量的动态调度问题,提出了一种基于Q-Learning的强化学习解决方案。通过建立包含复合信道模型和SIC接收机的系统模型,将WRB调度问题形式化为马尔可夫决策过程,并设计了兼顾传输效率与资源成本的奖励函数。仿真结果验证了强化学习在NOMA资源管理中的有效性与自适应性。未来工作可考虑更复杂的信道模型、多智能体协作以及在线学习机制,以进一步提升算法在动态环境中的鲁棒性。
仿真代码可见文末VX公众号(包含往期博客所有代码),所见即所得
更多推荐

 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)