
Python 爬虫实战:10wallpaper 壁纸批量下载器
一、项目介绍
本项目实现:
- 自动爬取多页壁纸图片
- 随机 UA 伪装,避免被网站拦截
- 自动创建文件夹保存图片
- 自动编号,不重复、不覆盖
- 代码极简、可直接复制运行
二、环境准备(必装,一步到位)
运行代码前,只需安装 3 个基础库(1 个系统自带),无需复杂配置,复制命令直接安装,避开所有安装坑:
requests:核心库,负责发送网络请求,获取网页内容和图片数据lxml:解析 HTML 网页,用 XPath 精准提取图片链接,爬虫解析必备fake_useragent:随机生成浏览器 UA 标识,防反爬关键,避免被网站拦截os:系统自带库,无需安装,负责创建保存文件夹、判断文件路径
安装命令(复制到终端,回车即可,建议用清华源提速,避免安装超时):
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install fake_useragent -i https://pypi.tuna.tsinghua.edu.cn/simple
三、逐行代码超详细解析
很多新手复制代码能运行,但不知道原理,这里逐行拆解每一段代码,讲清底层逻辑,看完就能举一反三,轻松应对其他图片爬虫项目!
1. 导入模块
python
import fake_useragent
import requests
from lxml import etree
import os
解析:每个库的核心作用,新手不用死记硬背,知道用途即可快速上手:
fake_useragent:生成随机浏览器标识,模拟真人访问,避免被网站识别为爬虫、拦截 IPrequests:爬虫核心库,负责向目标网站发送网络请求,获取网页源码和图片二进制数据lxml.etree:解析 HTML 网页内容,用 XPath 语法快速定位、提取我们需要的图片链接os:系统自带库,无需额外安装,负责创建图片保存文件夹、判断文件路径,避免保存时因路径不存在报错
2. 图片自动编号(避免重名覆盖)
python
n = 0
def count():
global n
n += 1
return n
解析:定义全局计数器n,搭配count()函数,每下载一张图片,编号自动 + 1,保存为 1.jpg、2.jpg、3.jpg...,彻底解决图片重名、覆盖的问题,让保存的壁纸更规范,无需手动整理。
3. 自动创建保存目录
python
if not os.path.exists("./Picture"):
os.mkdir("./Picture")
解析:判断当前 Python 项目目录下,是否存在 “Picture” 文件夹;如果不存在,自动创建该文件夹,避免后续保存图片时,因路径不存在报错
4. UA 伪装
python
head = {
"User-Agent": fake_useragent.UserAgent().random
}
解析:爬虫必备的防反爬手段!如果不添加 UA 伪装,网站会直接识别出请求来自 Python 程序,进而拦截请求,导致爬不出任何内容;用fake_useragent库,每次运行代码都会生成随机的浏览器标识,完美模拟真人浏览行为,大大降低被拦截的概率。
5. 循环爬取多页
python
for i in range(1, 3):
url = f'https://10wallpaper.com/List_wallpapers/page/{i}'
解析:range(1, 3) 表示爬取第 1 页和第 2 页壁纸;如果想多爬几页,直接修改 range 范围即可(比如爬 10 页改成range(1, 11)),新手可根据自己的需求灵活调整,操作极简。
6. 请求网页 + 解析 HTML
python
resp = requests.get(url, headers=head)
result = resp.text
tree = etree.HTML(result)
解析:这三步是爬虫获取数据的核心,一步都不能少:
requests.get(url, headers=head):向目标网页发送 GET 请求,带上 UA 伪装,获取网页完整源码resp.text:将获取到的网页响应,转为字符串格式的 HTML 源码,方便后续解析etree.HTML(result):将字符串格式的源码,转为可使用 XPath 解析的对象,为提取图片链接做准备
7. XPath 定位图片
python
p_list = tree.xpath("//div[@id='pics-list']/p")
解析:这是精准提取图片的关键一步!通过 XPath 语法,定位到 “id 为 pics-list 的 div 标签” 下的所有 p 标签,这些 p 标签里面,就包含了我们需要的壁纸图片链接,新手无需修改,直接复用即可,确保定位精准不报错。
8. 提取图片链接并拼接完整地址
python
img_url = p.xpath("./a/img/@src")[0]
img_url2 = 'https://10wallpaper.com' + img_url
解析:新手最容易踩的坑就在这里,一定要注意!
p.xpath("./a/img/@src")[0]:从每个 p 标签中,提取里面 a 标签下 img 标签的 src 属性(也就是图片链接),但这里提取到的是 “相对路径”(比如/wallpaper/xxx.jpg),无法直接用于下载img_url2 = 'https://10wallpaper.com' + img_url:将相对路径拼接上 10wallpaper 网站的主域名,得到完整的图片 URL,只有完整 URL 才能正常下载图片,缺一不可!
9. 下载并保存图片
python
print("正在下载:", img_url2)
img_name = count()
img_resp = requests.get(img_url2, headers=head)
with open(f"./Picture/{img_name}.jpg", "wb") as fp:
fp.write(img_resp.content)
解析:这是壁纸下载的最终步骤,每一步都有明确作用,新手必懂:
print("正在下载:", img_url2):在终端实时显示当前下载的图片链接,方便查看下载进度,也能快速排查链接是否无效img_name = count():调用计数函数,获取当前图片的编号,作为图片保存的文件名img_resp = requests.get(img_url2, headers=head):向完整的图片 URL 发送请求,获取图片的二进制数据(图片、视频等资源,均以二进制形式存在)with open(...) as fp:用 “自动关闭文件” 的方式打开文件,避免手动关闭文件导致的资源泄露,更安全、更省心wb:二进制写入模式,必须用这个模式保存图片,若用w文本模式,会导致图片损坏、无法打开(新手必记!)fp.write(img_resp.content):将获取到的图片二进制数据,写入到本地 Picture 文件夹中,完成壁纸下载
四、运行效果
运行代码后,终端会实时显示下载进度,清晰明了,如下所示:
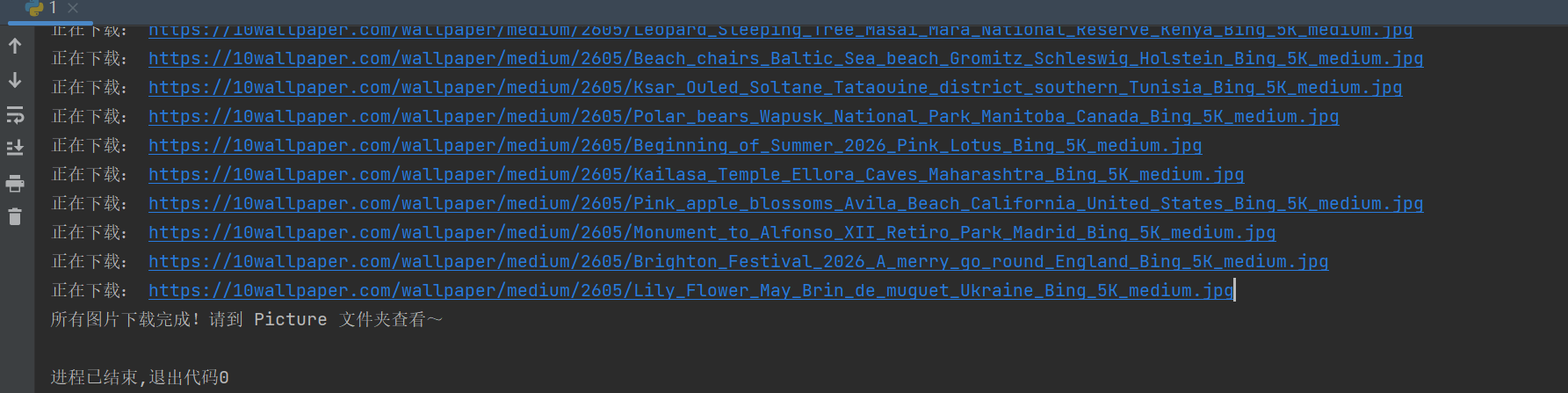
打开你的 Python 项目目录,找到自动创建的「Picture」文件夹,里面就是所有下载好的高清壁纸。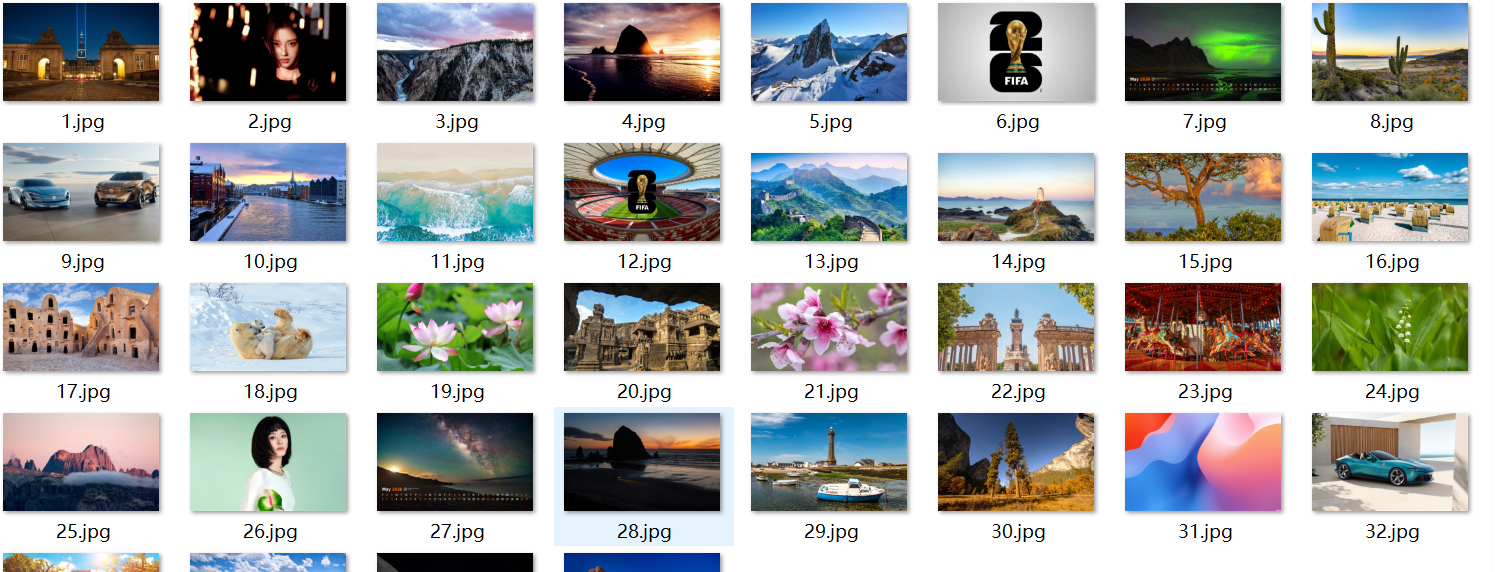
五、完整可运行代码(复制即生效,新手零报错)
无需修改任何内容,复制到 Python 编辑器(PyCharm即可),直接运行
python
# 导入需要的库(新手无需修改)
import fake_useragent
import requests
from lxml import etree
import os
# 全局计数器,给图片自动编号(防止重名覆盖)
n = 0
def count():
global n
n += 1
return n
# 自动创建图片保存文件夹(不存在则创建,避免报错)
if not os.path.exists("./Picture"):
os.mkdir("./Picture")
# 随机UA伪装,模拟真实浏览器,避免被网站拦截(爬虫核心防反爬)
head = {
"User-Agent": fake_useragent.UserAgent().random
}
# 爬取第1-2页(想多爬几页,直接修改range范围即可)
for i in range(1, 3):
# 拼接每页的URL地址
url = f'https://10wallpaper.com/List_wallpapers/page/{i}'
# 发送请求,获取网页源码
resp = requests.get(url, headers=head)
result = resp.text
# 解析网页,准备提取图片链接
tree = etree.HTML(result)
# XPath定位所有图片所在的标签(精准定位,避免爬取失败)
p_list = tree.xpath("//div[@id='pics-list']/p")
# 遍历每个图片标签,提取链接并下载
for p in p_list:
# 提取图片相对路径
img_url = p.xpath("./a/img/@src")[0]
# 拼接完整的图片URL(关键一步,否则无法下载)
img_url2 = 'https://10wallpaper.com' + img_url
print("正在下载:", img_url2)
# 获取图片编号
img_name = count()
# 下载图片数据
img_resp = requests.get(img_url2, headers=head)
# 二进制模式保存图片到本地文件夹
with open(f"./Picture/{img_name}.jpg", "wb") as fp:
fp.write(img_resp.content)
print("🎉 所有图片下载完成!请到 Picture 文件夹查看~")更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)