
python学习-xx14-1 pandas【⭐】
1 pandas介绍
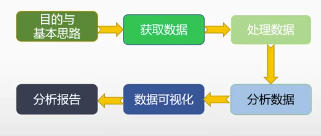
确认目的和思路:决定方向
获取数据:(采集器)web端-用户行为数据 app端-数据采集买点-日志/数据库收集 第三方-买数据或者抓取数据
处理数据:将不规整的数据进行整理和规范化
分析数据:依据目的进行标准数据的分析
数据可视化:数据分析的简单结果,对数据更深入的挖掘,这是有价值的地方
分析报告:生成数据分析的报表
pandas的优势(与Excel比较):高效处理海量数据,功能更强大
- pandas是python中数据分析核心库,能够快速,灵活的对大量数据进行分析,是Python进行数据分析的必要利器
- pandas支持多种数据导入,支持数据合并,拆分,基本统计,时间序列分析,透视表等多种操作
2 pandas主要内容
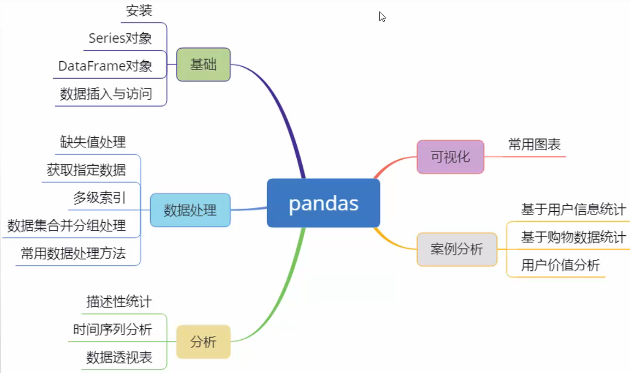
可以简单认为是numpy和matplotlib的强化版组合
- 掌握pandas中series与dataframe
- pandas数据清洗
- 使用pandas进行数据基本统计
- 时间序列分析
- 数据分析常用方法
3 pandas基础
3.1 series数据结构(一维的带索引数据结构(单列))
索引可以理解为是列表中的索引
Series类:
pd.Series(data=None,index=None,dtype=None,name=None,copy=False,fastpath=False)
(注意S一定要大写)








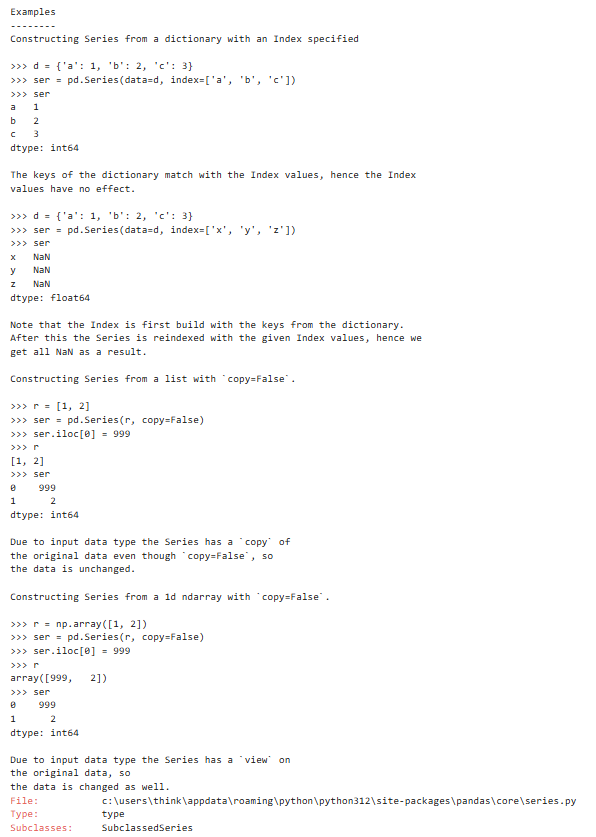
3.1.1 创建series
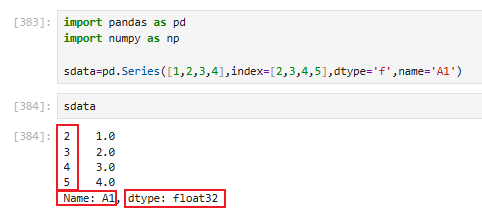
3.1.2 访问series(用索引)
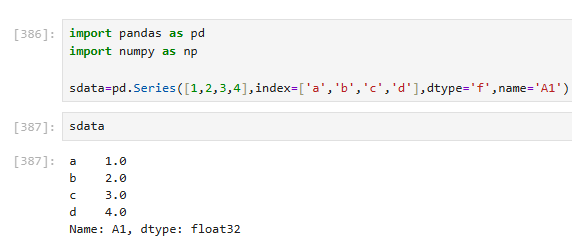
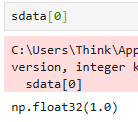
方法一:使用默认数字索引(隐式索引)
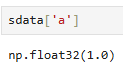
方法二:使用标签(显示索引)
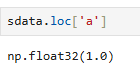
方法三:使用loc方式(仅适用于标签)
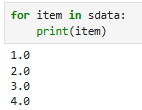
迭代:
直接访问是值
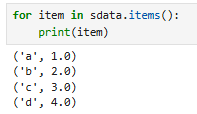
用.items()可以获取索引(标签)
3.1.3 获取index和value
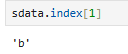
.index: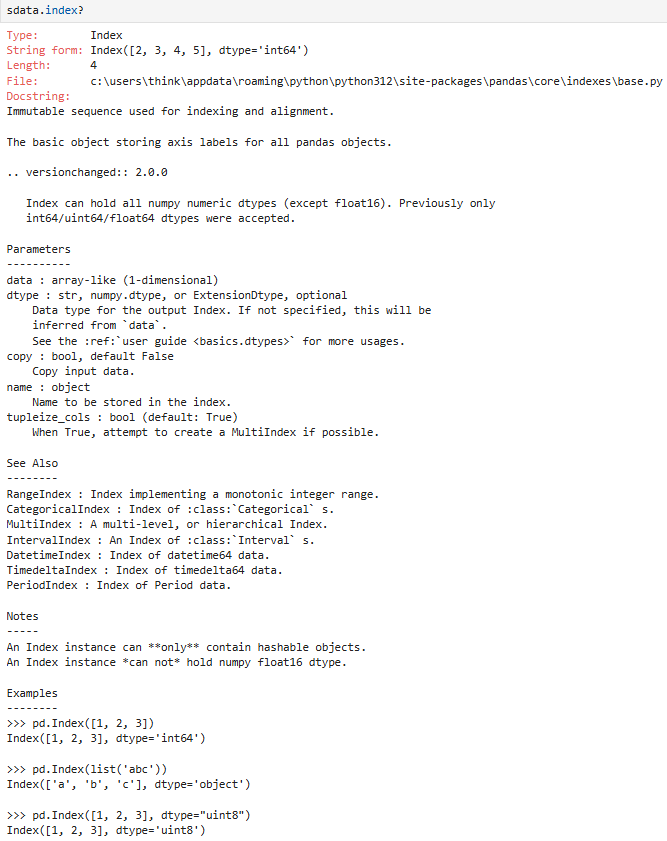
获取的是index的对象

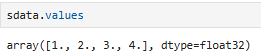
.values:

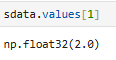
获取全部的值
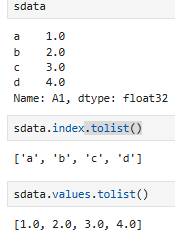
3.1.4 将index和value转换为列表(.tolist)
3.2 dataframe数据结构(多种类型的列构成的二维标签数据结构(多列))
DataFrame类:
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)









3.2.1 创建dataframe
原始
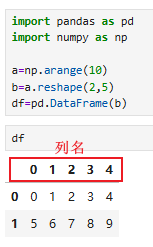
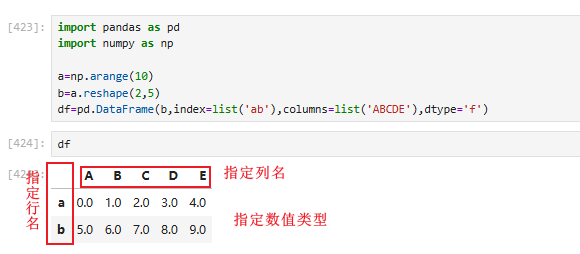
配置参数
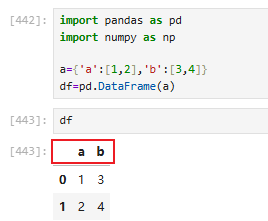
用字典创建(key值作为列标签)
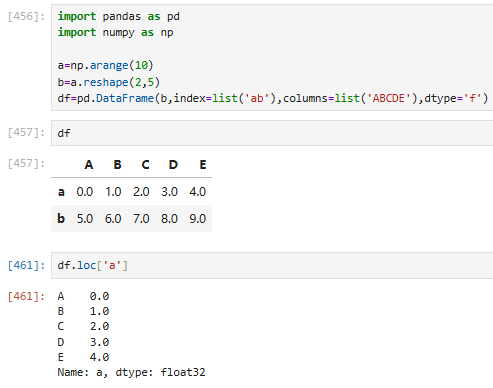
3.2.2 访问dataframe(只能按标签,先列后行)
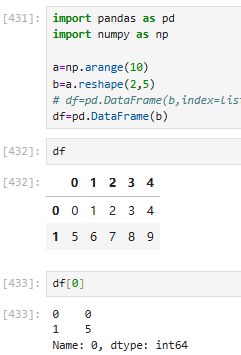
注意dataframe是按列访问的,df[0]是一个series
方法一:先列再行
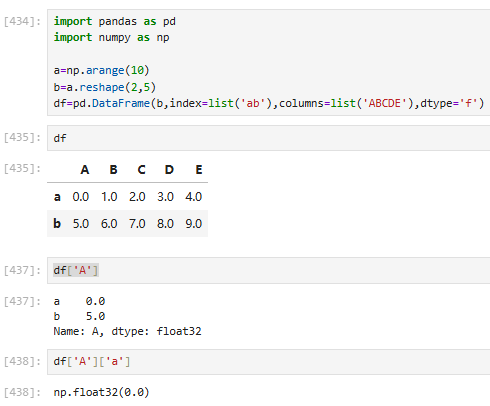
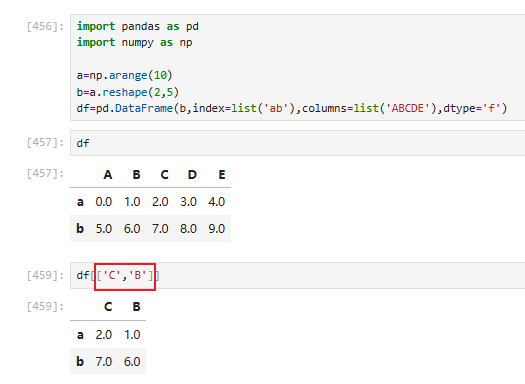
方法二:获取指定多列
[列名1,列名2,。。。]
方法三:.loc()方法【可以指定行获取,可以做切片,更灵活】



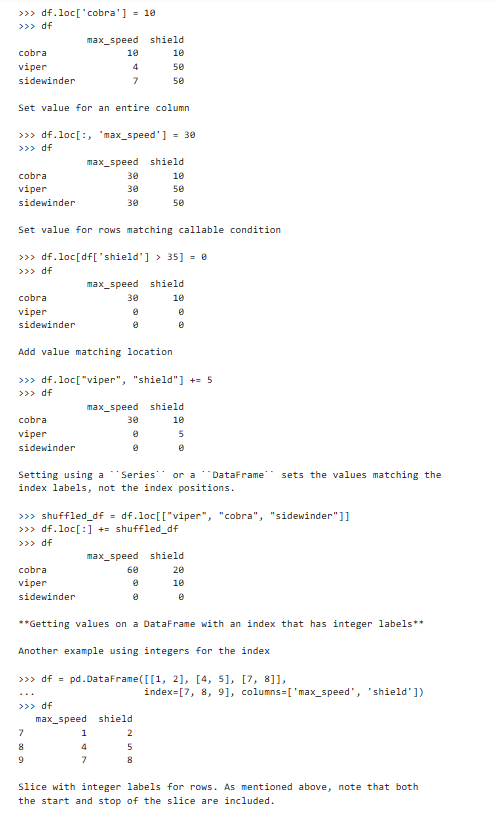

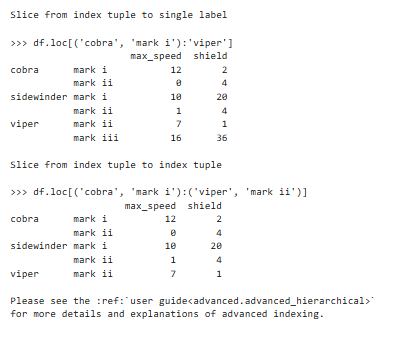
获取第'a'行
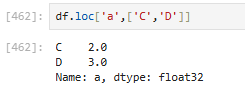
获取第'a'行的指定的C、D列
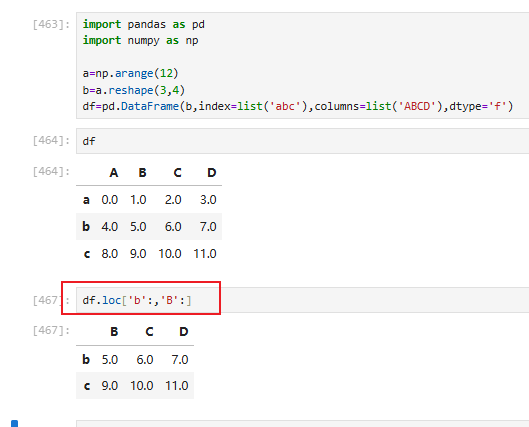
可进行切片操作
3.2.3 指定/更换 列(columns)和行(index)的标签
列标签(.columns)
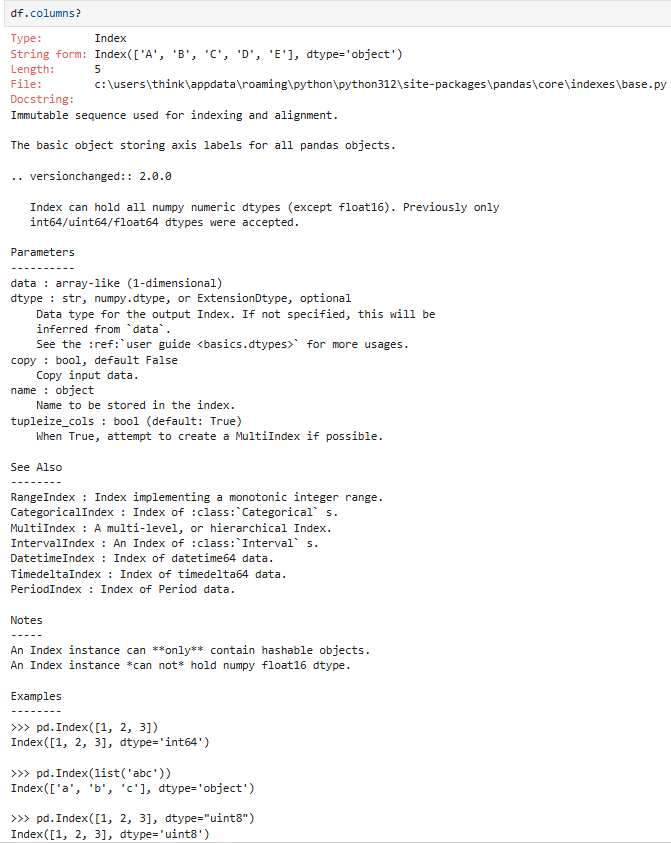
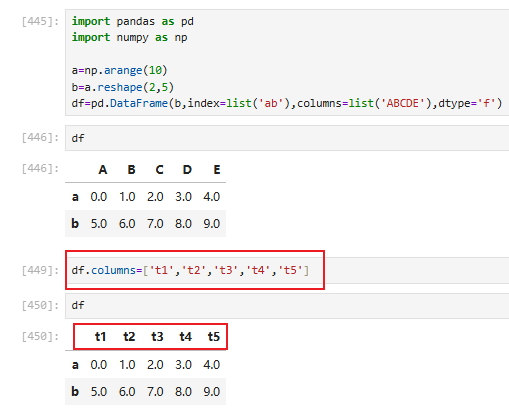
行标签(.index)
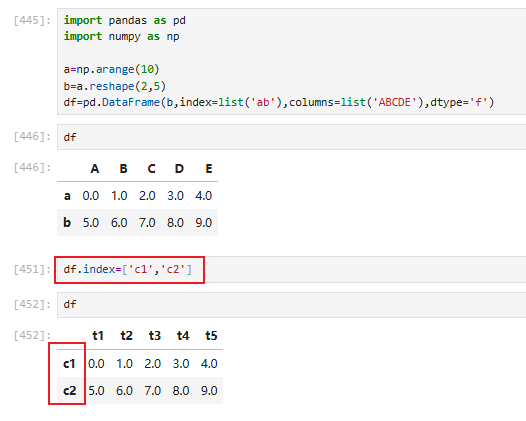
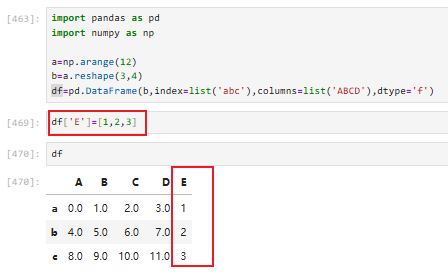
3.2.4 对dataframe进行修改
3.2.4.1 dataframe插入列
直接指定一个列的名称并且赋值即可
3.2.4.2 dataframe插入行(loc)
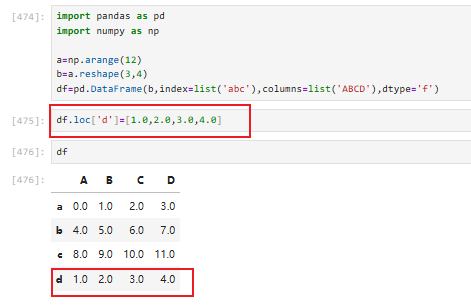
一定要注意数据类型,不然会报错
3.2.4.3 dataframe修改行/列
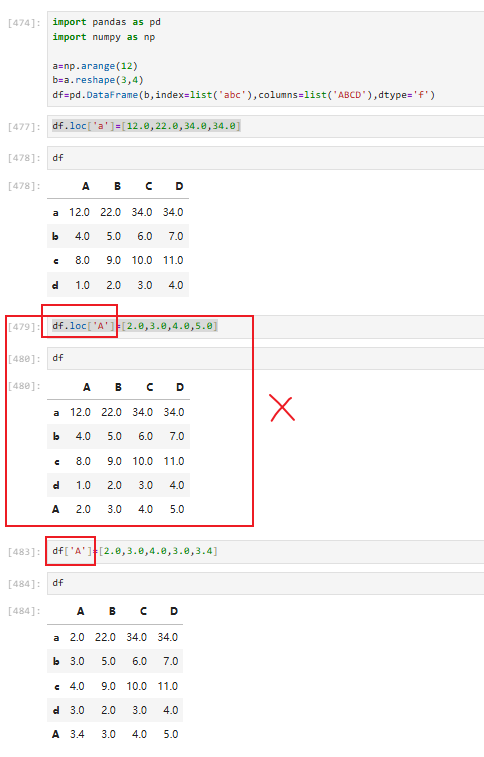
可以看出来loc适用于对行的修改,列直接用列名即可
4 pandas数据导入与保存
目的:
数据导入:excel, csv文件
数据导出
基本统计
缺省数据处理
4.1 数据导入
数据是分析基础,实际工作中,数据来源:来自于企业内部数据,网络数据,开源数据集
pandas支持导入方式(读取csv、excel、json文件):

4.1.1读取excel文件(pd.read_excel)
使用的是xlrd这个模块读取的,如果Excel的版本比较老,有可能读取不了,这个需要注意
4.1.1.1说明
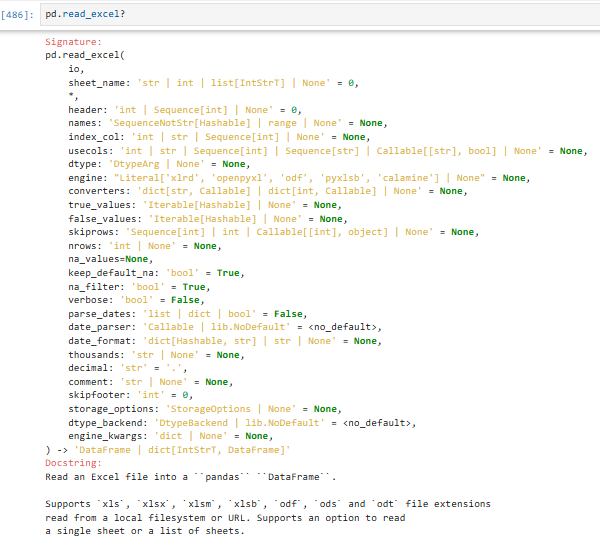




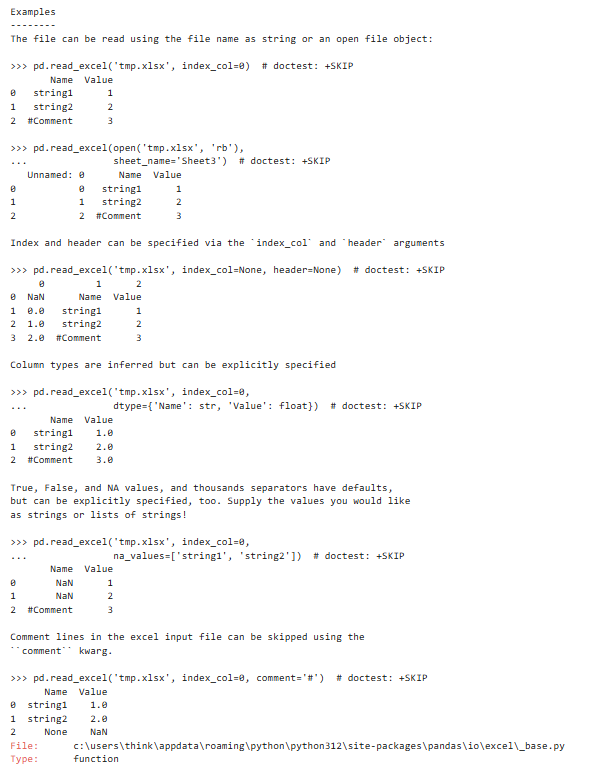
参数解释

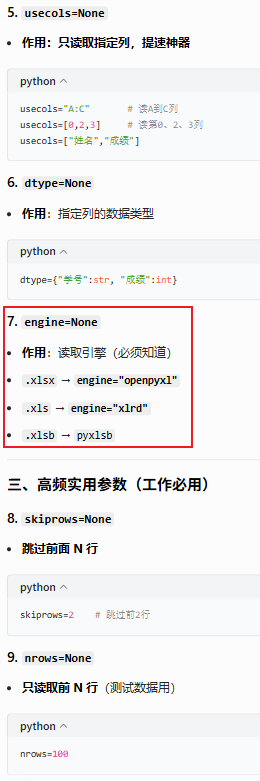
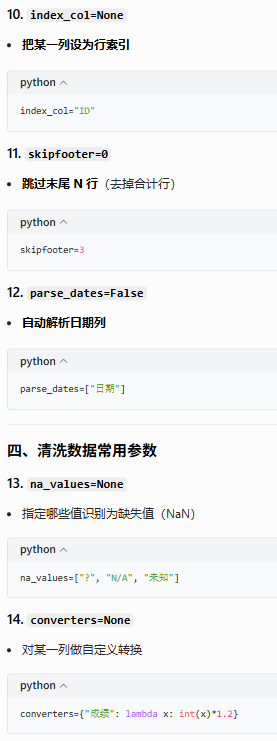
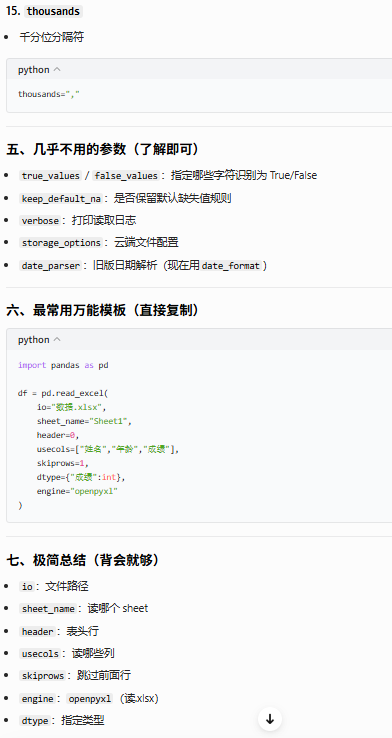
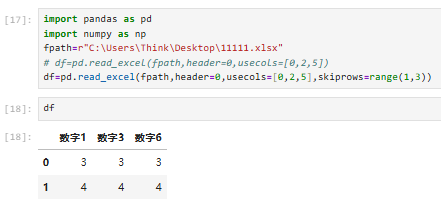
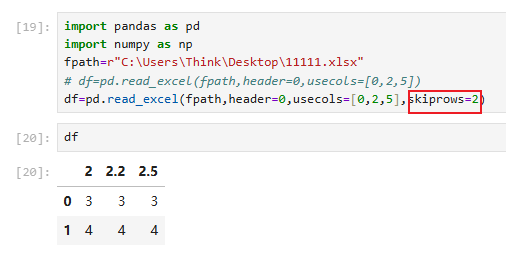
4.1.1.2示例
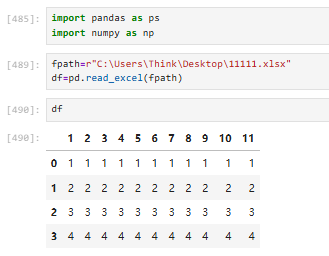
注意skiprows直接跳过表头会有问题
4.1.2 读取csv文件(pd.read_csv)
4.1.2.1 说明





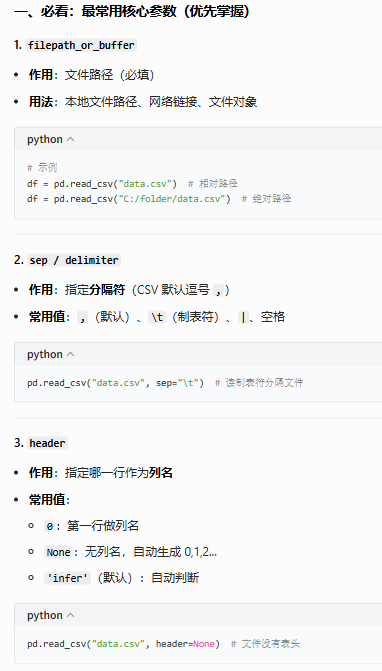
| 参数名 | 作用 | 常用值 / 写法 | 重要程度 |
|---|---|---|---|
|
filepath_or_buffer (可以指定目录filepath也可以指定文件对象buffer) |
文件路径 / URL | 'data.csv' |
⭐⭐⭐⭐⭐ |
| sep | 分隔符(逗号 / 制表符等) | ',' '\t' `' |
⭐⭐⭐⭐⭐ |
| delimiter | sep 别名 | 同 sep | ⭐⭐ |
| header | 用第几行做列名 | 0 / None |
⭐⭐⭐⭐⭐ |
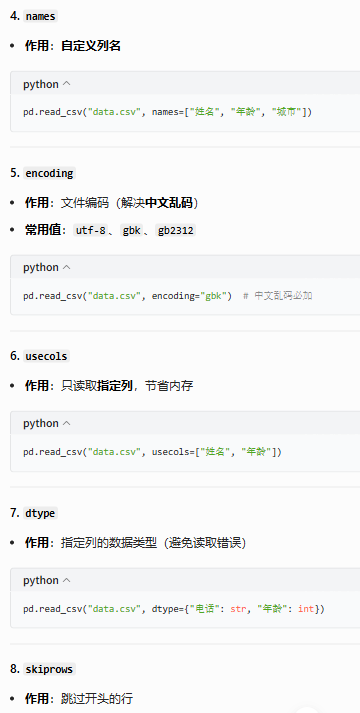
| names | 自定义列名 | ['姓名','年龄'] |
⭐⭐⭐⭐ |
| index_col | 把某列设为行索引 | 0 / 'ID' |
⭐⭐⭐⭐ |
| usecols | 只读取指定列 | [0,2] / ['姓名'] |
⭐⭐⭐⭐⭐ |
| dtype | 指定列数据类型 | {'手机号':str} |
⭐⭐⭐⭐ |
| engine | 读取引擎 | 'c' 快 / 'python' 兼容 |
⭐⭐⭐ |
| skiprows | 跳过前面 N 行 / 指定行 | 2 / [0,1] |
⭐⭐⭐⭐⭐ |
| skipfooter | 跳过末尾 N 行 | 3 |
⭐⭐⭐ |
| nrows | 只读取前 N 行 | 1000 |
⭐⭐⭐⭐ |
| na_values | 把指定值识别为空值 | ['未知','-'] |
⭐⭐⭐ |
| encoding | 文件编码(解决乱码) | 'utf-8' / 'gbk' |
⭐⭐⭐⭐⭐ |
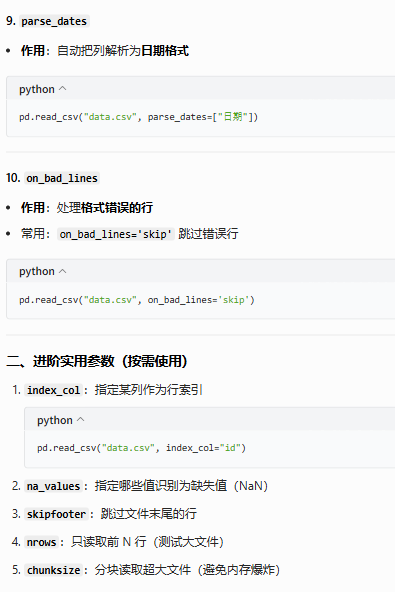
| parse_dates | 自动解析日期列 | ['日期'] / True |
⭐⭐⭐⭐ |
| date_format | 日期格式 | '%Y-%m-%d' |
⭐⭐⭐ |
| thousands | 千分位分隔符 | ',' |
⭐⭐⭐ |
| decimal | 小数点符号 | '.' |
⭐⭐ |
| skip_blank_lines | 跳过空行 | True |
⭐⭐⭐ |
| low_memory | 低内存模式 | False(避免类型警告) |
⭐⭐⭐ |
| on_bad_lines | 遇到错误行怎么处理 | 'skip' / 'warn' |
⭐⭐⭐ |
| converters | 对列做自定义转换 | {'成绩':lambda x:x*10} |
⭐⭐⭐ |
| comment | 跳过以某字符开头的行 | '#' |
⭐⭐ |
| compression | 自动解压 | 'gzip' / 'zip' |
⭐⭐ |
| iterator | 迭代读取大文件 | True |
⭐⭐ |
| chunksize | 分块读取大小 | 10000 |
⭐⭐ |
4.1.2.2 示例
注意:
①csv是有编码格式的,默认是utf8的,需根据文件编码格式适配读取编码
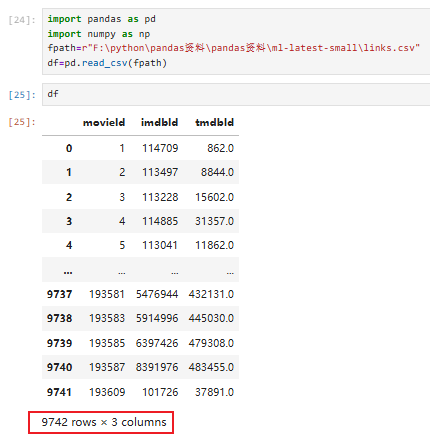
给出行列统计
②在直接使用pandas进行csv读取时,有可能会产生错误,那么可以先将文件打开,然后再读取内容【⭐】
简单读取
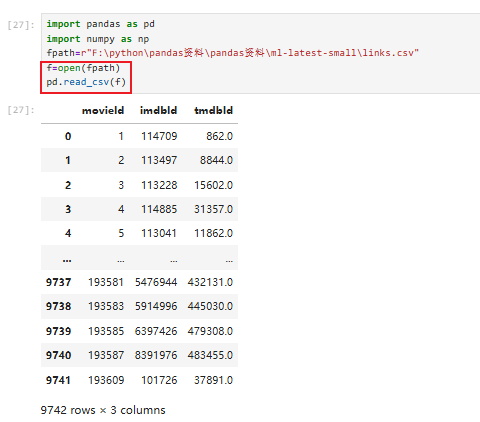
指定列读取:注意列名的一致性,有可能会有看不见空格导致匹配错误
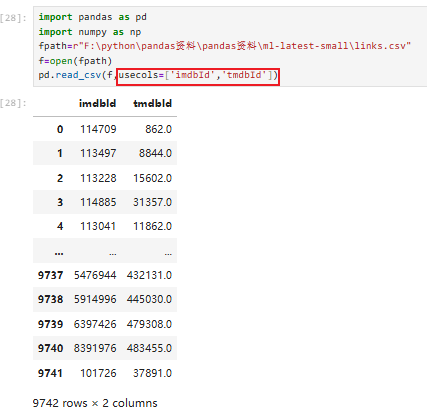
指定表头
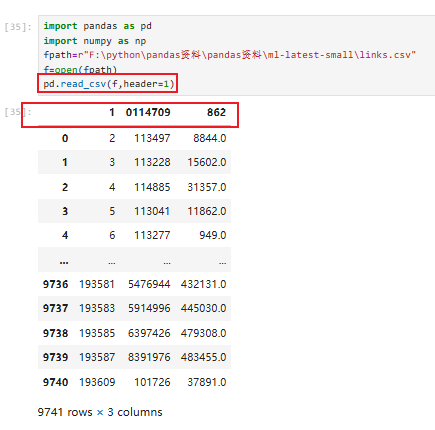
自定义表头
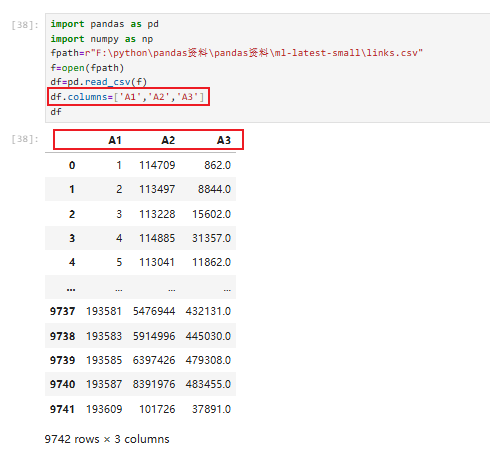
4.2 保存文件

4.2.1保存为csv文件(pdata.to_csv)
4.2.1.1 说明


参数用法:
| 参数名 | 作用 | 默认值 | 常用写法 |
|---|---|---|---|
| path_or_buf | 保存文件路径(必填) | None | "result.csv" |
| sep | 字段分隔符 | , |
sep="," / sep="\t" |
| na_rep | 缺失值填充为什么 | "" |
na_rep="NaN" |
| float_format | 浮点数格式 | None | float_format="%.2f" |
| columns | 只保存指定列 | None | columns=["姓名","成绩"] |
| header | 是否保存列名 | True | header=False |
| index | 是否保存行索引(最常用) | True | index=False(不保存行号) |
| index_label | 行索引的列名 | None | 几乎不用 |
| mode | 写入模式 | w |
w覆盖 / a追加 |
| encoding | 文件编码 | None | encoding="utf-8" / "gbk" |
| date_format | 日期格式 | None | "%Y-%m-%d %H:%M:%S" |
| compression | 压缩 | infer | 几乎不用 |
| quoting | 引号规则 | None | 几乎不用 |
| chunksize | 分块写入 | None | 大文件才用 |
| decimal | 小数点符号 | . |
几乎不用 |
4.2.1.2 示例
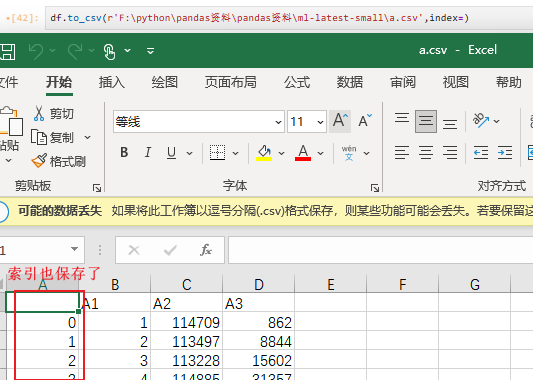
没有索引了
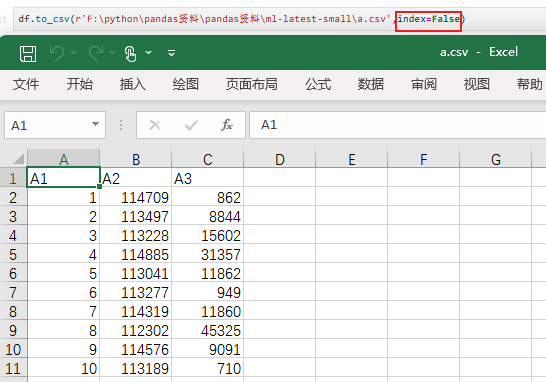
保存指定列
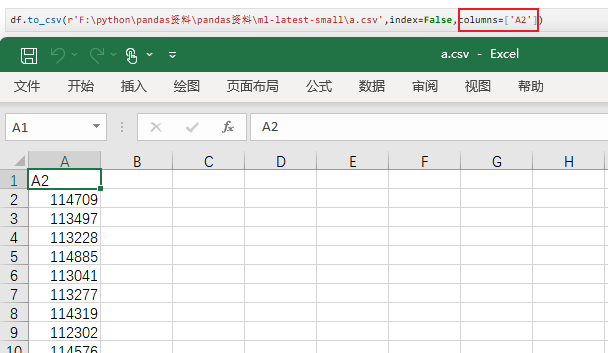
4.2.2 保存为excel文件(pdata.to_excel)
和to_csv类似
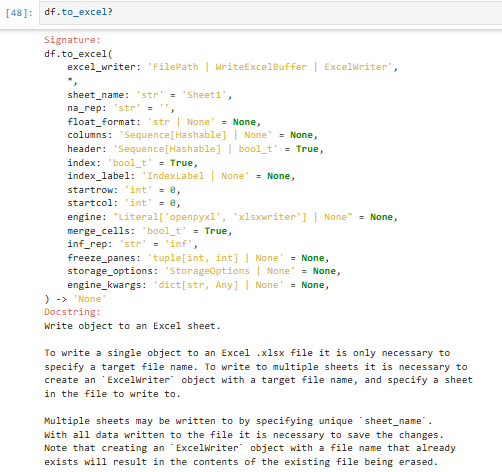

| 参数名 | 作用 | 默认值 | 常用写法 |
|---|---|---|---|
| excel_writer | 保存路径 / 文件对象 | 无 | "输出.xlsx" |
| sheet_name | 工作表名称 | Sheet1 |
"成绩表" |
| na_rep | 缺失值填充 | "" |
na_rep="缺失" |
| float_format | 浮点数保留小数 | None | float_format="%.2f" |
| columns | 只保存指定列 | None | columns=["姓名","年龄"] |
| header | 是否保存列名 | True | header=False |
| index | 是否保存行索引(最常用) | True | index=False |
| index_label | 行索引的列名 | None | 几乎不用 |
| startrow | 从第几行开始写入 | 0 | startrow=1 |
| startcol | 从第几列开始写入 | 0 | startcol=2 |
| engine | 写入引擎 | None | engine="openpyxl" |
| merge_cells | 是否合并单元格 | True | 一般不动 |
| inf_rep | 无穷大表示 | inf |
极少用 |
| freeze_panes | 冻结窗格 | None | freeze_panes=(1,0) |
| storage_options | 云存储配置 | None | 不用 |
5 缺失值处理
缺省值(没有值):数据集中数值为空的值, pandas使用Nan/NaT表示
空值(有值,值为空字符串):''
区别:pandas导入后,缺失值是Nan,空值是空字符串,两者不同
5.1 缺失值的产生(NaN->None)
①数据集本身是不规范的,某些字段没有统计上来,导致统计不全,就会算作缺失数据
②因为数据记录的某些原因,一些字段的数据本身就是不存在的
③使用爬虫抓取的时候,有些站点数据也是不全的,抓取就是空的,认定为缺失值
示例(填充NaN->None):
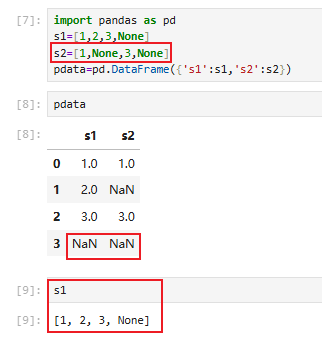
5.2 缺失值判断
判断方法:
法一:直接用pd:
pd.isnull():(找空值)缺省值对应的值为True,返回值为Boolean的Series或者DataFrame对象
pd.notnull():(找非空值)缺省值对应的值为False,返回值为Boolean的Series或者DataFrame对象
法二:用对象:
pdata.isnull()/pdata.notnull():同上
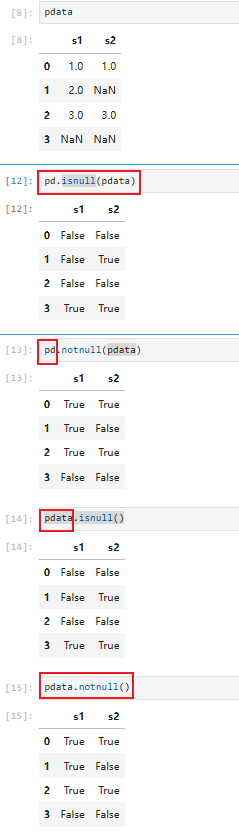
5.3 判断是否有缺失值
pd.notnull与np.all结合使用
pd.notnull只能给出布尔索引,用np.all来做总的判识
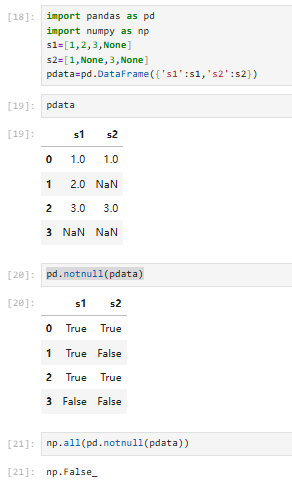
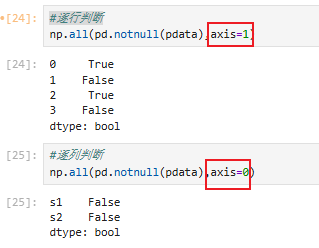
不全为真,有假(有缺失值)
指定行/列判识
5.4 缺失值处理(过滤、删除、填充)
①过滤缺省值(按行列)
②删除缺省值(按行列)
③填充值,填充值方式:
插入均值,中位数,最大值,最小值等
插入特殊值
插入前(后)值:向前填充和向后填充
5.5 缺失值过滤(索引过滤)
数据:某两只股票1周收盘值,None表示当前停盘
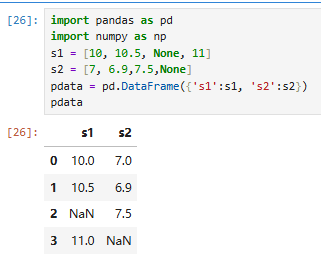
需求:获取两只股票都没有停牌的数据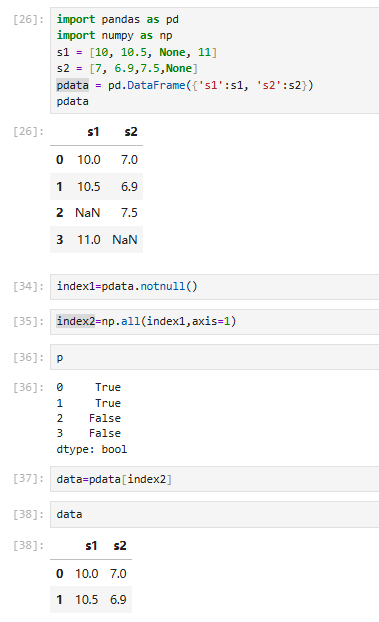
5.6 缺失值删除(pdata.dropna()【仅适用于pandas对象】)
召回(NaN/None):




参数【⭐】:

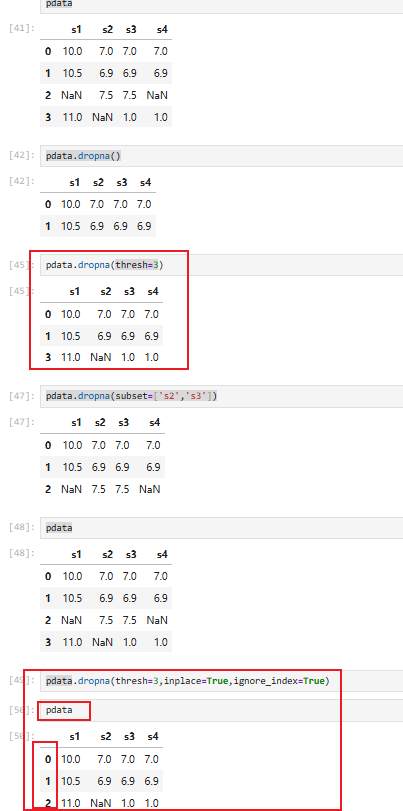
注意:是否对原始数据进行删除,是否更新索引,是否对缺失值数量进行控制
5.7 缺失值填充(pdata.fillna()【仅适用于pandas对象】)
数据处理中,可以先填充再删除



参数:

示例:
需求:
缺省值填充固定值0
使用前/后面数据填充
使用均值填充
插入均值
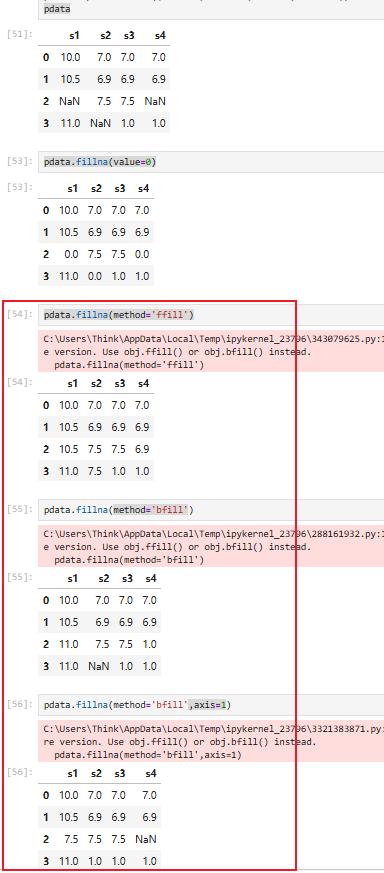
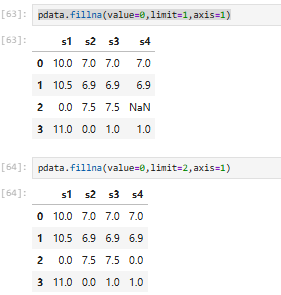
5.8 插入均值、中位数、最大值、最小值(pdata.mean/max/min/median)

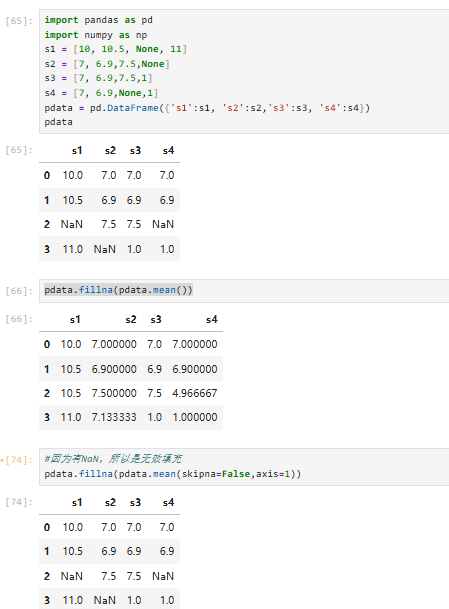
其他同理
6 获取指定数据
- 根据行列名称获取数据
- 根据指定条件获取数据
6.1 准备数据
某次考试成绩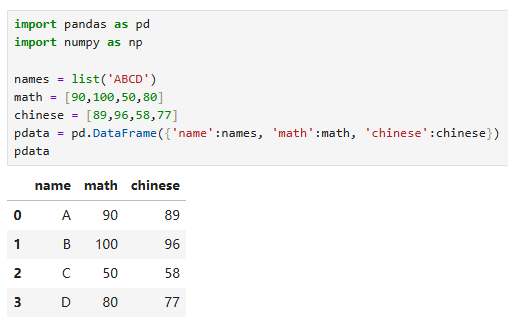
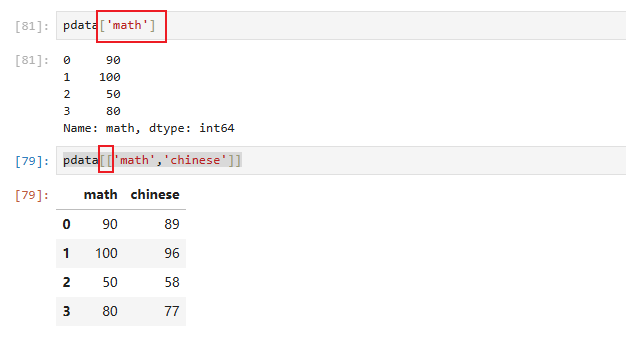
6.2 获取指定列
通过列名,获取单列/获取多列(注意括号)
6.3 根据指定条件获取数据
需求1:数学成绩大于80的所有成绩:
条件嵌套直接取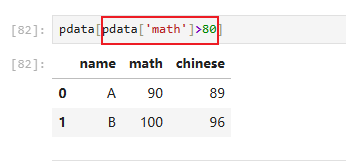
需求2:获取同学A的成绩:
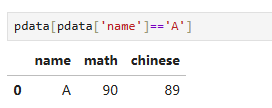
实现思路:
根据条件生成boolean索引
通过boolean索引获取数据
6.4 根据指定多个条件获取数据
需求1:获取数学语文都及格成绩
基本语法:pdata[condition1&condition2]
注意条件要加括号
注意用运算符(& |):and和or不行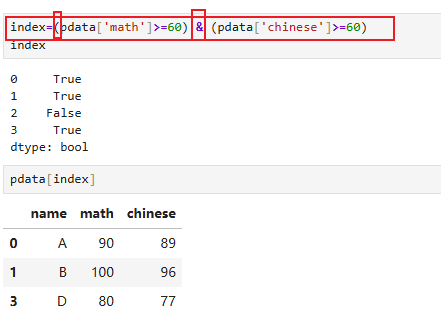
需求2:获取数学语文有一门大于等于80分
基本语法:pdata[condition1|condition2]
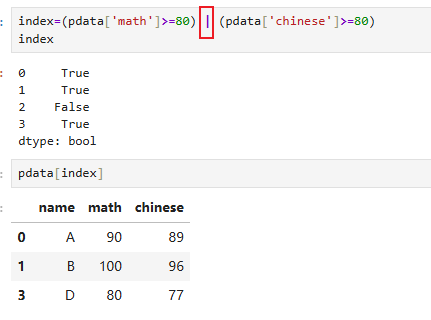
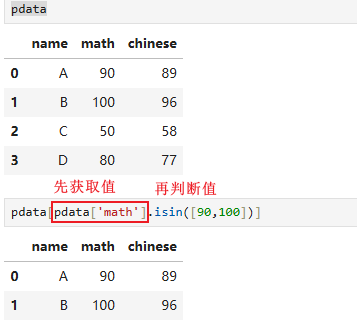
6.5 isin使用(多个值判断⭐)
当判断的条件很多的时候,用判断语句会非常长,不便于书写,此时可以采用isin进行筛选
类似于当我们指定的值在指定的集合中的时候,就判断有
多个值判断: pdata.isin(values),返回boolean索引
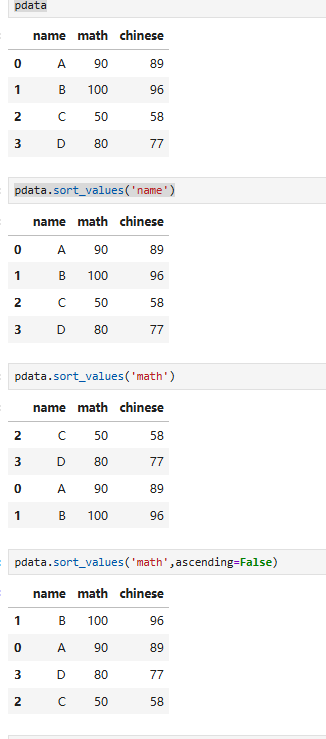
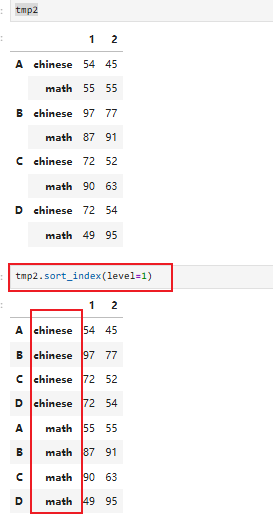
6.6 数据的排序(根据索引/根据值【⭐】)
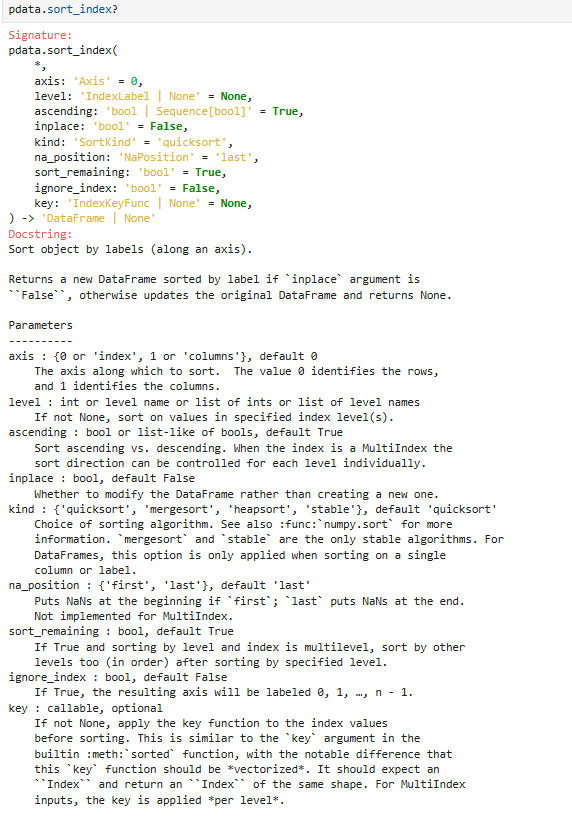
排序方式1:根据索引排序
pdata.sort_index(axis=0,level=None,ascending=True,...)
按照 行索引 / 列索引 的大小 / 字母顺序,给 DataFrame 排序
- 不是按数据值排序
- 是按行号、列名本身排序


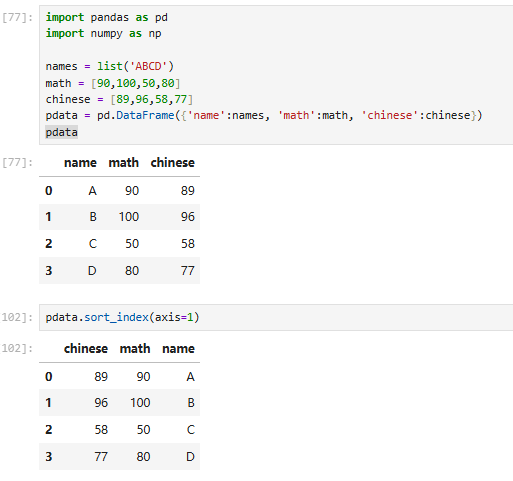
排序方式2:根据指定列内容排序
pdata.sort_values(by,axis=0,ascending=True,...)【较常使用】
按某一列 / 几列的 “数值大小” 排序

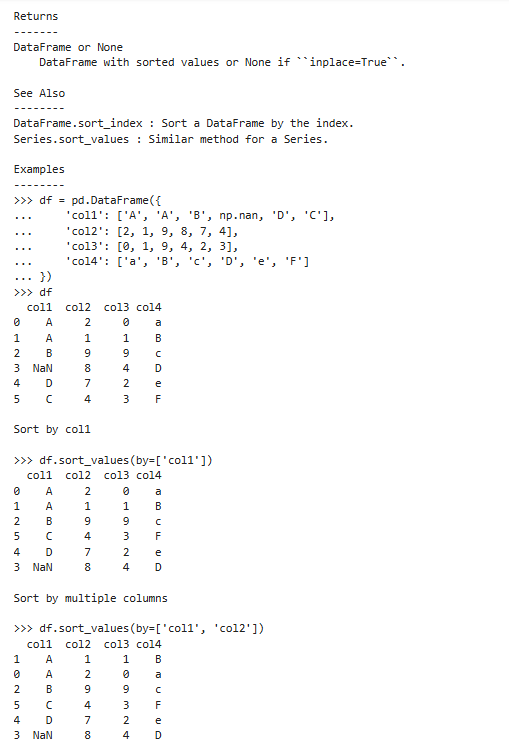
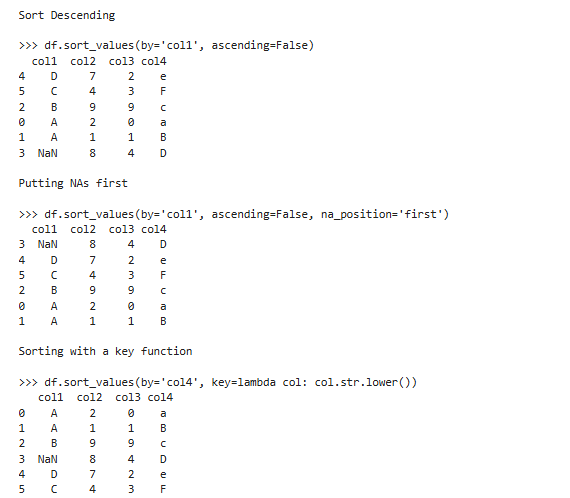
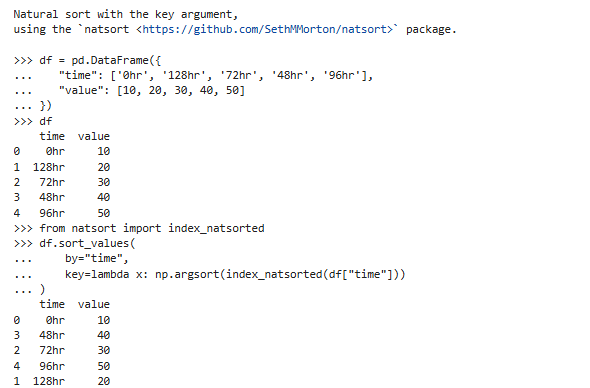
参数说明:




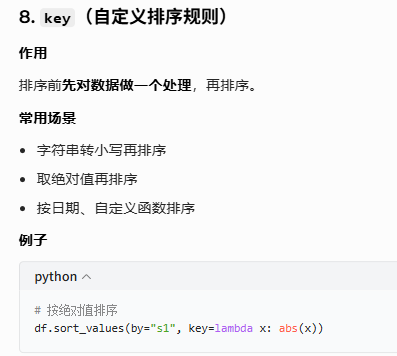
多组排序
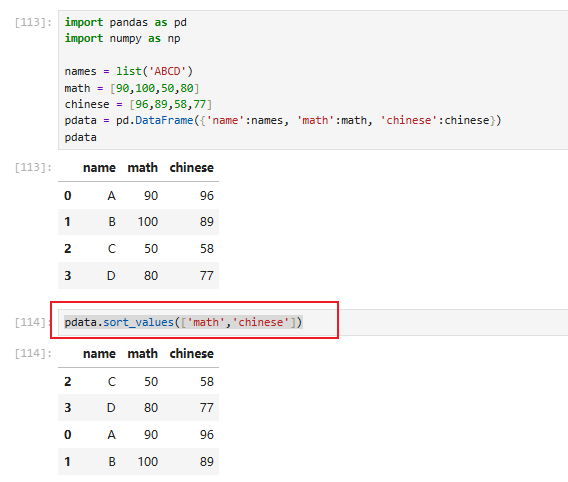
7 pandas汇总与描述性统计

7.1 准备数据
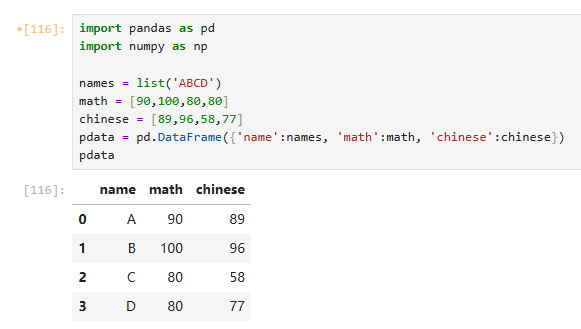
7.2 基本描述与计算
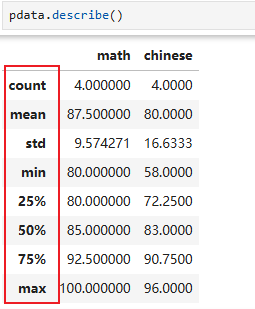
7.2.1 基本统计
数量、均值、标准差、最大值、最小值、四分位数
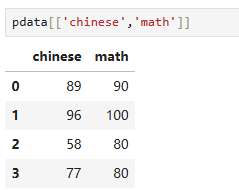
7.2.2 理解axis
取两列
注意做统计的时候不能有字符串掺杂在里面,只能是纯数据的统计
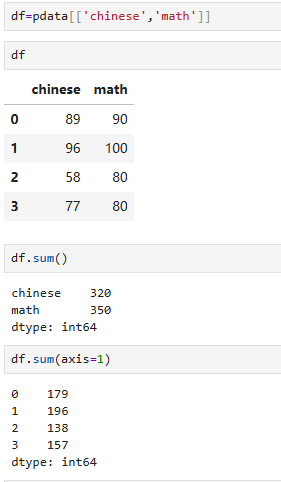
按列统计、按行统计
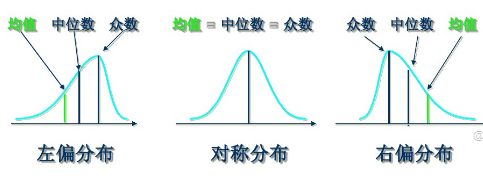
7.2.3 偏度(数据的不对称程度)
Skewness=0,分布形态与正态分布偏度相同
Skewness>0,正偏差数值较大,为正偏或右偏,长尾巴拖在右边,右侧数据离散程度更强
Skewness<0,负偏差数值较大,为负偏或左偏,长尾巴拖在左边,左侧数据离散程度更强
Skewness绝对值越大,表明数据分布越不对称,偏斜程度大
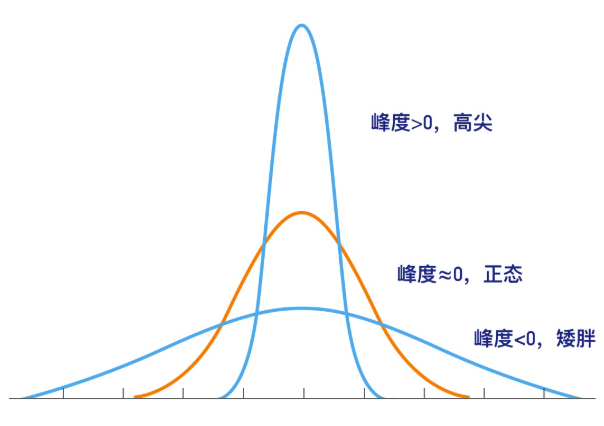
7.2.4 峰度(数据分布顶的尖锐程度)
Kurtosis=0,与正态分布的陡缓程度相同
Kurtosis>0,比正态分布的高峰更加陡峭-尖顶峰
Kurtosis<0,比正态分布的高峰来得平缓-平顶峰
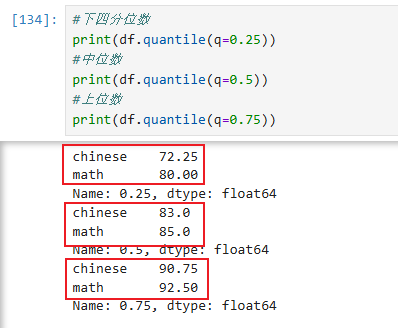
7.2.5 分位数(下四分位数、中位数、上四分位数)

示例:
8 索引/多级索引
重置索引
索引变换
多级索引
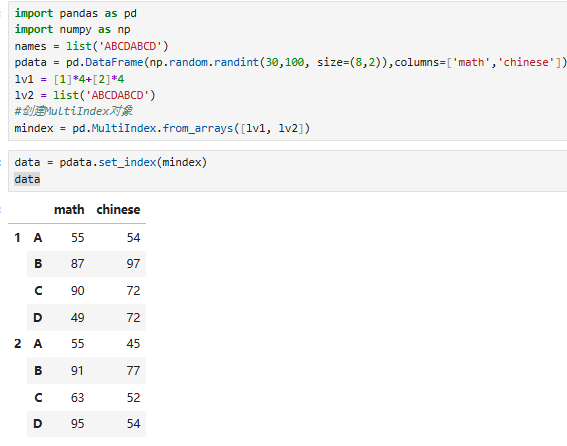
8.1 准备数据
注意数据构造的写法
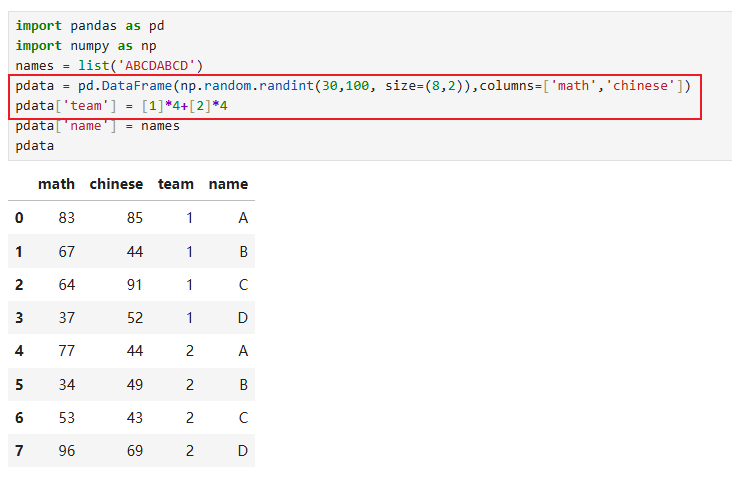
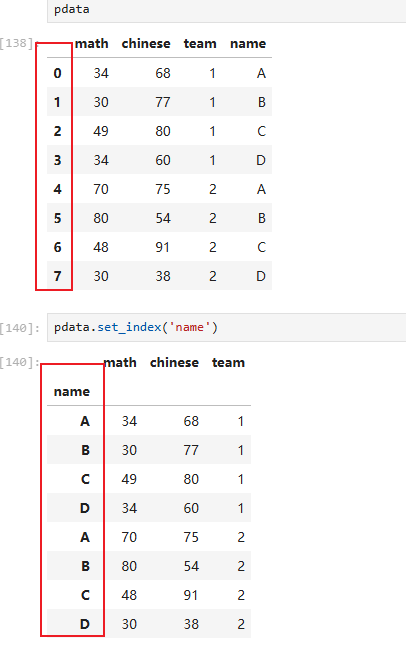
8.2 设置/重置索引(pdata.set_index())
获取name为A的所有数据
之前的方法是:pdata[pdata['name']=='A']
第二种方式采用索引:
将需要检索的字段设置为索引,然后利用索引进行检索即可
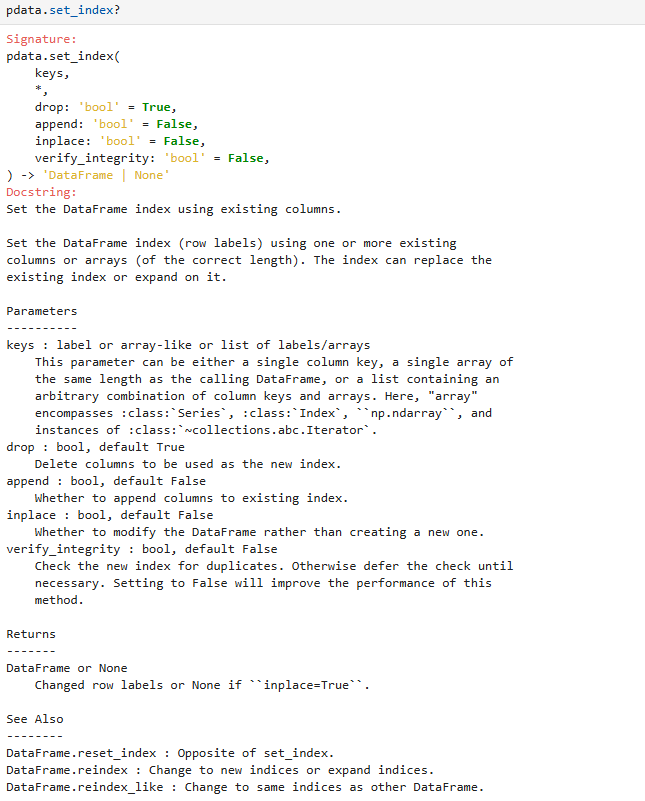
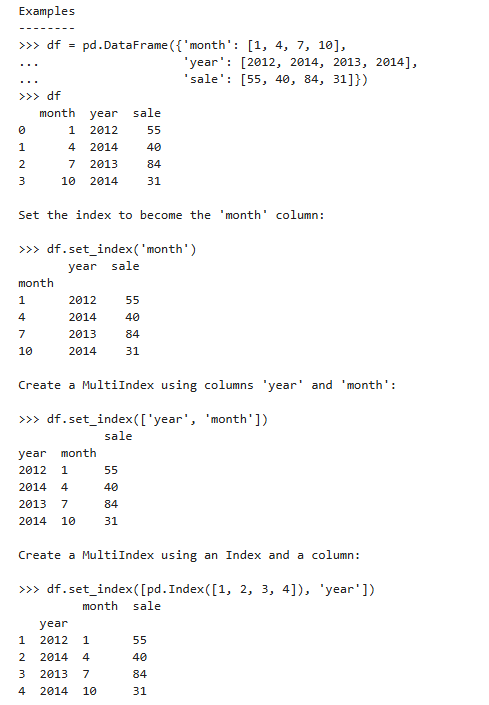
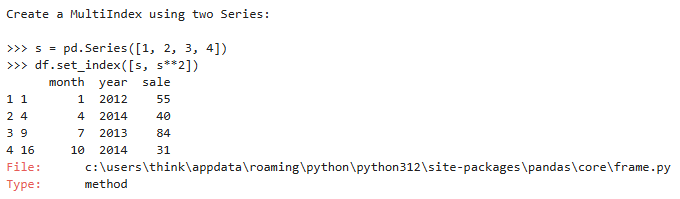
参数说明:
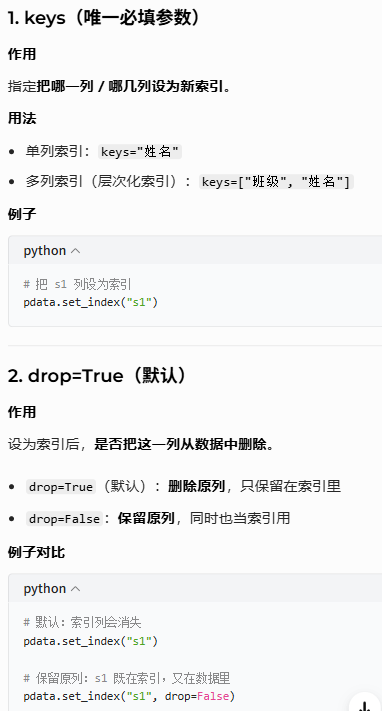

示例:
索引位
获取name为A的所有数据
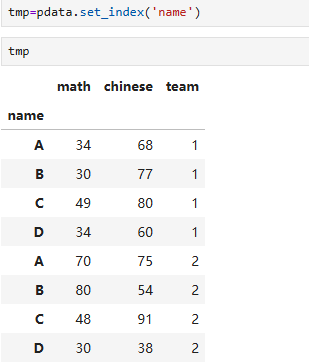
直接找会有问题
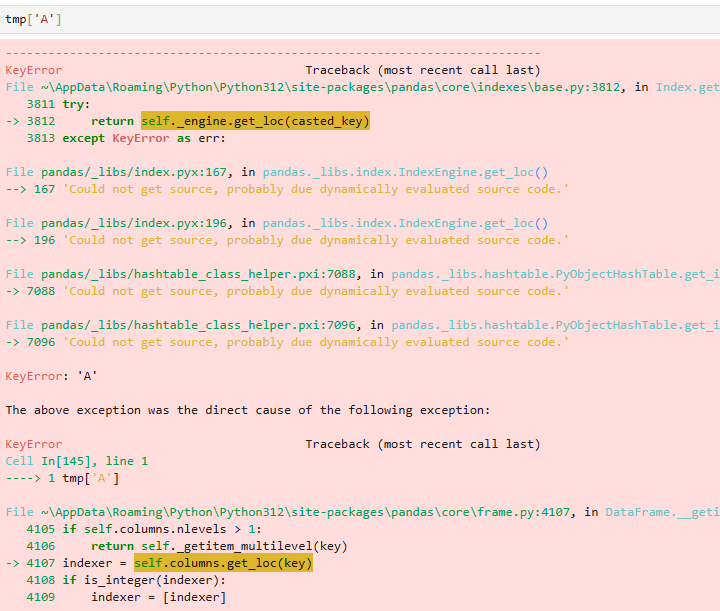
DataFrame要用loc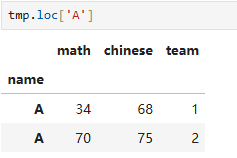
8.3 多级索引(pd.MultiIndex.from_arrays())
需求:通过索引获取指定学期数据
知识点:设置多级索引:
#根据array生成索引

注意:输入的只能是多个列表组成的数组,不可以是dataframe
pd.MultiIndex.from_arrays(arrays, sortorder=None, names=None)
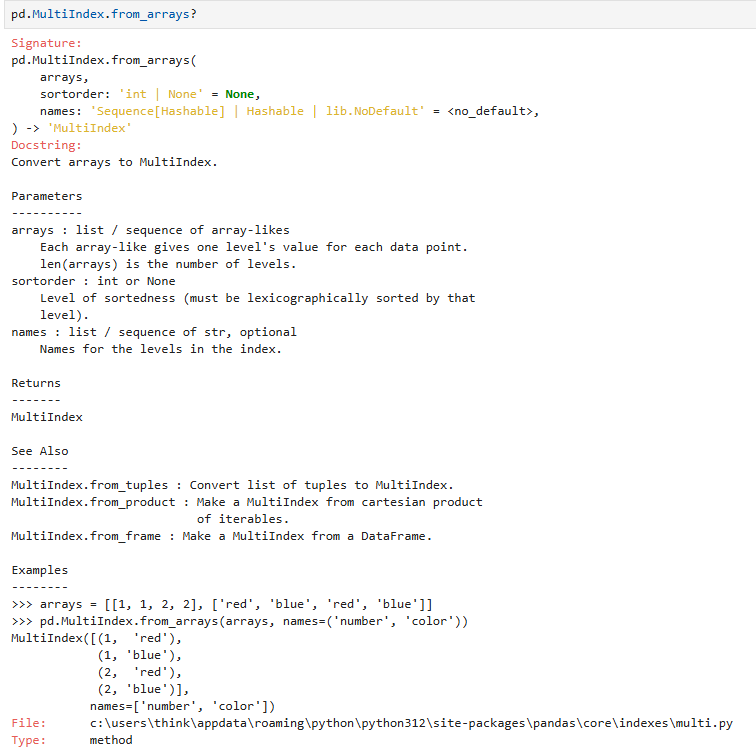
参数说明:
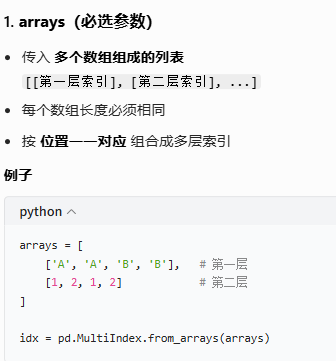
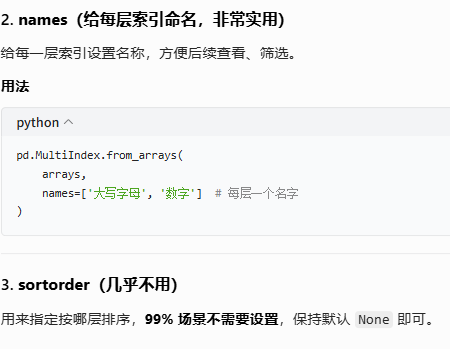

示例:
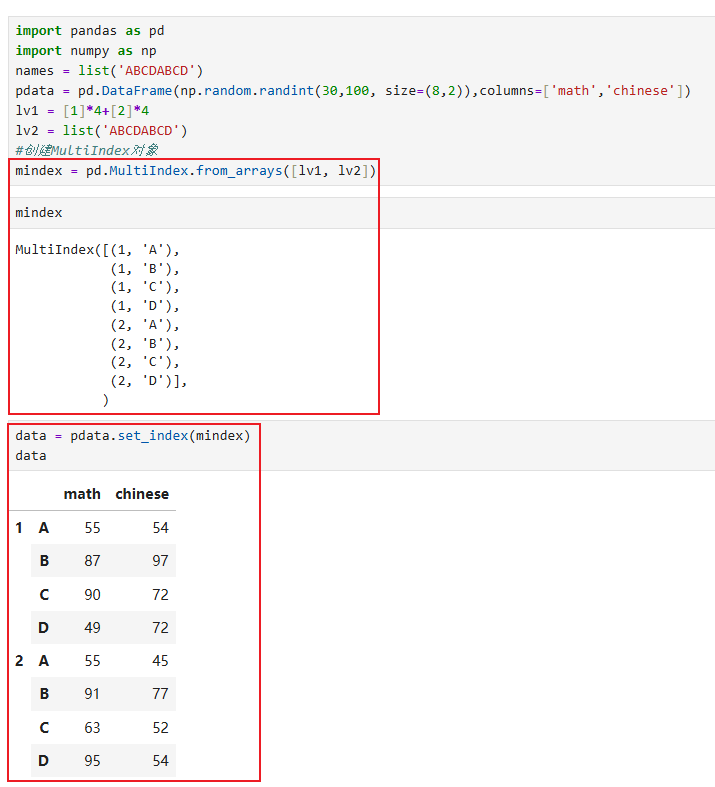
获取第一学期A同学的所有成绩
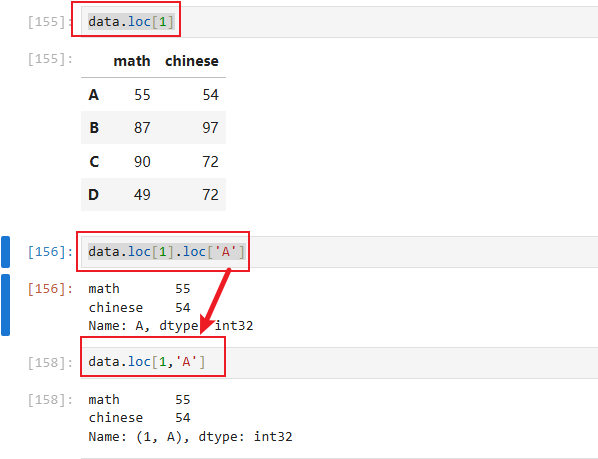
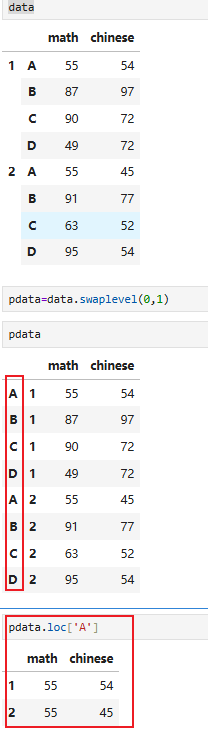
8.4 通过多级索引取值(多级索引有层级之分)
需求:
获取第一学期数据(同上)
获取第一学期A同学数据(同上)
获取A同学所有数据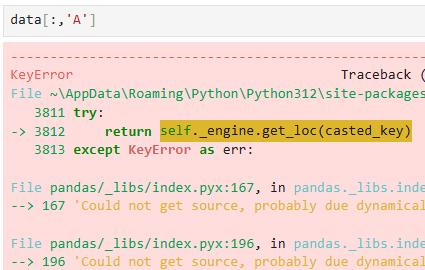
用:不可以
所以需要将索引进行交换⬇️
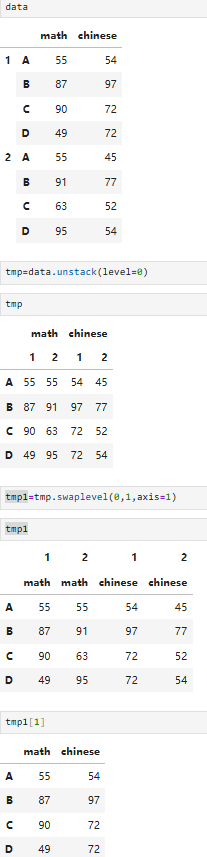
8.5 索引交换(swaplevel)
交换多层索引(行 / 列)中两层的位置
- 只能交换两层
- 不会改变数据,只改变索引层级顺序
注意:它只能对 MultiIndex(多层索引)生效,不管是行索引(axis=0)还是列索引(axis=1)
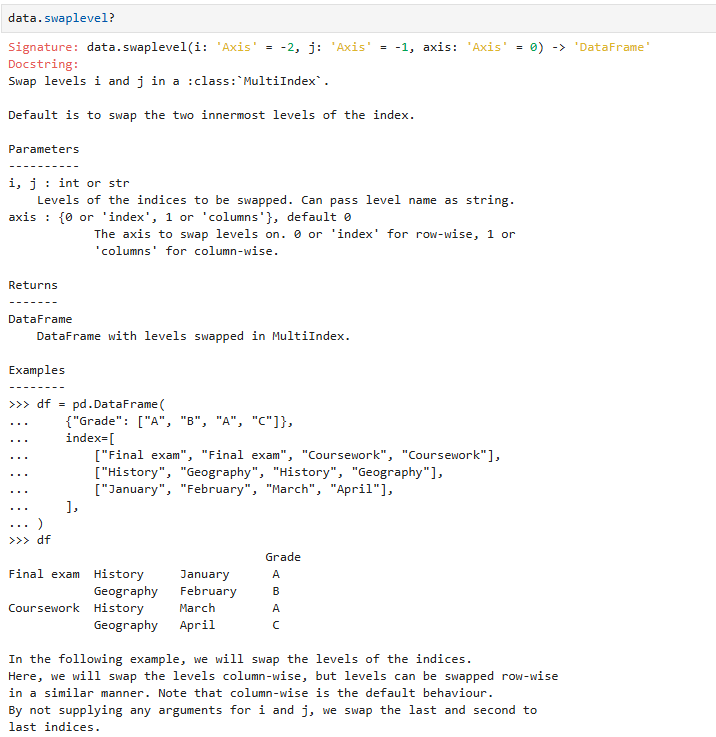
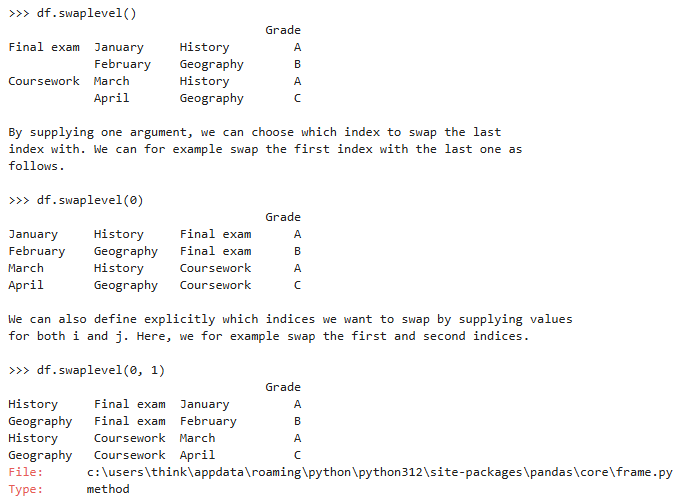
参数设置:

示例:
8.6 行列变换(stack/unstack)
将行索引变成列标签/将列标签变成行索引
数据准备:行索引是多级索引
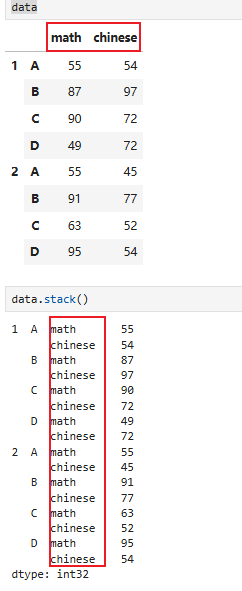
8.6.1 pdata.stack(列旋转为行)
pdata.stack(level=-1, dropna=True):将列“旋转”为行
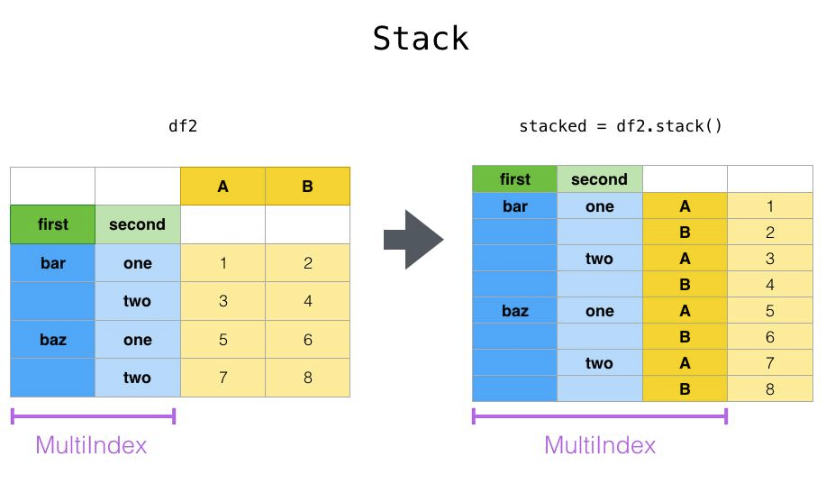
把列(columns)的层级,“搬到” 行索引(index)里去宽表 → 长表,列变少、行变多。
- 单层列 → 变成Series
- 多层列(MultiIndex columns)→ 行索引变成MultiIndex
将列的标签打成行的形式
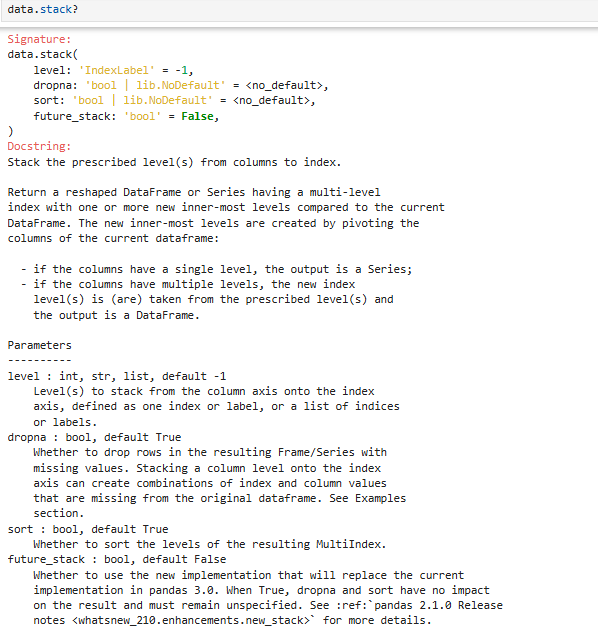

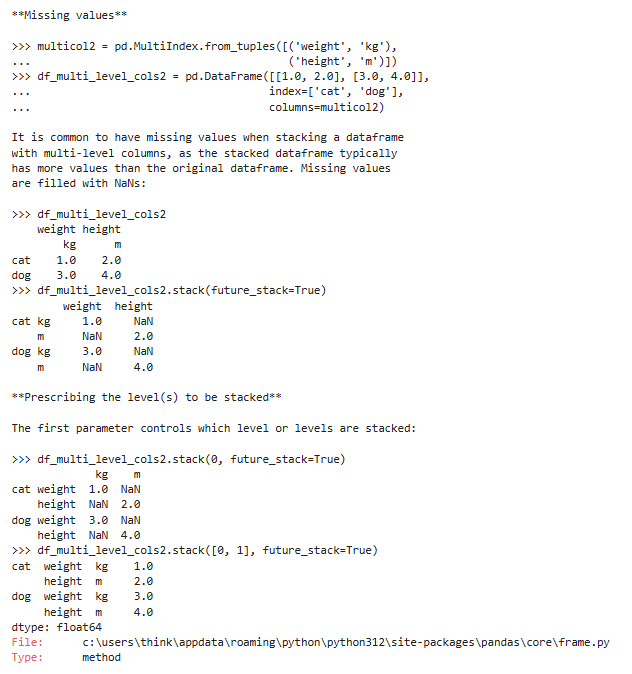
参数说明:

示例:
8.6.2 pdata.unstack(行旋转为列)
stack 的逆操作:
stack:列 → 行(宽 → 长)unstack:行 → 列(长 → 宽)
要求:行索引必须是 MultiIndex(多层索引),否则会报错。
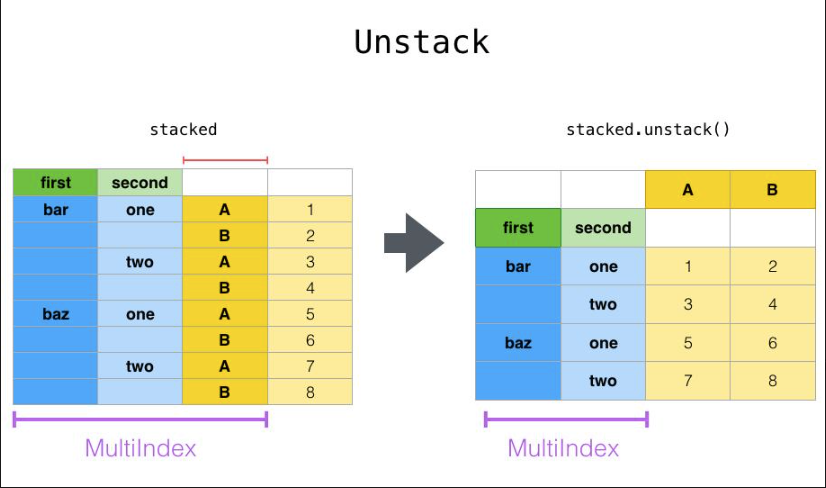
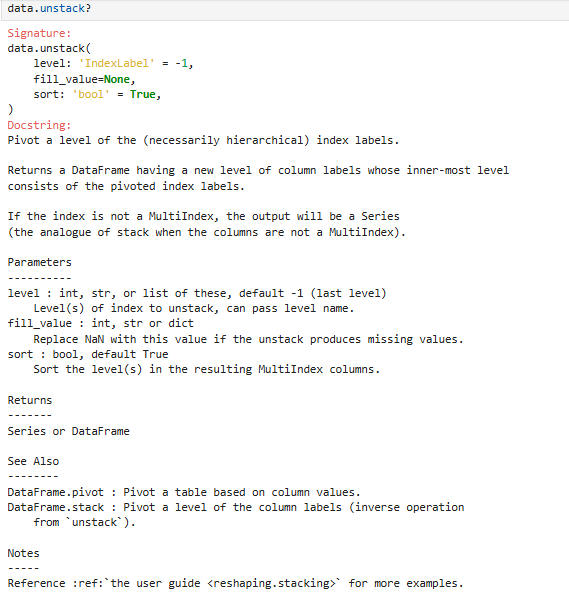

参数说明:

示例
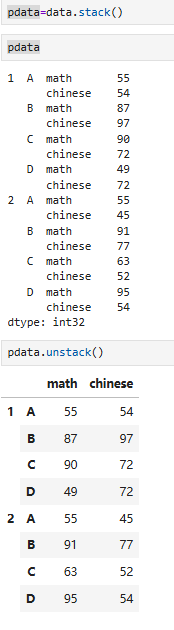
需求:
将学期转到列
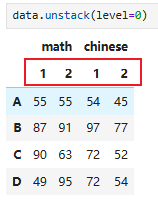
获取第一学期所有学生数学成绩
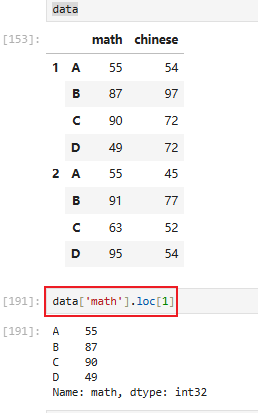
获取第一学期数据
排序
9 时间处理与时间序列
时间相关分析
- 日统计:日活、日销售额
- 月统计:月活、月销售额
- 用户留存
- 同比
- 环比
- 金融分析、股票分析。。。
时间是数据分析重要维度,pandas中时间主要知识点:
- 时间戳
- 周期
- 时间间隔
- 时间索引
- 时间滑动窗口
9.1 时间戳(pd.Timestamp-时间串)
时间处理中常见的对象;
时间戳方法:
pd.Timestamp(ts_input=<object object at 0x00000258D4E907F0>,freq=None, tz=None,...)
详情见说明案例
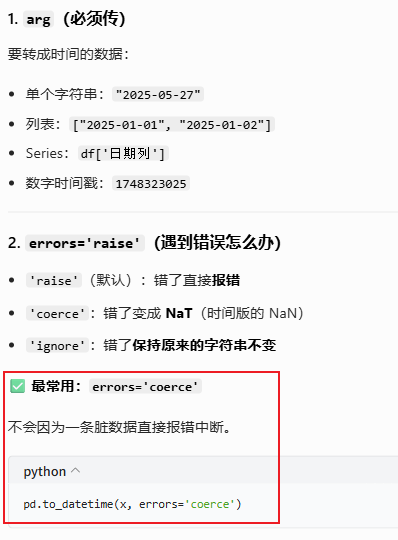
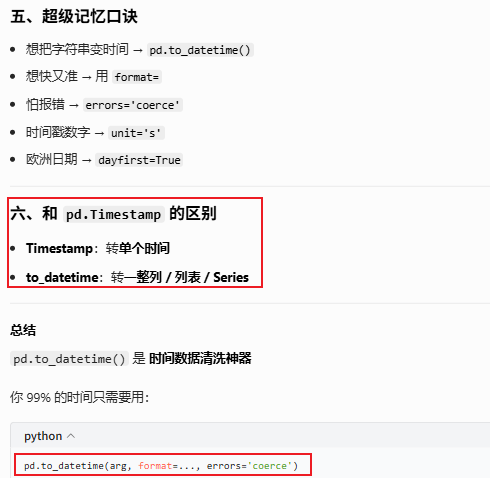
pd.to_datetime(arg,errors='raise', dayfirst=False,...)
想表示一个时间点 → Timestamp
想表示一段时间 → Timedelta
想把字符串转时间 → pd.to_datetime()
9.1.1 pd.Timestamp(创建一个 “精确时间点”)
它是 pandas 时间序列的最小单位。


参数说明:

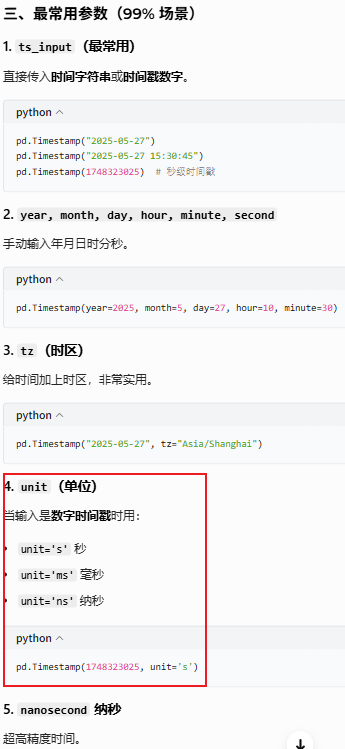
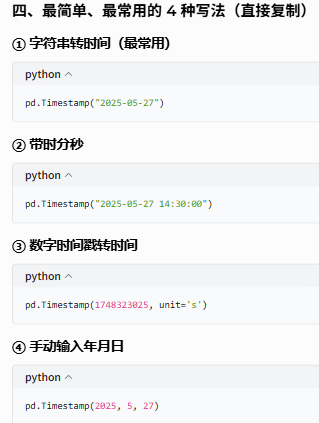
示例:
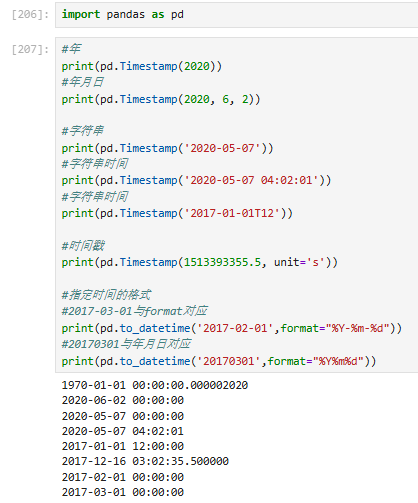
一些方法(在时间对象后.即可加载,可自行测试):
![]()
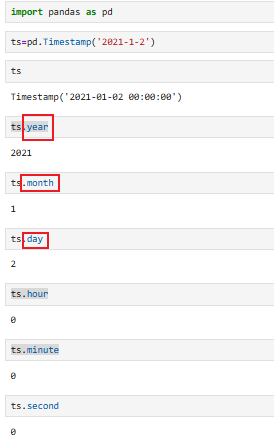
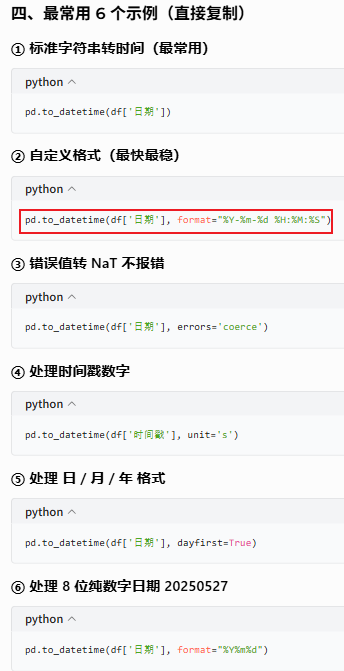
9.1.2 pd.to_datetime(转换成pandas标准时间【⭐】)
把字符串、数字、列表、Series、字典 → 转换成 pandas 标准时间(Timestamp 类型)
- 输入:
"2025-01-01"、20250527、1748323025、'01/05/2025' - 输出:
Timestamp('2025-01-01 00:00:00')
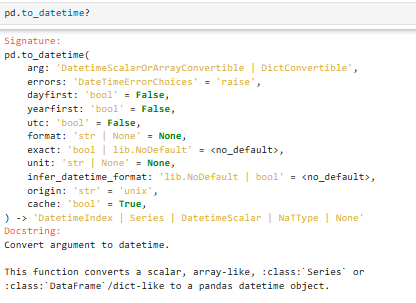
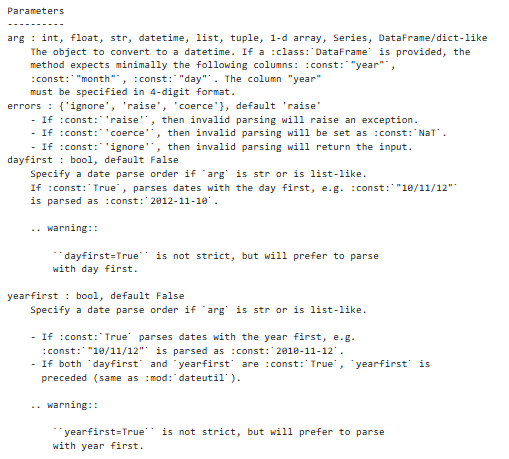
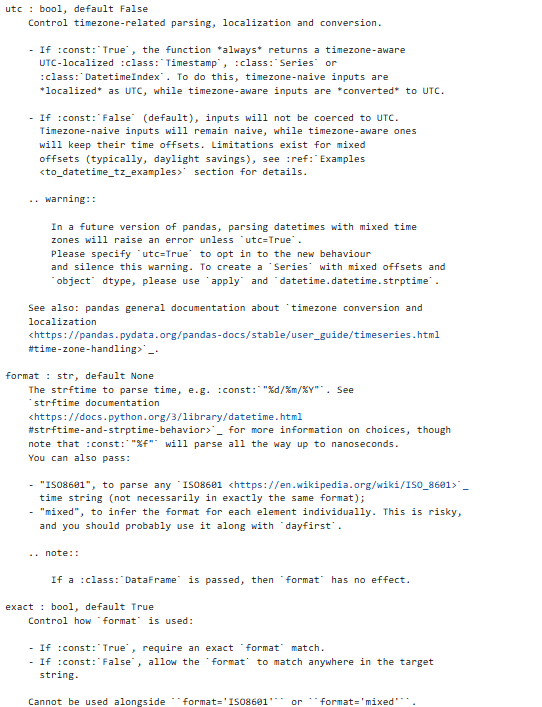

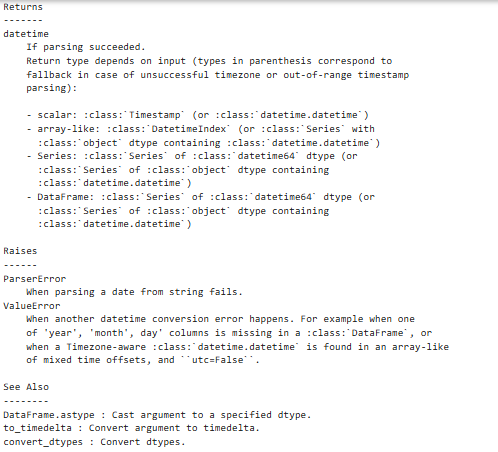
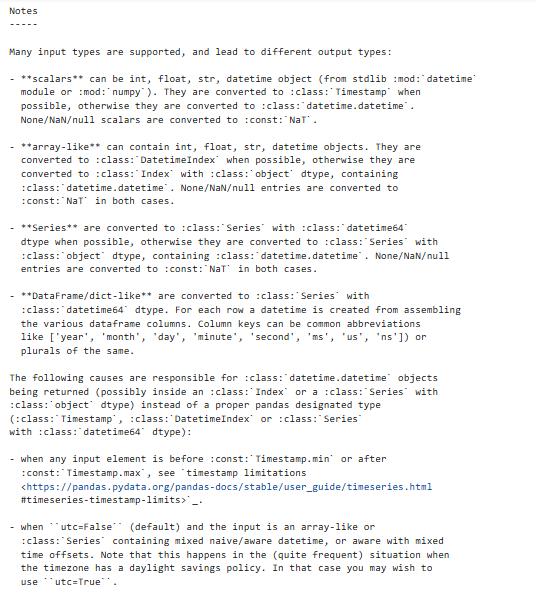



参数说明:


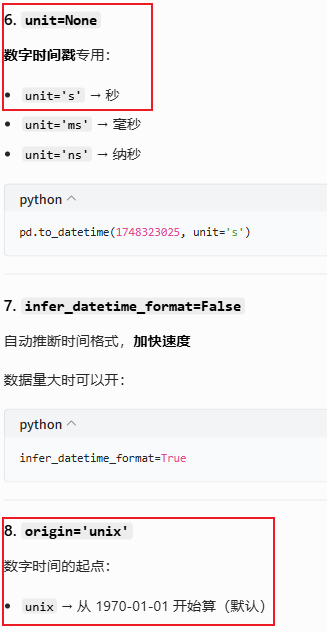
【注意】
示例:
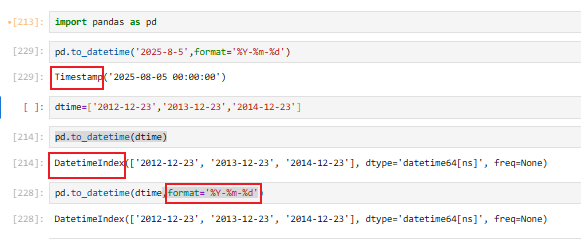
注意格式指定时的大小写以及与时间格式匹配的问题:Y m d H M S
注意单个是Timestamp格式的数据,而多个则是DatetimeIndex的格式
9.2 时间索引(pd.date_range:生成时间周期)
pd.date_range(start=None,end=None,periods=None,freq=None,tz=None, ... **kwargs)
生成固定频率的时间索引 DatetimeIndex,常用于时间序列、补全日期、重采样
官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.date_range.html
(https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.date_range.html)

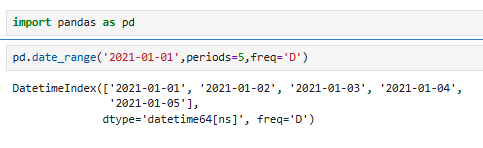
freq的主要参数:
(https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases)

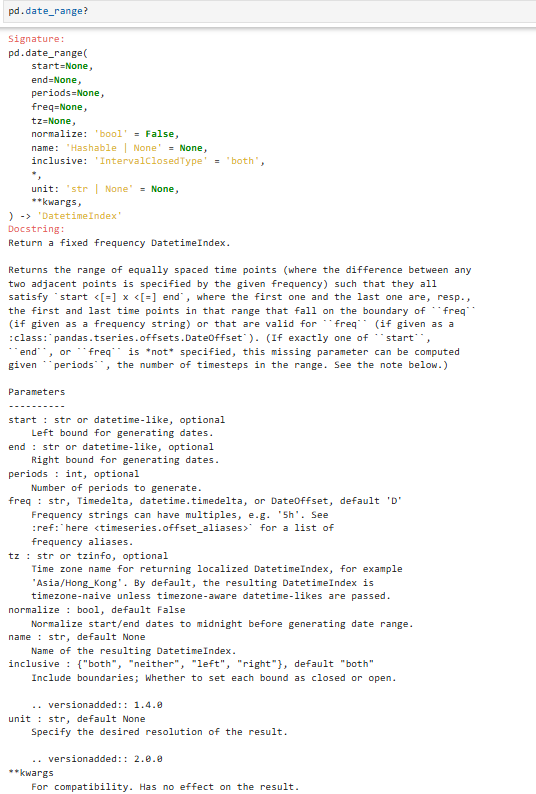
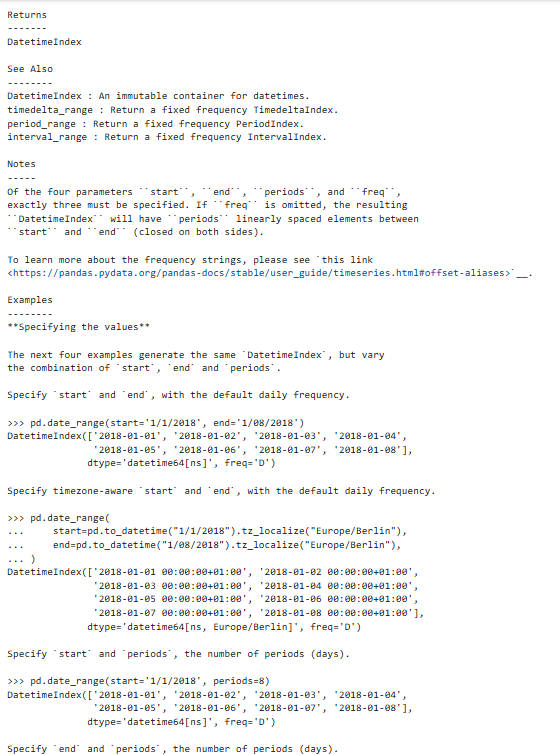

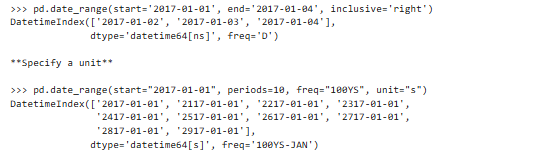
参数说明(开始时间和周期(多少个)必须要有):
periods是个数
freq是设置的时间最小单位

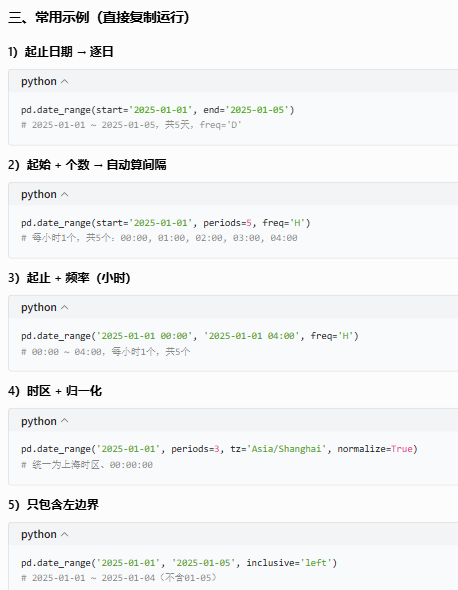
示例:
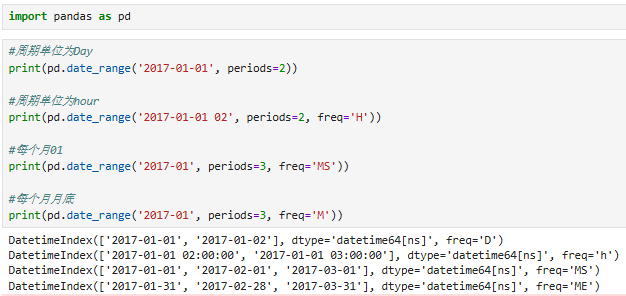
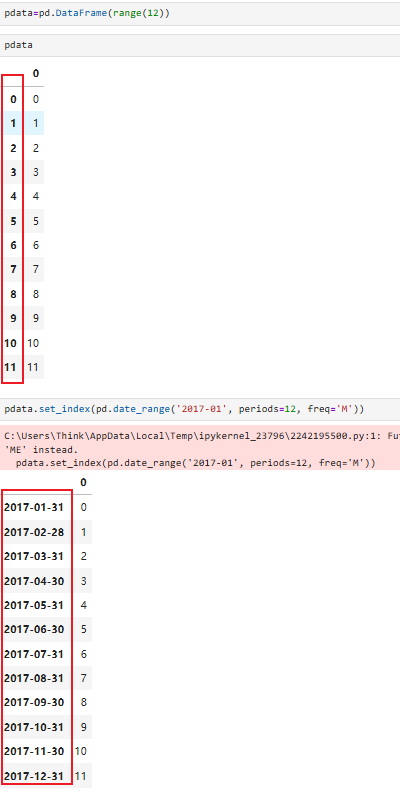
作用:用时间作为数据的索引
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)