
【课程作业1】Python 零基础实战:用 Playwright 打造智能招聘数据爬虫
【课程作业1】🚀 Python 零基础实战:用 Playwright 打造智能招聘数据爬虫
前言
如果你懂一点点 Python,又觉得传统的 Requests 爬虫经常被网站拦截、遇到各种反爬机制让人头疼,那么这篇文章绝对适合你!今天我们用一种“降维打击”的方式——浏览器自动化工具 Playwright,加上数据分析神器 Pandas,写一个能自动翻页、自动去重、并且一键生成多 Sheet 表格的招聘数据爬虫。
提示:以下是本篇文章正文内容,本次实验案例目标是获取西藏拉萨的电气工程师、工程管理员、工程监理员三者的职位名称、薪资待遇、就业公司名称、工作地点及要求。该案例可供参考
🛑第一步:跑代码前的准备工作
在让 Python 帮我们干活之前,我们需要给它安装几个必要的“外挂工具包”。如果你是纯新手,请务必跟着下面这两小步走:
1.1 打开你的终端(命令行)
-
Windows 用户:按键盘上的 Win + R,输入 cmd 然后回车,打开一个黑色的窗口。
-
Mac 用户:打开电脑里的“终端 (Terminal)”应用。
1.2 安装三大核心外挂库
在黑窗口里,复制粘贴下面这行命令并回车。
(💡 贴心提示:为了防止国内下载太慢,这里直接为你加上了清华大学的加速通道!)
pip install playwright pandas openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
这三个库分别是干嘛的?
-
playwright:爬虫界的新星,负责控制真正的浏览器。
-
pandas:数据分析神器,负责把数据排版。
-
openpyxl:有了它,Python 才能顺畅地生成并保存 .xlsx 格式的 Excel 文件。
1.3. 安装浏览器内核(极其重要!)
上面那步只是装了代码库,我们还需要让 Playwright 下载它专用的浏览器。继续在黑窗口里输入下面这行命令并回车:
playwright install chromium
注意:这一步会下载几百兆的谷歌浏览器内核,请耐心等待进度条跑完。由于服务器在海外,如果下载卡住报错,你可以按 Ctrl+C 强行停止,多试几次即可。)
🛠️ 第二步:导入我们需要的“魔法武器” (导入库)
`
代码的开头是我们要用到的工具箱,每个都有特殊作用:
from playwright.sync_api import sync_playwright # 核心大脑:负责控制真正的浏览器,模拟真人点击
import pandas as pd # 数据管家:大名鼎鼎的 Pandas,负责把抓到的数据排版并保存成高大上的 Excel
import time # 怀表:负责控制程序的节奏,让它学会“等一等”
import random # 骰子:配合 time 使用,生成随机的等待时间,防止被识别为机器人
import os # 导航员:帮你自动识别电脑的路径(比如把文件自动存到你的桌面上)
🎯 第三步:建立“关键词矩阵” (配置分类规则)
在这个脚本中,我们没有用死板的单一搜索,而是建立了一个字典 categories_config。
它的功能是:
告诉爬虫去搜哪个大词(比如:“电气”)。
定下严格的过滤规则(比如:标题必须包含“机电”、“PLC”、“调试”等同义词中的任意一个)。这样就能把招聘网站强塞给我们的无关广告和擦边职位统统过滤掉,保证数据的纯净度。
🤖 第四步:穿上隐身衣,启动浏览器
browser = p.chromium.launch(headless=False)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64)..."
)
功能解析:
- headless=False:这句代码会让浏览器真正地在你屏幕上弹出来。这对新手非常友好,你能亲眼看到机器人在干嘛。如果有滑块验证码,你还能赶紧用鼠标帮它滑一下!
- user_agent(用户代理):这就像给机器人穿上了一件人类的外衣,告诉网站:“我是一个正常的 Windows 电脑上的 Chrome 浏览器,别拦截我!”
⚙️ 第五步:核心逻辑——自动翻页与精准捕获
这是整个爬虫最精彩的部分,嵌套了两个循环:
5.1 自动翻页是怎么实现的?
for page_num in range(1, 4): # 让爬虫自动遍历第 1 到 3 页
url = f"https://sou.zhaopin.com/?jl=854&kw={search_word}&p={page_num}"
我们观察到网站的网址规律:p=1 就是第一页,p=2 就是第二页。所以我们用一个简单的 for 循环不断改变网址里的页码,爬虫就会乖乖地一页一页往下翻。如果发现哪一页没有数据(if not job_cards:),它还会聪明地跳出循环,去抓下一个大类。
5.2 防反爬“休眠”机制:
wait_time = random.uniform(3.5, 6.5)
time.sleep(wait_time)
翻页后不能立刻抓取,否则100%被封锁!我们让程序随机睡上 3.5 到 6.5 秒,完美模拟人类看网页的速度。
5.3 终极去重逻辑(防重复抓取):
unique_id = f"{company}_{title}_{salary}"
if unique_id in seen_job_ids:
continue
有些岗位既属于“管理”又属于“监理”。我们把公司名+职位名+薪资拼接成一个独一无二的“身份证号”,存入一个集合(seen_job_ids)。遇到重名的,直接抛弃,保证最后生成的 Excel 里一行就是一个不重复的岗位!
📊 第六步:Pandas 展现 Excel 魔法
数据抓完后,怎么保存得漂亮?传统的 CSV 只能存一张表,这里我们用 Pandas 的高级玩法:
with pd.ExcelWriter(excel_file_path, engine='openpyxl') as writer:
for category_name, job_list in categorized_jobs.items():
df = pd.DataFrame(job_list)
df.to_excel(writer, index=False, sheet_name=category_name)
功能解析:
我们把刚才分类抓好的数据,通过 pd.ExcelWriter 写入同一个 Excel 文件中。而且,代码会根据我们的三大类名称,在 Excel 底部自动创建 3 个独立的工作表(Sheet)。
完整程序
from playwright.sync_api import sync_playwright
import pandas as pd
import time
import random
import os
def scrape_engineering_jobs():
categories_config = {
"电气工程师": {
"search_keyword": "电气", # 去掉了“拉萨”,靠底层的 jl=854 锁定
"synonyms": ["电气", "机电", "PLC", "工控", "供配电", "强弱电", "电气设计", "调试", "运维", "电力", "电工","plc","机械电子","电子工程"]
},
"工程监理员": {
"search_keyword": "监理",
"synonyms": ["监理员", "工程监理", "土建监理", "市政监理", "水电监理", "现场监理", "房建监理", "公路监理",
"监理","项目监理"]
},
"工程管理员": {
"search_keyword": "工程管理",
"synonyms": ["工程管理", "工程项目", "现场管理", "施工管理", "土建管理", "市政管理", "工程专员", "工地管理","管理"]
}
}
categorized_jobs = {
"电气工程师": [],
"工程监理员": [],
"工程管理员": []
}
seen_job_ids = set()
print("正在启动自动化浏览器...")
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
)
page = context.new_page()
for category_label, config in categories_config.items():
search_word = config["search_keyword"]
allowed_keywords = config["synonyms"]
print(f"\n🚀 正在抓取大类:【{category_label}】...")
for page_num in range(1, 4):
print(f" 📄 正在请求第 {page_num} 页数据...")
# 【核心修复】:jl=854 代表拉萨,强制网站只返回拉萨及西藏周边的数据!
url = f"https://sou.zhaopin.com/?jl=847&kw={search_word}&p={page_num}"
page.goto(url)
wait_time = random.uniform(3.5, 6.5)
time.sleep(wait_time)
job_cards = page.locator('.joblist-box__item').all()
if not job_cards:
print(f" ⚠️ 第 {page_num} 页无数据,跳出当前分类抓取。")
break
for card in job_cards:
try:
title = card.locator('.jobinfo__name').inner_text().strip()
salary = card.locator('.jobinfo__salary').inner_text().strip()
company = card.locator('.companyinfo__name').inner_text().strip()
# 【新增提取】:提取工作地点、经验、学历等综合信息
job_info = "无信息"
if card.locator('.jobinfo__other-info').count() > 0:
# 把“拉萨-城关区 | 3-5年 | 本科”这种信息提取出来并把换行替换成空格
job_info = card.locator('.jobinfo__other-info').inner_text().replace('\n', ' ').strip()
tags_locator = card.locator('.jobinfo__tag')
tags = tags_locator.inner_text().strip() if tags_locator.count() > 0 else "无标签"
unique_id = f"{company}_{title}_{salary}"
if unique_id in seen_job_ids:
continue
is_valid_job = any(keyword in title for keyword in allowed_keywords)
if is_valid_job:
seen_job_ids.add(unique_id)
categorized_jobs[category_label].append({
'职位名称': title,
'薪资水平': salary,
'公司名称': company,
'工作地点及要求': job_info, # 新增的列,让你核对城市
'福利标签': tags
})
print(f" ✅ 命中: {title} | {job_info.split(' ')[0]} | {company}")
except Exception:
continue
browser.close()
has_data = any(len(jobs) > 0 for jobs in categorized_jobs.values())
if has_data:
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
excel_file_path = os.path.join(desktop_path, "拉萨_工程类岗位分表_薪资调研.xlsx")
with pd.ExcelWriter(excel_file_path, engine='openpyxl') as writer:
for category_name, job_list in categorized_jobs.items():
if job_list:
df = pd.DataFrame(job_list)
df.to_excel(writer, index=False, sheet_name=category_name)
print(f"\n🎉 完美结束!城市已经严格锁定在拉萨。")
print(f"💾 报表已生成,路径: {excel_file_path}")
else:
print("\n❌ 未能捕获到数据,请检查网络或是否遭遇滑块验证码。")
if __name__ == '__main__':
scrape_engineering_jobs()
🎉 运行效果展示(你将看到什么?)
运行脚本后会自动弹出浏览器界面

pycharm运行窗口界面会弹出命中的职位信息
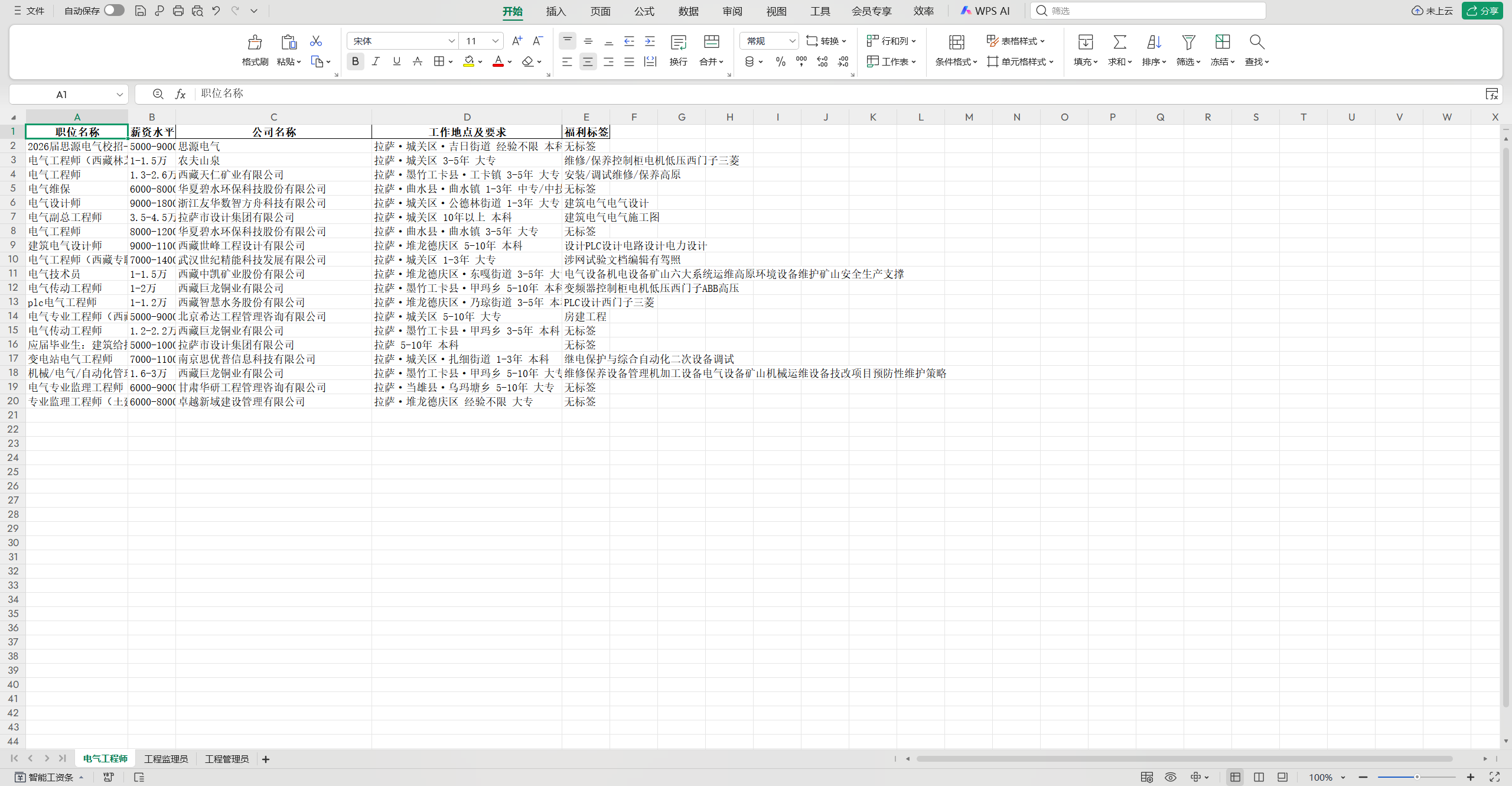
在桌面的excel文件即可看见抓取的3个职位。
💡 独家进阶小技巧:如何把代码变成你的“私人定制”?
授人以鱼不如授人以渔,拿到这段代码后,你可以使用ai工具直接修改代码,或者手动修改几个小参数,让它为你做更多的事情:
1. 怎么更换抓取城市?(解锁全国数据)
在代码第 48 行左右,有这样一个网址:
url = f"https://sou.zhaopin.com/?jl=854&kw={search_word}&p={page_num}"
这里的 jl=854 就是智联招聘系统里“拉萨”的专属城市代码。如果你想抓取其他城市怎么办?
方法极其简单: 你只需要用电脑浏览器打开智联招聘官网,手动把城市切换成你想要的城市(比如北京、上海或西安),然后随便搜个职位。
抬头看浏览器顶部的网址,你会发现网址里多了一个 jl=530(北京)或者 jl=538(上海)。
把这段代码里的 854 替换成你查到的数字,这个爬虫就瞬间变成了“北京岗位采集器”!
2. 遭遇滑块验证码怎么办?
即使我们加了随机休眠,有时候网站抽风依然会弹出验证码。不要慌!因为我们在代码里设置了 headless=False(显示浏览器界面),所以当爬虫卡住时,你只需要抓紧时间用鼠标在弹出的浏览器里手动把滑块拖过去。只要你滑过去验证成功,代码就会聪明地接着往下跑,绝不罢工。
3. 万物皆可爬(自定义关键词)
代码开头的 categories_config 字典完全是为你敞开的。今天你爬的是“电气”和“监理”,明天你完全可以把它改成 {“新媒体运营”: {“search_keyword”: “新媒体”, “synonyms”: [“小红书”, “抖音”, “内容运营”]}},这套代码的骨架对任何岗位都通用!
总结
新手学爬虫,没必要一开始就死磕复杂的网页解析和反爬逆向。用 Playwright 操控真实的浏览器,就像造了一个模仿人类上网的机器人,简单且直接。
今天我们利用 Playwright + Pandas,用不到 100 行代码就搞定了“搜索 -> 翻页 -> 智能去重 -> 分表导出 Excel”的全流程。编程的意义在于解决实际问题,希望这套轻量级的自动化模板能成为你工作中的利器!
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)