
使用 C# 高效替换 PDF 中的文本:全页、区域与正则匹配
PDF是目前应用最广泛的电子文档格式之一,因其跨平台一致性强、格式固定等优势而被广泛用于文档存储、分发和存档。在实际业务场景中,开发者常常需要通过编程方式批量修改PDF文档内容,如更新合同中的公司名称、替换日期信息、批量修正错别字等。
本文将详细介绍如何使用免费 .NET PDF 处理库,在 C# 中实现 PDF 文本的查找与替换。
🛠️ 免费库安装:Install-Package FreeSpire.PDF
⚠️ 注意:免费版本单文档仅支持处理 10 页内容,超出部分会被截断,建议使用前提前核对文档页数是否适用。
1. 核心 API 解析
免费库提供了专门用于 PDF 文本替换的 PdfTextReplacer 类,以及用于配置替换行为的 PdfTextReplaceOptions 类。这两个类是执行所有文本替换操作的基础。
主要方法和属性说明:
| 类/方法 | 说明 |
|---|---|
PdfTextReplacer(PdfPageBase) |
构造函数,基于指定页面创建文本替换器 |
ReplaceAllText(string, string) |
将页面中所有匹配的文本替换为新文本 |
ReplaceText(string, string) |
仅替换页面中首次匹配到的文本 |
Options |
获取或设置文本替换的配置选项 |
PdfTextReplaceOptions.ReplaceType |
设置替换类型(整词匹配、忽略大小写、自动适应宽度等) |
2. 常见文本替换场景及代码
2.1 替换 PDF 指定页面中的文本
以下示例演示如何替换 PDF 文档中第一页的所有指定文本:
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceTextInPage
{
class Program
{
static void Main(string[] args)
{
// 创建PdfDocument对象
PdfDocument pdf = new PdfDocument();
// 加载PDF文件
pdf.LoadFromFile("制度.pdf");
// 获取第一页
PdfPageBase page = pdf.Pages[0];
// 基于页面创建PdfTextReplacer对象
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 将页面中所有的"旧公司名"替换为"新公司名"
textReplacer.ReplaceAllText("公司", "企业");
// 保存文档
pdf.SaveToFile("文本替换.pdf");
// 释放资源
pdf.Dispose();
}
}
}
文本替换对比效果展示: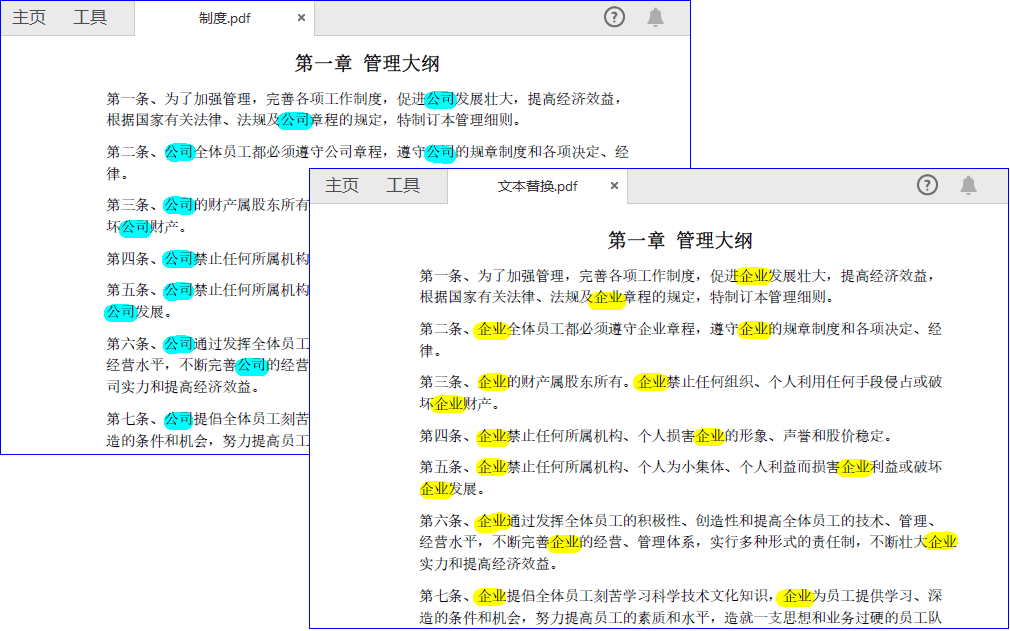
2.2 替换 PDF 所有页面中的文本
要替换整个PDF文档中所有匹配的文本,只需遍历文档的每一页,对每页分别执行替换操作即可:
// 遍历所有页面
foreach (PdfPageBase page in pdf.Pages)
{
// 创建PdfTextReplacer对象
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 执行替换
textReplacer.ReplaceAllText("旧内容", "新内容");
}
2.3 仅替换首次匹配的文本
如果只需要替换页面中第一次出现的匹配文本(后续出现保持不变),可以使用 ReplaceText 方法:
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 仅替换第一次出现的"旧内容"
textReplacer.ReplaceText("旧内容", "新内容");
2.4 批量替换多组文本
在实际业务场景中,常常需要同时替换多个不同的文本内容。使用 字典(Dictionary) 存储“原文→新文本”的映射关系,然后遍历每一页执行替换,是一种简洁高效的实现方式。
下面示例中的占位符(如 {company}、{phone}、{version})是预置在 PDF 中的标记,通过字典一次性替换为真实数据,适用于合同、报告等模板类文档的批量处理。
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
namespace BatchTextReplacer
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("测试.pdf");
// 定义待替换的文本映射表:键为原文占位符,值为新文本
Dictionary<string, string> replaceMap = new Dictionary<string, string>()
{
{"{company}","某某科技有限公司"},
{"{phone}","400-888-XXXX"},
{ "{version}", "v2.0.11" },
};
// 遍历所有页面,对每一页依次替换所有映射项
foreach (PdfPageBase page in pdf.Pages)
{
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
foreach (var item in replaceMap)
{
textReplacer.ReplaceAllText(item.Key, item.Value);
}
}
pdf.SaveToFile("批量替换.pdf");
pdf.Close();
pdf.Dispose();
}
}
}
效果预览: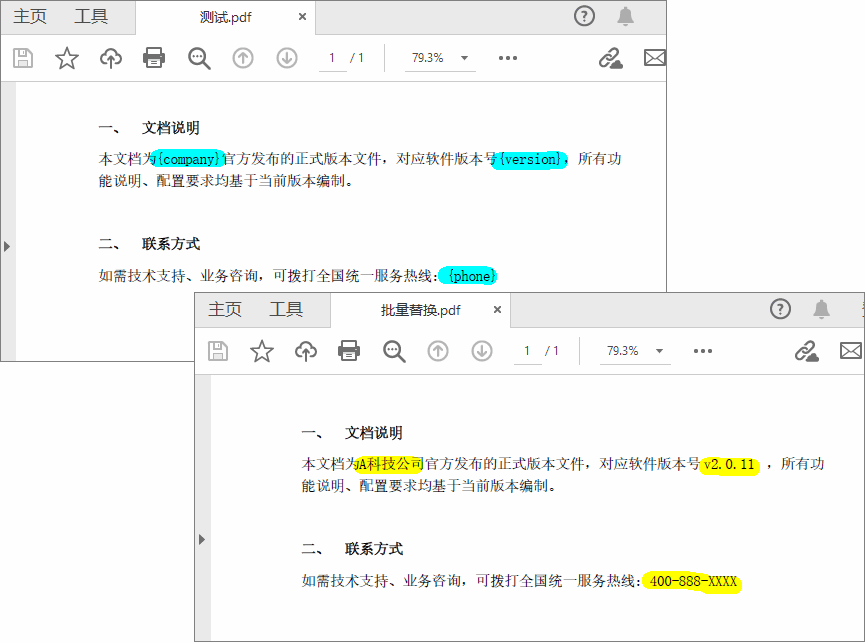
3. 高级替换选项
3.1 配置替换行为
PdfTextReplaceOptions 类提供了丰富的选项来控制文本替换的行为:
using Spire.Pdf;
using Spire.Pdf.Texts;
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("input.pdf");
PdfPageBase page = pdf.Pages[0];
// 创建PdfTextReplacer对象
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 创建并配置PdfTextReplaceOptions对象
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// 设置替换选项
textReplaceOptions.ReplaceType =
PdfTextReplaceOptions.ReplaceActionType.WholeWord; // 仅替换整个单词
textReplaceOptions.ReplaceType =
PdfTextReplaceOptions.ReplaceActionType.IgnoreCase; // 忽略大小写
textReplaceOptions.ReplaceType =
PdfTextReplaceOptions.ReplaceActionType.AutofitWidth; // 自动调整字符宽度
textReplacer.Options = textReplaceOptions;
// 执行替换
textReplacer.ReplaceAllText("Document", "File");
可用的ReplaceActionType枚举值包括:
- WholeWord:仅匹配完整的单词,而非单词的一部分
- IgnoreCase:忽略英文字母的大小写差异
- AutofitWidth:自动调整新文本的宽度以适应原文本区域
- Regex: 使用正则表达式匹配文本,适用于批量匹配多种模式
💡 在实际使用中,可以根据需要设置单个或多个替换选项。
3.2 基于正则表达式的文本替换示例
利用 ReplaceActionType.Regex 可以实现利用正则表达式匹配PDF文档中的特定文本模式并进行批量替换。这对于处理不确定的文本内容(如日期格式、电话号码、邮箱地址等)尤为实用。
以下示例演示如何使用正则表达式匹配并替换PDF中的电子邮件地址:
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Text.RegularExpressions;
namespace ReplaceUsingRegex
{
class Program
{
static void Main(string[] args)
{
// 创建PdfDocument对象并加载PDF文件
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("contact.pdf");
// 创建PdfTextReplaceOptions对象并设置为正则匹配模式
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.Regex;
// 遍历文档所有页面
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
textReplacer.Options = textReplaceOptions;
// 使用正则表达式匹配常见邮箱格式并替换
string regexPattern = @"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}";
textReplacer.ReplaceAllText(regexPattern, "contact@newdomain.com");
}
pdf.SaveToFile("contact_updated.pdf");
pdf.Dispose();
}
}
}
📌 参考文档: 常见正则表达式规则
3.3 保持原文本的字体和样式
Free Spire.PDF 的一个重要特性是,在执行文本替换时,PdfTextReplacer 接口默认会保持原文本的字体和样式不变。这意味着替换后的文本会自动沿用原文本的字体、字号、粗体/斜体等格式属性,无需手动设置,有效保证了替换后PDF文档的视觉一致性。
⚠️ 注意:如果新文本的长度超过了原占位符区域的可容范围,设置
AutofitWidth效果也会不佳。
3.4 在指定区域内替换文本
该库还支持在PDF页面的指定区域内进行文本替换。这一功能非常实用,例如当只需要替换表格单元格内或特定文本框中的内容时,可以通过设置SetReplacementArea方法限定替换范围:
✅ 单位为磅(
Point)。
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("input.pdf");
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
PdfTextReplacer replacer = new PdfTextReplacer(page);
PdfTextReplaceOptions replaceOptions = new PdfTextReplaceOptions();
// 定义替换区域(矩形区域,参数依次为X坐标、Y坐标、宽度、高度)
RectangleF rectangle = new RectangleF(79, 184, 453, 119);
replaceOptions.SetReplacementArea(rectangle);
replacer.Options = replaceOptions;
replacer.ReplaceAllText("公司", "企业");
}
pdf.SaveToFile("区域替换.pdf");
pdf.Dispose();
上述代码指定了一个从 (79,184) 开始、宽度 453、高度119 的矩形区域,该区域内的匹配文本才会被替换。
总结
本文系统地介绍了使用 C# 实现PDF文本查找与替换的完整方法。从环境安装、基本用法到高级配置,涵盖了PDF文本替换开发中的主要场景。开发者可以根据实际业务场景灵活运用上述技术方案,实现对PDF文档的自动化批量处理,有效提升文档处理效率。
更多推荐


 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)