
个人总结的超详细的Claude Code学习笔记
Claude Code官方文档:https://code.claude.com/docs/zh-CN/overview
Claude Code泄露源码:https://github.com/NanmiCoder/cc-haha
一、 CLAUDE.md
Claude Code 的上下文工程是一个分层体系:从静态的 CLAUDE.md,到动态的 MEMORY.md,到按需的 SKILL.md 和 Rules,再到执行层的 Hooks——它们绝大多数最终都作为 user-role context message 注入到对话历史,而不是 system prompt。理解这个分层,才能真正做好上下文工程。
(一) CLAUDE.md简介
CLAUDE.md 最常见的的位置,会放到这两个地方,一个是项目目录下面的 CLAUDE.md,一个是项目目录下面 .claude 文件夹下的 CLAUDE.md,总共包含11种放置位置。内容如下:
- 项目介绍,如:目录介绍,模块介绍,命令介绍
- 开发规范,如:命名规范,代码风格,Git提交规范
- 注意事项,如:特别约束,采坑文档
(二) CLAUDE.md的11种位置
1. 组织级3种
- /组织级配置目录/CLAUDE.md
- /组织级配置目录/.claude/CLAUDE.md
- /组织级配置目录/.claude/rules/*.md
公司的全局编码标准、安全策略、合规要求等信息,适合写到这里
2. 用户级2种
- C:\Users\admin/.claude/CLAUDE.md
- C:\Users\admin/.claude/rules/*.md
个人的代码风格偏好、个人工具快捷方式等信息,适合写到这里
3. 项目级5种(最常用)
- /项目目录/CLAUDE.md
- /项目目录/.claude/CLAUDE.md
- /项目目录/.claude/rules/*.md
- /项目目录/module/rules/*.md
- /项目目录/module/sub_module/CLAUDE.md
单个项目的项目架构、编码标准、常用工作流等信息,适合写到这里
4. 本地级1种
- /项目目录/module/sub_module/CLAUDE.local.md
个人的沙盒 URL、偏好的测试数据等信息,适合写到这里
5. 参考图

(三) CLAUDE.md的执行过程
1. 拼接用户参数的函数:prependUserContext
从claude code泄露源码中发现的关键函数:prependUserContext
很多人会下意识以为 CLAUDE.md 的内容是被 Claude Code 拼到 system prompt 里发给模型的。这个理解其实不准确,下面我们看一下源码里它实际是怎么被传过去的
关键源码在 src/utils/api.ts:449,函数名叫prependUserContext
// 定义一个函数 prependUserContext,作用是把额外上下文"塞"到对话历史最前面
export function prependUserContext(
messages: Message[], // 参数 1:原本的对话历史(一个消息数组)
context: { [k: string]: string }, // 参数 2:要注入的上下文对象,CLAUDE.md 内容就装在这里
): Message[] {
// 如果是测试环境,原样返回不做处理,避免污染测试
if (process.env.NODE_ENV === 'test') return messages
// 如果 context 对象是空的,没东西要塞,直接返回
if (Object.entries(context).length === 0) return messages
// 返回一个全新的数组:新造的消息在前,原对话历史在后
return [
// 临时造一条"用户消息"插到对话最前面
createUserMessage({
// 消息内容是下面这一大段文本,被 <system-reminder> 标签包起来
content: `<system-reminder>
As you answer the user's questions, you can use the following context:
${Object.entries(context).map(([k, v]) => `# ${k}\n${v}`).join('\n')}
IMPORTANT: this context may or may not be relevant to your tasks.
You should not respond to this context unless it is highly relevant to your task.
</system-reminder>`,
isMeta: true, // 打个"元消息"标记:这是系统造的,不是真用户输入
}),
...messages, // 把原本的对话历史展开拼在后面
]
}
2. 分析执行方法
1. 接收一个 messages 数组,再接一个 context 对象(CLAUDE.md的内容就放在 context 里面)
2. 把 context 拼成一段文本,外面套一层<system-reminder>标签
3. 用 createUserMessage() 创建一条 user message,再用 ...messages 拼到原 messages 数组的前面
所以CLAUDE.md实际上是以一条 user message 的形式被塞到对话历史最前面的,它不是 system prompt 的一部分
3. 分析执行方法得到的执行过程
读取 CLAUDE.md
↓
形成 context 对象
↓
prependUserContext(messages, context)
↓
创建一条 user-role meta message
↓
插入 messages 最前面
↓
连同 system prompt、tools、历史消息一起发给 Claude API
4. 总结思考
_**CLAUDE.md**_** = Claude Code 应用层的项目上下文;最终落到 API 请求时 = 一条插在最前面的
user-role meta message。**
思考一:CLAUDE.md的约束力其实没有想象中那么强。它在模型那里只是一段"user message",并不是系统层指令
思考二:注入文本末尾那句
“IMPORTANT: this context may or may not be relevant to your tasks. You should not respond to this context unless it is highly relevant to your task. ”
翻译为中文:“重要提示:此上下文可能与您的任务相关,也可能不相关。除非与您的任务高度相关,否则您不应响应此上下文。”
是源码里写死的,相当于明确告诉模型可以判断当前任务和这段上下文是否相关。所以有时候模型会觉得任务和CLAUDE.md关系不大,就忽略掉部分规则,这并不是 AI 不听话,是源码层面就允许它这样做
思考三:如果你希望让 AI 强制遵守某些规则,CLAUDE.md不是最强的通道。可以考虑用 agent 的 system prompt、或者 hooks 这种程序级约束来实现
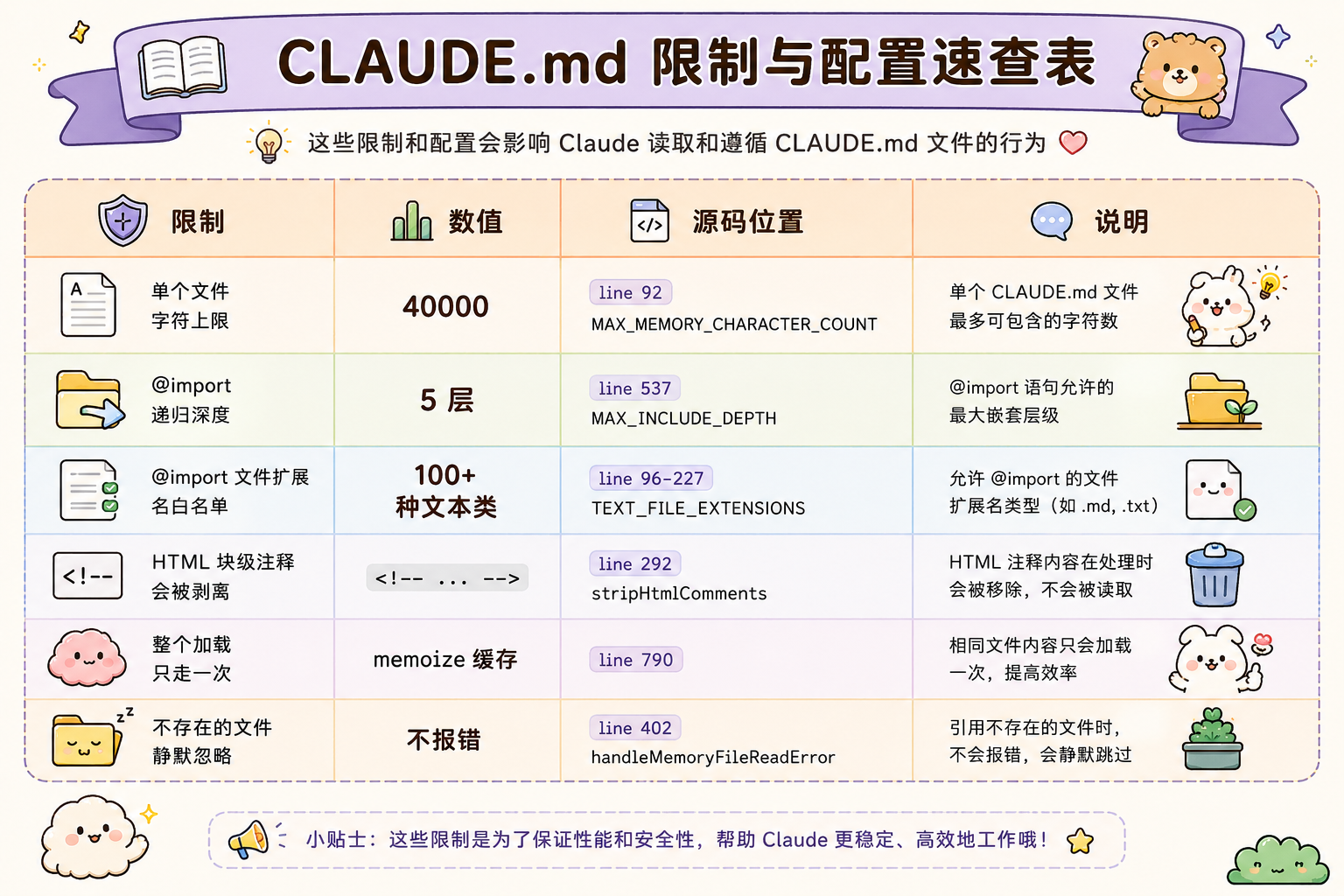
(四) CLAUDE.md的硬性限制清单
以下是通过claude code源码发掘到的CLAUDE.md的限制
二、 MEMORY.md
_MEMORY.md__ 是 Claude Code __Auto Memory(自动记忆)机制的入口文件,用来让 Claude 在不同会话之间保留它“自己学到的项目知识”。它属于典型的上下文工程(Context Engineering)_组件,但不是 System Prompt,而是被当作上下文注入给 Claude 使用。
我在一次让AI编写接口用例时,它没有遵守格式规范,漏掉了一部分要求必须写的注释内容。我就反问AI,让AI反思并总结这次犯错的原因,以及以后如何避免。最后AI生成了如下的记忆文件,来避免下次犯同样的错:~.claude\projects\D–workSpace-001-test-automation\memory\MEMORY.md。
(一) MEMORY.md 是什么?
Claude Code 每个会话都会从新的上下文窗口开始,因此它本来不会记得上次调试过什么、项目有什么特殊命令、用户偏好是什么。Auto Memory 用来解决这个问题:Claude 会在工作过程中,把它认为未来有用的信息写入记忆文件,例如构建命令、调试经验、架构笔记、代码风格偏好和工作流习惯。
它不是你手写的项目规范,而是 Claude 根据会话中的修正、偏好和发现自动沉淀出来的内容。
(二) 它解决的痛点
| 痛点 | MEMORY.md 如何解决 |
|---|---|
| 每次新会话都从零开始 | 会话开始时自动加载记忆,让 Claude 继承项目经验 |
| 重复解释项目规则和偏好 | Claude 可记住“使用 pnpm 而不是 npm”等偏好 |
| 调试经验丢失 | 把曾经踩过的坑、特殊命令、环境问题保存下来 |
| 长期项目上下文断裂 | 让 Claude 在多次会话中逐渐积累项目知识 |
| 人工维护文档成本高 | Claude 自动判断哪些信息值得记住,无需每次手动写文档 |
(三) 存放路径
官方当前路径是:
~/.claude/projects/<project>/memory/
├── MEMORY.md
├── debugging.md
├── api-conventions.md
└── ...
<project> 通常根据 Git 仓库派生。同一个 Git 仓库下的所有 worktree 和子目录会共享同一个自动记忆目录;如果不在 Git 仓库中,则使用项目根目录作为依据。
(四) 加载规则
MEMORY.md 并不是无限制全部塞进上下文。
官方规则是:
每次会话启动时加载 MEMORY.md 的前 200 行,或前 25KB,取先到者。
超过部分不会在启动时加载。Claude 会尽量保持 MEMORY.md 简洁,并把详细内容移动到其他主题文件,例如 debugging.md、patterns.md,这些文件不会启动时加载,而是在需要时由 Claude 通过文件工具按需读取。
这是一种典型的 Progressive Disclosure(渐进式披露) 思路:
启动时加载小索引
需要时再读取详细文件
避免上下文窗口被无关信息撑爆
(五) 如何使用
1. 查看和编辑
在 Claude Code 中使用:
/memory
/memory 可以查看当前会话加载的 CLAUDE.md、CLAUDE.local.md、rules 文件,并提供打开自动记忆文件夹的入口,还可以切换 Auto Memory 开关。
2. 让 Claude 记住某件事
你可以直接说:
记住:这个项目使用 pnpm,不要用 npm。
或者:
Remember that API tests require a local Redis instance.
Claude 会把这些信息保存到 Auto Memory 中。
3. 禁用 Auto Memory
Auto Memory 默认开启。可以通过 /memory 面板关闭,也可以在项目设置(settings.json)中写:
{
"autoMemoryEnabled": false
}
或者通过环境变量关闭:
$env:CLAUDE_CODE_DISABLE_AUTO_MEMORY = "1"
官方也说明可以使用 autoMemoryEnabled: false 或 CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 关闭自动记忆。
(六) 在上下文工程中的作用
MEMORY.md 属于上下文工程中的 Context Persistence(上下文持久化)。
它的作用不是规定 Claude 必须做什么,而是让 Claude 在每次会话开始时获得一份“历史经验摘要”。
可以这样理解:
CLAUDE.md 负责告诉 Claude:这个项目的规则是什么。
MEMORY.md 负责提醒 Claude:你之前在这个项目里学到了什么。
SKILL.md 负责教 Claude:遇到某类任务时应该怎么做。
官方明确说明,CLAUDE.md 和 Auto Memory 都会在每次对话开始时加载,并且 Claude 会把它们当作上下文,而不是强制配置。
另外,官方还说明 CLAUDE.md 内容是作为 system prompt 之后的 user message 传递的,不是 system prompt 本身;它会影响行为,但不能保证严格遵守。
(七) MEMORY.md、CLAUDE.md、SKILL.md 区别
| 对比项 | MEMORY.md |
CLAUDE.md |
SKILL.md |
|---|---|---|---|
| 核心定位 | Claude 的自动记忆 | 人类写给 Claude 的项目说明和规则 | 可复用任务技能 |
| 谁写 | Claude 自动写,也可用户要求记住 | 开发者、团队、组织 | 开发者、团队、插件作者 |
| 内容类型 | 学到的经验、偏好、调试发现 | 项目规则、架构、命令、约定 | 某类任务的步骤、流程、工具说明 |
| 加载时机 | 每次会话启动加载前 200 行或 25KB | 每次会话启动加载,通常完整加载 | 相关任务触发时按需加载 |
| 适合放什么 | “上次发现测试需要 Redis” | “项目使用 pnpm,API 在 src/api” | “如何生成 PR 摘要”“如何做代码审查” |
| 是否版本控制 | 默认机器本地,不跨机器共享 | 项目级通常提交 Git | 项目级或插件级可提交 Git |
| 是否硬约束 | 否 | 否 | 否 |
| 是否占用上下文 | 是,但有 200 行/25KB 限制 | 是,文件越大越占 token | 触发时才占用主要上下文 |
| 主要风险 | 记住错误信息、过期信息、个人偏好污染 | 文件过长、规则冲突、过度泛化 | 技能描述不准导致误触发或不触发 |
(八) 什么时候用哪个?
1. 用 CLAUDE.md
适合写稳定、团队共享、每次都需要知道的信息:
# Build
- 使用 pnpm install
- 使用 pnpm test 运行测试
# Architecture
- API 位于 src/api/
- 数据库使用 PostgreSQL
- ORM 使用 Prisma
官方建议 CLAUDE.md 用于 coding standards、workflows、project architecture 等内容。
2. 用 MEMORY.md
适合保存 Claude 在工作中发现的、未来可能有用的信息:
# Memory
- API 测试需要本地 Redis 实例。
- Windows 环境下运行 e2e 测试前需要先启动 Docker Desktop。
- 上次调试发现 auth 模块的 token 过期问题来自系统时间偏移。
官方说明 Auto Memory 适合保存 build commands、debugging insights、Claude 发现的 preferences 等内容。
3. 用 SKILL.md
适合封装“任务流程”:
---
name: pr-review
description: Use when reviewing a pull request.
---
# PR Review Process
1. 查看 diff
2. 检查测试覆盖
3. 检查安全风险
4. 输出 review summary
官方建议:如果某个条目是多步骤过程,或者只对代码库某一部分重要,应移动到 skill 或 path-scoped rule,而不是塞进 CLAUDE.md。
(九) 优缺点对比
| 文件 | 优点 | 缺点 |
|---|---|---|
CLAUDE.md |
稳定、明确、适合团队共享 | 太长会占上下文;规则冲突会降低遵守度 |
MEMORY.md |
自动学习、减少重复解释 | 可能保存错误或过期知识,需要审计 |
SKILL.md |
按需加载,适合复杂任务流程 | 需要设计触发描述;不适合放全局常识 |
(十) 总结
_**CLAUDE.md**_** 是项目说明书,**_**MEMORY.md**_** 是 Claude
的工作笔记,**_**SKILL.md**_**
是任务操作手册。三者都是上下文工程的重要组成部分,但都不是硬安全边界;真正需要强制执行的规则应使用 Hooks、权限配置或
CI/CD。**
三、 skills
(一) skills简介
2025年10月16日 Anthropics 最早推出 Skills的概念,并于2025年12月18日 正式将Skills定义为AI开放标准。Anthropics官方文章链接:https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
skills的作用:AI大模型目前并非全能,对特定领域可能不够了解,直接提问可能得到错误答案。通过Skills功能,用户可为AI提供说明文档(如开发流程、规范或经验),补充AI的知识,使其在需要时查阅,从而提高回答的准确性。例如,可为特定编程语言(如Java、前端开发)或公司内部规范创建Skills文档。参考目前的harness概率,一个skill也能做成专门完成一件特定工作的技能包(比如我个人编写的专门写接口用例的skill:https://github.com/buer2233/api-test-dwp)。
(二) skills的构成
1. Skill存放位置
- 第一种是项目目录下(项目级)位置是你项目目录下的 .claude/skills/xxx,适合放与你这个项目有关的Skills。
- 第二种就是用户目录下(全局级),以windows电脑举例:C:\Users\admin.claude\skills,放到这里的Skills所有项目都能用,适合放置一些通用规范和技能。
2. SKILL.md的内容简介
- 一个skills 必须包括一个 SKILL.md 文件,且其中必须包含两个模块:元数据和指令。元数据 必填两项是:name 和 description。name为SKILL名称,description描述SKILL的作用和触发条件。
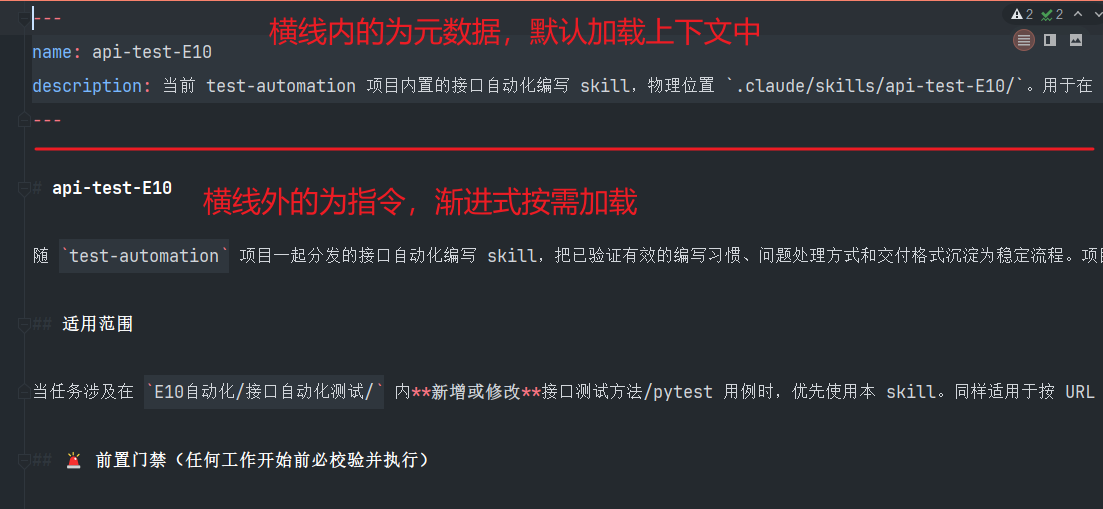
skill默认情况下只会加载元数据name和description,在需要使用技能时,才会渐进式的按需加载SKILL内的指令。
3. SKILL.md中的元数据详细介绍
3.1 必填字段
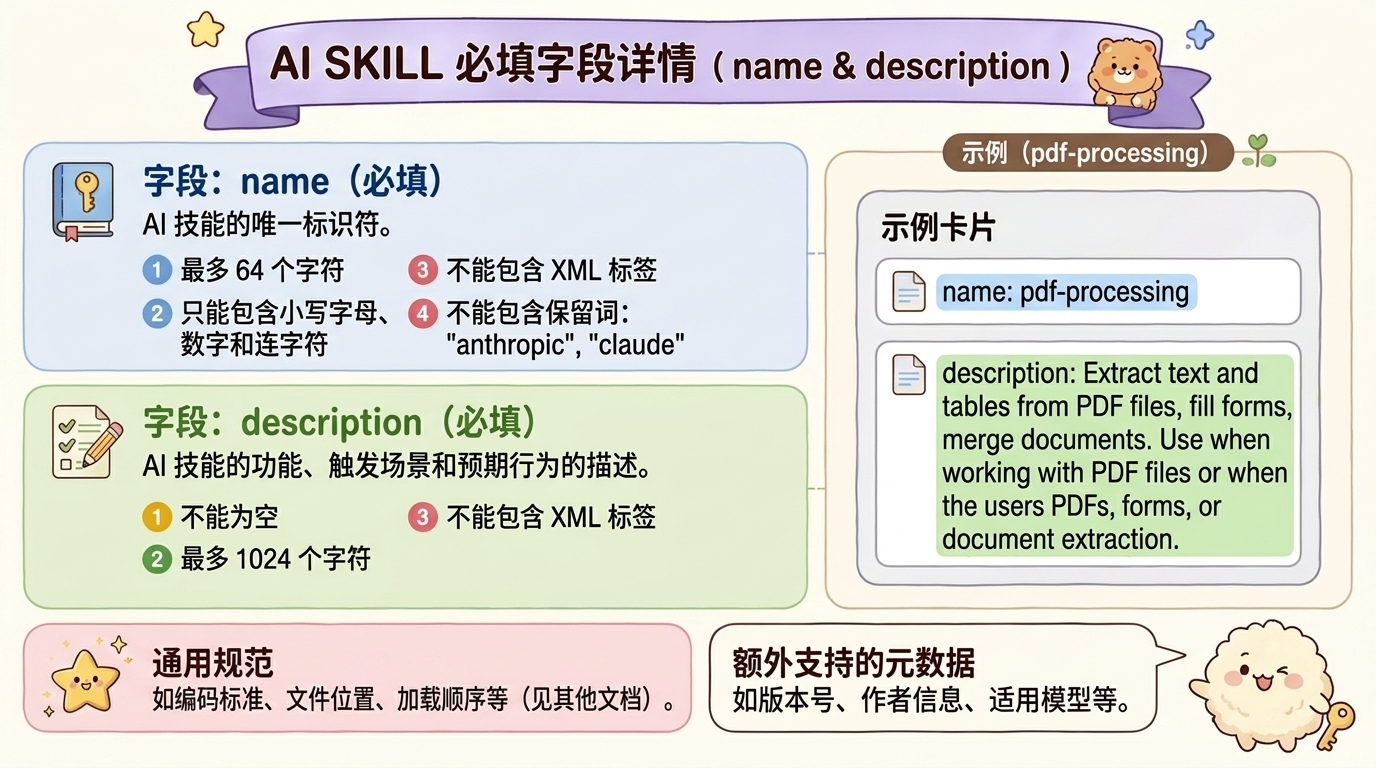
3.2 通用规范元数据(非必填)
- codex,cursor,vscode等支持skills规范的产品,都支持这些元数据

3.3 Claude Code 额外支持的元数据(非必填)
- claude code 支持这些元数据,其他codex,cursor等可能不支持或者部分支持
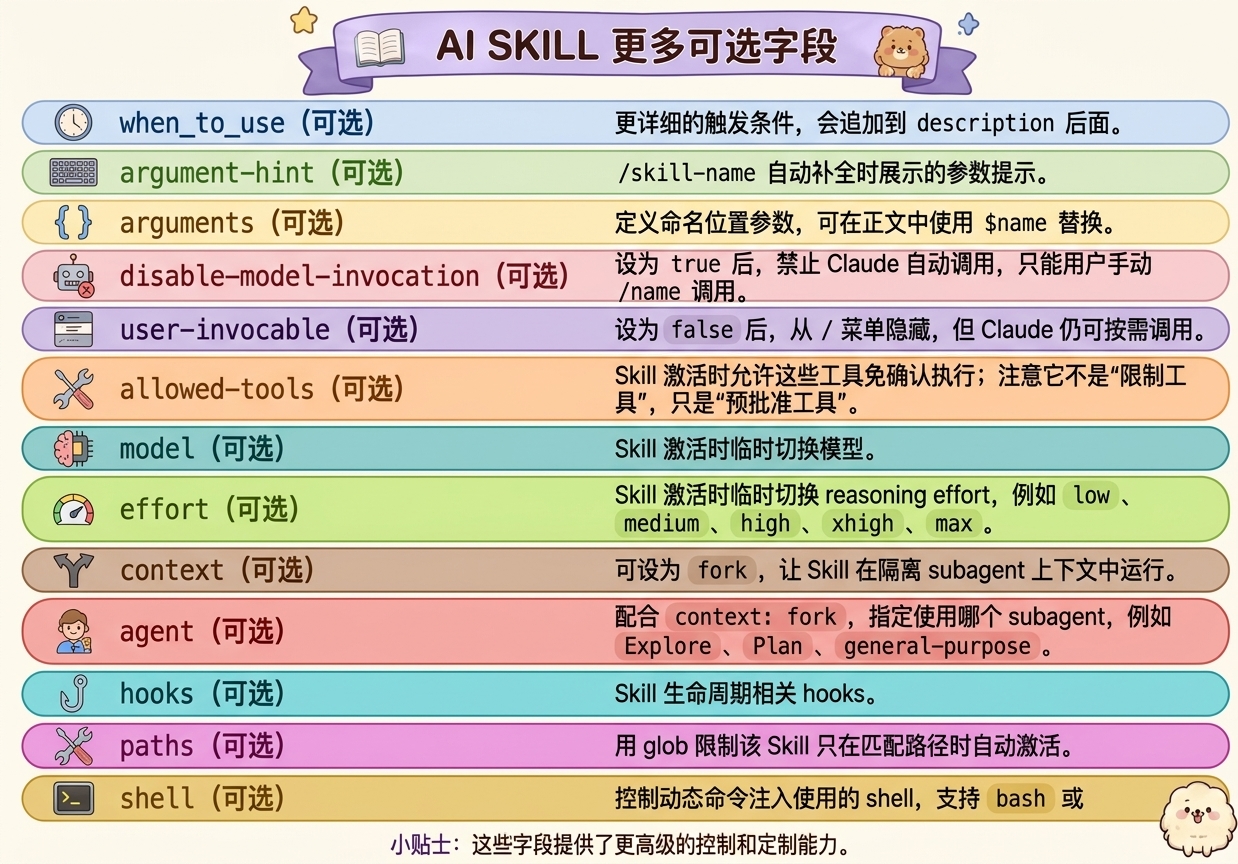
4. Skills 完整目录
- SKILL.md和CLAUDE.md 一样,不建议都写到一个文件,SKILL.md 也可以将内容分拆到多个.md文件。
- SKILL.md中 支持引入一个脚本,注意一个细节,就是写到Skills里面的脚本,不会加载,而是执行。还有个技巧是针对那种重复性较高,可以脚本化的操作,都建议直接脚本化,以此提升AI执行的效率也能大幅的减少Token的消耗。
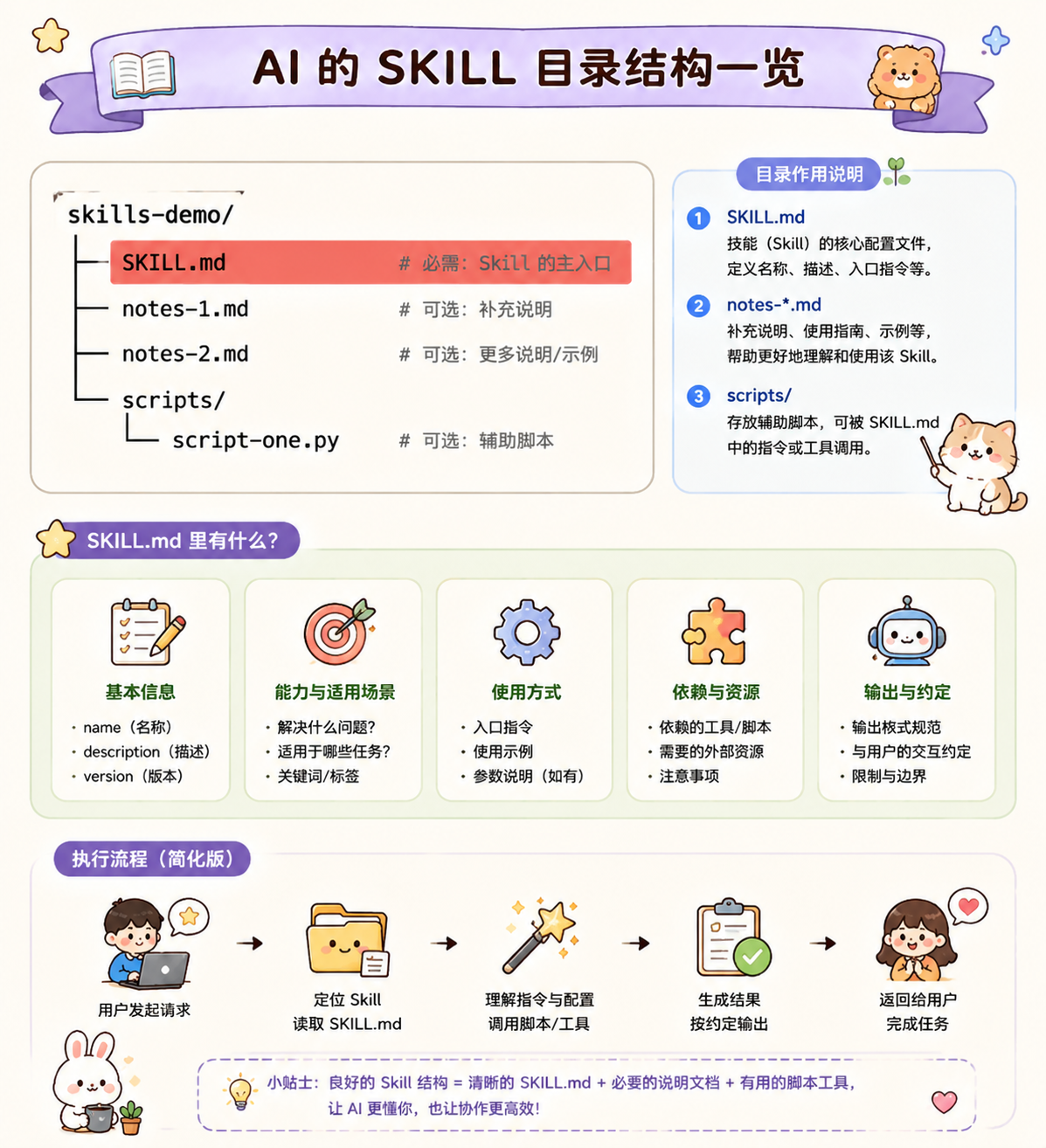
(三) skills触发
1. 自动触发
AI会在提问的开始,将skills全局 和 你当前项目下的 skills 元数据内容(name,description 等)都加载一下
所以你什么都不用管,当AI感觉需要读取某个skills的时候,会自动读取。
2. 手动触发
也可以直接通过斜杠指令,来手动触发,根据截图斜杠指令加载的是name的名称,另外也能看到 description的信息。

3. 禁止自动触发
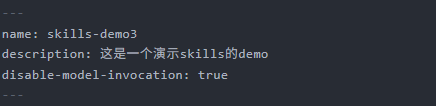
如下图,在SKILL的描述后添加:disable-model-invocation: true。这样skills就不会自动被调用了,只能手动触发了。
(四) Skills中添加参数
1. $ 初步讲解
Claude Code 里跟 $ 有关的写法,其实只有两类:
1.1 参数占位符(接受用户输入的东西)
| 写法 | 含义 |
|---|---|
$ARGUMENTS |
用户传进来的全部内容 |
$0$1 $2 |
第几个 参数(从 0 开始数) |
$ARGUMENTS[0]$ARGUMENTS[1] |
上面那种的「全名版」 |
$名字 |
给参数起个有意义的名字 |
1.2 环境变量(运行环境自动提供的信息)
| 写法 | 含义 |
|---|---|
${CLAUDE_SKILL_DIR} |
当前 Skill 自己所在的目录 |
${CLAUDE_SESSION_ID} |
当前会话的编号 |
重点划一下: 第一类是
$XXX,没有花括号。 第二类是${XXX},有花括号。
这俩是被两套不同的代码处理的,写错花括号就不会替换,这是新手最容易栽的坑之一。
2. 最基础的 $ARGUMENTS
在 SKILL.md 正文里直接写 $ARGUMENTS:
---
description:分析指定文件
---
请帮我分析这个文件有没有问题:$ARGUMENTS
用户这样调用:
/分析文件 src/login.ts
$ARGUMENTS 就会被替换成用户跟在命令后面写的那串字:
请帮我分析这个文件有没有问题:src/login.ts
就这么简单。 $ARGUMENTS 拿到的是用户在命令名后面写的所有内容。
$ARGUMENTS= 「用户输入的所有东西」的占位符。 你把它放哪里,用户的输入就填到哪里。
$ARGUMENTS必须全大写。写成$arguments、$Arguments一律不认,不会替换。
3. $ARGUMENTS 自动兜底机制
「如果我忘了写 $ARGUMENTS,用户传的参数是不是就丢了?」
不会丢。
举个例子,假设你的 Skill 长这样,正文里没写任何占位符:
请帮我做代码审查。
用户照样传了参数:
/审查 src/login.ts
Claude Code 会发现你正文里没有占位符,于是自动把参数贴到正文末尾,注入给模型的内容会变成:
请帮我做代码审查。
ARGUMENTS: src/login.ts
所以参数永远不会凭空消失。这只是个兜底机制,建议还是显式写 $ARGUMENTS 让效果更可控。
4. 参数切片: $0 / $1 / $2
用编号占位符 $0``$1``$2:
任务内容:$0
优先级:$1
负责人:$2
用户调用 /建任务修复登录bug 高优先级张三,结果:
任务内容:修复登录bug
优先级:高优先级
负责人:张三
把参数想象成一排储物柜,编号从 0 开始:
$0是第 1 个柜子、$1是第 2 个、$2是第 3 个……
(程序员数数都从 0 开始,习惯一下就好)
- 等价写法:
$0 是简写,它的「全名」是 $ARGUMENTS[0]:
任务内容:$ARGUMENTS[0]
优先级:$ARGUMENTS[1]
两种写法效果完全一样,平时用 $0 就够了,省事。
5. 给参数起名字: $文件名、 $负责人
第一步:在 SKILL.md 最上面的 frontmatter 里,用 arguments 字段按顺序列出参数名:
---
description:创建任务
arguments:
-任务内容
-优先级
-负责人
---
第二步:正文里就能直接用名字了:
任务内容:$任务内容
优先级:$优先级
负责人:$负责人
用户调用 /建任务修复登录bug 高张三,结果:
任务内容:修复登录bug
优先级:高
负责人:张三
比 $0 $1 $2 好读太多了。
- 一个关键认知:名字只是「外号」,本质还是按顺序
这是这一节最重要的一点,很多人会理解错:
❌ 误解:以为可以这样写命令 /建任务负责人=张三优先级=高(像填表格那样指定) ✅ 真相:还是严格按位置对号入座
arguments 里写的第 1 个名字,永远绑定用户传的第 1 个参数。
名字只是给「1 号柜子」贴了个标签叫「任务内容」方便你读,但东西还是按顺序塞进柜子的。位置错了,名字救不了你。
- 容易踩的坑:名字不能用纯数字
别把参数命名成 1、 2 这种纯数字。
因为系统已经用 $1``$2 表示编号了,如果你的参数名也叫 1,两套语法就打架了。系统会直接无视这种命名,相当于没声明。
起名就起有意义的人话,比如 文件名、 模式、 负责人。
6. ${CLAUDE_SKILL_DIR} 介绍
- 为什么需要
一个 Skill 经常不只有 SKILL.md 一个文件,旁边可能还放着脚本、模板、参考资料:
我的Skill/
├── SKILL.md
└── scripts/
└──检查.sh ←我想在Skill里运行这个脚本
问题来了:怎么写脚本的路径?
如果写死成 /Users/你/.claude/skills/我的Skill/scripts/检查.sh,那别人下载你的 Skill 装到自己电脑就找不到了——每个人电脑的路径都不一样。
- 怎么用
用魔法变量 **$****{****CLAUDE_SKILL_DIR****}**,它会自动变成「当前 Skill 自己所在的文件夹路径」:
运行检查脚本:
!`${CLAUDE_SKILL_DIR}/scripts/检查.sh`
不管这个 Skill 被装到谁的电脑、哪个项目, ${CLAUDE_SKILL_DIR} 都能准确指向它自己的位置。
${CLAUDE_SKILL_DIR}= 「我这个 Skill 住在哪」。 想引用同目录的脚本/模板,用它就对了,别写死路径。
- 重点:花括号别忘了!
再强调一遍上面提过的:
- 参数家族(接用户输入的):
$ARGUMENTS、$0、$名字,没有花括号 - 环境家族(运行环境的):
${CLAUDE_SKILL_DIR}、${CLAUDE_SESSION_ID},必须带花括号
如果你把环境变量写成 $CLAUDE_SKILL_DIR(少了花括号),它不会被替换。这是新手最常踩的坑之一。
- 顺便认识一下 ${CLAUDE_SESSION_ID}
${CLAUDE_SESSION_ID} 会被替换成当前对话的编号,常用于给临时文件起不重名的名字,例如:
把结果保存到/tmp/result-${CLAUDE_SESSION_ID}.json
用法和 ${CLAUDE_SKILL_DIR} 一样,记得带花括号。
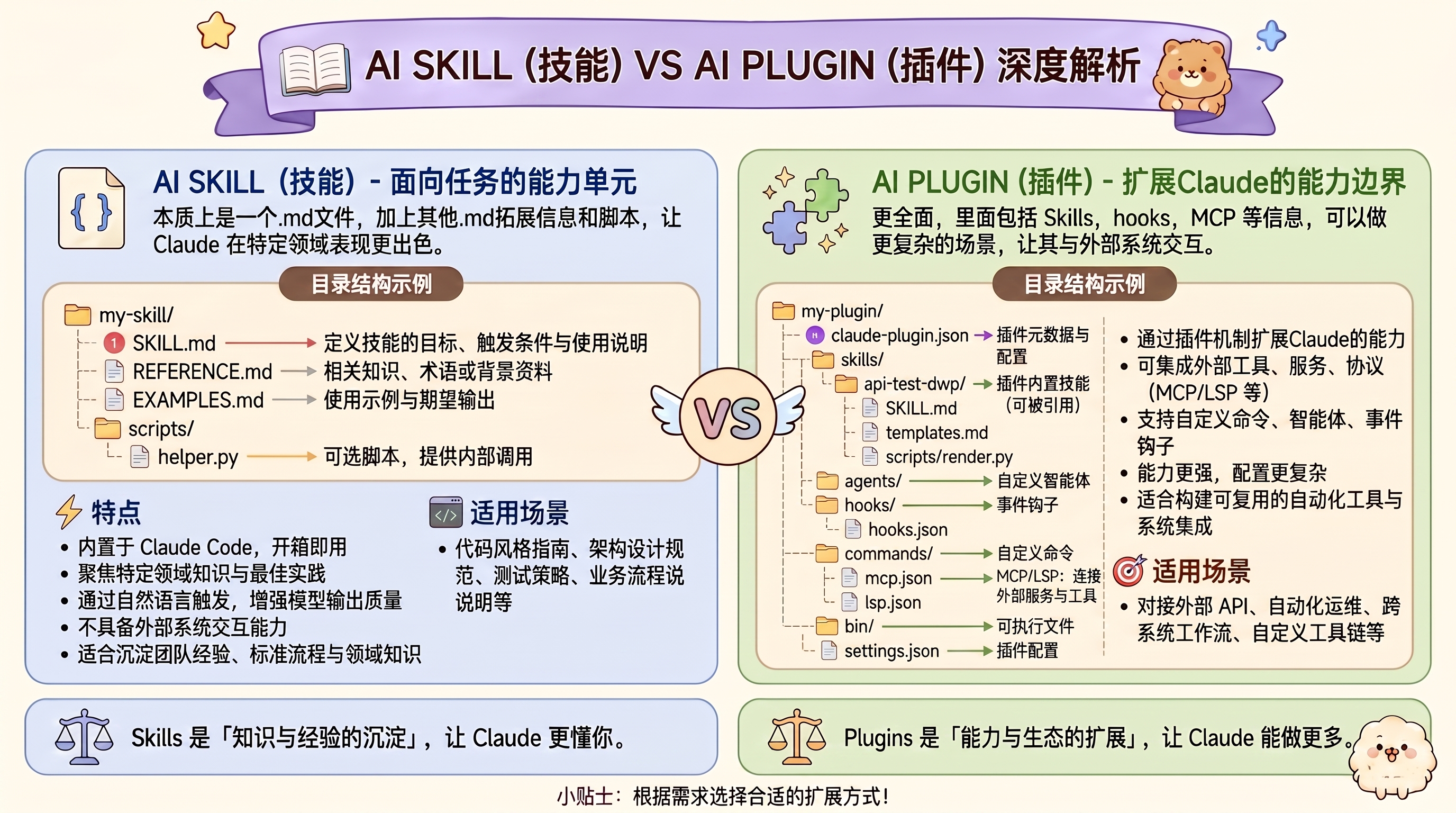
(五) Skills 和 Plugins 的区别
- Skills本质上就是一个.md的文件 再加上 其他.md拓展信息 和 拓展脚本
- Plugin则更全面,里面包括 Skills,hooks,mcp 等信息,可以做更复杂的场景
(六) Skills 和 MCP 的区别
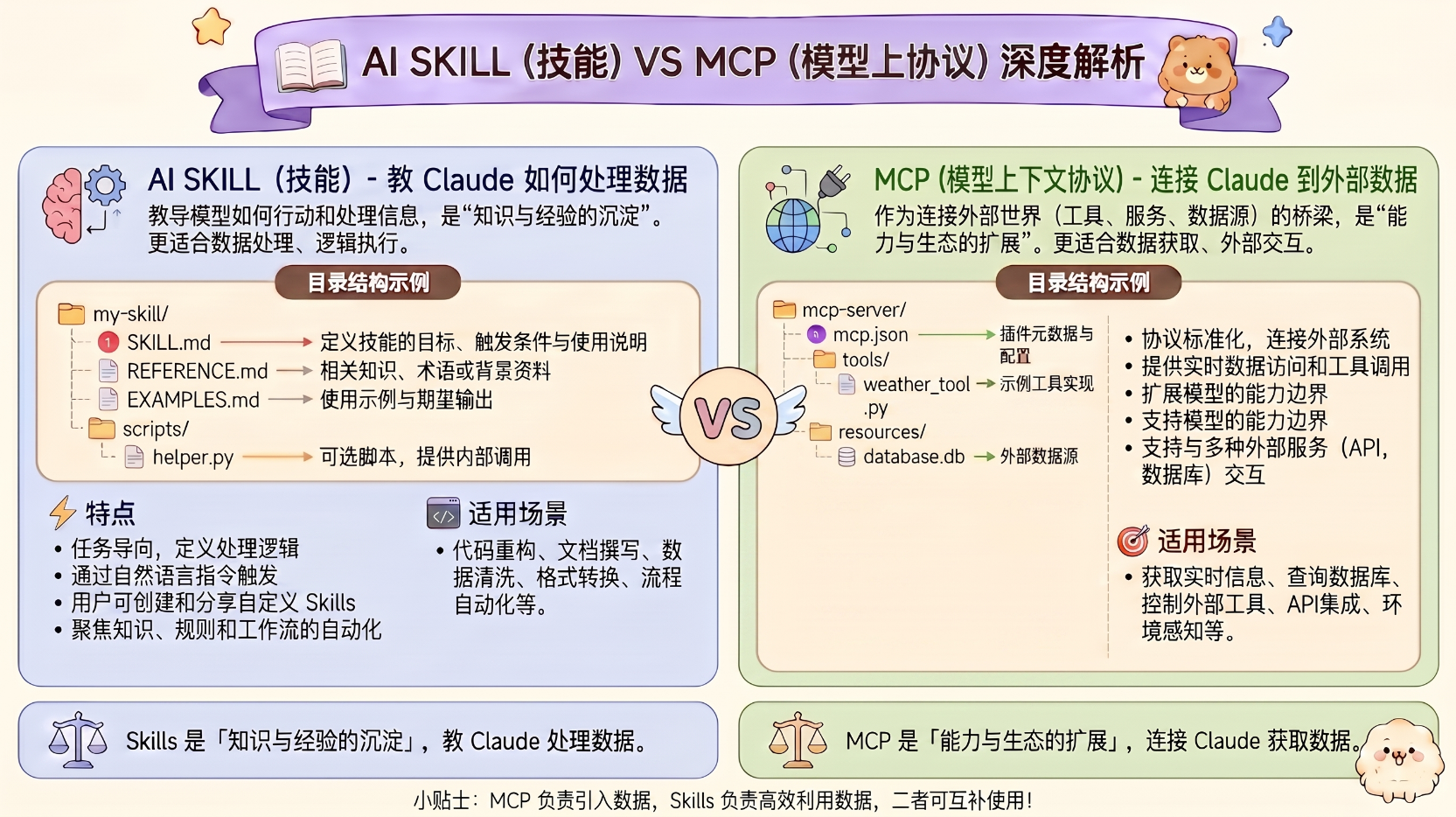
官方原文:https://claude.com/blog/skills-explained
MCP connects s Claude todata; Skills steach Claude what to do with that data.(MCP 适合做获取数据的场景;Skills 更适合做获取数据之后,处理数据的场景)
(七) Skills的详细执行流程(纯泄露源码分析)
先通过一张图概括整体的执行过程
1. 完整的执行流程图
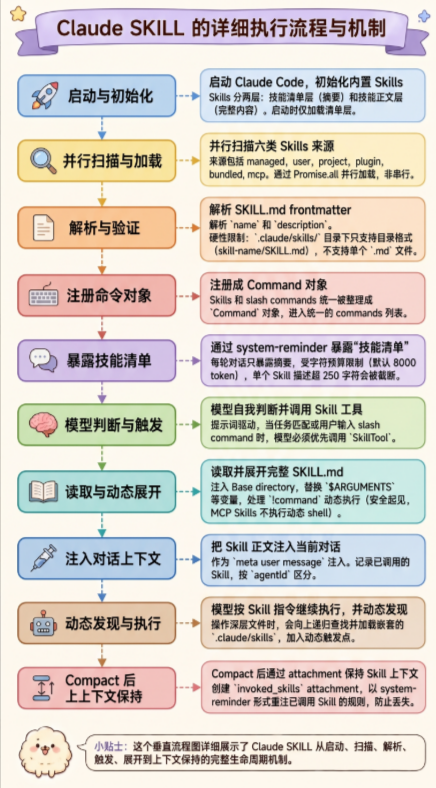
2. Skills开始不是全量注入
很多人会以为 Skills 跟 CLAUDE.md 一样,启动会话时就把所有内容塞进上下文。源码里不是这样。
Skills 分两层:
- 技能清单层:只把 name / description 这类摘要给模型看。
- 技能正文层:只有模型调用 Skill 工具后,完整 SKILL.md 才会进入上下文。
Skills的提示词在这里 在src/tools/SkillTool/prompt.ts:173
export const getPrompt = memoize(async (_cwd: string): Promise<string> => {
return `Execute a skill within the main conversation
When users ask you to perform tasks, check if any of the available skills match. Skills provide specialized capabilities and domain knowledge.
When users reference a "slash command"or"/<something>" (e.g., "/commit", "/review-pr"), they are referring to a skill. Use this tool to invoke it.
How to invoke:
- Use this tool with the skill name and optional arguments
...
Important:
- Available skills are listed in system-reminder messages in the conversation
- When a skill matches the user's request, this is a BLOCKING REQUIREMENT: invoke the relevant Skill tool BEFORE generating any other response about the task
...
`
})
这段提示词说明了三件事:
- 模型要先检查当前任务是否匹配可用 Skills。
- 用户提到/command这种 slash command 时,也可能是在说一个 Skill。
- 如果 Skill 匹配当前任务,模型应该先调用Skill工具。
所以 Skills 的触发是靠提示词驱动的:AI自我判断
3. 模型为什么知道要调用 Skills
前面提到,Skill 工具的提示词在src/tools/SkillTool/prompt.ts。
这个提示词很重要,因为它给模型建立了一个规则:当用户请求和某个 Skill 匹配时,必须先调用 Skill 工具。
还有一段系统级提示也会补充告诉模型 slash command 和 Skill 的关系,位置在src/constants/prompts.ts:382
hasSkills
? `/<skill-name> (e.g., /commit) is shorthand for users to invoke a user-invocable skill. When executed, the skill gets expanded to a full prompt. Use the ${SKILL_TOOL_NAME} tool to execute them. IMPORTANT: Only use ${SKILL_TOOL_NAME} for skills listed in its user-invocable skills section - do not guess or use built-in CLI commands.`
: null
翻译一下:
/<skill-name> 是用户调用 user-invocable skill 的简写。
执行时,这个 skill 会被展开成完整 prompt。
使用 Skill 工具来执行它。
重要:只对技能列表里的 skills 使用 Skill 工具,不要猜内置 CLI 命令。
用户输入/commit,在 Claude Code 的模型视角里,它并不只是一个普通字符串,而可能是一个需要通过 Skill 工具展开的技能。
4. Skills 是怎么被发现和加载的
技能目录加载的核心函数在:src/skills/loadSkillsDir.ts
它先准备几个路径:
const userSkillsDir = join(getClaudeConfigHomeDir(), 'skills')
const managedSkillsDir = join(getManagedFilePath(), '.claude', 'skills')
const projectSkillsDirs = getProjectDirsUpToHome('skills', cwd)
对应的就是:
用户级:~/.claude/skills
管理级:managed path 下的 .claude/skills
项目级:当前项目路径向上查找 .claude/skills
然后它会并行加载这些来源:也就是说,Skills 的读取不是一个一个串行读,而是多个来源并行读。
const [
managedSkills,
userSkills,
projectSkillsNested,
additionalSkillsNested,
legacyCommands,
] = await Promise.all([
...
])
5. Skills 的六类加载位置
源码里 Skills 的来源大概有六类:
managed skills
user skills
project skills
plugin skills
bundled skills
mcp skills
// 还有一个旧版兼容来源:legacy commands
具体解释就是
managed:
getManagedFilePath()/.claude/skills
user:
~/.claude/skills
project:
从当前目录向上查找 .claude/skills
additional:
--add-dir 指定目录下的 .claude/skills
legacy:
.claude/commands
plugin:
插件目录里的 skills
bundled:
Claude Code 内置注册的 skills
mcp:
MCP server 暴露的 prompt 型 skills
加载所有命令的入口在src/commands.ts
const loadAllCommands = memoize(async (cwd: string): Promise<Command[]> => {
const [
{ skillDirCommands, pluginSkills, bundledSkills, builtinPluginSkills },
pluginCommands,
workflowCommands,
] = awaitPromise.all([
getSkills(cwd),
getPluginCommands(),
getWorkflowCommands ? getWorkflowCommands(cwd) : Promise.resolve([]),
])
return [
...bundledSkills,
...builtinPluginSkills,
...skillDirCommands,
...workflowCommands,
...pluginCommands,
...pluginSkills,
...COMMANDS(),
]
})
Skills 最终会进入统一的commands列表。
Claude Code 内部没有把 Skills 和 slash commands 完全割裂开。它们最后都被整理成Command对象,只是来源字段不同。
6. SKILL.md 是怎么被解析的
每个SKILL.md会先经过 frontmatter 解析:src/utils/frontmatterParser.ts:130
export function parseFrontmatter(
markdown: string,
sourcePath?: string,
): ParsedMarkdown {
const match = markdown.match(FRONTMATTER_REGEX)
if (!match) {
return {
frontmatter: {},
content: markdown,
}
}
const frontmatterText = match[1] || ''
const content = markdown.slice(match[0].length)
...
}
它只认文件开头这种格式:
---
name: code-review
description: Review code changes
---
# Code Review
...
如果没有 frontmatter,也不是不能加载。源码会返回:
frontmatter: {}
content: markdown
7. Skill被模型调用后发生了什么
Skill 工具真正执行的位置在:src/tools/SkillTool/SkillTool.ts:580
async call(
{ skill, args },
context,
canUseTool,
parentMessage,
onProgress?,
): Promise<ToolResult<Output>> {
...
}
流程可以概括成:
拿到 skill 名
↓
去掉可能存在的 /
↓
从 commands 里找到对应 command
↓
记录 Skill 使用
↓
判断是否 context: fork
↓
如果 fork,交给 executeForkedSkill
↓
否则走 processPromptSlashCommand
↓
返回新的 messages 和 contextModifier
8. SKILL.md 正文展开时会做哪些处理
首先会注入Base directory
位置在src/skills/loadSkillsDir.ts:344:
async getPromptForCommand(args, toolUseContext) {
let finalContent = baseDir
? `Base directory for this skill: ${baseDir}\n\n${markdownContent}`
: markdownContent
...
}
如果这个 Skill 来自文件系统,有自己的目录,那么展开时会在正文前面加上:
Base directory for this skill: /path/to/.claude/skills/my-skill
因为一个 Skill 不一定只有一个SKILL.md。它的目录里可能还有脚本、模板、示例、参考文件。
加上 base directory 后,模型就知道这个 Skill 的资源根目录在哪里,可以用 Read/Grep 等工具去读同目录下的配套文件。
还会进行如下操作
- 替换
$ARGUMENTS和具名参数 - 替换
${CLAUDE_SKILL_DIR} - 替换
${CLAUDE_SESSION_ID} - 执行
!command动态语法
9. Skills 的上下文保存机制
已调用 Skills 会被记录到invokedSkills,状态结构在src/bootstrap/state.ts:1525:
export type InvokedSkillInfo = {
skillName: string
skillPath: string
content: string
invokedAt: number
agentId: string | null
}
添加函数在src/bootstrap/state.ts:1534:
export function addInvokedSkill(
skillName: string,
skillPath: string,
content: string,
agentId: string | null = null,
): void {
const key = `${agentId ?? ''}:${skillName}`
STATE.invokedSkills.set(key, {
skillName,
skillPath,
content,
invokedAt: Date.now(),
agentId,
})
}
注意这里会按agentId区分。也就是说,主对话调用的 Skill 和子 agent 调用的 Skill,不会随便混在一起。
10. compact 后为什么还能继续遵守已调用 Skill
Skills 还有一个和 compact 相关的保存机制。当上下文被压缩后,如果已调用 Skill 的正文完全丢失,模型后续就可能忘掉这个 Skill 的规则。
所以 Claude Code 会在 compact 后创建一个invoked_skillsattachment。
生成函数在src/services/compact/compact.ts:1494:
export function createSkillAttachmentIfNeeded(
agentId?: string,
): AttachmentMessage | null {
const invokedSkills = getInvokedSkillsForAgent(agentId)
if (invokedSkills.size === 0) {
returnnull
}
...
return createAttachmentMessage({
type: 'invoked_skills',
skills,
})
}
这个 attachment 渲染成模型消息的位置在src/utils/messages.ts:3644:
case 'invoked_skills': {
if (attachment.skills.length === 0) {
return []
}
const skillsContent = attachment.skills
.map(
skill =>
`### Skill: ${skill.name}\nPath: ${skill.path}\n\n${skill.content}`,
)
.join('\n\n---\n\n')
return wrapMessagesInSystemReminder([
createUserMessage({
content: `The following skills were invoked in this session. Continue to follow these guidelines:\n\n${skillsContent}`,
isMeta: true,
}),
])
}
也就是说,compact 后模型会看到类似:
<system-reminder>
The following skills were invoked in this session. Continue to follow these guidelines:
### Skill: code-review
Path: projectSettings:code-review
...
</system-reminder>
翻译过来就是:这就是为什么有些 Skill 被调用后,即使发生 compact,后续仍然可能继续生效。
<system-reminder>
在本课程中调用了以下技能。继续遵循这些准则:
###技能:代码审查
路径:projectSettings:代码审阅
...
</system-reminder>
(八) Skills 源码里的硬性限制
1. /skills/目录不支持单个.md文件
这个限制非常重要。在.claude/skills/目录下,单个.md文件不会被加载。
- 正确格式:.claude/skills/my-skill/SKILL.md
- 错误格式:.claude/skills/my-skill.md
源码位置:src/skills/loadSkillsDir.ts:424
2. Skills有上下文预算
预算逻辑在src/tools/SkillTool/prompt.ts:20:
export const SKILL_BUDGET_CONTEXT_PERCENT = 0.01
export const CHARS_PER_TOKEN = 4
export const DEFAULT_CHAR_BUDGET = 8_000
也就是说,默认技能清单大概占上下文窗口的 1%。
如果上下文窗口是 200k tokens,那么:200000 _* _0.01 = 8000 token
所以默认字符预算就是 8000 token,如果 Skills 太多,清单会被裁剪。
单个 Skill 的描述也有上限。
源码在src/tools/SkillTool/prompt.ts:29:
export const MAX_LISTING_DESC_CHARS = 250
如果description + when_to_use超过 250 字符,就会被截断。这就是为什么SKILL内容写太多之后,AI执行不会全部遵守的原因,因为上下文已经丢失了。
3. MCP Skills 不执行动态 shell 命令
本地 Skills 可以支持:
!`git status --short`
但 MCP Skills 不执行这类动态 shell。这样做是为了安全考虑
因为 MCP skills 是远程来源,源码不信任远程 Markdown 里的 shell 命令。
源码位置:src/skills/loadSkillsDir.ts:371
// Security: MCP skills are remote and untrusted — never execute inline
// shell commands (!`…` / ```! … ```) from their markdown body.
四、 Plugins
Plugin 是一个自包含目录,用来把 Skills、Commands、Agents、Hooks、MCP Servers、LSP Servers、Monitors、Themes 等能力打包起来,然后在个人、项目或团队范围内复用和分发。_ 官方文档也将 plugin 定义为“a self-contained directory of components that extends Claude Code with custom functionality”。_
_官方文档: _https://code.claude.com/docs/zh-CN/plugins-reference
(一) Plugins 基础介绍
1. Plugins 的诞生
如果说 Skills 是一本"专业领域的说明书",那 Plugins 就是一整个"工具箱"
Anthropic 在推出 Skills 之后,发现单纯一个 .md 文件还不够用
有时候用户想要的不只是给 AI 加一段说明,而是希望:
- 使用特定的AI Agent
- 设置生命周期 Hook(在操作前后自动执行某段脚本)
- 接入一个 MCP 服务器(让 AI 能调用外部工具)
把这些零碎东西分开装,又麻烦又容易乱
于是 Plugins 就诞生了——它把上面这些能力打包到一个目录里,一键安装、一键启用、一键禁用
简单理解: Skills 是一本书,Plugins 是一个图书馆
一个 Plugin 里面可以包含很多 Skills,再加上 commands、agents、hooks、MCP 服务等
2. Plugins 解决的核心痛点
我们先来看看,没有 Plugins 之前会有什么问题:
痛点一:能力分散
你想给团队加一套"前端开发规范+自动格式化命令+Hook 自动检查+MCP 接入 Figma",要分别配置 4 个地方
配置完之后,团队里每个新人来都要再配一遍,离谱
痛点二:缺乏分发
就算你写好了一套规范,怎么给别人?发压缩包?发 GitHub?发完别人怎么装到他自己的环境里?
痛点三:版本管理混乱
你改了一个 hook 脚本,团队里有人在用旧版有人在用新版,没人知道谁是对的
Plugins 就是为了一次性解决这些问题
它让你:
- 把所有能力打包到一个目录里(commands、agents、skills、hooks、mcp、lsp 全都装得下)
- 通过 Marketplace(插件市场)一键安装和卸载
- 自带版本号和作者信息,方便维护和升级
- 支持user / project / local 三种作用域,灵活控制对谁生效
举个最直观的例子:
- 你想让团队用上"浓缩了 10 年经验的 Java 开发规范"——下载一个 java-best-practices 插件就行
- 你想让 AI 接入公司内部 Jira 系统——下载一个 jira-mcp 插件就行
- 你想给所有项目加上"提交前自动跑 lint"的 Hook——下载一个 pre-commit-guard 插件就行
(二) Plugins 的构成
1. Plugin 存放位置
1.1 本地缓存目录(全局)
默认是:~/.claude/plugins/(mac/linux)
里面的结构大概是这样:
~/.claude/plugins/
├── known_marketplaces.json # 已注册的市场列表
├── installed_plugins.json # 已安装的插件清单
├── marketplaces/ # 各个市场的本地缓存
│ └── claude-plugins-official/
│ └── .claude-plugin/
│ └── marketplace.json
└── cache/ # 已下载的插件版本缓存
└── my-plugin@some-market/
└── 1.0.0/
└── (插件实际内容)
这是 Claude Code 帮你管理的,你一般不用动手改
1.2 项目级 plugin 目录
放在你的项目下的 .claude-plugin/ 目录里
适合放和这个项目深度绑定的插件源代码
your-project/
└── .claude-plugin/
└── plugin.json ← plugin 元数据
如果你只是想"使用"插件,记住安装位置在 ~/.claude/plugins/ 就够了
如果你要"开发"插件,记住 .claude-plugin/plugin.json 这个文件就够了
2. plugin.json
一个 Plugin 必须包含一个 plugin.json 文件,位于插件目录下的 .claude-plugin/plugin.json 路径
它和 Skills 的 SKILL.md 类似,都是用来描述这个东西"是什么、能做什么"
下面是一个最小化的示例:
{
"name": "my-plugin",
"version": "1.0.0",
"description": "这是一个演示插件",
"author": {
"name": "张三",
"email": "zhangsan@example.com"
}
}
只要这 4 个字段,一个最简 Plugin 就成型了
其中 name 是必填的,剩下的都是选填(但是建议都写上,方便别人识别)
plugin.json 里面还可以配置一堆字段,咱们这里先列举一下常用的
3. Plugin 完整目录
光有 plugin.json 还不够,Plugin 真正的"内容"在它的子目录里
一个完整的 Plugin 目录长这样:
my-plugin/
├── .claude-plugin/
│ └── plugin.json # 必填,插件元数据
├── commands/ # 可选,自定义斜杠命令
│ ├── deploy.md # /deploy 命令
│ └── format.md # /format 命令
├── agents/ # 可选,自定义 AI 代理
│ └── reviewer.md # 代码审查代理
├── skills/ # 可选,插件附带的 Skills
│ └── my-skill/
│ └── SKILL.md
├── hooks/ # 可选,生命周期 Hook
│ └── hooks.json
├── output-styles/ # 可选,输出风格定义
│ └── concise.md
├── .mcp.json # 可选,MCP 服务器配置
└── .lsp.json # 可选,LSP 语言服务器配置
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)