
Golang 实战 ELK 日志系统全流程教程(六):把 Logstash 加进日志链路
Golang 实战 ELK 日志系统全流程教程(六):把 Logstash 加进日志链路
上一篇我们已经跑通了一条最短链路:
Go -> logs/app.log -> Filebeat -> Elasticsearch -> Kibana
这条链路很适合刚开始做日志系统。组件少,问题也容易定位。Go 服务只要稳定输出一行一条 JSON,Filebeat 负责采集,Elasticsearch 负责存,Kibana 负责查,整个闭环就能跑起来。
这一篇要往前走一步,把 Logstash 加进来:
Go -> logs/app.log -> Filebeat -> Logstash -> Elasticsearch -> Kibana
这次的目标很明确:
Filebeat 不再直写 Elasticsearch
Filebeat 把日志发给 Logstash
Logstash 做字段加工、脱敏、类型转换
最后再写入 go-app-log-* 索引
先说清楚边界:这不是说所有项目都必须上 Logstash。如果日志格式已经很干净,只需要采集和查询,Filebeat 直写 ES 反而更轻。Logstash 的价值,通常是在日志开始变复杂以后才体现出来。
比如真实项目里经常会遇到这些情况:
手机号、token、邮箱要脱敏
老服务日志格式不统一
某些字段类型打错了,需要转换
不同 service_name 想写到不同索引
ERROR 日志想单独路由
Filebeat 带来的元数据字段太多,想清理一部分
这些事情放在 Go 应用里做,会把业务代码弄脏;放在 Filebeat 里做,又不是特别顺手。Logstash 更像日志链路中间的加工层,适合集中处理这类规则。
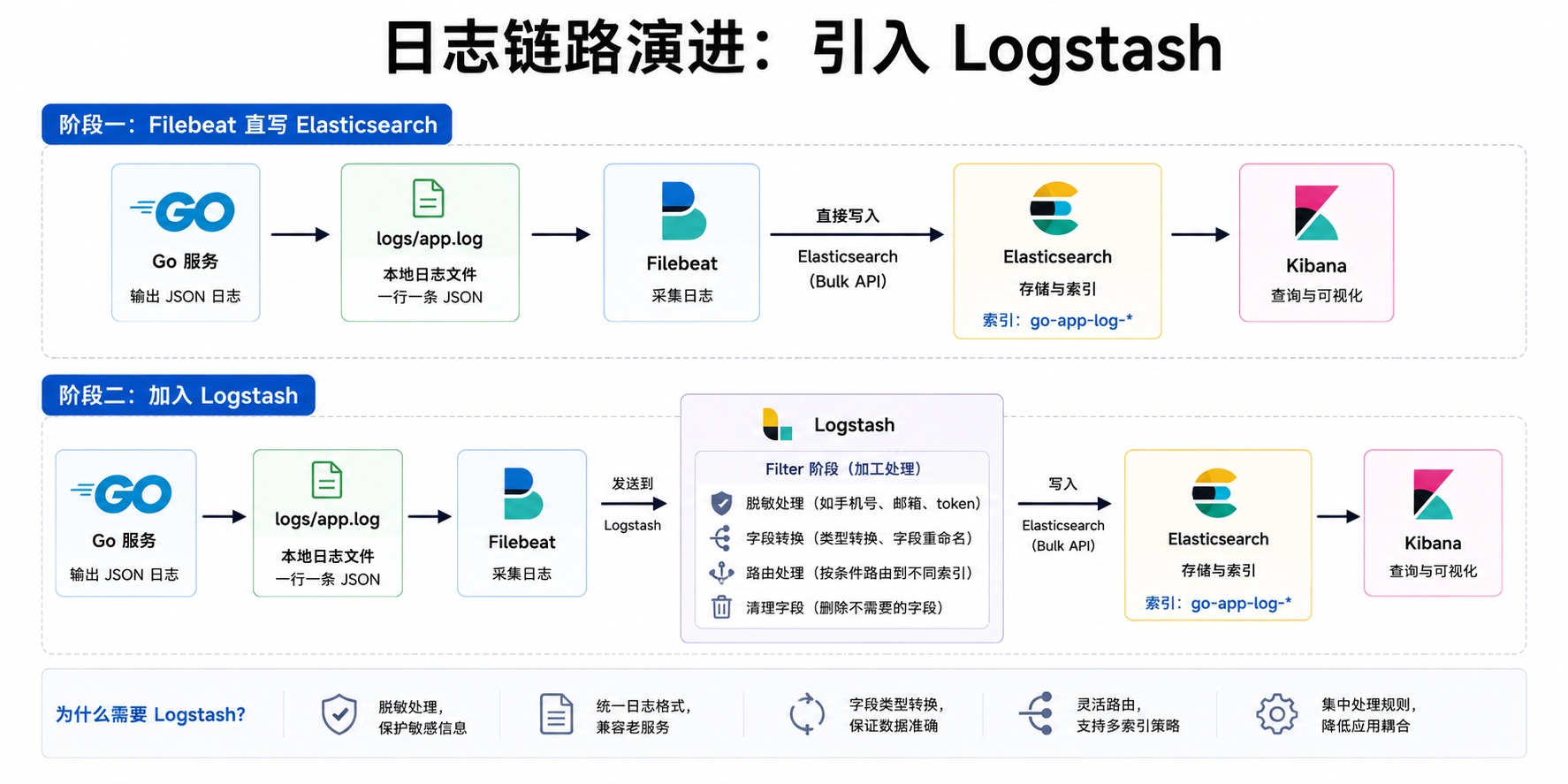
先理解 Logstash 在哪一层
Logstash 的模型可以先记成三段:
input -> filter -> output
input 负责接收数据。
filter 负责加工数据。
output 负责把数据发出去。
这三个词看起来像概念,但写配置时真的就是这三块。Filebeat 把事件发到 Logstash 的 input,Logstash 在 filter 里改字段、删字段、转类型,最后在 output 里写入 Elasticsearch。
这一篇先不追求复杂规则,先跑通一个最小可用版本。链路通了以后,再一点点补脱敏、类型转换和路由。
准备目录
沿用上一篇的 demo,目录可以整理成这样:
go-elk-demo
├── docker-compose.yml
├── logs
│ └── app.log
├── filebeat
│ └── filebeat.yml
└── logstash
└── pipeline.conf
logs/app.log 还是 Go 服务写出来的 JSON 日志。
filebeat/filebeat.yml 负责采集日志文件。
logstash/pipeline.conf 是这篇新增的 Logstash 管道配置。
这里默认 Elasticsearch 和 Kibana 仍然使用上一篇 demo 里的服务。
compose 里加 Logstash
先在 docker-compose.yml 里追加 Logstash 服务:
services:
logstash:
image: docker.elastic.co/logstash/logstash:${STACK_VERSION}
container_name: go-elk-logstash
ports:
- "5044:5044"
volumes:
- ./logstash/pipeline.conf:/usr/share/logstash/pipeline/logstash.conf:ro
environment:
- LS_JAVA_OPTS=-Xms512m -Xmx512m
depends_on:
elasticsearch:
condition: service_healthy
这里有几个点要注意。
5044 是 Beats input 常用端口。Filebeat 后面会把日志发到 logstash:5044。
pipeline.conf 挂载到容器里的 /usr/share/logstash/pipeline/logstash.conf。Logstash 默认会读取这个目录下的 pipeline 配置。
LS_JAVA_OPTS=-Xms512m -Xmx512m 是本地 demo 的写法。Logstash 是 JVM 应用,内存给太小容易慢,给太大本地电脑又吃紧。学习环境先给 512m,足够观察链路。
加完以后可以先校验 compose:
docker compose config
如果 YAML 缩进错了,这一步会比启动容器更早暴露问题。
Filebeat 改成输出到 Logstash
上一篇 Filebeat 是直写 Elasticsearch:
output.elasticsearch:
hosts: ["http://elasticsearch:9200"]
index: "go-app-log-%{+yyyy.MM.dd}"
现在要把输出改成 Logstash:
output.logstash:
hosts: ["logstash:5044"]
完整的 filebeat.yml 可以先这样写:
filebeat.inputs:
- type: filestream
id: go-app-log
enabled: true
paths:
- /logs/*.log
parsers:
- ndjson:
target: ""
overwrite_keys: true
add_error_key: true
output.logstash:
hosts: ["logstash:5044"]
这里还保留 filestream + ndjson,因为 Go 服务输出的仍然是一行一条 JSON。Filebeat 在采集阶段就把 JSON 展开成字段,然后把事件交给 Logstash。
注意一个容易漏的点:用了 Logstash output 以后,Filebeat 就不再直接负责写 ES 索引了。也就是说,上一篇里 setup.template.name、setup.template.pattern 这些配置不再是这条链路的重点。模板和索引治理后面会单独讲,这一篇先把链路跑通。
写第一版 pipeline.conf
先写一个最小版本,几乎不做加工,只加一个字段,方便确认日志确实经过了 Logstash:
input {
beats {
port => 5044
}
}
filter {
mutate {
add_field => {
"log_source" => "go-app"
}
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "go-app-log-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
beats { port => 5044 } 用来接收 Filebeat 发来的事件。
add_field 给每条日志加一个 log_source 字段。这个字段没什么复杂含义,就是为了验证 Logstash 的 filter 真的执行了。
stdout { codec => rubydebug } 是调试用的。我建议学习阶段先保留它。Logstash 收到什么、加工后变成什么样,能直接在容器日志里看到。
启动服务:
docker compose up -d logstash filebeat
看 Logstash 日志:
docker logs -f go-elk-logstash
再请求 Go 服务生成一条日志:
curl -X POST http://localhost:8080/api/orders
如果 Logstash 日志里打印出了 rubydebug 格式的事件,并且能看到 service_name、trace_id、level、message、log_source 这些字段,就说明 Filebeat 到 Logstash 已经通了。
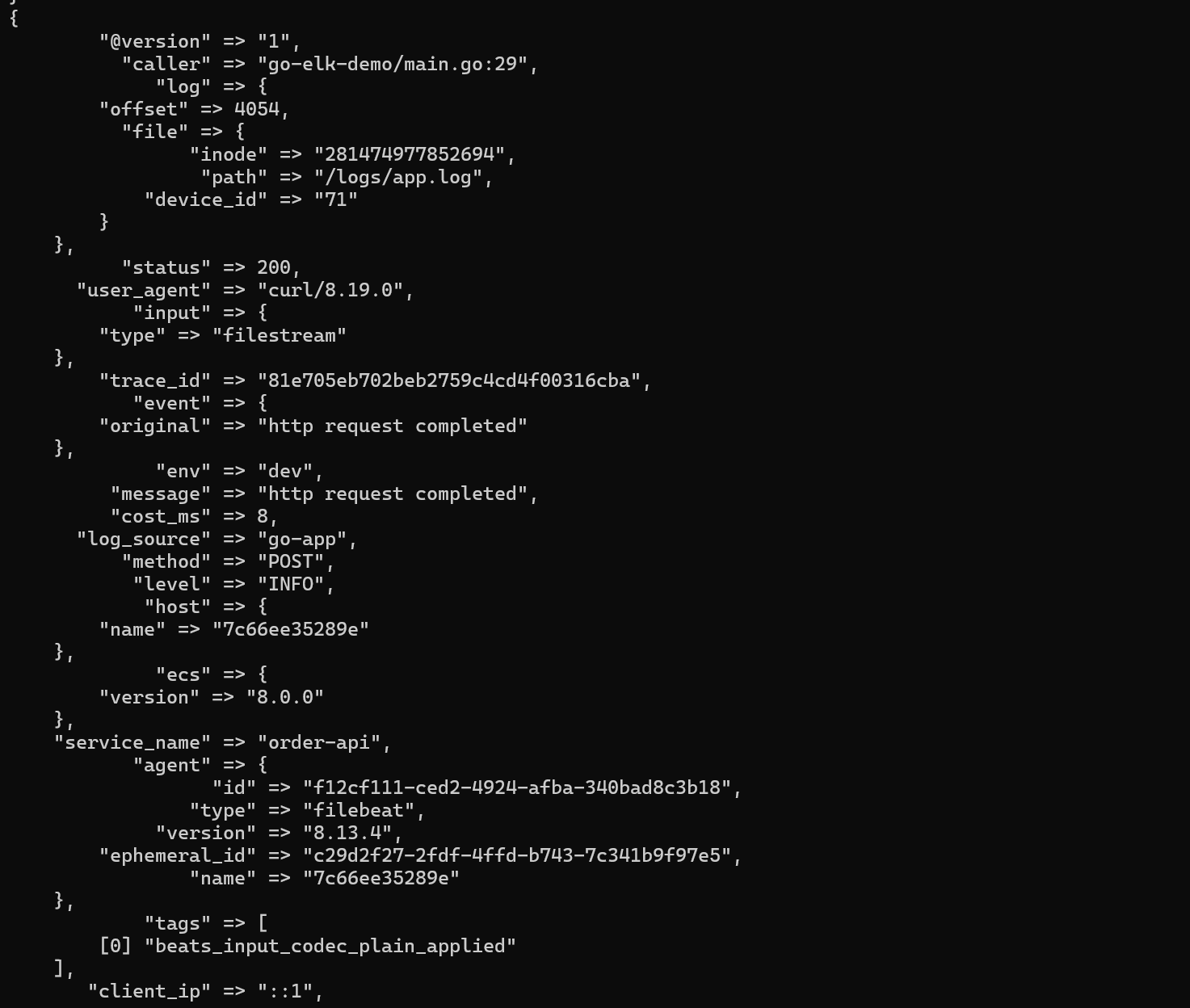
再查 Elasticsearch:
curl "http://localhost:9200/_cat/indices/go-app-log-*?v"
如果能看到 go-app-log-2026.xx.xx 这类索引,说明 Logstash 到 Elasticsearch 也通了。
做一个字段脱敏
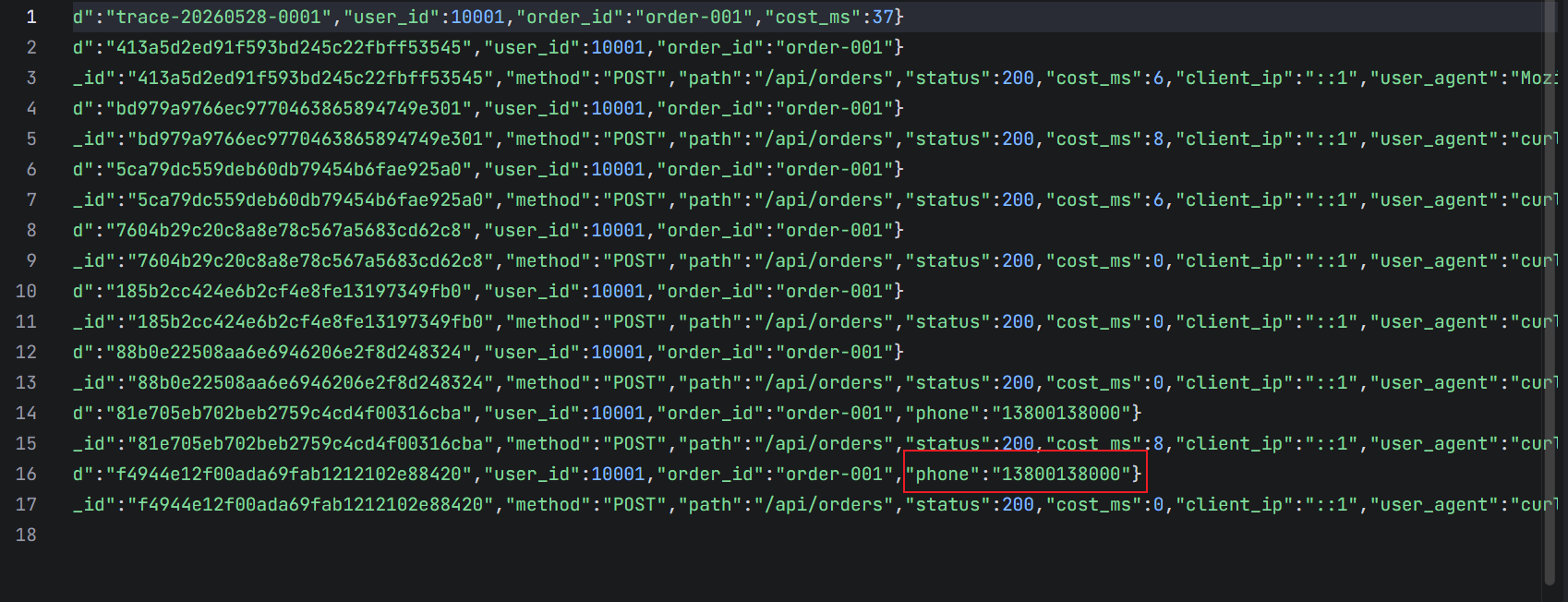
链路通了以后,再加一个真实一点的规则:手机号脱敏。
假设业务日志里有这样的字段:
{
"phone": "13800138000"
}
这种字段不应该原样进日志系统。很多团队一开始没注意,后面才发现 Kibana 里一搜全是敏感信息,再回头处理就很麻烦。
Logstash 可以用 mutate gsub 做一个简单脱敏:
filter {
if [phone] {
mutate {
gsub => [
"phone", "(\d{3})\d{4}(\d{4})", "\1****\2"
]
}
}
}
脱敏前:
13800138000
脱敏后:
138****8000
这只是 demo 级别的规则。真实项目里还会遇到身份证、邮箱、token、银行卡号,甚至嵌套 JSON 里的敏感字段。这里先不用一次写全,先确认 Logstash 适合做这类集中处理。
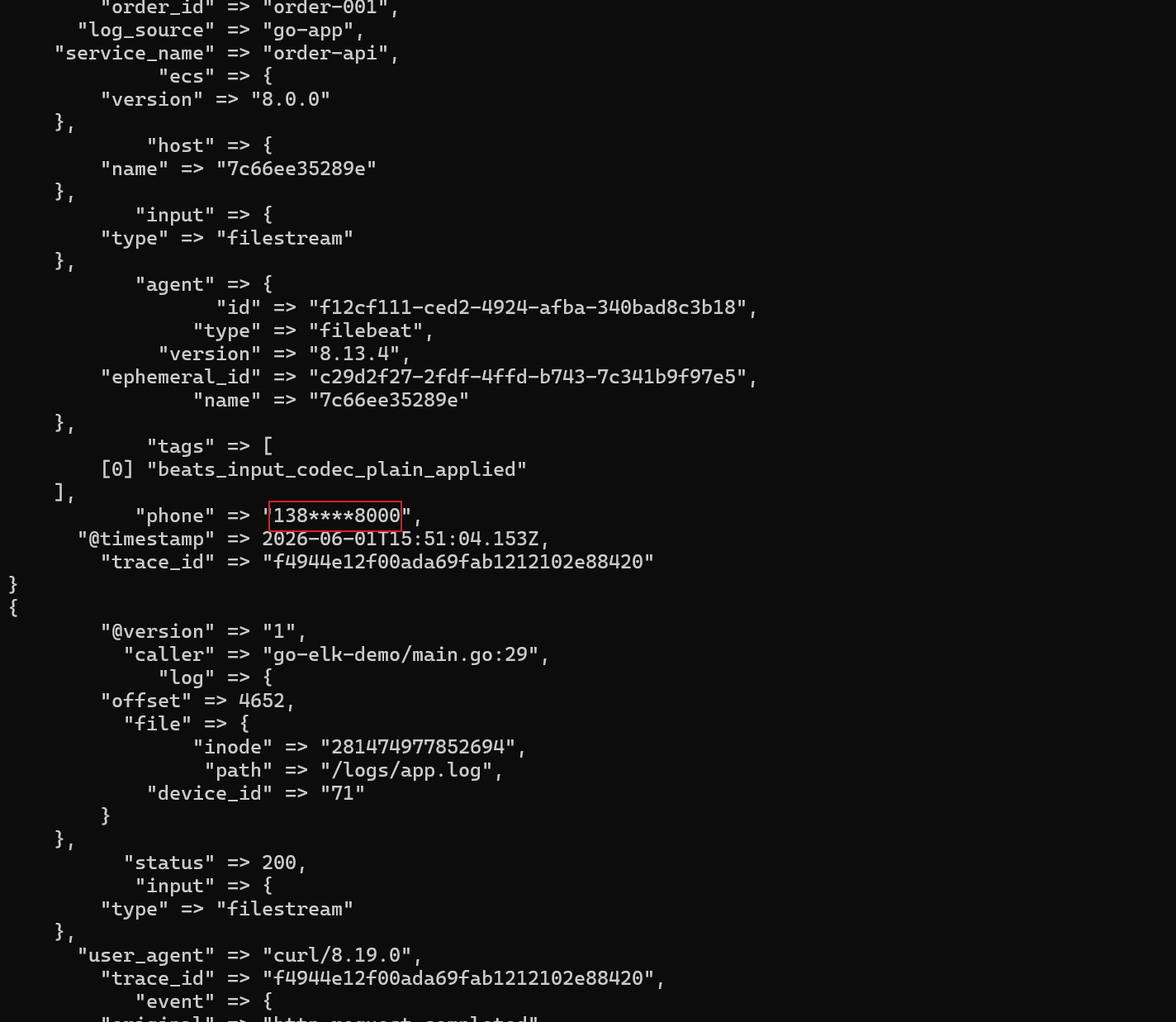
我个人不太喜欢把脱敏完全寄托在应用代码上。应用层当然要注意,但日志链路中间再兜一层,会更稳一点。
删除不想进入 ES 的字段
Filebeat 会带一些元数据字段,例如 agent、ecs、input、host。有些字段对排查有用,有些字段在本地 demo 里只是让结果看起来很乱。
如果想删掉一部分字段,可以这样写:
filter {
mutate {
remove_field => ["agent", "ecs", "input", "host"]
}
}
这个地方不要为了“干净”就一股脑全删。
host 在多机器排查时很有用,agent 能帮你确认采集器版本。学习环境可以删得干净一点,生产环境要按查询、排障、审计这些实际需求来决定。
做字段类型转换
有些旧服务打出来的日志字段是字符串:
{
"status": "500",
"cost_ms": "1200"
}
如果 Elasticsearch 动态映射把它们识别成 keyword,后面做范围查询会很难受:
cost_ms >= 1000
Logstash 可以在 filter 里转类型:
filter {
mutate {
convert => {
"status" => "integer"
"cost_ms" => "integer"
"user_id" => "integer"
}
}
}
不过这里也要保持清醒:更好的做法是应用侧一开始就打对类型。Logstash 可以兜底,但不应该变成上游日志随便打的借口。
按服务名路由到不同索引
前期所有服务都写一个索引最简单:
go-app-log-2026.05.28
然后用 service_name 过滤:
service_name: "order-api"
但服务多了以后,有些团队会希望按服务拆索引:
go-order-api-log-2026.05.28
go-user-api-log-2026.05.28
go-payment-worker-log-2026.05.28
Logstash 可以在 output 里判断字段:
output {
if [service_name] == "order-api" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "go-order-api-log-%{+YYYY.MM.dd}"
}
} else if [service_name] == "user-api" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "go-user-api-log-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "go-app-log-%{+YYYY.MM.dd}"
}
}
}
我不建议一开始就把索引拆得太碎。
拆索引有好处:权限、保留周期、查询范围都能更细。
代价也很明显:模板、ILM、Data View、Dashboard 都会变复杂。日志量不大的系统,用统一索引加 service_name 字段过滤通常就够了。
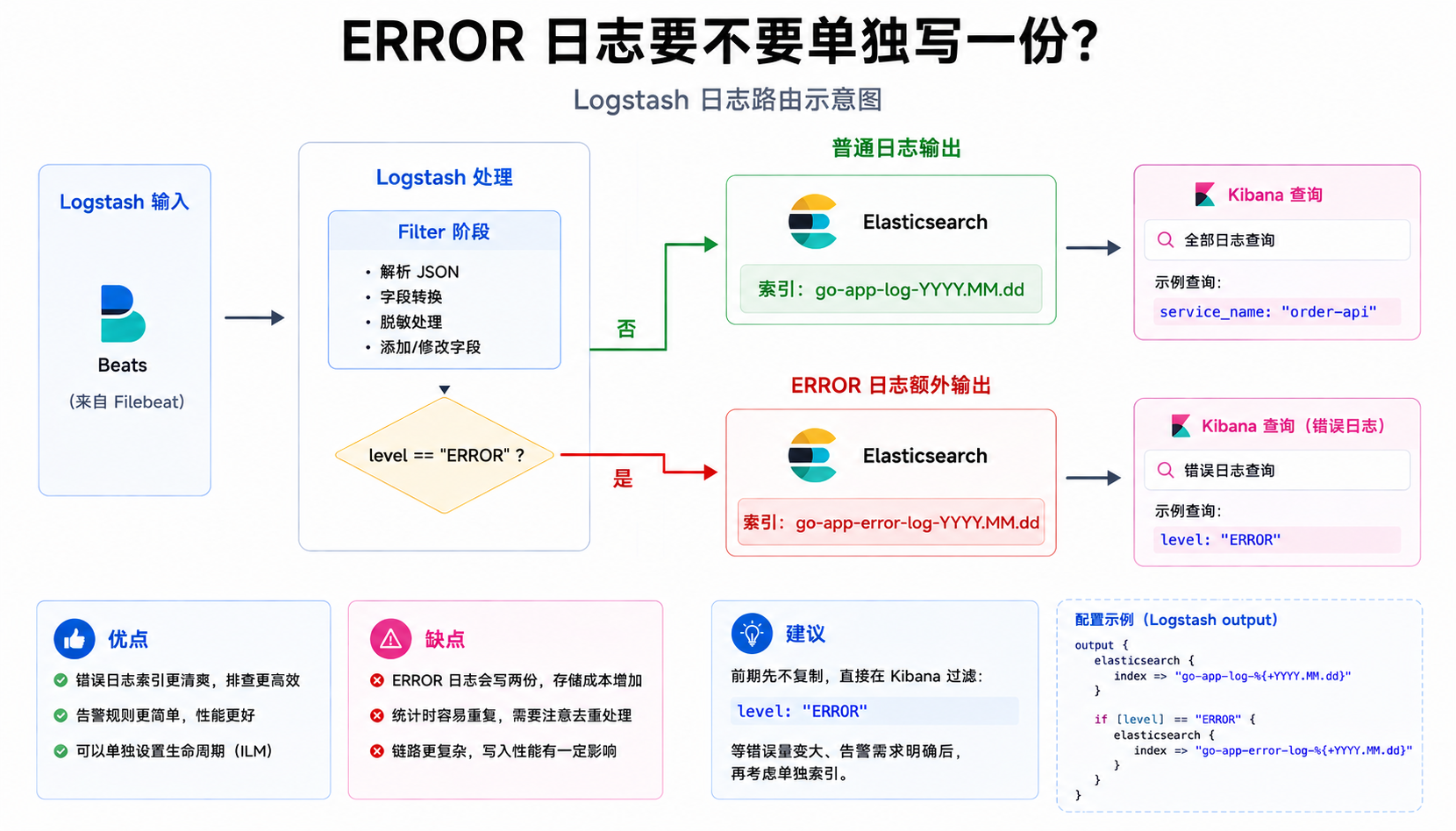
ERROR 日志要不要单独写一份
还有一种常见需求:错误日志写到单独索引,方便告警和排查。
配置可以这样写:
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "go-app-log-%{+YYYY.MM.dd}"
}
if [level] == "ERROR" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "go-app-error-log-%{+YYYY.MM.dd}"
}
}
}
这会让 ERROR 日志写两份。
优点是错误索引很清爽,后面做告警也方便。
缺点是存储会变多,而且一条日志存在两个索引里,后面统计时要避免重复计算。
我现在更倾向于前期先不复制,直接在 Kibana 里用条件过滤:
level: "ERROR"
等错误量真的大了、告警需求也明确了,再考虑单独索引。
这一篇先用的完整 pipeline
把前面的几个规则合起来,这一篇可以先用下面这版:
input {
beats {
port => 5044
}
}
filter {
mutate {
add_field => {
"log_source" => "go-app"
}
}
if [phone] {
mutate {
gsub => [
"phone", "(\d{3})\d{4}(\d{4})", "\1****\2"
]
}
}
mutate {
convert => {
"status" => "integer"
"cost_ms" => "integer"
"user_id" => "integer"
}
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "go-app-log-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
这版做了三件事:
给日志加 log_source
如果有 phone 字段就脱敏
把 status、cost_ms、user_id 转成 integer
它没有做复杂路由,也没有删除 Filebeat 元数据字段。原因很简单:这一篇的重点是把 Logstash 放进链路,并确认它能稳定加工日志。其他策略可以后面再加。
验证链路
启动:
docker compose up -d elasticsearch kibana logstash filebeat
启动 Go 服务:
go run .
请求接口生成日志:
curl -X POST http://localhost:8080/api/orders
看本地日志文件:
tail -n 5 logs/app.log
Windows PowerShell 可以用:
Get-Content .\logs\app.log -Tail 5
看 Logstash 是否收到事件:
docker logs -f go-elk-logstash
查 Elasticsearch 索引:
curl "http://localhost:9200/_cat/indices/go-app-log-*?v"
查具体文档:
curl "http://localhost:9200/go-app-log-*/_search?pretty"
如果结果里能看到 log_source,说明日志经过了 Logstash 的 filter。
如果能看到 status、cost_ms 这些字段正常存在,说明 Go 日志里的业务字段也被保留下来了。
【图片占位】【Elasticsearch 查询结果截图:go-app-log-* 索引中的文档包含 service_name、trace_id、level、message、status、cost_ms、log_source,说明 Logstash 已经完成加工并写入 ES】
排查 Logstash 时先看三段
Logstash 出问题时,不要一上来就改配置。先按管道三段排查。
第一段:input 有没有收到。
docker logs -f go-elk-logstash
如果 stdout rubydebug 完全没输出,先看 Filebeat 到 Logstash 的网络和端口。重点检查 output.logstash.hosts 是否写成了 logstash:5044,以及 Logstash 容器是否正常启动。
第二段:filter 有没有写坏。
Logstash 配置对括号、引号、字段路径都比较敏感。有时候只是少了一个 },容器就会启动失败。先看 Logstash 日志,不要凭感觉改。
第三段:output 有没有写进 ES。
curl "http://localhost:9200/_cat/indices/go-app-log-*?v"
如果 Logstash 已经打印了事件,但 ES 里没有索引,重点看 Elasticsearch output 的报错,比如连接失败、索引名不合法、字段映射冲突。
这一篇的边界
到这里,日志链路已经从:
Go -> Filebeat -> Elasticsearch
演进成:
Go -> Filebeat -> Logstash -> Elasticsearch
这个变化的意义不是“组件更多了”,而是日志系统开始有了统一加工层。
但我还是想强调:不是所有项目都必须上 Logstash。
如果你的日志是标准 JSON,只需要采集、查询、简单看板,Filebeat 直写 ES 更轻。
Logstash 更适合这些场景:
日志格式不统一
需要集中脱敏
需要复杂路由
需要字段转换
需要兼容旧系统日志
下一篇要处理一个更容易被低估的问题:Elasticsearch 索引治理。
日志能写进去,不代表日志系统就稳定了。字段类型错了、索引无限增长、磁盘没有保留策略,这些问题一般不会第一天爆,但它会在你以为系统已经没问题的时候回来找你。
参考资料:
更多推荐


 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)