
Python sqlite3 极简教程
本文主要介绍如何使用Python的sqlite3标准库操作SQLite数据库文件,帮助大家快速上手
0. 简介
SQLite是一种用C语言编写的非常轻量的数据库,所有内容都集成在一个.db文件中
一个 .db 文件就是一个数据库
Python标准库里的 sqlite3 可以很方便的结合SQL语句操作SQLite数据库文件
由于属于Python标准库,所以我们不需要额外的安装命令
直接 import sqlite3 即可
在数据库操作中,我们的行为常被叫做 CRUD ,或者说增删改查
(其实叫 增查改删 才和字母能对应上)
所以接下来我也会分成这4个部分来介绍
- C,Create
- R,Read
- U,Update
- D,Delete
Python 操作 SQLite 数据库基本流程:
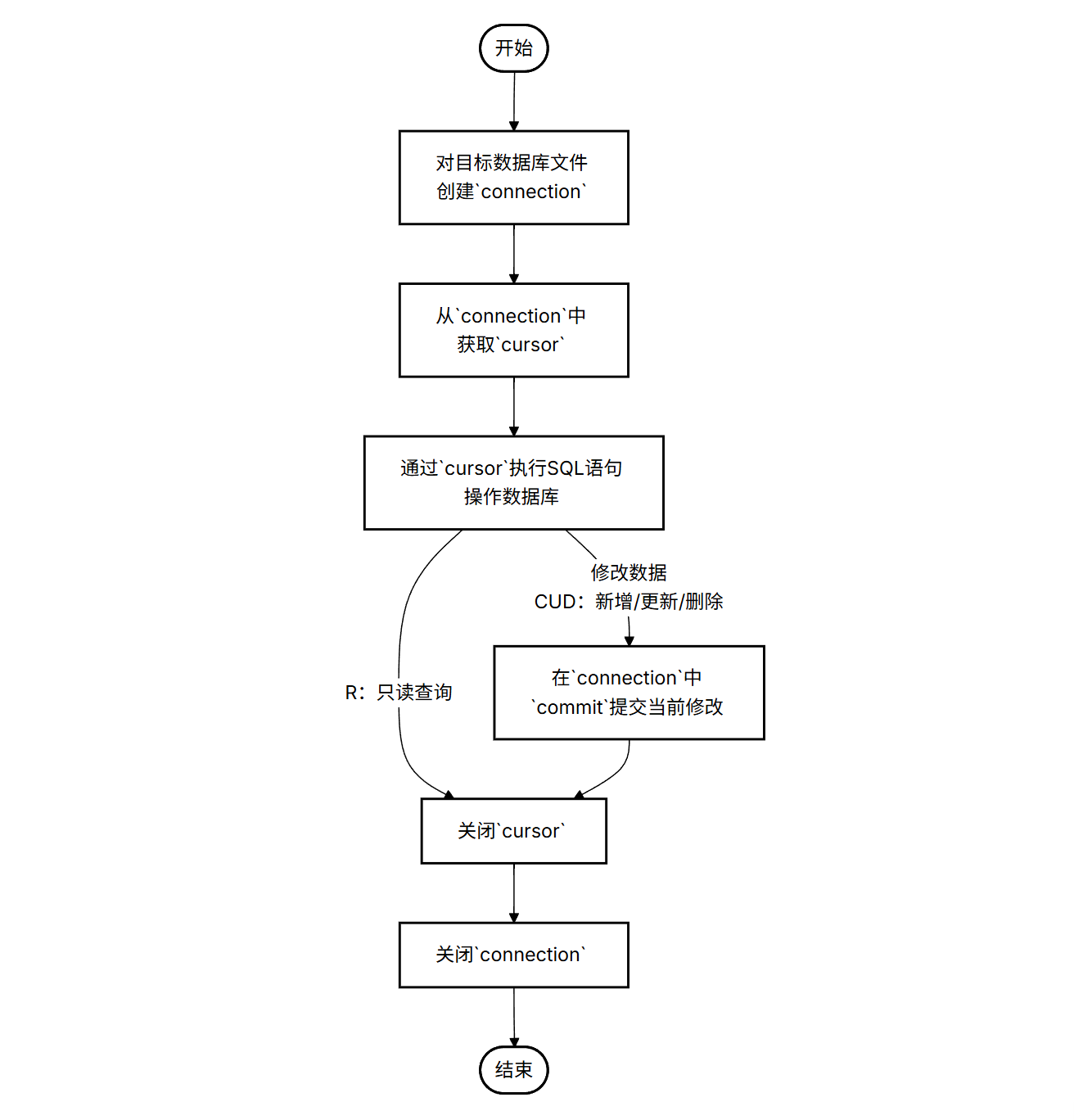
1. Create 新增数据
1.1 创建数据库(database)、数据表(table)
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
connection = sqlite3.connect('test.db') # 数据库文件名为`test.db`
# 创建一个cursor用来操作数据,一个`游标对象`
cursor = connection.cursor()
# 编写创建新数据表的SQL语句
sql_create_table = '''
CREATE TABLE user(id INTEGER PRIMARY KEY, name TEXT);
'''
cursor.execute(sql_create_table) # 执行SQL语句
cursor.close() # 关闭游标
connection.close() # 关闭连接
执行完以后你会发现运行代码的同级目录下会多一个 test.db 文件
如果再次运行会报错,不是因为 test.db 文件已存在
而是因为这个数据库里已经有一个叫 user 的数据表了,不能再创建一个一样的表了
每个 connection 和 cursor 用完都要记得关闭,养成好习惯
理论上,每个SQLite数据库的 .db 文件可以创建多个 connection,多个 cursor
大家可以自行向AI咨询相关知识
本文只介绍一个 connection 一个 cursor 的简单使用方法
建议:
要执行的SQL语句,可以创建一个单独的变量保存,变量名推荐 sql_+功能简介
使用三单引号包裹内容 (三双引号表示函数docstring,所以不用它)
三引号可以跨行编写字符串,并且不需要对字符串中的其它引号进行转义
因为SQL语句往往很多行,并且语法和Python代码类似但又不同
如果直接把SQL字符串写在 execute 的括号里,可读性差
注意每条SQL语句后要加英文分号 ;
SQL语句实际上是不区分大小写的,但是为了可读性和代码维护方便
推荐把关键字用全大写,其它用全小写
SQLite数据类型: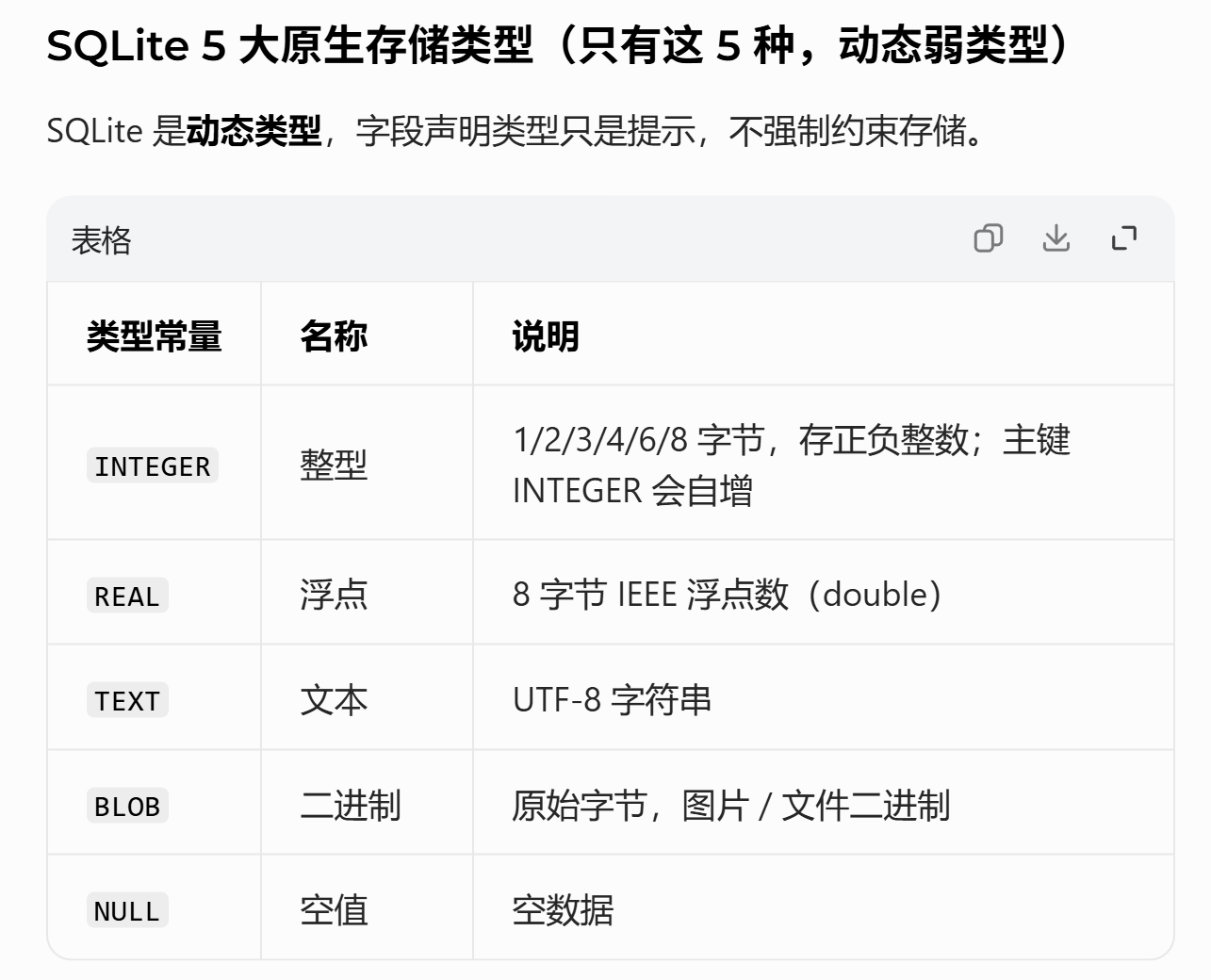
遇到不太理解的大家可以自行咨询AI,我尽量简洁一点
1.2 插入(新增)数据到数据表中
插入(新增)数据的SQL语法格式为INSERT INTO 表名(字段名1, 字段名2, ..., 字段名n) VALUES(字段值1, 字段值2, ..., 字段值n)
示例代码:
import sqlite3
# 创建与数据库文件的链接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
connection = sqlite3.connect('test.db') # 数据库文件名为`test.db`
# 创建一个cursor用来操作数据,一个`游标对象`
cursor = connection.cursor()
# 编写 插入新数据 到 数据表 的SQL语句
sql_insert = '''
INSERT INTO user(id, name) VALUES(1, 'xiao');
INSERT INTO user(id, name) VALUES(2, 'tian');
INSERT INTO user(id, name) VALUES(3, '小天');
'''
cursor.executescript(sql_insert) # 执行SQL语句
connection.commit()
cursor.close()
connection.close()
当我们的SQL语句有多行时,需要使用 cursor.executescript() 方法cursor.execute() 只能执行一行SQL语句
在SQL语句中,字符串字面量用单引号 '' 包裹
当我们修改数据(增、改、删)之后,可以使用 connection.commit() 提交操作,如果操作失败数据库会自动回退到修改之前
下面这种写法其实是不安全且比较啰嗦的写法
sql_insert = '''
INSERT INTO user(id, name) VALUES(1, 'xiao');
INSERT INTO user(id, name) VALUES(2, 'tian');
INSERT INTO user(id, name) VALUES(3, '小天');
'''
cursor.executescript(sql_insert) # 执行SQL语句
用Python操作数据库时应该用 ? 占位,防止SQL注入 (大家自行AI一下)
更推荐的写法是:
sql_insert = '''
INSERT INTO user(id,name) VALUES(?, ?);
'''
data = [(1, "xiao"), (2, "tian"), (3, "小天")]
cursor.executemany(sql_insert, data)
批量插入数据时优先使用 cursor.executemany
它只接收一行SQL语句,然后使用数据列表中的每个元组作为参数值
重复执行多次该SQL语句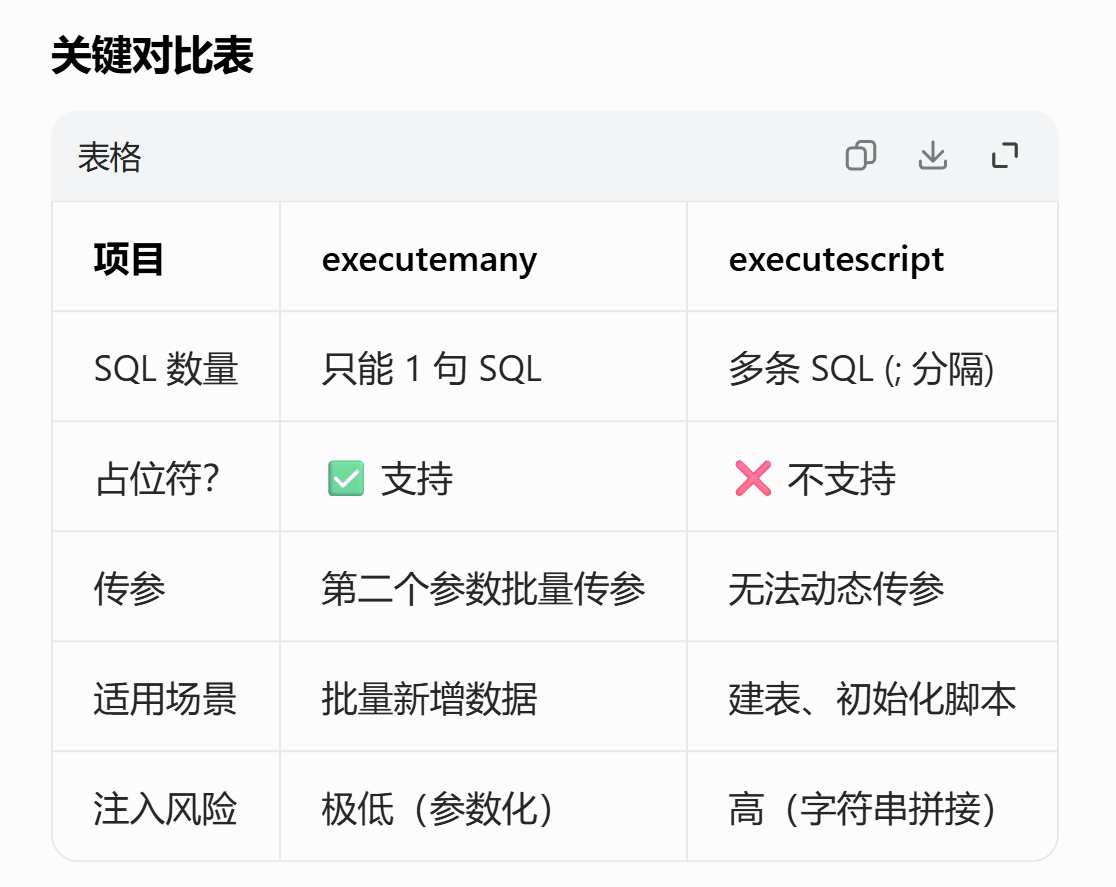
由于需要频繁修改代码测试,大家报错了可以直接把数据库文件删了
用代码重新创建数据库、表并插入数据
总结代码:
import sqlite3
# 创建与数据库文件的链接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
connection = sqlite3.connect('test.db') # 数据库文件名为`test.db`
# 创建一个cursor用来操作数据,一个`游标对象`
cursor = connection.cursor()
# 编写 创建新数据表 的SQL语句
sql_create_table = '''
CREATE TABLE user(id INTEGER PRIMARY KEY, name TEXT);
'''
cursor.execute(sql_create_table) # 执行SQL语句
# 编写 插入新数据 到 数据表 的SQL语句
sql_insert = '''
INSERT INTO user(id, name) VALUES(?, ?);
'''
data = [(1, "xiao"), (2, "tian"), (3, "小天")]
cursor.executemany(sql_insert, data) # 执行SQL语句
connection.commit() # 提交
cursor.close()
connection.close()
2. Read 读取数据
在SQL语句中,查看数据用的是 SELECT 这个关键词,select 这个英文单词的意思 “挑选、筛选”
因为数据库读取数据不是直接读取全部数据,而是按条件挑选数据
查看数据的SQL语法格式:SELECT 字段名1, 字段名2, ..., 字段名n FROM 表名 WHERE 查询条件
示例代码:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
connection = sqlite3.connect('test.db') # 数据库文件名为`test.db`
# 创建一个cursor用来操作数据,一个`游标对象`
cursor = connection.cursor()
# 编写 查看数据 的SQL语句
sql_select = '''
SELECT * FROM user;
'''
cursor.execute(sql_select) # 执行查询SQL,服务端暂存匹配结果,数据未载入Python内存
result = cursor.fetchall() # 将数据加载到Python程序当中
print(result)
cursor.close()
connection.close()
可以把test.db数据库文件删了,我们和之前的代码融合一下,重头来一遍:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
connection = sqlite3.connect('test.db') # 数据库文件名为`test.db`
# 创建一个cursor用来操作数据,一个`游标对象`
cursor = connection.cursor()
# 编写 创建新数据表 的SQL语句
sql_create_table = '''
CREATE TABLE user(id INTEGER PRIMARY KEY, name TEXT);
'''
cursor.execute(sql_create_table) # 执行SQL语句
# 编写 插入新数据 到 数据表 的SQL语句
sql_insert = '''
INSERT INTO user(id, name) VALUES(?, ?);
'''
data = [(1, "xiao"), (2, "tian"), (3, "小天")]
cursor.executemany(sql_insert, data) # 执行SQL语句
connection.commit() # 提交
# 编写 查看数据 的SQL语句
sql_select = '''
SELECT * FROM user;
'''
cursor.execute(sql_select) # 执行查询SQL,服务端暂存匹配结果,数据未载入Python内存
result = cursor.fetchall() # 将数据加载到Python程序当中
print(result)
cursor.close()
connection.close()
其实代码是有一点长的,当逻辑较复杂,代码较多时会容易忘记 commit 或者忘记close cursor 和 connection
这个时候 Python 的 with 语句就起到一个十分方便的作用了sqlite3 库中的 connection 对象是支持 with 语法的,在 with 语句结束后会自动 commit 、close 对应的 connection
但是 cursor 类型的对象暂不支持 with 语法
(删掉 test.db 后重新运行) 示例代码:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
with sqlite3.connect('test.db') as connection: # 数据库文件名为`test.db`
# 创建一个cursor用来操作数据,一个`游标对象`
cursor = connection.cursor()
# 编写 创建新数据表 的SQL语句
sql_create_table = '''
CREATE TABLE user(id INTEGER PRIMARY KEY, name TEXT);
'''
cursor.execute(sql_create_table) # 执行SQL语句
# 编写 插入新数据 到 数据表 的SQL语句
sql_insert = '''
INSERT INTO user(id, name) VALUES(?, ?);
'''
data = [(1, "xiao"), (2, "tian"), (3, "小天")]
cursor.executemany(sql_insert, data) # 执行SQL语句
# 编写 查看数据 的SQL语句
sql_select = '''
SELECT * FROM user;
'''
cursor.execute(sql_select) # 执行查询SQL,服务端暂存匹配结果,数据未载入Python内存
result = cursor.fetchall() # 将数据加载到Python程序当中
print(result)
cursor.close()
省略了 connection 的 commit 和 close 两个部分
但是代码还是很长,其实我们可以把 cursor 的部分也省略掉
我们现在是手动创建 cursor 并手动关闭,并且通过我们创建的 cursor 来执行SQL语句
但是,实际上 connection 对象也可以直接执行SQL语句,它内部会创建一个临时 cursor 并在语句执行结束后返回该 cursor ,如果没有通过变量保存返回的 cursor ,相当于这个 cursor 用完后被丢弃
(删掉 test.db 后重新运行) 示例代码:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
with sqlite3.connect('test.db') as connection: # 数据库文件名为`test.db`
# 编写 创建新数据表 的SQL语句
sql_create_table = '''
CREATE TABLE user(id INTEGER PRIMARY KEY, name TEXT);
'''
connection.execute(sql_create_table) # 执行SQL语句
# 编写 插入新数据 到 数据表 的SQL语句
sql_insert = '''
INSERT INTO user(id, name) VALUES(?, ?);
'''
data = [(1, "xiao"), (2, "tian"), (3, "小天")]
connection.executemany(sql_insert, data) # 执行SQL语句
# 编写 查看数据 的SQL语句
sql_select = '''
SELECT * FROM user;
'''
# 执行查询SQL,服务端暂存匹配结果,数据未载入Python内存
cursor = connection.execute(sql_select) # 保存返回的cursor
result = cursor.fetchall() # 将数据加载到Python程序当中
print(result)
connection 执行SQL语句的方法名和 cursor 的一样execute 、executemany、executescript
注意,读取数据时必须通过 cursor 类型的对象才能 fetch
所以,需要保存 connection 执行查询操作后返回的 cursor
读取数据部分的代码也可以通过方法链简写为:
# 编写 查看数据 的SQL语句
sql_select = '''
SELECT * FROM user;
'''
# 执行查询SQL,并将数据加载到Python程序当中
result = connection.execute(sql_select).fetchall()
print(result)
cursor 类型对象获取已选择的数据,除了 fetchall ,还有 fetchone ,fetchmany
| 方法 | 返回值 | 读取逻辑 | 适用场景 | 优缺点 |
|---|---|---|---|---|
| fetchone() | 单行元组 / None | 读取游标下一行; 无数据返回 None |
大数据逐行遍历、流式读取 | 内存占用极小; 需要循环处理 |
| fetchmany(size) | 多行元组列表 | 读取后续 size 行,默认size=1; 无数据返回空列表 |
分页查询、分批处理大量数据 | 可控内存负载,可自定义批次数量 |
| fetchall() | 全部结果元组列表 | 一次性读取游标剩余所有行; 无数据返回空列表 |
数据量小,需要一次性拿到全部结果 | 代码最简; 数据量大时内存占用高 |
确保数据库、数据表、数据都已存在,运行示例代码:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
with sqlite3.connect('test.db') as connection: # 数据库文件名为`test.db`
# 编写 查看数据 的SQL语句
sql_select = '''
SELECT * FROM user;
'''
# 执行查询SQL,并将数据加载到Python程序当中
result = connection.execute(sql_select).fetchall()
print(result) # 打印结果:[(1, 'xiao'), (2, 'tian'), (3, '小天')]
# 上一个cursor已被丢弃,需要重新创建
cursor = connection.execute(sql_select)
print(cursor.fetchone()) # 打印结果:(1, 'xiao')
print(cursor.fetchone()) # 打印结果:(2, 'tian')
# 上一个cursor位置已经移动到第3条数据前面,想要重新读取,需要移动cursor或重新创建
cursor = connection.execute(sql_select)
print(cursor.fetchmany(2)) # 打印结果:[(1, 'xiao'), (2, 'tian')]
3. Update 更新(修改)数据
SQL语法格式:UPDATE 表名 SET 字段名 = 字段值 WHERE 查询条件
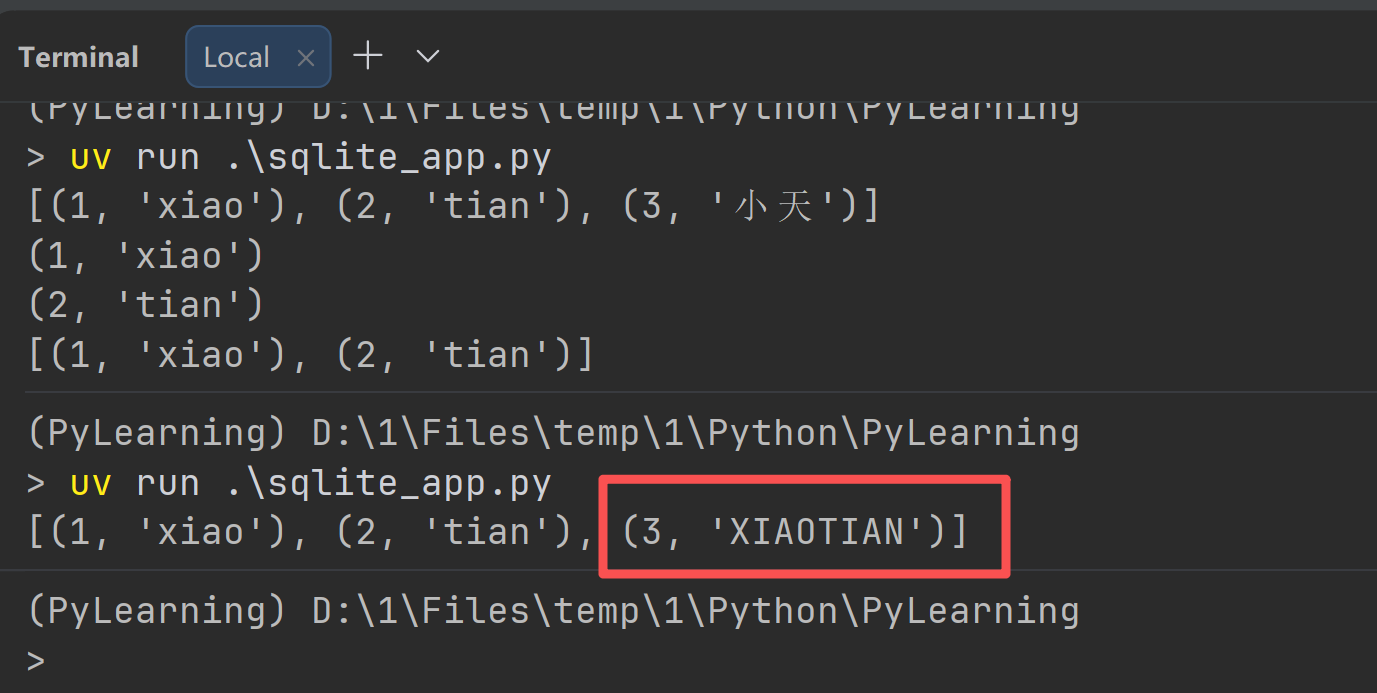
示例代码1:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
with sqlite3.connect('test.db') as connection: # 数据库文件名为`test.db`
# 编写 更新数据 的SQL语句
sql_update = '''
UPDATE user SET name = ? WHERE id = ?;
'''
connection.execute(sql_update, ('XIAOTIAN', 3))
sql_select = '''
SELECT * FROM user;
'''
result = connection.execute(sql_select).fetchall()
print(result)
示例代码2:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
with sqlite3.connect('test.db') as connection: # 数据库文件名为`test.db`
# 编写 更新数据 的SQL语句
sql_update = '''
UPDATE user SET name = ? WHERE id = ?;
'''
params = [('xiao', 1), ('tian', 2), ('XIAOTIAN', 3)]
connection.executemany(sql_update, params)
sql_select = '''
SELECT * FROM user;
'''
result = connection.execute(sql_select).fetchall()
print(result)
4. Delete 删除数据
SQL语法格式:DELETE FROM 表名 WHERE 查询条件
示例代码:
import sqlite3
# 创建与数据库文件的连接(connection),一个`连接对象`
# 如果这个数据库不存在,那么会自动创建一个新的数据库
with sqlite3.connect('test.db') as connection: # 数据库文件名为`test.db`
# 编写 删除数据 的SQL语句
sql_delete = '''
DELETE FROM user WHERE id = ?;
'''
connection.execute(sql_delete, (3,))
sql_select = '''
SELECT * FROM user;
'''
result = connection.execute(sql_select).fetchall()
print(result) # 打印结果:[(1, 'xiao'), (2, 'tian')]
注意,即使只有一个参数,也要保证传入的是元组类型
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)