
【中小学AI人工智能教育】声音分类——提琴分类:快速定义项目类型实例
Ai创想实验室是专门为中小学AI教育开发的教学平台,包含了值计算、图像分类、音频分类、文本分类、数值回归、图像回归、图像分类+回归、平衡杆、手写数字生成、文本生成等中小学人工智能学习类项目。无需编程基础、无需添加硬件、无需购买算力、无隐私担忧、无需师资培训即可进行教学实践。
在Ai创想实验室中,可以使用后台管理功能快速定义已有项目类型的实例。之前,我们介绍了如何使用0-9音频数据集来进行音频分类实验;现在,我们介绍如何在后台构建一个类型相同而数据不同的实例以实现“个性化”实验教学。
一、构建新项目实例
进入管理后台→项目管理选项卡→点击“新建项目”,填写必填内容,而后点击“创建项目”:
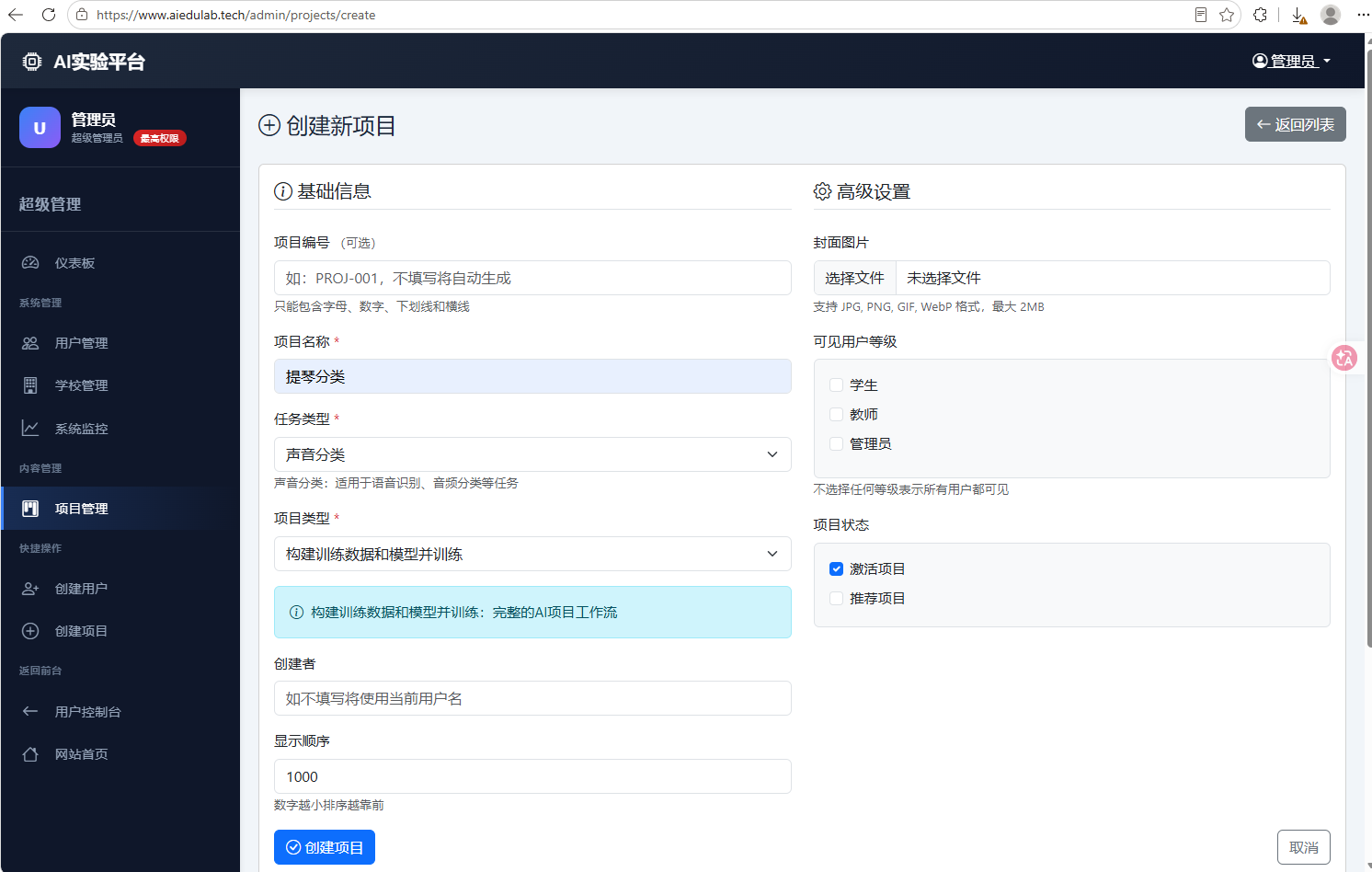
这样就得到了一个新的项目,在前台可以看到该项目。在后台项目管理页中,点击该项目的“编辑”按钮,进入编辑界面,在这里我们可以更改相关信息:
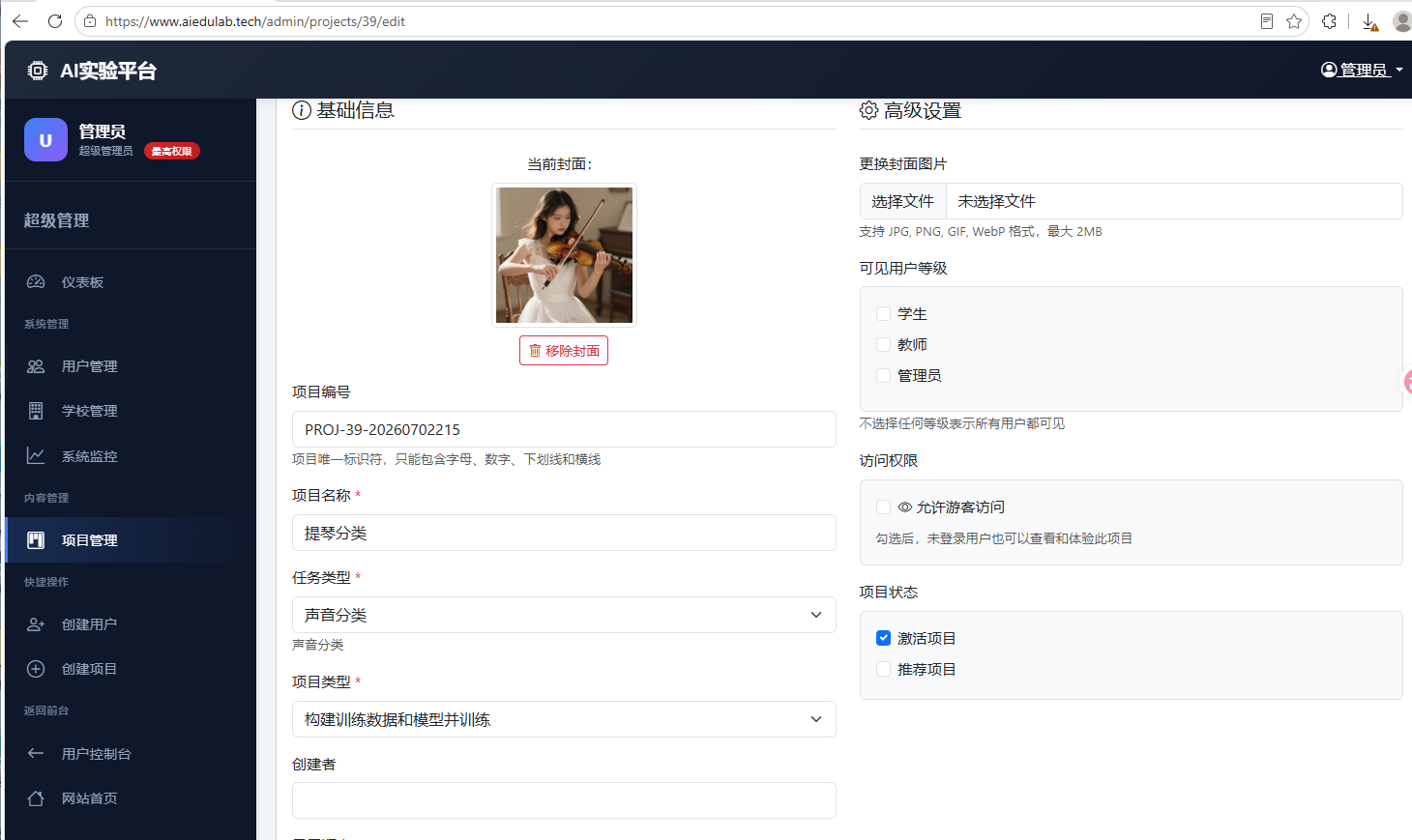
当我们完成示例数据构建之后,也从该页面上传数据。修改后,点击“保存更改”即可。
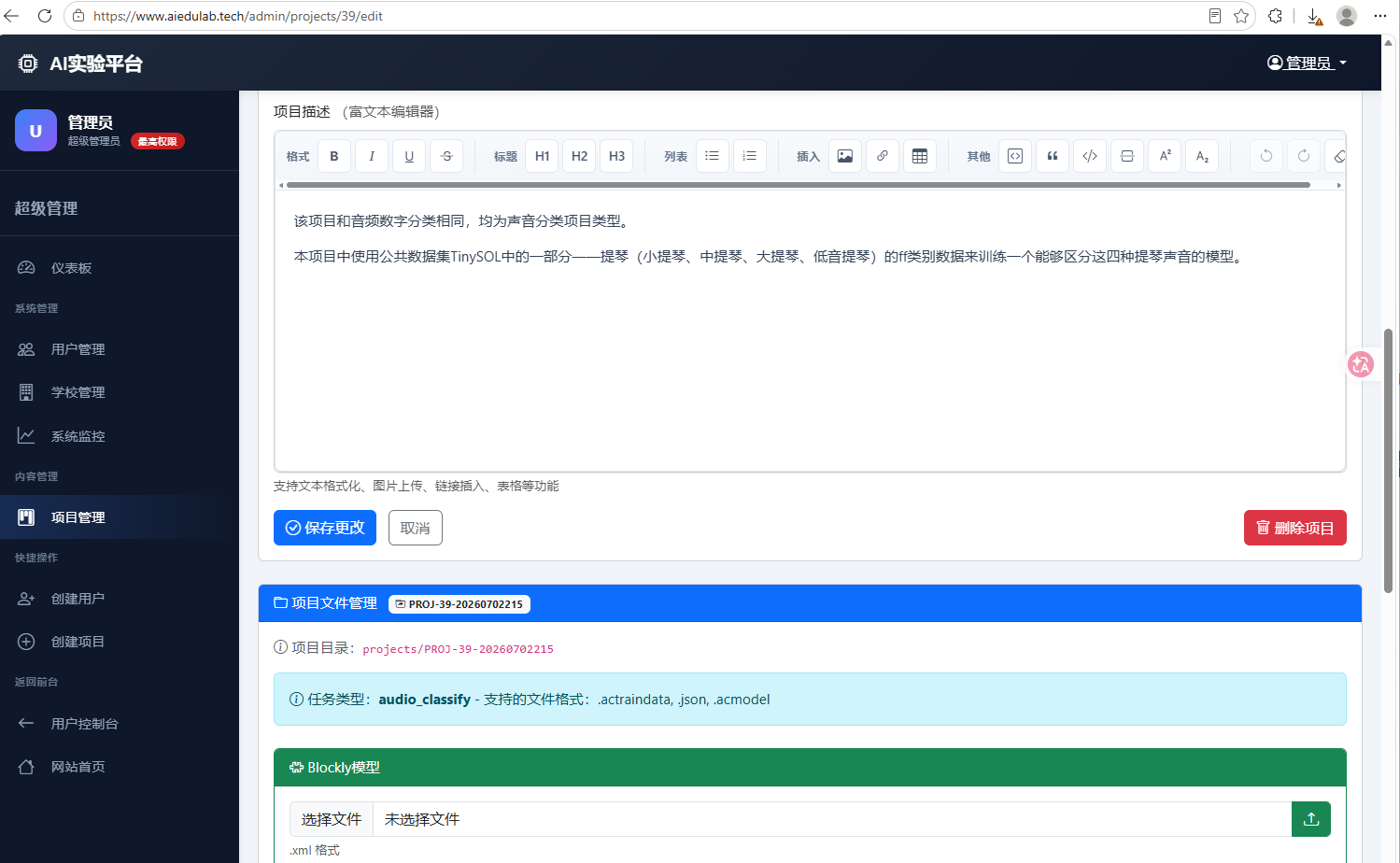
可见,如果不制作示例数据,只需不到一分钟就可以创建一个项目实例。一般来说,在教学中我们会跑完整个流程再回来上传示例数据,上传过程也不会超过一分钟。
二、在管理页面构建示例数据
和在项目页面相同,在后台项目管理中点击该项目后的“项目工具”按钮打开工具页面,该页面和项目页面底部的工具完全一致。
对于音频分类模型,通常我们先对数据进行清洗——因为我们需要知道梅尔谱图的大小来确定模型输入参数。当然,对于普通数据来说,使用界面上的默认设置完全可行,即:使用none,64,59,1这样的参数——批次大小由训练器决定,图像宽度为64,高度为59,单通道:
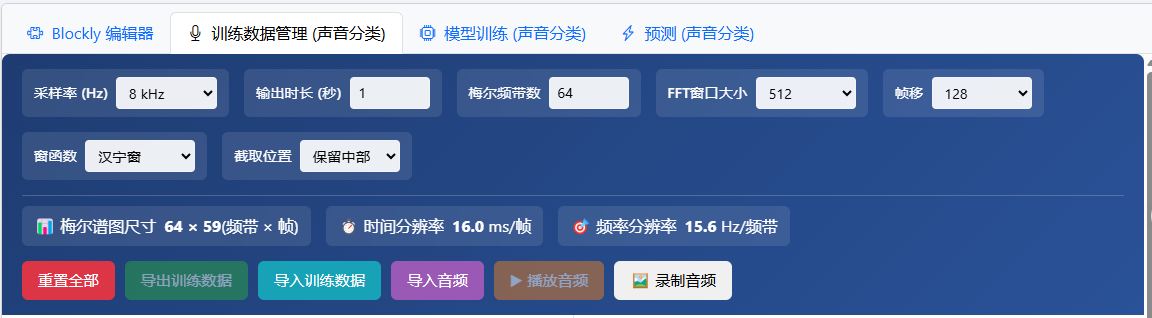
而后,我们需要获取数据并进行清洗。如果你使用相同的方法,那么搜索TinySOL数据集并下载,而后用以下脚本进行清洗即可(脚本重建了文件夹并汉化,提取声音较强的ff数据):
import os
import shutil
from pathlib import Path
# 乐器英文名到中文名的映射表(完整版)
INSTRUMENT_MAP = {
# === 弦乐器 (Strings) ===
'Violin': '小提琴',
'Viola': '中提琴',
'Violoncello': '大提琴',
'Contrabass': '低音提琴',
'DoubleBass': '低音提琴',
'Guitar': '吉他',
'Harp': '竖琴',
'Mandolin': '曼陀林',
'Banjo': '班卓琴',
'Ukulele': '尤克里里',
# === 木管乐器 (Winds) ===
'Flute': '长笛',
'Piccolo': '短笛',
'Oboe': '双簧管',
'EnglishHorn': '英国管',
'Clarinet': '单簧管',
'Clarinet_Bb': '降B调单簧管',
'BassClarinet': '低音单簧管',
'Saxophone': '萨克斯',
'Sax_Alto': '中音萨克斯',
'Sax_Tenor': '次中音萨克斯',
'Sax_Baritone': '上低音萨克斯',
'Sax_Soprano': '高音萨克斯',
'Bassoon': '巴松管',
'Recorder': '竖笛',
# === 铜管乐器 (Brass) ===
'Trumpet': '小号',
'Trumpet_C': 'C调小号',
'Cornet': '短号',
'FrenchHorn': '圆号',
'Horn': '圆号',
'Trombone': '长号',
'BassTrombone': '低音长号',
'Tuba': '大号',
'Bass_Tuba': '低音大号',
'Euphonium': '上低音号',
'BaritoneHorn': '中音号',
# === 打击乐器 (Percussion) ===
'Percussion': '打击乐',
'Timpani': '定音鼓',
'Xylophone': '木琴',
'Marimba': '马林巴',
'Vibraphone': '颤音琴',
'Glockenspiel': '钟琴',
'Chimes': '管钟',
'Cymbal': '钹',
'Gong': '锣',
'Drum': '鼓',
'SnareDrum': '小军鼓',
'BassDrum': '大鼓',
'TomTom': '通通鼓',
'Bongo': '邦戈鼓',
'Conga': '康加鼓',
'Tambourine': '铃鼓',
'Triangle': '三角铁',
'Castanets': '响板',
# === 键盘乐器 (Keyboards) ===
'Piano': '钢琴',
'Harpsichord': '羽管键琴',
'Organ': '管风琴',
'Accordion': '手风琴',
'Celesta': '钢片琴',
'Synthesizer': '合成器',
'ElectricPiano': '电钢琴',
'Clavichord': '翼琴',
# === 人声 ===
'Voice': '人声',
'Soprano': '女高音',
'Alto': '女低音',
'Tenor': '男高音',
'Bass': '男低音',
'Choir': '合唱团',
# === 中国乐器 ===
'Erhu': '二胡',
'Pipa': '琵琶',
'Guzheng': '古筝',
'Dizi': '笛子',
'Xiao': '萧',
'Sheng': '笙',
'Suona': '唢呐',
'Yangqin': '扬琴',
'Ruan': '阮',
'Liuqin': '柳琴',
# === 其他 ===
'Guitar': '吉他',
'ElectricGuitar': '电吉他',
'BassGuitar': '贝斯吉他',
'Banjo': '班卓琴',
'Mandolin': '曼陀林',
}
# 文件夹级别名映射(用于非乐器名但需要翻译的文件夹)
FOLDER_MAP = {
'Strings': '弦乐器',
'Winds': '木管乐器',
'Brass': '铜管乐器',
'Keyboards': '键盘乐器',
'Percussion': '打击乐器',
'Voice': '人声',
'Chinese': '中国乐器',
'Plucked': '弹拨乐器',
'Bowed': '弓弦乐器',
}
def get_chinese_name(path_parts):
"""
根据路径部分转换为中文名称
返回转换后的路径列表
"""
chinese_parts = []
for part in path_parts:
# 1. 先检查是否在文件夹映射中(如 Strings -> 弦乐器)
if part in FOLDER_MAP:
chinese_parts.append(FOLDER_MAP[part])
# 2. 再检查是否在乐器映射中
elif part in INSTRUMENT_MAP:
chinese_parts.append(INSTRUMENT_MAP[part])
else:
# 不在映射表中的保留原名
chinese_parts.append(part)
return chinese_parts
def copy_ff_files_with_chinese(source_dir, target_dir):
"""
复制所有包含-ff-的wav文件到目标目录,并将文件夹名转换为中文
"""
# 支持的音频格式
audio_extensions = {'.wav', '.flac', '.mp3', '.aiff', '.ogg'}
# 统计信息
total_files = 0
copied_files = 0
skipped_files = 0
not_found_in_map = set()
print("🚀 开始复制并转换文件夹名...")
print("="*60)
for root, dirs, files in os.walk(source_dir):
for file in files:
# 检查是否为音频文件
ext = os.path.splitext(file)[1].lower()
if ext not in audio_extensions:
continue
total_files += 1
# 检查文件名是否包含 -ff-
if '-ff-' in file:
# 源文件完整路径
source_path = os.path.join(root, file)
# 获取相对于源目录的路径,并分割成路径组件
rel_path = os.path.relpath(root, source_dir)
path_parts = rel_path.split(os.sep)
# 记录未映射的路径组件(用于调试)
for part in path_parts:
if part not in FOLDER_MAP and part not in INSTRUMENT_MAP:
if part not in ['ordinario', '..', '.']: # 忽略常见操作符
not_found_in_map.add(part)
# 将路径组件中的英文名转换为中文
chinese_parts = get_chinese_name(path_parts)
# 构建中文目标路径
chinese_rel_path = os.path.join(*chinese_parts)
target_path = os.path.join(target_dir, chinese_rel_path)
# 创建目标目录
os.makedirs(target_path, exist_ok=True)
# 构建目标文件路径
dest_path = os.path.join(target_path, file)
# 复制文件
try:
shutil.copy2(source_path, dest_path)
copied_files += 1
# 显示转换信息(只显示有变化的)
if rel_path != chinese_rel_path:
print(f"✓ 复制: {rel_path}/{file}")
print(f" ↳ 转换为: {chinese_rel_path}/{file}")
else:
print(f"✓ 复制: {chinese_rel_path}/{file}")
except Exception as e:
print(f"✗ 复制失败: {source_path} -> {e}")
else:
skipped_files += 1
# 打印统计信息
print("\n" + "="*60)
print(f"📊 统计结果:")
print(f" 总音频文件数: {total_files}")
print(f" 已复制 -ff- 文件: {copied_files}")
print(f" 跳过的文件: {skipped_files}")
print(f" 目标目录: {target_dir}")
# 如果有未映射的路径,提示用户
if not_found_in_map:
print(f"\n⚠️ 以下路径组件未找到映射,已保留原名:")
for item in sorted(not_found_in_map):
print(f" - {item}")
print(" 提示: 可以在 INSTRUMENT_MAP 或 FOLDER_MAP 中添加这些项")
print("="*60)
def preview_conversion(source_dir):
"""
预览功能:显示哪些文件夹名会被转换
"""
print("🔍 预览文件夹名转换效果:")
print("-"*60)
# 收集所有将被转换的路径
conversion_examples = []
all_parts = set()
for root, dirs, files in os.walk(source_dir):
rel_path = os.path.relpath(root, source_dir)
if rel_path == '.' or rel_path.startswith('..'):
continue
path_parts = rel_path.split(os.sep)
# 找一个包含ff文件的路径作为示例
has_ff = any('-ff-' in f for f in files)
if has_ff and len(path_parts) >= 2:
chinese_parts = get_chinese_name(path_parts)
if path_parts != chinese_parts:
conversion_examples.append((path_parts, chinese_parts))
# 收集所有路径组件
for part in path_parts:
all_parts.add(part)
# 显示哪些会被转换
mapped_parts = {p for p in all_parts if p in FOLDER_MAP or p in INSTRUMENT_MAP}
unmapped_parts = {p for p in all_parts if p not in FOLDER_MAP and p not in INSTRUMENT_MAP}
if mapped_parts:
print("✅ 会被转换的文件夹名:")
for part in sorted(mapped_parts):
chinese = FOLDER_MAP.get(part, INSTRUMENT_MAP.get(part))
print(f" {part} -> {chinese}")
if unmapped_parts:
print("\n⚠️ 未找到映射,将保留原名的文件夹名:")
for part in sorted(unmapped_parts):
if part not in ['ordinario', '..', '.']:
print(f" {part}")
# 显示几个转换示例
if conversion_examples:
print("\n📝 转换示例:")
for original, chinese in conversion_examples[:5]:
print(f" {'/'.join(original)}")
print(f" -> {'/'.join(chinese)}")
print()
print("-"*60)
if __name__ == "__main__":
# 配置路径
source_directory = "." # 当前目录
target_directory = "./tinySOL_ff_only_中文" # 目标目录(中文文件夹名)
print(f"源目录: {os.path.abspath(source_directory)}")
print(f"目标目录: {os.path.abspath(target_directory)}")
print("-"*60)
# 先预览转换效果
preview_conversion(source_directory)
# 询问是否继续
print("\n⚠️ 即将开始复制文件,确认继续?(y/n)")
confirm = input().strip().lower()
if confirm in ['y', 'yes', '是']:
# 执行复制
copy_ff_files_with_chinese(source_directory, target_directory)
print("\n✅ 处理完成!")
else:
print("❌ 已取消操作")清洗数据之后,和在项目页面使用相同,先设置一个维度且含4个标签;而后选择一个标签,点击“导入音频”按钮给该标签导入数据即可:
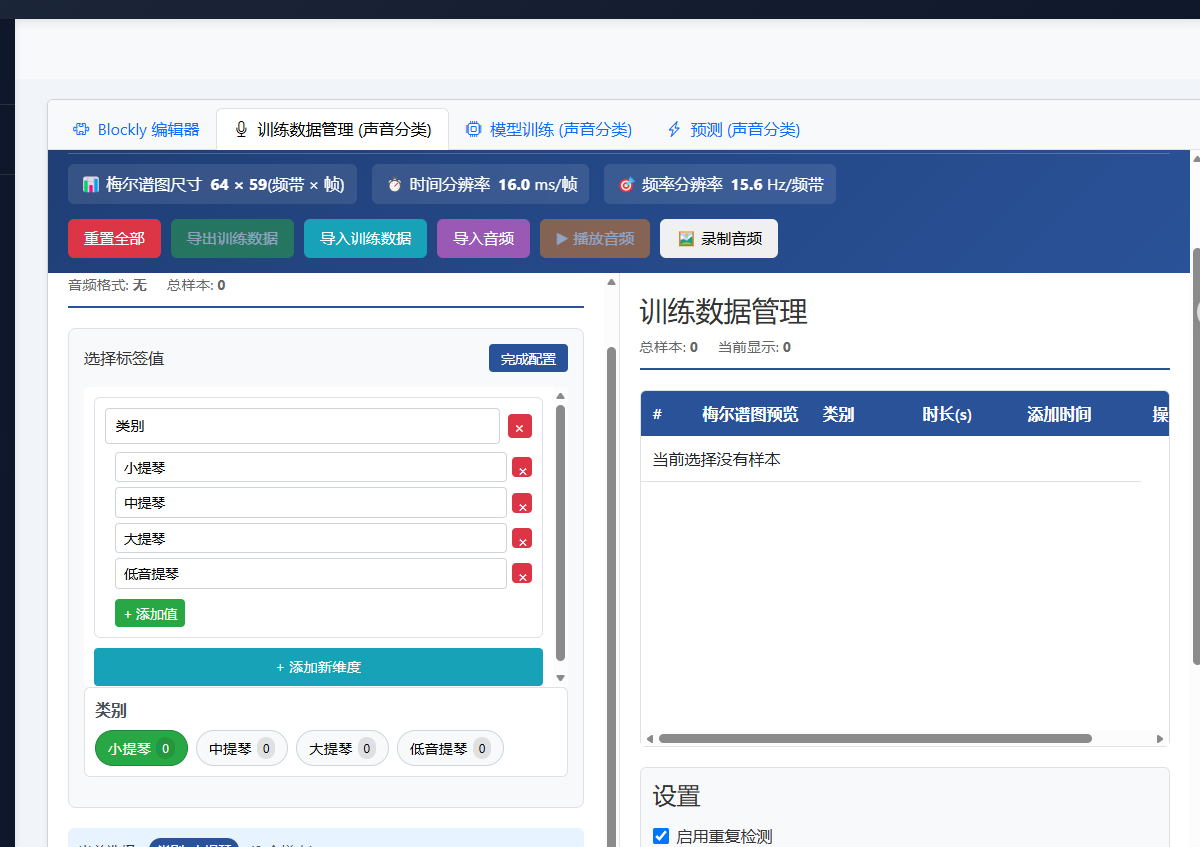
将数据导出,并重命名。
三、模型构建
我们使用“音频数字分类”模型相同的模型,仅修改输入、输出参数即可:
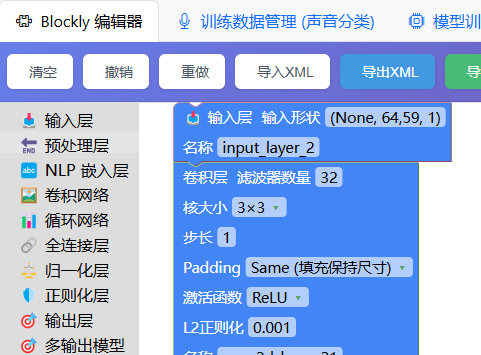

将XML和JSON均导出并重命名。
四、训练
和在项目中训练相同,导入模型、数据,打开数据增强的全部选项,开始训练。为了得到稍好的已训练模型,我们可以选择多训练几轮或者训练一些轮次之后点击“继续训练”,使用上述数据和模型,训练20轮可以使得损失降低到0.4左右,模型可以表现出较高的准确率:
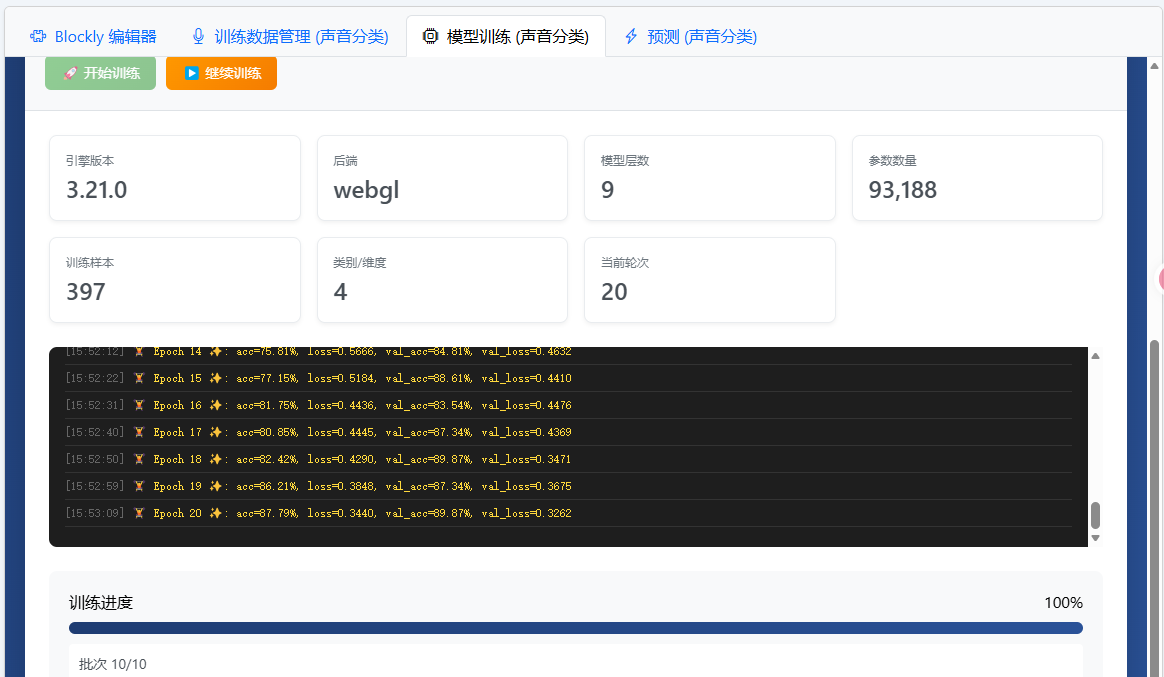
导出已训练模型,在预测器中进行验证,如果能够达到较为理想的效果,就可以回到项目编辑界面上传保存的数据。而后回到前台的项目中,点击打开该项目,即可看到完整的项目实例:
在Ai创想实验室中,通过建立已有项目类型的实例可以非常便捷的实现“个性化”、“校本化”的AI实验项目。这为中小学开展“个性化”的AI教学提供了极大便利。
在AI创想实验室中,我们无需编程基础,不用学习框架,不用配置环境,无需购买费用高昂的显卡,更不用为云端算力付费,使用当前已有的各种硬件:仅有核显的个人、办公、机房电脑,希沃白板等都能达到理想的教学效果。操作简单但AI核心知识样样俱全,无需师资培训就可以进行教学且能取得理想的教学效果。如果加入试点或合作方那么只需要一台局域网服务器(无需显卡、服务器不用供算力)即可一次投入永久使用全部项目和功能,通过后台管理一分钟即可创建一个本地化、校本化的项目实例。
有任何问题欢迎留言或发送邮件至:hello@AiEduLab.tech
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)