
Excel 不可见字符一键清除(Python + Pandas)
·
问题场景
从某些平台导出的 Excel 数据,单元格里藏着肉眼看不到的特殊字符,导致匹配、去重、统计全部翻车。
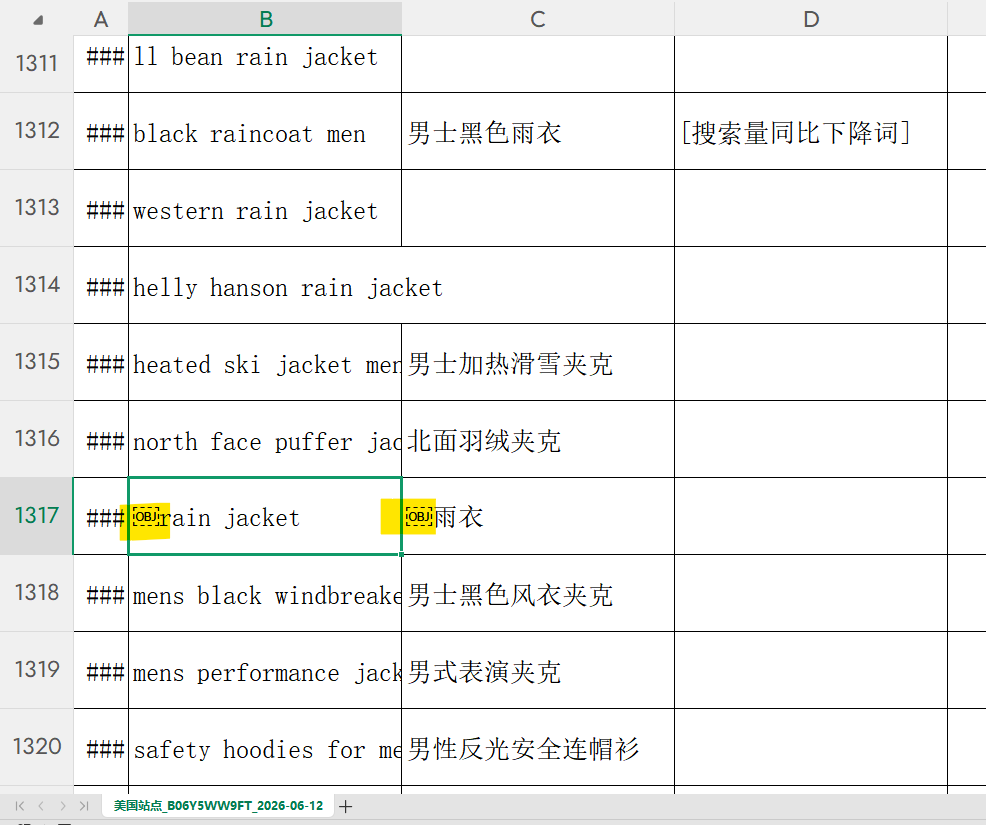
典型表现:
- 看着是"雨衣",VLOOKUP 就是匹配不上
- len() 发现比正常多 1~2 个字符
- 复制到记事本,光标前有个"幽灵占位"
罪魁祸首
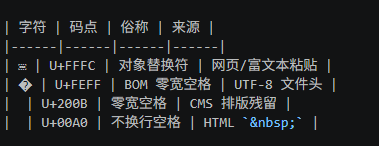
这些不可见字符的 Unicode 码点集中在:
解决方案
核心就一行正则替换: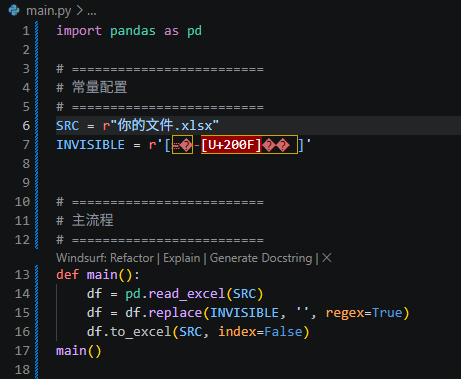
原理
df.replace(pattern, '', regex=True) 对整个 DataFrame 逐单元格执行正则替换,匹配到的不可见字符替换为空字符串。
正则 r'[-
]' 字符类包含:
- U+FFFC — 最常见,拷贝网页/富文本时带入
- U+FEFF — 文件 BOM 标记,常黏在数据第一列开头
- U+200B~U+200F — 零宽空格家族
- U+2028/U+2029 — Unicode 换行/分段符
- U+00A0 — HTML 不换行空格转义残留
完整脚本
由于特殊字符代码段展示不出来,可点击下载脚本:
常见问题
Q:会不会把正常文字也删了?
不会。正则只命中那几类零宽/控制字符,中文、英文、数字、标点都不受影响。
搞定。下次遇到 Excel 里匹配不上的"幽灵字符",跑一遍就干净了。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)