
Python入门和基础
python是一门编程语言。python的解释器pycharm。
一、安装和部署
1.1 安装Python工具
在官网上下载工具,然后安装。
安装pycharm
https://pycharm.zuitie.cn/?bd_vid=8472754158287571923
二、Python基础
2.1 语句
2.1.1 输出语句
采用print输出
print('你好Python')2.1.2 输入input
采用input输入,可以接收输入结果
name = input('请输入你的名字:')
print(name)用户输入后,回车键返回,将输入结果赋值给name。
input输出的结果是字符串.
type获取数据类型
# input输出的结果是字符串
c = input("请输入第一个数字:")
# 可以使用type运算符得到变量类型
print(type(c))<class 'str'>
说明c是字符串类型
数据类型转换
# py基本数据类型转换逻辑:
# 想把谁转换为xxx, 就用xxx 套谁
# 想把谁转换为xxx, 就用xxx 套谁
# str => int. int(str)
c = int(c)c转换为int类型。
2.1.3 注释语句
采用# 注释语句。
# 输入(增加提示语)
name = input('请输入你的名字:')
print(name)注释是对代码进行解释和说明,是给人看的。
单行注释
采用#对单行进行注释。
多行注释
采用 """ """或者 ''' '''进行多行注释
"""
多行注释
"""2.2 字面量
Python 字面量是指直接在源代码中写下的固定值,无需通过变量或计算即可被解释器识别和使用 。它是 Python 程序中最基本的数据表示形式,涵盖了数字、字符串、布尔值、空值及容器等多种类型 。可以理解为常量。
2.3 变量
变量是存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间。
变量赋值
语法:
变量名 = 变量值counter = 100 # 赋值整型变量
多个变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = 1标准数据类型(变量类型)
在内存中存储的数据可以有多种类型。
例如,一个人的年龄可以用数字来存储,他的名字可以用字符来存储。
Python 定义了一些标准类型,用于存储各种类型的数据。
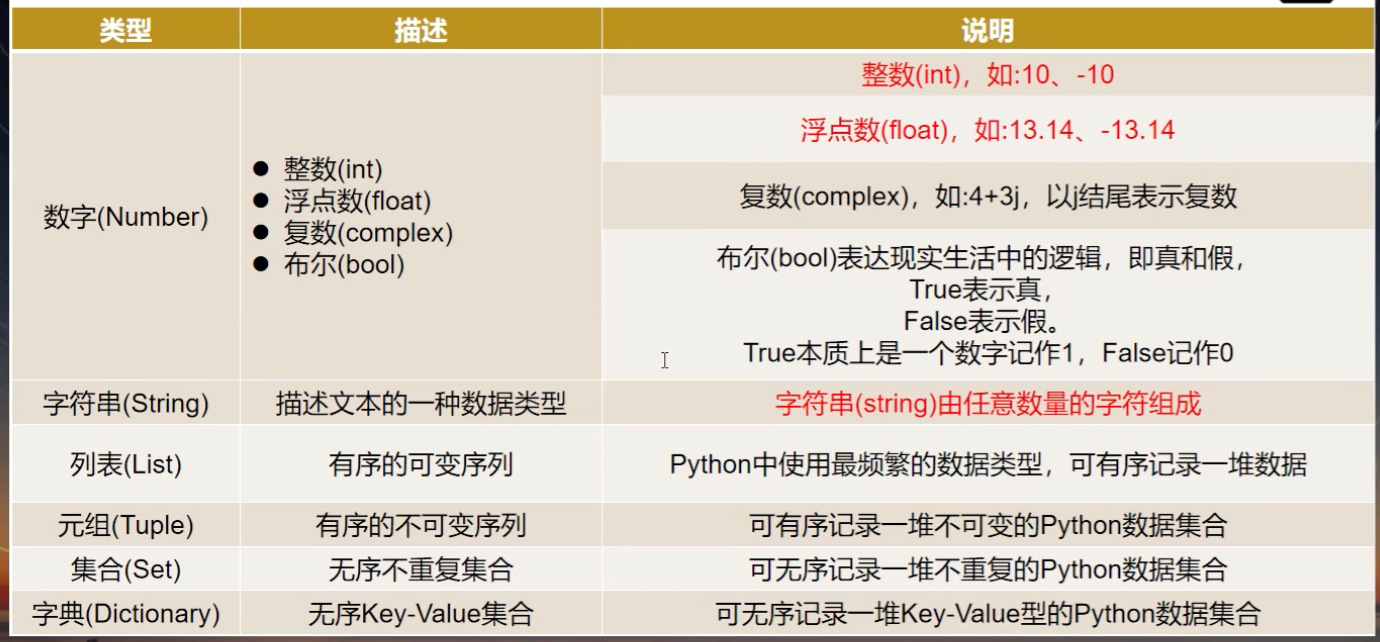
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
Python支持四种不同的数字类型:
- int(有符号整型)
- long(长整型,也可以代表八进制和十六进制)
- float(浮点型)
- complex(复数)
2.4 常量
所有大写字母的变量可以看做常量。
# 没有严格意义上的常量。
PI = 3.1415926
print(PI)
# 约定为常量,也可以改变值
PI = 3
print(PI)2.5 条件语句
if 语句的判断条件可以用>(大于)、<(小于)、==(等于)、>=(大于等于)、<=(小于等于)来表示其关系。
当判断条件为多个值时,可以使用以下形式:
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……简单的语句组
你也可以在同一行的位置上使用if条件判断语句
if ( var == 100 ) : print "变量 var 的值为100" 2.6 循环语句
让语句重复执行。
2.6.1 while循环
语法:
while 条件:
循环体代码
例如计算:1-2+3-4....-100=?
# 计算 1-2+3-4...-100=?
i = 1
v = 1
s = 0
sign = 1
while i<=100:
s = s + v
i = i + 1
if v > 0:
sign = -1
else:
sign = 1
v = i * sign
print("s=" + format(s) + " v=" +format(v) + " i=" + format(i))
print(s)2.6.2 立即停止循环break
2.6.3 停止当前一轮循环continue
continue停止当前一轮循环继续下一轮.
2.6.4 for循环
语法:
for 变量 in 可迭代的东西:
循环体for循环可以遍历集合。
for循环用于计数
range(n): 从0~n-1.区间是前开后闭的区间
for i in range(10): # 0~9
print(i)
range(m,n): 从m~(n-1).区间循环
range(m,n,step): 从m~(n-1).区间循环,步长step
pass占位
循环体未实现的情况下,先占位,可以采用pass
for i in range(10):
pass2.7 基础数据类型
2.7.1 数字类型Number
Python Number 数据类型用于存储数值。
数据类型是不允许改变的,这就意味着如果改变 Number 数据类型的值,将重新分配内存空间。
delete删除引用
您也可以使用del语句删除一些 Number 对象引用。
del语句的语法是:
del var1[,var2[,var3[....,varN]]]]四种数值类型
Python 支持四种不同的数值类型:
- 整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。
- 长整型(long integers) - 无限大小的整数,整数最后是一个大写或小写的L。
- 浮点型(floating point real values) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
- 复数(complex numbers) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
- 长整型也可以使用小写"L",但是还是建议您使用大写"L",避免与数字"1"混淆。Python使用"L"来显示长整型。
- Python还支持复数,复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型
2.7.2 Python Number 类型转换
int(x [,base ]) 将x转换为一个整数
long(x [,base ]) 将x转换为一个长整数
float(x ) 将x转换到一个浮点数
complex(real [,imag ]) 创建一个复数
str(x ) 将对象 x 转换为字符串
repr(x ) 将对象 x 转换为表达式字符串
eval(str ) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s ) 将序列 s 转换为一个元组
list(s ) 将序列 s 转换为一个列表
chr(x ) 将一个整数转换为一个字符
unichr(x ) 将一个整数转换为Unicode字符
ord(x ) 将一个字符转换为它的整数值
hex(x ) 将一个整数转换为一个十六进制字符串
oct(x ) 将一个整数转换为一个八进制字符串 # 字符串转整数 int
a = "200"
b = int(a)
print("转换后的类型:", type(b)) # <class 'int'>2.7.3 数学计算模块math及cmath
Python 中数学运算常用的函数基本都在 math 模块、cmath 模块中。
Python math 模块提供了许多对浮点数的数学运算函数。
Python cmath 模块包含了一些用于复数运算的函数。
cmath 模块的函数跟 math 模块函数基本一致,区别是 cmath 模块运算的是复数,math 模块运算的是数学运算。
math中的函数:
>>> import math
>>> dir(math)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__',
'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign',
'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial',
'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose',
'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p',
'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt',
'tan', 'tanh', 'tau', 'trunc']
>>>查看 cmath 查看包中的内容:
>>> import cmath
>>> dir(cmath)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__',
'acos', 'acosh', 'asin', 'asinh', 'atan', 'atanh', 'cos', 'cosh', 'e',
'exp', 'inf', 'infj', 'isclose', 'isfinite', 'isinf', 'isnan', 'log',
'log10', 'nan', 'nanj', 'phase', 'pi', 'polar', 'rect', 'sin', 'sinh',
'sqrt', 'tan', 'tanh', 'tau']
>>>2.7.4 Python数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 以浮点数形式返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根 |
2.7.5 Python随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
Python包含以下常用随机数函数:
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| randrange ([start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| seed([x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
2.7.6 Python三角函数
Python包括以下三角函数:
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(x*x + y*y)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
2.7.7 Python数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 e,e即自然常数(自然常数)。 |
2.7.8 字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号 ( ' 或 " ) 来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!'
var2 = "Python Runoob"2.7.8.1 访问字符串的值
字符串子串的访问。
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号来截取字符串,如下实例:
var1 = 'Hello World!'
var2 = "Python Runoob"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5]
# 输出结果
var1[0]: H
var2[1:5]: ytho
# var1[0]的类型是<class 'str'>
print(type(var1[0]))截取前N个字符子串的语法:
str[:N]: 截取前[0,n) 个字符的子串;
str[m:]: 截取从m开始的[m, len)子串。
str[startIndex:endIndex:step]: 获取从[startIndex, endIndex)的子串,按照step抽取字符。
# 截取从0~5的子串,步长为2,结果:Hlo
print("var1[0:5:2]: ", var1[0:5:2])
获取尾部的子串
采用负数标记从尾部计数下标的子串。
最末尾的字符的索引开始,往左一个位置则-1
# 获取末尾3个字符的子串
print("var1[-3:]: ", var1[-3:])
2.7.8.2 字符串格式化
字符串进行格式化输出。
类型一:百分号占位格式
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
# 类型一:采用百分号占位
print("My name is %s and weight is %d kg!" % ('Lucky', 21) )python 字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
语法结构:
"格式化字符串" % (参数列表,采用逗号分隔)类型二:format格式化
参数采用{}占位,
语法:参数采用{} 占位
"格式化字符串".format(参数列表)例如:
# 类型二:采用format格式化
name = "李磊"
age = 21
print("我是{}, 我今年{}".format(name, age))类型三:f-string方式
f-string方式类似于字符串模版,将格式化字符串与参数一起拼接,减少参数类型对应的麻烦。
与format类型,也是采用{}进行参数占位,括号中直接写参数名称。
格式化字符串之前“f”标记为 f-string 方式。
# 类型三:f-string方式
print(f"我是{name}, 我今年{age}")
输出:
我是李磊, 我今年21
2.7.8.3 字符串内建函数
目前字符串内建支持的方法,所有的方法都包含了对 Unicode 的支持,有一些甚至是专门用于 Unicode 的。
| 方法 | 描述 |
|---|---|
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
格式化字符串 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
|
|
类似于 index(),不过是返回最后一个匹配到的子字符串的索引号。 |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
类似于 partition()函数,不过是从右边开始查找 |
|
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
|
|
按照行('\r', '\r\n', '\n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
string.capitalize():第一个字母大写
# 3.1 string.capitalize()
s = "my name is Lucky, I like basketball."
# 第一个字母大写 “My name is lucky, i like basketball.”
s1 = s.capitalize()
print(s1)string.startswith(str): 字符串是否以str开头
判断字符串是否以某个子串开头
# 3.2 string.startswith(str): 字符串是否以str开头
print(s1.startswith("My"))string.endswith(str): 字符串是否以str结尾
判断字符串是否以某个子串结尾。
# 3.3 string.endswith(str): 字符串是否以str结尾
print(s1.endswith("."))len(string) 字符串长度
计算字符串的长度
# 3.4 len(string) 字符串长度
print(f"s1的长度是:{len(s1)}")s1的长度是:36
string.find(str, startIndex = 0)字符串查找
# “My name is lucky, i like basketball.”
# 3.5 string.find(str) 查找子串
index = s1.find("lucky")
print(index)输出结果:
11
未找到子串则返回-1
string.lower() 转换为小写
将字符串内容转换为小写
# 3.6 string.lower() 将字符串内容转换为小写
s = "That is a cat."
# 输出:that is a cat.
print(s.lower())string.upper() 将字符串内容转换为大写
# 3.7 string.upper() 将字符串内容转换为大写
# 输出:THAT IS A CAT.
print(s.upper())string.index(str) 子串的索引位置
s = "That is a cat."
# 输出:10
print(s.index("cat"))
# 未找到则发生报错,程序终止
print(s.index("dog"))
print("下一个测试")找不到"dog",则发生报错
Traceback (most recent call last):
File "/Users/zhouronghua/WORK/DEV/projects/Python/字符串.py", line 69, in <module>
print(s.index("dog"))
~~~~~~~^^^^^^^
ValueError: substring not foundstring.replace(old_str, new_str)字符串内容替换
# 3.9 string.replace(old_str, new_str)字符串内容替换
s2 = s.replace("cat", "monkey")
# 输出:That is a monkey.
print(s2)string.swapcase() 翻转 string 中的大小写
# 3.10 string.swapcase() 翻转 string 中的大小写
# 输出:tHAT IS A MONKEY.
print(s2.swapcase())string.strip() 去掉字符串前后的空白(\n,\r或者空格)
# 3.11 string.strip() 去掉字符串前后的空白(\n,\r或者空格)
s = " I like Lucy. "
print(s)
# 输出:I like Lucy.
print(s.strip())string.split(str) 字符串切分为字符串数组
# 3.12 string.split(str) 字符串切分为字符串数组
s = "com_demo_java_nativeInit"
# 采用 _ 进行字符串切分, 输出:['com', 'demo', 'java', 'nativeInit']
print(s.split("_"))string.join(集合) 字符串拼接
# 3.12 join 字符串拼接
list = ["orange", "banana", "apple"]
s = "_".join(list)
# 输出:orange_banana_apple
print(s)2.7.9 列表(List)
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
Python有6个序列的内置类型,但最常见的是列表和元组。
Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]2.7.9.1 列表的切分
根据索引范围对列表元素进行切分。
语法:
list[startIndex:endIndex:step]和字符串切分类似。
list2 = [1, 2, 3, 4, 5, 6, 7 ]
# 1.列表元素的切分
print("list2[1:5]: ", list2[1:5])
# 从第一个开始的元素 输出:从第一个开始的元素 [2, 3, 4, 5, 6, 7]
print("从第一个开始的元素", list2[1:])2.7.9.2 list.append(元素)末尾添加元素
# 2.list.append(元素) 列表末尾添加元素
list2.append(100)
print(list2)输出:
[1, 2, 3, 4, 5, 6, 7, 100]
2.7.9.3 list.extend(列表)将列表合并追加到末尾
# 3.list.extend(列表)将列表合并追加到末尾
list2.extend(["苹果", "葡萄"])
# 输出:[1, 2, 3, 4, 5, 6, 7, 100, '苹果', '葡萄']
print(list2)2.7.9.4 更新列表元素:采用索引更新列表元素
# 4.更新列表元素:采用索引更新列表元素
# list2的第二个元素更新为15
list2[1] = 15
# 输出:[1, 15, 3, 4, 5, 6, 7, 100, '苹果', '葡萄']
print(list2)2.7.9.5 list.remove(元素)删除列表元素
list.remove(元素) 删除列表元素。
# 如果元素不存在则发生错误
list2.remove(15)
# 输出:[1, 3, 4, 5, 6, 7, 100, '苹果', '葡萄']
print(list2)
如果删除一个不存在的元素
# 删除一个不存在的元素报错
list2.remove(2)
print(list2)Exception has occurred: ValueError
list.remove(x): x not in list
File "/Users/zhouronghua/WORK/DEV/projects/Python/列表.py", line 31, in <module>
list2.remove(2)
~~~~~~~~~~~~^^^
ValueError: list.remove(x): x not in list在循环中删除元素
# 删除元素:删除第一个"李三丰"后,后面的元素往前移动一个位置,下一轮循环直接到”赵敏“
myList = ["赵本山", "李三丰", "李九龄", "赵敏"]
for item in myList:
if item.startswith("李"):
myList.remove(item)
# 输出结果:'赵本山', '李九龄', '赵敏']
print(myList)发现"李九龄"仍然在列表中。
2.7.9.6 list.index(元素) 查找元素所在的索引位置
# 4.list.index(元素) 查找元素所在的索引位置
print(list2.index(5))
# [1, 3, 4, 5, 6, 7, 100, '苹果', '葡萄']
# 4.list.index(元素) 查找元素所在的索引位置
print(list2.index(5))
# 输出:3如果元素不存在则会报错
# 如果元素不存在则报错
# Traceback (most recent call last):
# File "/Users/zhouronghua/WORK/DEV/projects/Python/列表.py", line 36, in <module>
# print(list2.index(8))
# ~~~~~~~~~~~^^^
#ValueError: list.index(x): x not in list
print(list2.index(8))2.7.9.7 Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
2.7.9.8 Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
2.7.9.9 列表排序
列表升序排列list.sort()。如果需要降序,list.sort(reverse=True)
# 5.列表元素排序 list.sort()
list3 = [2,100, 40, 7, 27]
list3.sort()
# 输出:[2, 7, 27, 40, 100]
print(list3)
# 如果需要降序排列
list3.sort(reverse=True)
# 输出结果:[100, 40, 27, 7, 2]
print(list3)
2.7.9.10 列表翻转
将列表元素翻转
# [100, 40, 27, 7, 2]
# 6.列表翻转
list3.reverse()
# 输出结果:[2, 7, 27, 40, 100]
print(list3)
2.7.10 元组(Tuple)
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"2.7.10.1 只有一个元素的元组
元组中只包含一个元素时,需要在元素后面添加逗号
tup1 = (50,)如果不加, 括号会被识别为优先级符号。
# 1.只有一个元素的元组
tup = (10)
# 如果不加逗号,括号被识别为优先级符号,因此 tup为<class 'int'>
print(type(tup))
# 元组中只包含一个元素时,需要在元素后面添加逗号
tup = (10, )
# 输出:<class 'tuple'>
print(type(tup))2.7.10.2 访问元组
元组可以使用下标索引来访问元组中的值
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print "tup1[0]: ", tup1[0]
print "tup2[1:5]: ", tup2[1:5]# 2.访问元组元素
# 采用下标访问元组元素
print(tup[0])
# 元组支持切分
# 输出:(3, 4, 5)
print(tup2[2:])2.7.10.3 元组不支持元素修改
元组是不可变的,因此不支持元素的修改。
如果元组的元素是数组,不能修改数组,但可以修改数组中的元素。
# 3.元组不支持元素修改
tup4 = (1,2,3, ["苹果", "香蕉", "橘子"])
# 可以修改数组元素的内容
tup4[3].append("葡萄")
# 输出:(1, 2, 3, ['苹果', '香蕉', '橘子', '葡萄'])
print(tup4)2.7.10.4 删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
tup = ('physics', 'chemistry', 1997, 2000)
print tup
del tup
print "After deleting tup : "
print tup以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
('physics', 'chemistry', 1997, 2000)
After deleting tup :
Traceback (most recent call last):
File "test.py", line 9, in <module>
print tup
NameError: name 'tup' is not defined
删除元组以后,元组的引用不存在。因此会报错“name 'tup' is not defined”
2.7.10.5 元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |
2.7.10.6 元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
L = ('spam', 'Spam', 'SPAM!')
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'SPAM!' | 读取第三个元素 |
| L[-2] | 'Spam' | 反向读取,读取倒数第二个元素 |
| L[1:] | ('Spam', 'SPAM!') | 截取元素 |
2.7.10.7 元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) |
2.7.11 Set集合(Set)
set是包含不重复元素的无序集合。
2.7.11.1 set的创建
创建一个空set
# 1.创建一个空集合
s = set()
# 输出<class 'set'>
print(type(s))
# 创建一个非空set
s = {1,2,6}
print(s)
# 输出:<class 'set'>
print(type(s))2.7.11.2 set元素是可哈希的
不可哈希:python中的set集合存储元素的时候,需要对数据进行哈希计算,根据计算出来的哈希 值进行存储数据。
set集合要求存储的数据元素必须是可以进行哈希计算的。
可变的数据类型是不可哈希的,list, dict, set
可哈希:不可变的数据类型。int, str, 元组,布尔值
# 列表是可变的,不可以作为set的元素
# 不可哈希:python中的set集合存储元素的时候,需要对数据进行哈希计算,根据计算出来的哈希值进行存储数据。
# set集合要求存储的数据元素必须是可以进行哈希计算的。
# 可变的数据类型是不可哈希的,list, dict, set
# 可哈希:不可变的数据类型。int, str, 元组,布尔值
# 列表是可变的,不可以作为set的元素
s = {1,2,"哈巴狗", [2,6,7]}
print(s)
# 创建集合
s = {1,5, True, 6}
# True元素丢失。输出:{1, 5, 6}
print(s)
print(len(s))
# 为什么True丢失了呢?
# 1. 核心原因:True 等于 1在 Python 中,bool 是 int 的子类。
# 这意味着:True 的整数值为 1False 的整数值为 0表达式 True == 1 的结果为 True表达式 False == 0 的结果为 True
# 字符串元素
s.add("小龙女")
# 输出:{1, '小龙女', 5, 6}
print(s)2.7.11.3 添加元素
set集合是无需的,添加的元素不一定在末尾;另外,Set集合元素是唯一的,如果已经存在,则添加后set维持不变。
# 3.set集合添加元素
s.add("欧阳锋")
s.add("欧阳锋")
# 输出:{1, 5, 6, '欧阳锋', '小龙女'}
print(s)
2.7.11.4 删除元素set.remove(e)
set集合通过remove(e:Elment)删除元素
# 4.删除元素
s.remove("欧阳锋")
# 输出:{1, 5, 6, '小龙女'}
print(s)2.7.11.5 更新元素
set集合元素是不可变的,更新元素采用:删除旧元素+添加新元素的方式实现。
# 5.更新元素
# set集合元素是不可变的,更新元素采用:删除旧元素+添加新元素的方式实现。
# 把set集合的小龙女替换为“杨过”
s.remove("小龙女")
# 输出:{1, 5, 6, '杨过'}
s.add("杨过")
print(s)2.7.11.6 集合的运算:交集、并集和差集
集合的运算:交集、并集和差集
# 6.2 交集
s1 = {"赵本山", "大脚", "小沈阳"}
s2 = {"张嘎", "贾队长", "小沈阳"}
print(s1 & s2)
# set.intersection(set) 计算集合的交集
print(s1.intersection(s2))计算并集
# 6.2 并集
# 输出:{'贾队长', '大脚', '小沈阳', '张嘎', '赵本山'}
print(s1 | s2)
# 输出:{'贾队长', '大脚', '小沈阳', '张嘎', '赵本山'}
print(s1.union(s2))计算差集
set1 - set2: s1减去在set2中出现的元素。
# 6.3 差集
# 输出:{'大脚', '赵本山'}
print(s1 - s2)
# 输出:{'大脚', '赵本山'}
print(s1.difference(s2))
2.7.11.7 取出重复元素
set的作用可以去除重复元素。利用set元素唯一的特性,可以去除列表的重复元素。得到去重后的无序集合。
去除重复元素
list = [1,1,3, 30, '贾队长', '大脚', '小沈阳', '张嘎', '赵本山', '贾队长', '大脚', '小沈阳', '张嘎', '赵本山']
# 输出:{1, 3, '贾队长', '张嘎', '小沈阳', '赵本山', '大脚', 30}
print(set(list))
# 得到去重后的无序列表2.7.12 字典(Dictionary)
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中.
语法:
d = {key1 : value1, key2 : value2 }注意:dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
字典,也可以称做MAP。
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
>>> tinydict = {'a': 1, 'b': 2, 'b': '3'}
>>> tinydict['b']
'3'
>>> tinydict
{'a': 1, 'b': '3'}2.7.12.1 获取键对应的值
根据键获取存储的value值
# 2.根据键获取对应的值
# 输出:456
print(tinydict1['abc'])
print(tinydict1.get('abc'))
# 如果对应的键不存在的话
# 直接报错:Traceback (most recent call last):
# File "/Users/zhouronghua/WORK/DEV/projects/Python/字典.py", line 18, in <module>
# print(tinydict1['ccc'])
# ~~~~~~~~~^^^^^^^
# KeyError: 'ccc'
# print(tinydict1['ccc'])
# get方式安全返回,不存在的键获取得到None
v = tinydict1.get('ccc')
# 输出:None
print(v)
# 输出:<class 'NoneType'>
print(type(v))2.7.12.2 修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对
# 4. 修改字典
# 可以根据键修改对应的值,或者直接增加键值对
tinydict['Age'] = 8 # 更新
# 输出:{'Alice': '2341', 'Beth': '9102', 'Cecil': '3258', 'Age': 8}
print(tinydict)
# 输出:{'Alice': '2341', 'Beth': '9102', 'Cecil': '3258', 'Age': 8, 'School': 'RUNOOB'}
tinydict['School'] = "RUNOOB" # 添加
print(tinydict)2.7.12.3 删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
# 5.删除字典元素
# 根据key删除字典的键值对
del tinydict['Alice']
# 输出:{'Alice': '2341', 'Beth': '9102', 'Cecil': '3258', 'Age': 8, 'School': 'RUNOOB'}
{'Beth': '9102', 'Cecil': '3258', 'Age': 8, 'School': 'RUNOOB'}
print(tinydict)
# 删除整个字典
del tinydict # 删除字典
# 字典输出以后访问元素则会发生 NameError
# NameError: name 'tinydict' is not defined. Did you mean: 'tinydict1'?
print(tinydict['Beth'])2.7.12.4 字典键的特性
字典值可以没有限制地取任何 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)键是唯一的:不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
# 字典值可以没有限制地取任何 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
# 两个重要的点需要记住:
# 1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
tinydict = {'Name': 'Runoob', 'Age': 7, 'Name': 'Manni'}
#. 输出:tinydict['Name']: Manni
print("tinydict['Name']: ", tinydict['Name'])2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行
# 2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行,如下实例:
# TypeError: cannot use 'list' as a dict key (unhashable type: 'list')
tinydict = {['Name']: 'Zara', 'Age': 7} 2.7.12.5 字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false。Python3 不支持。 |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
2.7.12.6 字典嵌套
字典可以嵌套使用。value的值可以是一个字典。
# 6.字典的嵌套
nestdic = {
"friuts": {
"banana" : "黄色",
"apple": "红色",
"orange": "橘色"
},
"annimal": {
"cat": "田园猫",
"dog": "柯基",
"chicken": "黄毛鸭"
},
"children" : [
{"name":"小布丁", "age": 8},
{"name":"靓仔", "age": 5}
]
}
# 打印friuts二级元素banana的值
# 输出:黄色
print(nestdic["friuts"]["banana"])
# 打印children第二个元素的name
# 输出:靓仔
print(nestdic["children"][1]["name"])
# 修改children第二个元素的age
nestdic["children"][1]["age"] = 4
# 输出:{'name': '靓仔', 'age': 4}
print(nestdic["children"][1])2.8 字符集编码与解码
编码主要解决电脑如何存储文字信息。
ASCII码:128个基本字符;
中文编码:gb2312, gbk
日文编码:JIS编码
Unicode: 全球统一编码,万国码。UTF-16:4个字节表示一个字符。UCS-4
UTF:是可变长的Unicode, 可以进行数据的传输和存储。
UTF-8:最短的字节长度8;
英文:8bit 1byte
欧洲文字: 16bit (2byte)
中文:24bit (3byte)
UTF-16: 最短的字节长度16;
gbk和utf-8不能直接转化
bytes
程序员平时遇见的所有数据最终单位都是字节byte。
1.编码 str.encode(编码格式)
2.解码:bytes.decode(编码格式)# 1.编码 str.encode(编码格式)
a = "你好!Python"
# print(len(a))
bs = a.encode("utf-8")
# 输出:b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x81Python'
print(bs)
# 输出:15
print(len(bs))
b = bs.decode("utf-8")
# 解码以后能够恢复到原来的字符
# 输出:你好!Python
print(b)
# 输出:True
print(len(b) == len(a))
2.9 运算符
Python语言支持以下类型的运算符:
2.9.1 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) |
>>> 9//2 4 >>> -9//2 -5 |
# 1.数值运算符 +-*/ %
a = 10
b = 3
print(a+b)
# 计算 a / b
# 输出: 3
print(a // b)
# 3.33333333
print(a/b)2.9.2 比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量 True 和 False 等价。 | (a < b) 返回 True。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 |
# 2.比较运算符
# > < >= <= != ==
# 模拟用户登录
name = input("请输入姓名:")
passwd = input("请输入密码:")
# 输出:
# 请输入姓名:Kimy
# 请输入密码:123456
# 用户名或者密码错误
if (name == "Lucky" and passwd == "123456"):
print("用户登录成功")
else:
print("用户名或者密码错误")2.9.3 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
# 3.赋值运算符
# = += -= *= ...
# 计算1+2+。。。+100
n = 1
sum = 0
while n <= 100:
sum += n
n += 1
print(sum)2.9.4 位运算符
按位运算符是把数字看作二进制来进行计算的。
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:将二进制表示中的每一位取反,0 变为 1,1 变为 0。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011 (以补码形式表示),在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 |
# 4.位运算符
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print ("1 - c 的值为:", c)
c = a | b; # 61 = 0011 1101
print ( "2 - c 的值为:", c)
c = a ^ b; # 49 = 0011 0001
print ("3 - c 的值为:", c)
c = ~a; # -61 = 1100 0011
print("4 - c 的值为:", c)
c = a << 2; # 240 = 1111 0000
print( "5 - c 的值为:", c)
c = a >> 2; # 15 = 0000 1111
print("6 - c 的值为:", c) 2.9.5 逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
# 5.逻辑运算符
# 1)and 并且,左右两端同时成为,结果才能成立
# 2)or 或者 左右两端有成为,结果就成立
# 3)not 非 非真即假,非假即真
# 当 and 和 or 以及 not同时出现的时候,最好加上括号。不会产生歧义或者不容易理解的问题。
# 如果没有括号怎么办?
# 记住运算顺序:
# 先算括号 > 再算 not > and > or
# 输出:Flase
print(True and False and True)
# 输出:True
print(not True)
# 输出:True
print(True and not False or False and not False)2.9.6 成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
a = 10
b = 20
list = [1, 2, 3, 4, 5 ];
# 输出:1 - 变量 a 不在给定的列表中 list 中
if ( a in list ):
print("1 - 变量 a 在给定的列表中 list 中")
else:
print("1 - 变量 a 不在给定的列表中 list 中")
# 输出:2 - 变量 b 不在给定的列表中 list 中
if ( b not in list ):
print("2 - 变量 b 不在给定的列表中 list 中")
else:
print("2 - 变量 b 在给定的列表中 list 中")
# 插入元素a
list.append(a)
# 输出:1 - 变量 a 在给定的列表中 list 中
if ( a in list ):
print("1 - 变量 a 在给定的列表中 list 中")
else:
print("1 - 变量 a 不在给定的列表中 list 中")2.9.7 身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
# 7.身份运算符
# is 是判断两个标识符是不是引用自一个对象
# not is 是判断两个标识符不是引用自一个对象
a = 20
b = 20
# 输出:1 - a 和 b 有相同的标识
if ( a is b ):
print( "1 - a 和 b 有相同的标识")
else:
print("1 - a 和 b 没有相同的标识")
# 输出:2 - a 和 b 有相同的标识
if ( a is not b ):
print("2 - a 和 b 没有相同的标识")
else:
print("2 - a 和 b 有相同的标识")
# 修改变量 b 的值
b = 30
# 输出:3 - a 和 b 没有相同的标识
if ( a is b ):
print("3 - a 和 b 有相同的标识")
else:
print("3 - a 和 b 没有相同的标识")
# 输出:4 - a 和 b 没有相同的标识
if ( a is not b ):
print("4 - a 和 b 没有相同的标识")
else:
print("4 - a 和 b 有相同的标识")2.9.8 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
# 结果:4
print( 4 - 2 << 1)
# 相当于:(4 -2) << (1+2) = 2 << 3 = 16
print( 4 - 2 << 1 + 2)
# [(~3) + 4 - 2] << (2 + 2) = [-4 + 4 -2] << 4 = (-2) << 4 = -32
print(~3 + 4 - 2 << 2+2)
# 输出:-4
print(~3)2.10 文件操作
2.10.1 打开文件
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
file object = open(file_name [, access_mode][, buffering])各个参数的细节如下:
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。可以使用绝对路径,也可以使用相对路径。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- encoding:编码格式。
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
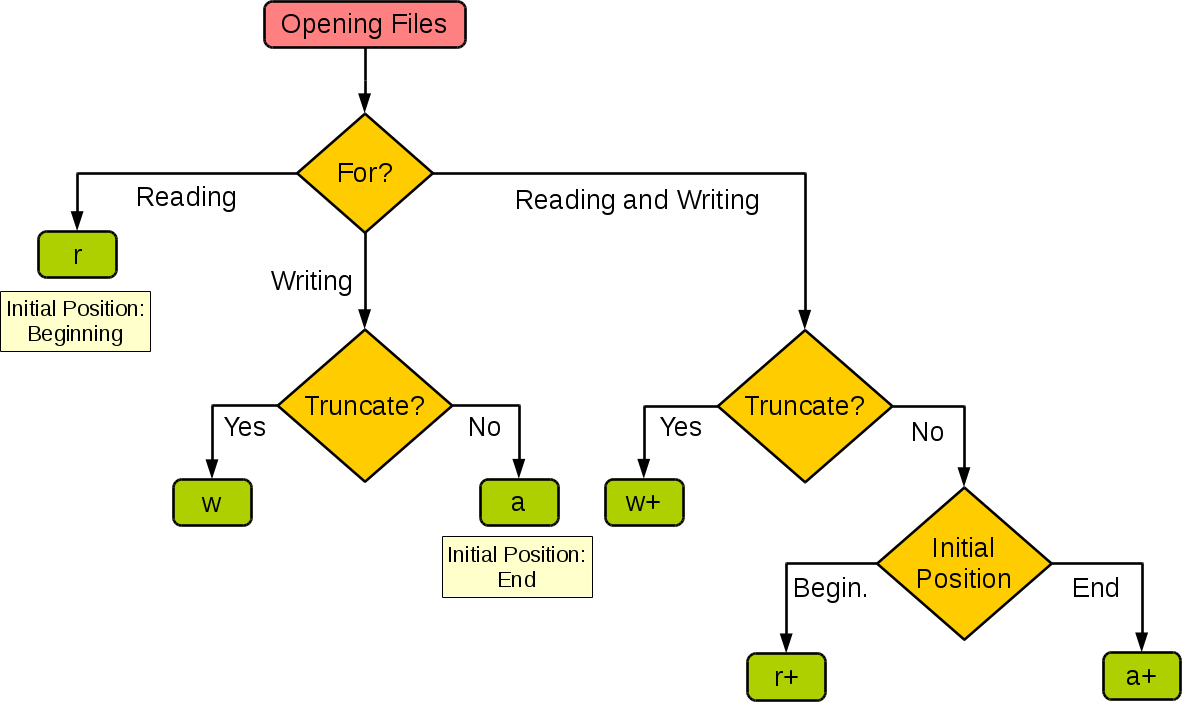
文件读写模式
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
2.10.2 写入文件
语法:
file.write(内容)# 文件操作
# 1.打开文件
# 文件路径:
# 绝对路径: "c:/test/xxx.txt"
# 相对路径:
# “xxx.txt”
f = open("最爱水果.txt", mode="w", encoding="utf-8")
# 2.写入文本内容
# 将列表内容写入分行文件,
list = ["苹果", "葡萄", "枸杞", "山楂", "橘子"]
for line in list:
f.write(line)
f.write("\n")
# 关闭文件
f.close()2.10.3 关闭文件
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
file.close()2.10.4 文件读取read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
# 文件内容读取
fileObject.read([count])
# 按行读取
str = fileObject.readLine()
# 读取所有行
str = fileObject.readLines()
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
# 2.读取文件内容
f2 = open("最爱水果.txt", mode="r", encoding="utf-8")
while True:
line = f2.readline()
print(line)
if len(line) == 0:
break
# 读取全部内容
f2.seek(0)
# 输出:['苹果\n', '葡萄\n', '枸杞\n', '山楂\n', '橘子\n']
print(f2.readlines())
f2.close()2.10.5 文件定位
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
例子:
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "读取的字符串是 : ", str
# 查找当前位置
position = fo.tell()
print "当前文件位置 : ", position
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(10)
print "重新读取字符串 : ", str
# 关闭打开的文件
fo.close()2.10.6 with操作文件
with使用上下文操作文件,不需要对文件对象执行close,退出上下文文件自动关闭。
# 3.通过with操作文件对象
with open("最爱水果.txt", mode="r", encoding="utf-8") as f4:
for line in f4:
print(line)
# 退出with上下文区域f4已经关闭。
# 输出:True
print(f4.closed)2.10.7 重命名和删除文件
Python的os模块提供了帮你执行文件处理操作的方法,比如重命名和删除文件。
要使用这个模块,你必须先导入它,然后才可以调用相关的各种功能。
rename() 方法
rename() 方法需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)import os
# 重命名文件test1.txt到test2.txt。
os.rename( "test1.txt", "test2.txt" )remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)2.10.8 目录操作
所有文件都包含在各个不同的目录下,不过Python也能轻松处理。os模块有许多方法能帮你创建,删除和更改目录。
创建目录mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir("newdir")import os
# 创建目录test
os.mkdir("test")# 4 目录操作
# 创建一个新目录test, 如果目录已经存在则报错
# FileExistsError: [Errno 17] File exists: 'test'
# 通过os.path.exists("test")先判断文件夹是否存在,不存在则创建
if os.path.exists("test") == False:
os.mkdir("test", mode=0o777)chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
import os
# 将当前目录改为"/home/newdir"
os.chdir("/home/newdir")getcwd() 方法
getcwd()方法显示当前的工作目录。
# 显示当前目录
# 输出:/Users/xxx/WORK/DEV/projects/Python
print(os.getcwd())rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir('dirname')文件、目录相关的方法
File 对象和 OS 对象提供了很多文件与目录的操作方法,可以通过点击下面链接查看详情:
参考文献:
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)