
RAG 向量检索:原理、ANN、数据库选型与 Java 落地
RAG 向量检索:原理、ANN、数据库选型与 Java 落地
前面的文章:
先看结论
RAG 里的“检索”,不是按关键词硬匹配,而是把文档和问题都转成向量,再在向量空间里找语义最接近的内容。
你读完这篇可以掌握:
- 向量检索的完整流程
- 余弦相似度、内积、L2 距离怎么选
- 为什么不能直接做全量精确搜索
- HNSW、IVF 这类 ANN(近似最近邻)索引的核心思想
- Milvus、pgvector、Chroma、FAISS、Pinecone、Weaviate 的差异
- Java 项目里怎么做实际选型
1. 向量检索到底在做什么
在 RAG 中,检索的目标不是“找字面相同的内容”,而是“找意思最接近的内容”。
核心思路
- 文本经过 Embedding(向量化模型)后,会变成一个高维向量
- 向量:可以理解成一串数字,里面编码了语义信息
- 用户问题也会被转成向量
- 然后比较“问题向量”和“文档向量”之间的距离或相似度
- 语义越接近,向量越接近
2. RAG 检索的标准流程
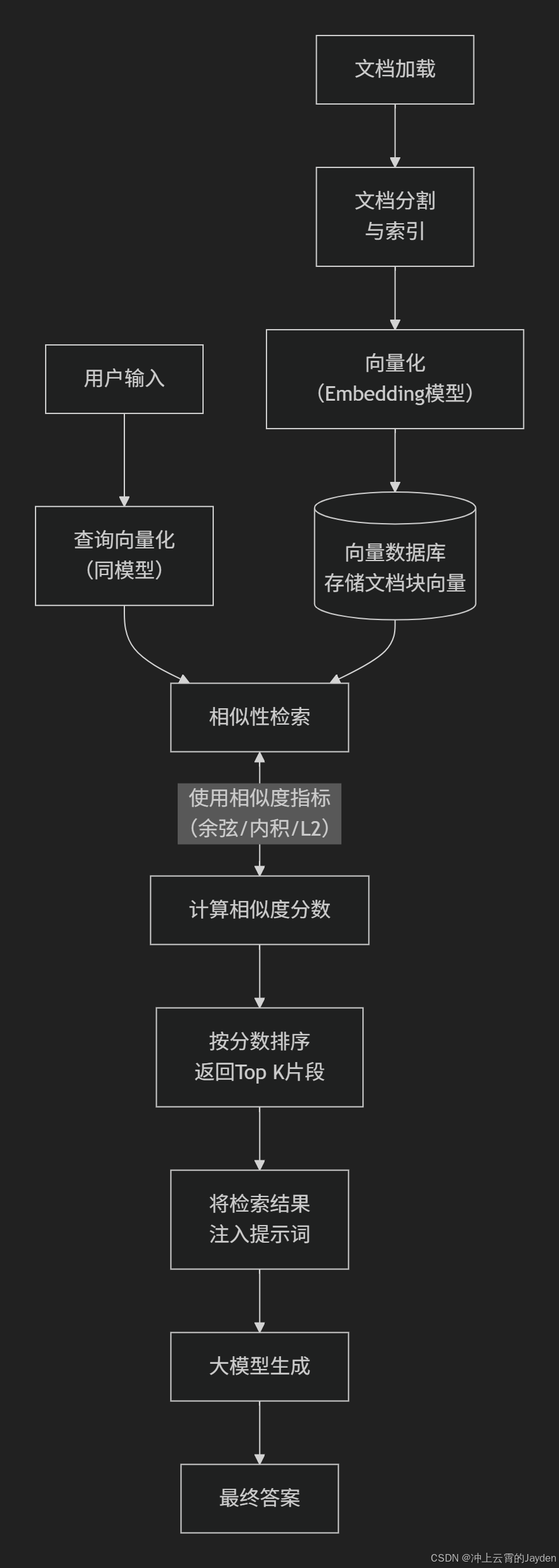
1)文档切块(Chunking)
把长文档切成多个小片段,称为 chunk。
这样做的原因:
- 方便检索
- 便于控制上下文长度
- 减少“整篇太长、模型看不下”的问题
每个 chunk 通常会带上 metadata(元数据),例如:
source:来源title:标题tenant:租户category:类别time:时间doc_id:文档 ID
metadata 的作用:后续可以按业务规则过滤结果,比如“只查某个租户的知识库”。
2)Embedding 向量化
使用 embedding model 把 chunk 转成向量。
常见维度有:
- 768 维
- 1024 维
- 1536 维
维度越高,不一定越好;更重要的是模型效果、速度和成本的平衡。
3)写入向量库
通常会存三类信息:
- 向量
- 原文 chunk
- metadata
这样做的好处:
- 能快速按向量找相似内容
- 能按业务字段过滤
- 能把结果原文返回给大模型
4)查询
用户提问后,也会先转成向量。
然后在向量库里做相似度搜索,取出 topK 结果。
topK:返回最相近的前 K 条结果
5)过滤
在相似度搜索之外,还要加业务过滤条件,例如:
- 只查某个 tenant
- 只查某种文档类型
- 只查某个知识库
- 只查有效状态的数据
这一步非常重要,因为很多生产系统不是“谁相似就给谁”,而是“在允许范围内找最相似”。
6)返回上下文给 LLM
把召回的 chunk 拼进 prompt,让 LLM 基于这些上下文回答。
这就是 RAG 的核心闭环:
检索到相关知识 → 交给模型生成答案
3. 常见相似度指标
向量检索里最常见的三个指标是:
- 余弦相似度(Cosine Similarity)
- 内积(Inner Product)
- L2 距离(欧氏距离)
指标对比
| 指标 | 核心特点 | 适用场景 |
|---|---|---|
| 余弦相似度 | 看两个向量方向是否接近,忽略大小(模长) | 最常用,尤其适合文本语义检索 |
| 内积 | 向量对应元素相乘后求和,结果受模长影响 | 向量未归一化,或模型/系统明确使用内积时 |
| L2 距离 | 看两个向量在空间里的直线距离,越近越相似 | 需要直接比较“距离”的场景 |
简单理解
- 余弦相似度:像看两个箭头方向像不像
- 内积:既看方向,也受长度影响
- L2 距离:像量两点之间直线有多远
实战建议
- 文本语义检索里,余弦相似度最常见
- 如果向量已经归一化,内积和余弦在效果上往往接近
- 具体用哪种,最好和 embedding 模型、向量库配置保持一致
4. 为什么不能直接全量精确搜索
如果有 100 万个 chunk,每次查询都要和这 100 万个向量逐一计算相似度,成本会非常高。
问题主要有两个:
- 延迟高:用户要等很久
- 吞吐低:并发一上来就扛不住
所以实际系统通常不用“全量精确搜”,而是用 ANN。
5. ANN 是什么
ANN(Approximate Nearest Neighbor,近似最近邻)
意思是:不一定找“绝对最精确”的最近邻,但会用更低的成本找到“足够接近”的结果。
它的核心价值是:
- 降低查询延迟
- 提升系统吞吐
- 让大规模向量检索可用
这也是向量数据库的核心能力之一。
6. ANN 基础概念:HNSW / IVF
这里只需要理解思想,不必一开始就死记参数。
6.1 HNSW
HNSW(Hierarchical Navigable Small World)
可以理解成一种“分层导航图”。
思路
- 每个向量是图上的一个点
- 点与点之间建立近邻连接
- 查询时不是全表扫描
- 而是在图中不断跳转,逐步逼近目标
优点
- 查询速度快
- 召回率通常很高
- 很适合通用在线检索
缺点
- 内存占用较高
- 建索引成本相对更大
常见参数
M:每个点保留多少连接efConstruction:建图时搜索范围efSearch:查询时搜索范围
一般来说,
efSearch越大,召回越好,但速度会变慢。
6.2 IVF
IVF(Inverted File Index)
可以理解成“先粗分桶,再桶内搜索”。
思路
- 先把向量聚成很多桶
- 查询时先找最可能相关的几个桶
- 再只在这些桶里搜索
优点
- 大规模数据下效率高
- 比全量扫描快很多
缺点
- 需要先做聚类或训练
- 召回率依赖参数调优
常见参数
nlist:桶的数量nprobe:查询时探测多少个桶
nprobe越大,找得越准,但查询也越慢。
6.3 HNSW 和 IVF 怎么区分
一句话记忆:
- HNSW:像在“路网”里导航找最近地点
- IVF:像先找“区域”,再在区域里细找
6.4 ANN(近似最近邻搜索) 与 余弦相似度、内积、L2距离
RAG、向量检索与文档处理的语境下,ANN(近似最近邻搜索) 与 余弦相似度、内积、L2距离 是“搜索算法”与“判定标准”的关系,两者紧密协作,共同完成高效、准确的向量检索。
下图直观地展示了它们在整个RAG检索流程中的分工与协作关系: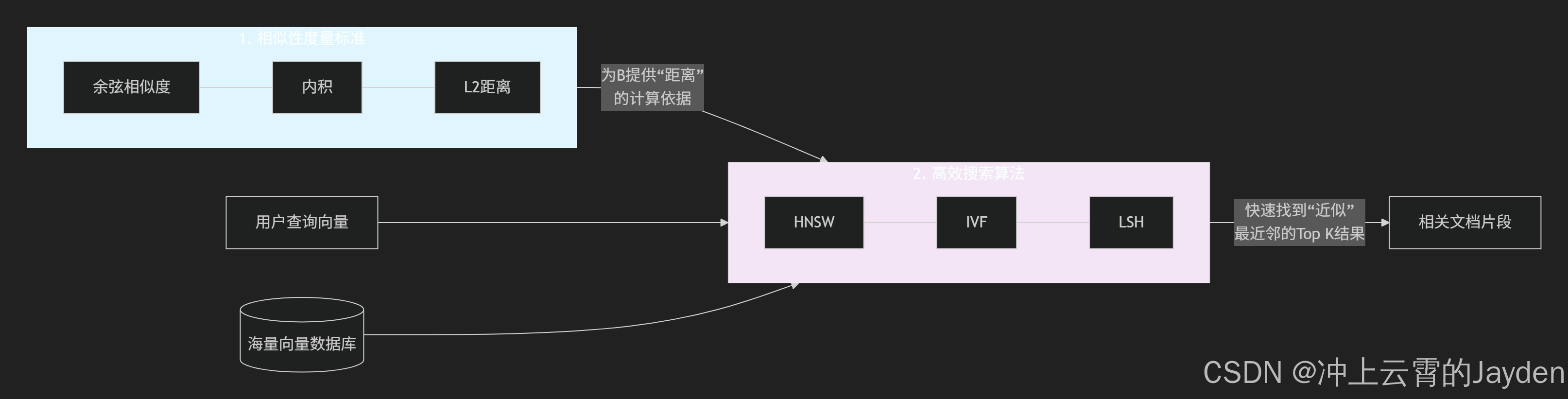
可以从核心角色与分工来理解它们的联系:
- 余弦相似度、内积、L2距离是 “度量标准”。
- 它们定义了在向量空间中,如何计算两个向量之间的“距离”或“相似性”的数值。这回答了“什么叫‘近’?”的问题。
- 在RAG的检索阶段,它们被用来精确计算查询向量与每一个候选向量之间的相关性分数。
- ANN(近似最近邻) 是一种 “搜索算法”。
- 当向量数据库中有数百万甚至数十亿的向量时,用“度量标准”去逐一精确计算与查询向量的距离(即“暴力搜索”),在时间和计算资源上是不可行的。
- ANN算法(如HNSW、IVF、LSH)的目标是牺牲一点点精度,换取巨大的速度提升,快速地找到与查询向量“很可能最近邻”的那一小部分候选向量。这回答了“如何在海量数据中快速找到‘近邻’?”的问题。
工作中怎么选
- 通用在线检索:优先看 HNSW
- 超大规模、需要更细调参:看 IVF / IVFFlat / IVF_PQ
7. 常见向量工具对比
下面是面向 Java 项目落地的实用对比。
| 方案 | 类型 | 优势 | 劣势 | 适合场景 |
|---|---|---|---|---|
| Milvus | 专用向量数据库 | 向量检索强、索引丰富、适合大规模和高吞吐 | 部署和运维比 PostgreSQL 复杂 | 独立检索服务、大规模 RAG、向量为核心业务 |
| pgvector | PostgreSQL 扩展 | SQL 生态成熟、易联表、事务能力强、团队容易接受 | 极大规模纯向量检索能力不如专用向量库 | 已有 PostgreSQL、过滤复杂、业务和检索数据强关联 |
| Chroma | 轻量向量库 | 本地开发简单、POC 快 | 分布式、治理、生产能力相对弱 | 本地开发、Demo、POC、小型应用 |
| FAISS | 向量检索库,不是完整数据库 | 性能好、灵活、适合研究和本地服务 | 不负责持久化、多租户、权限、HA 等完整能力 | 单机检索、离线构建、研究型项目 |
| Pinecone | 托管型向量数据库 | 免运维、上手快 | 成本和厂商依赖需要评估 | 云原生团队、想快速上线 |
| Weaviate | 向量数据库/知识对象存储 | 对象模型清晰,支持混合检索 | 学习和运维成本更高 | 需要对象化知识建模、Hybrid Search |
8. Java 项目里的选型逻辑
这是最重要的一部分。
先问 5 个问题
1)你们是否已经大量使用 PostgreSQL?
如果是,优先考虑 pgvector。
原因:
- 团队熟悉
- 运维成熟
- SQL 能力强
- metadata 过滤天然方便
- 可以和业务表直接联查
2)向量检索是不是核心能力?
如果向量检索本身就是核心服务,比如:
- 大规模知识库
- 高并发召回
- 多租户检索平台
- 独立 AI 检索中台
优先考虑 Milvus。
3)数据规模有多大?
可以粗略这样理解:
- 小到中等规模,且业务数据本来就在 PostgreSQL 中:先看 pgvector
- 中大规模到超大规模,且对召回性能敏感:先看 Milvus
不建议只按“多少条数据”机械判断,还要看向量维度、QPS、过滤复杂度和硬件资源。
4)metadata 过滤复杂吗?
如果经常需要:
- tenant 过滤
- 时间范围过滤
- 类型过滤
- 状态过滤
- 权限过滤
- 和业务字段联查
那 pgvector 往往更顺手,因为本质上还是 PostgreSQL 生态。
5)团队有没有能力运维专用向量库?
如果没有专门运维能力,而且你们已经有稳定的 PostgreSQL:
- pgvector 的组织成本通常更低
9. 为什么生产环境常优先 Milvus / pgvector,而不是只用 Chroma
Chroma 很适合本地开发、快速验证和小型场景,但在很多生产环境里,Milvus 或 pgvector 更常作为优先候选。
1)运维成熟度
- pgvector 背靠 PostgreSQL,备份、监控、权限、迁移、HA 方案成熟
- Milvus 是专门做向量检索的数据库,更适合规模化生产
- Chroma 更偏轻量和开发友好,生产治理能力不是强项
2)扩展能力
- Milvus 更适合大规模、高 QPS 检索
- pgvector 更适合业务数据和检索数据一体化管理
- Chroma 做 POC 很舒服,但系统变复杂后,扩展压力会更早暴露
3)过滤与业务集成
- pgvector 用 SQL / JSONB 做 metadata 过滤很自然
- Milvus 也支持标量过滤,适合检索型系统
- Chroma 在复杂业务过滤和治理方面通常不是首选
4)团队协作成本
Java 团队常见两条成熟路线:
- 已有 PostgreSQL 体系 → pgvector
- 构建专门检索平台 → Milvus
这两条路线通常更容易形成长期维护能力。
10. 实战里再补 3 个小建议
1)Chunk 不是越大越好
- 太大:检索不准,噪声多
- 太小:上下文不完整,信息碎片化
通常要结合文档结构调优。
2)topK 不是越大越好
返回太多结果会让:
- prompt 变长
- 成本升高
- 相关内容反而被噪声淹没
常见做法是:
- 先召回一批
- 再做 重排序(rerank)
rerank:对候选结果再做一次更精细的排序
3)先过滤,再检索,通常更稳
如果业务本来就限定了范围,比如:
- 只看某个租户
- 只看某个知识库
- 只看某种状态
尽量先把范围收窄,再做向量检索,效果通常更好。
11. 最后的选型口诀
- PostgreSQL 已经很成熟 → 先看 pgvector
- 向量检索是核心能力 → 优先 Milvus
- 本地验证 / Demo / POC → 用 Chroma 或 FAISS
- 想免运维 → 看 Pinecone
- 需要对象化建模和混合检索 → 看 Weaviate
如果只记一句话:
RAG 检索的本质,是在业务约束下,找到语义最接近、最可用的上下文。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)