
DeepSeek 玩转 MoE 并行的底层逻辑

来源:机器学习算法与自然语言处理 知乎
本文约5000字,建议阅读10分钟本文介绍了 DeepSeek MoE 模型并行策略及 GPU 计算与通信优化方法。最近模型从Dense切到了MoE,MFU也相应地暴跌了,大家直觉上觉得Expert被切的很小,所以计算强度上不去,但实际切分完的维度至少也有1024,MFU暴跌的原因一定不来自这里。
深入理解这个问题,就是理解GPU的分布式并行计算,要在计算和访存bound之外,引入通信bound,而解决吞吐和MFU的问题的手段,就是设计合理的GPU并行策略,做好GPU计算和通信的遮掩(overlap)。
DeepSeek的H800和昇腾卡,8卡nvlink高速互联,跨节点都是IB(InfiniBand)低速网络,我们手里虽然有B200,但实际也也没用上NVL72,所以DeepSeek的并行策略有普适的借鉴意义——硬件基础相似,低成本方案,新的 MoE 的方案也做了开源。
DeepSeek 的并行策略
V4重点讲了EP策略的计算和通信遮掩,没有细讲它的并行策略,它是延续DeepSeek-V3 的。
Our training framework is built upon the scalable and efficient infrastructure developed for DeepSeek-V3.In training DeepSeek-V4, we inherit this robust foundation
V3披露的硬件是2048张H800,8卡节点内nvlink互联,并行策略是16-way PP×64-way EP×ZeRO-1 DP。
这里先说下nvlink和IB的差异,nvlink下的8卡内速度可以到900GB/s,而节点间的IB速度为50GB/s。EP跨节点占用了IB带宽,这里是主要的通信bound,这里的每一份通信安排都至关重要,这也造就了DeepSeek的精妙的并行策略选择。
在展开更多细节之前,先搞清楚什么是GPU并行策略?
最朴素的并行策略就是DP(Data Parallel,数据并行),每一张卡保存了全部参数,读不同的数据,做不同的计算,最后合并梯度做更新。在模型参数不大的年代里,这是最自然的并行方式。
模型开始变大,GPU的显存装不下了,就要考虑怎么拆分存储,计算用的inputs和weights不在一块GPU上,那么就要进行通信。
多大的模型就参数,就要考虑做拆分了?几百B的模型自然装不进一张H100(80B),那10B的模型呢?这就是一个经典问题,训练时模型的显存占用有多大。
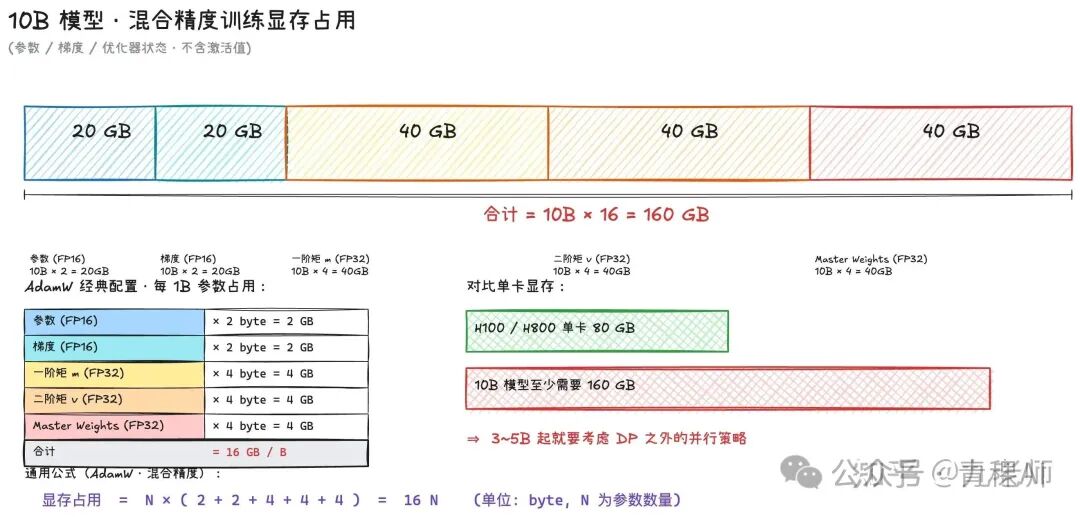
显存里要放哪些东西?答案是参数/梯度/优化器状态/激活值。
一个10B的模型,在FP16混合精度下,参数是2字节,那么就是20GB的存储;而梯度也是FP16,那么又是20GB的存储;优化器的状态就复杂了,以 经典AdamW为例子,两个一阶矩和二阶矩都要用FP32存,这就要2x4x10=80GB了,再加一个Master Weights,以FP32存储,那就是4x10=40GB。
所以,在不考虑任何激活值和系统占用的情况下,光是参数/梯度/优化器就10x16=160GB了。
再考虑上激活值,一个模型3~5B就要思考它在朴素DP之外的分布式并行策略了。
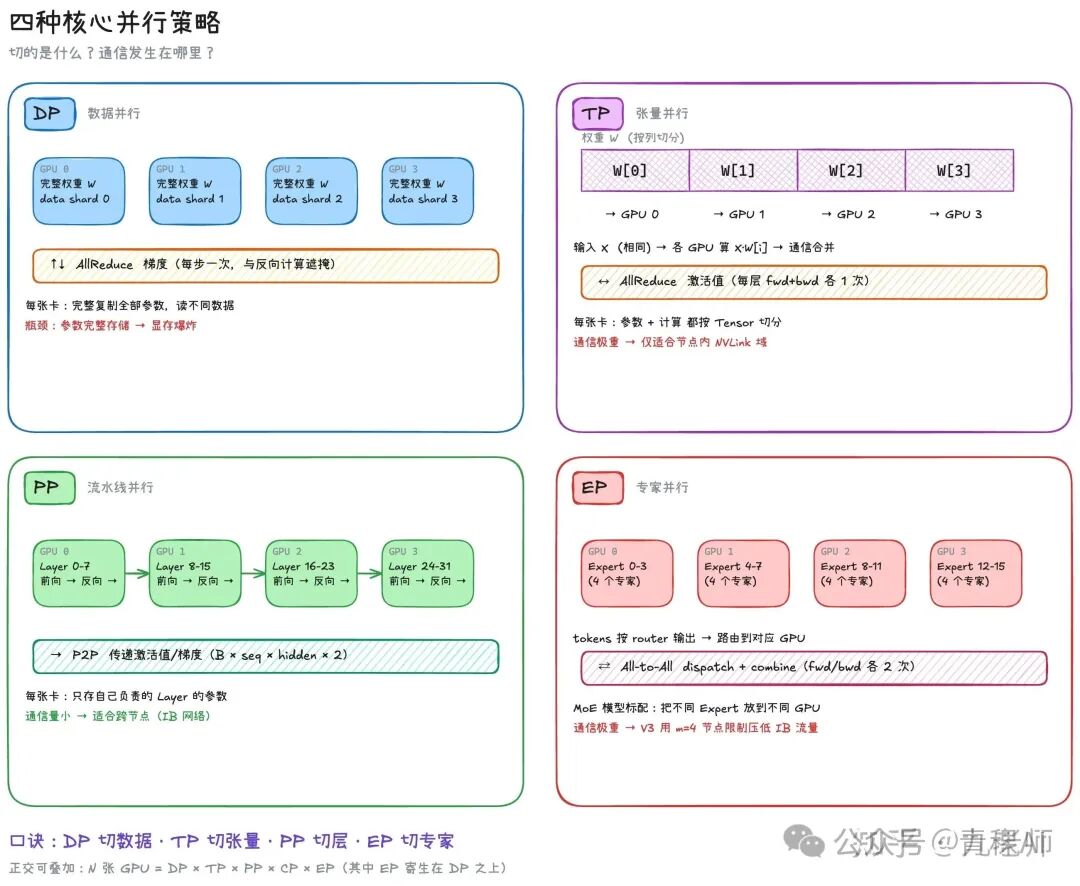
几种常见的策略:
DP基础上,计算不变,把存储拆分到多个GPU卡上,每卡只存一部分。如果拆分的是12倍的优化器状态,那么这就是ZeRO-1(Zero RedundancyOptimizer);把梯度也做了拆分,这就是ZeRO-2;如果把模型参数则做了拆分,那这就是ZeRO-3,也叫FSDP(Fully Sharded Data Parallel)。
TP(Tensor Parallel)是按参数的Tensor做切分,放在不同的 GPU上存储和计算。这里经常出现的混淆是,FSDP也切分了参数,它和 DP 有什么区别?
答案是FSDP只是切分了存储,没有切分计算,它本身还是DP,需要做前向计算的时候先把其他GPU上的参数shard拉回来,组成完整的 Tensor,和朴素DP一样做前向的计算,而 TP 则是同时也拆分了计算,不同的GPU读的是相同的数据,做了不同shardTensor的计算,再通信合并计算结果。
TP的特点是通信量大,适合放在 nvlink 域内。
PP(Pipeline Parallel),它是最好理解的,Transformer 的不同的 Layers拆到一组GPU上做计算,多组GPU就形成了一条流水线,这就自然地按层拆分了存储和计算。它的通信量小,适合跨节点。
EP(Expert Parallel),它是MoE模型的标配。它实际和 TP 有一点像(都是参数拆分存储和计算),Expert是天然拆分的,放在不同的 GPU上存储参数,在计算时,token路由到对应的GPU完成Expert 的计算,然后再把结果Combine回来。通信量也重,DeepSeek的关键优化就是怎么能在 IB 网络上把EP=64跑明白。
CP(Context Parallel),在Attention内部沿seq切激活,每张卡算一段的OKVO,Attention的时候做跨GPU通信。V3中没有提到,V4中1M上下文装不下,做了sequence维度的切分,一般出现在预训练的long context 阶段或post-train中。
多种并行策略可以叠加吗?
如果你有 N 块 GPU,上面的各种并行策略是正交的,他们可以进行叠加,比如基础的3D并行是DPxTPxPP,并且是DPxTPxPP=N。
EP特殊,它可以寄生在DP之上,就是可以共用卡。比如一个5D并行:N=DP_totalxTPxPPxCP,其中DP_total=EPxDP_replica, DP_replica代表模型权重完全复制的组数。
再看下DeepSeek的例子,2048张GPU,PP=16,EP=64,实际 DP_total=128,DP_replica=2.就是模型实际就2个完整副本,内部做EP,GBS(global batch size)=MBS(micro-batch size)xDP_totalxgrad_accum_steps。
EP 能和 DP 共用卡,是个特例。EP 是唯一一个”在 forward pass 内部把 token 重新换主”的并行维度——它通过 all-to-all 让 token 临时离开自己的 DP rank、被另一组卡处理、再送回来。
假如教室是GPU,每个学生(数据)有自己的教室,每个班主任(Expert)有自己的教室,它同时作为选修课老师给所有教室的学生上课,那就是上课的时候让学生重组下教室,下课的时候他们再回去。
TP 为什不行,它实际要求所有老师合上一节课,又不能离开自己的教室,学生必须要分身去上课了;EP 可以是因为它的MoE稀疏性和 Expert 的独立性。
先让 EP 在 IB 网络上跑起来
EP策略是包括dispatch,Expert计算,Combine多个串行流程,dispatch是把token通过all-to-all给到所在专家的GPU上,完成计算后,Combine把结果用 all-to-all传回来。
为了使得节点间通信不爆炸,它在做专家选取的时候,限制只能在 4 个平均最优的节点内选8个专家,使得跨节点通信次数减少,但这并不是最优的专家选择,而在 V4 中则取消了这个限制。
为什么这么做可以限制 IB 上的通信量呢?如果top-k=8,然后这8 个专家又恰好在8个不同的节点里,那么所以的通信走的都是IB网络。
限制了最多4个节点,那么平均每个节点要路由到2个GPU,它可以在 IB 网络上归并传输的信息,先交给目标节点里的一块GPU,再由它通过NVlink转发到对应的GPU,把IB通信量转成NVlink通信量,就是降低了通信的时长,这里争取的通信时长越低,后续EP的计算通信遮掩就变得越容易。
DP ZeRO-1 和 EP/PP 的组合
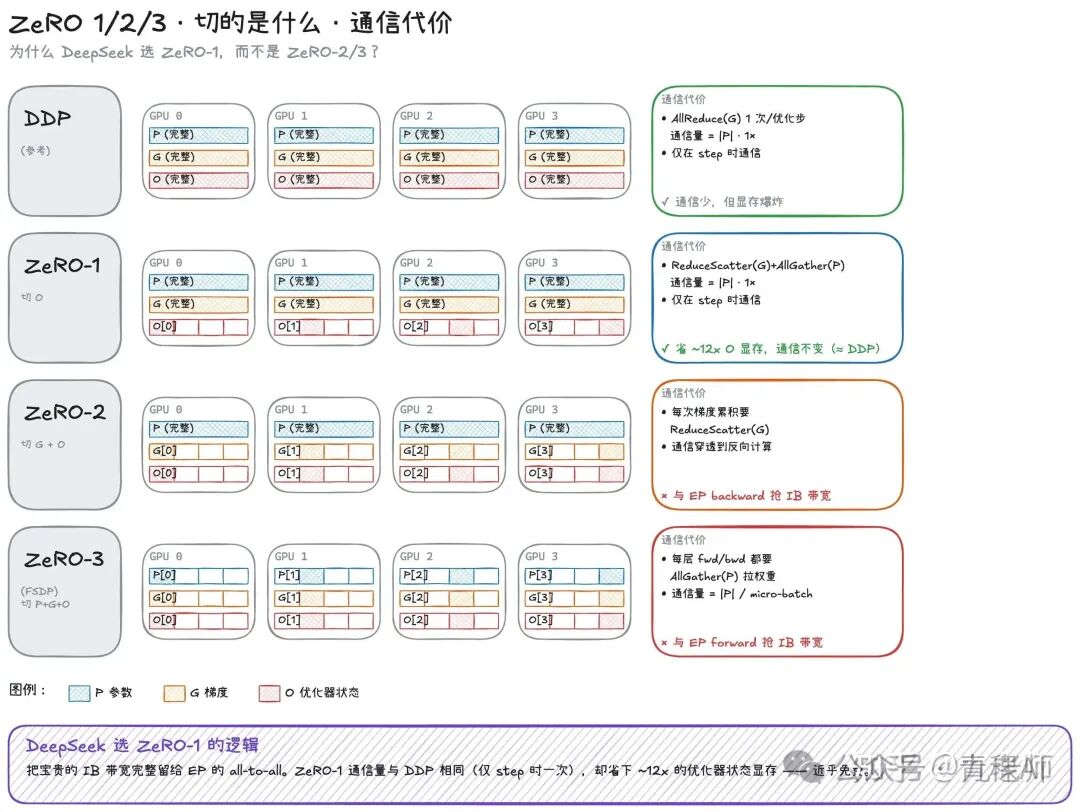
因为Transformer是天然分层的,DP天然计算和通信可遮掩。ZeRO 本质是切参数,计算都发生在当前 GPU 上,这是天然可遮掩的条件。
DP,我在反向传播的时候,计算下一层的时候,上一层可以把刚才的梯度做all-reduce。
ZeRO-1/2,因为优化器和梯度是分片的,做reduce-scatter把自己梯度 shard 做更新,然后更新优化器状态,权重更新后做一次 all-gather更新权重。
ZeRO-3/FSDP,是每次前向都做一个all-gather,但可以再上一层算的时候,all-gather 拉下一层的参数。
DP选择了ZeRO-1,而非FSDP/ZeRO-3或ZeRO-2,这背后的选择是避免和EP的通信墙IB带宽。首先ZeRO-3每次前向都要all-gather取到权重参数,一次micro-batch的通信量就是参数量(GB级别),这和EP的forward 直接形成了IB带宽抢占。
ZeRO-2 GPU只保留部分梯度,那梯度累积的时候就不能像ZeRO-1那样只是本GPU累加,而是要reduce-scatter通信,通信量也是参数量(GB 级别),和EP的 backward 抢占IB带宽。
而ZeRO-1,在非优化器step是没有通信的,这和DDP一样;优化器步骤做更新只能更新本GPU的参数,因而需要做一次all-gather 才能拿到正确的参数。
由于DP和ZeRO本来就要在优化器步做一次all-reduce把梯度累加,all-reduce可以拆成reduce-scatter和all-gather,那在reduce-scatter后每一个shard优化器对应的梯度都是对的了,把完成参数更新后,再all-gather一次参数即可,那么原本梯度的all-gather替换成了更新后的参数all-gather,ZeRO-1的通信量和普通 DP一模一样,却省了接近12倍参数的显存,这就是ZeRO-1是近乎免费的原因。
DeepSeek 选择把宝贵的 IB 带宽留给了 EP 的通信。
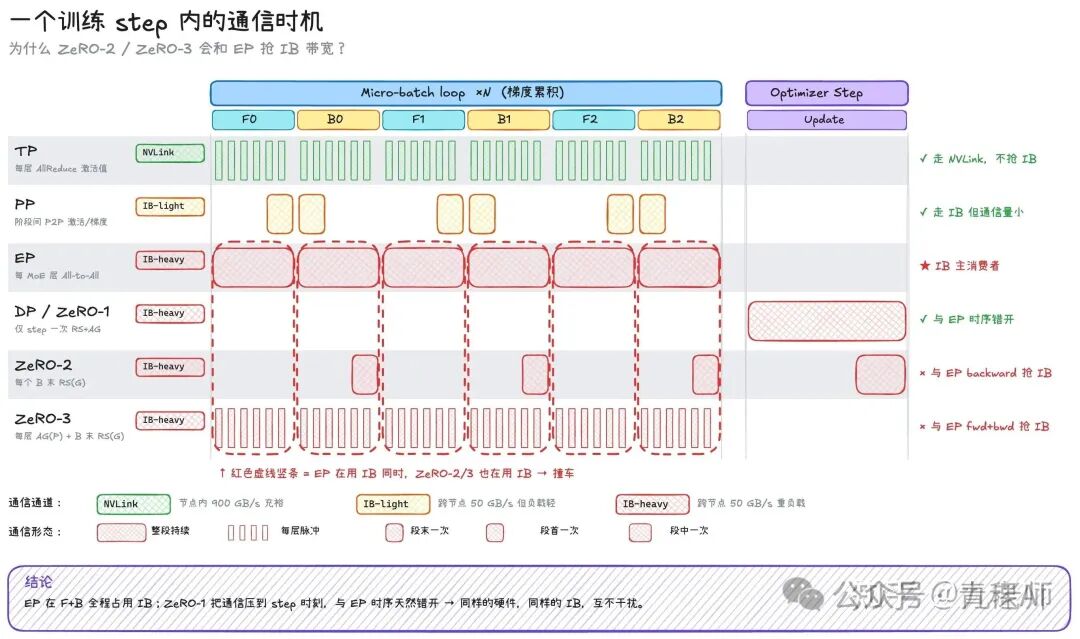
EP的all-to-all操作,通信量是BxLxseq_lenxtop-kxhidden_sizex4.其中forward和backward分别有两次all-to-all。这个几乎把IB通信占住了,通信量打到了IB带宽的同量级。
选 PP 也很自然,H800 是 8 卡互联,跨节点通信速度从 900GB/s的nvlink降低到50GB/s的InfiniBand,PP的通信量小(Bxseq_lenxhidden_sizex2),适合跨节点,也避免了抢IB 带宽。
综合看,PP+EP+DP ZeRO-1,没用TP,没有ZeRO-2/3,避开了在每一个micro-batch上去抢占EP 的 宝贵 IB带宽,使得整体的并行策略能够在低配硬件下顺利进行。
PP 的气泡挤压
PP的通信量很小,所以不存在遮掩的问题,它是因为要等反向计算而产生的流水线气泡。上图为最朴素的PP——GPipe,这个方案已经废弃了,只是为了说明气泡问题。

1F1B(1Forward1Backward)的策略是在做完F0,直接接一个B0,开始交替一次 forward 一次 backward,实际并不能减少气泡,但是由于激活可以更早丢掉,那么显存占用更小,可以增大micro-batch数M变相增大了计算比例,挤压了气泡。
GPipe 和 1F1B 的气泡占比都是 (P-1) / (M+P-1),P 是 PP 数,M 是一个 step 的 micro-batch 数。
ZB1P(Zero Bubble PP)的解决方案是在 1F1B 基础上,把每一层反向计算做一个拆解,反向计算是根据 dy 来计算 dx 和 dw 的过程,前一层之所以不能进行计算是依赖了 dx,那么先把 dx 计算出来,往回挤压气泡,把 dw 的计算留到气泡产生时发生。
但也因为要延迟计算 dW = x^T · dy,它的底料x 也就是激活值不能立即释放,相当于用一些显存的占用换了计算。
DualPipe:挤压气泡同时搞定 EP 的通信计算遮掩
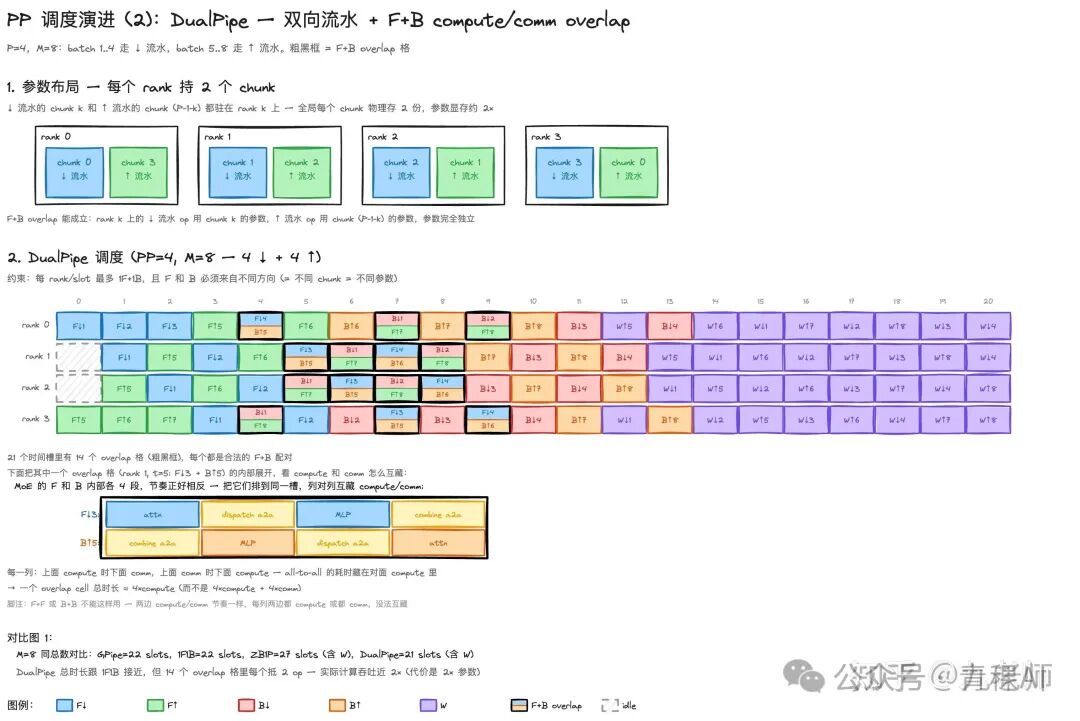
DeepSeek-V3就引入了DualPipe方案,它是在ZB1P基础上,在 PP 上形成两条反向的 micro-batch,使得 Forward 和 Backward 恰好把计算和通信错开,挤压气泡的同时把 EP 的通信遮掩到了计算背后。
EP 的计算和通信的流程是串行的,forward 的时候通过一次 all-to-all 把token的hidden路由到对应专家的GPU(dispatch),完成计算,然后把结果用一次all-to-all再发回原GPU(combine),也是天然不可遮掩。
EP 吃了最大头的 IB带宽, DeepSeek V3 和 V4 都在讲它的通信和计算时间接近 1:1,能不能把通信遮掩到计算背后就成了关键。
每一个rank持有两份参数,也就是 micro-batch 可以从 rank0 留到 rank3,反之也可以从 rank3 流到 rank0. 每一个 step 开始,双向做 forward,当双向第一个 Backward 到来后,它与逆向的 forward 发生了交叠。
交叠处,一个正向[attention, dispatch, MLP, combine]与一个逆向的发生了通信和计算的遮盖。DualPipe 的副作用就是显存占用增加了一倍,PP+EP+ZeRO-1 已经把显存占用切到很小了,V3 paper 说这可以接受。
具体的实现上,H800共132个SM,划出20个SM专门做通信,剩下的给计算。传统 NCCL 的工作模式是SM-shared:通信 kernel 和计算 kernel 共享 SM 池,每个 kernel 启动时按需占用一些SM。这 20 个 SM 跑的是 DeepSeek 自己写的 PTX 级通信 kernel,不是 NCCL。
V4 的 Waved-EP 通信计算遮掩
Waved-EP是一个DeepSeek-V4的新的EP计算通信遮掩方案,一个 kernel 直接在 MoE 层解决问题,不再依赖PP调度了,它思路很简单:直接把 Expert 切成几个wave,在不同wave之间做通信遮掩。
既然DualPipe已经能够遮掩掉EP阶段的all-to-all通信,那为什么还要做Waved-EP的新kernel呢?论文给的答案是,在小 batch 的RL 或推理情况下,DualPipe 就不够用了。
原理上推理就没有Backward,那也就无法和Forward做相互一一对应的通信遮掩了。所以对比baseline(Comet),RL场景下1.96x加速,通用场景下1.50 ~ 1.73×。
当然,论文并没有对比DualPipe的遮掩,因为V3也是100% 遮掩,大 batch场景下应该长不多。
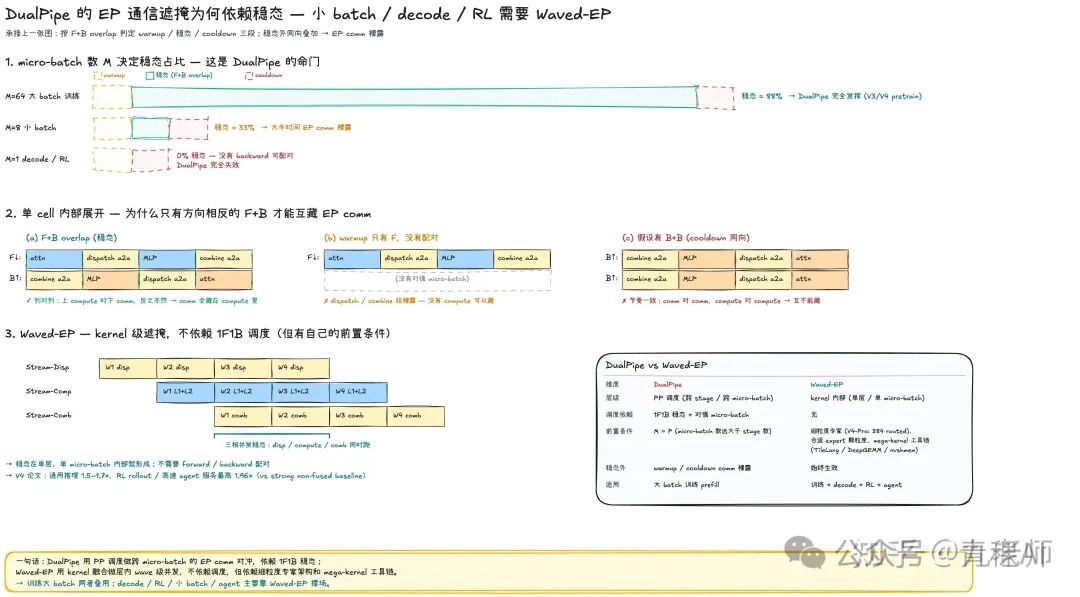
为什么DualPipe依赖大 Batch?PP 在 1F1B 基础上做交叠,可以大致分成3个阶段:warmup全F,没有B配对;稳态F+B overlap;cooldown是纯 B/W 排空。warmup 阶段只有 F,cooldown 阶段只有 B,那就无从遮掩通信,F和F/B和B 交叠下,通信和计算没法交错,也无法遮掩。
DualPipe的Forward和Backward遮掩,就发生在稳态阶段,稳态的长度依赖于M(micro-batch 的数量),batch size=Mxmicro-batch x DP。所以RL或Long Context这种小 batch 下,M 过小,稳态过短,遮掩的效果就大打折扣。
DeepSeek V4的方法,是一个kernel直接在MoE层解决问题,不再依赖 PP 调度了。
它是把Expert分成几组,每组一个wave,dispatch确保第一个 wave通信完成,就开启计算,同时第二个wave的dispatch也在进行,算完了就直接Combine,每一个wave内串行,但wave间的 dispatch/L1+Act+L2 计算/Combine 就可以并行起来了。
他是kernel级别的方案,那么就无所谓训练还是推理,大Batch还是小Batch,更多的依赖来自于细粒度专家的模型设计,wave过少第一个dispatch和最后一个Combine暴露无法遮掩。
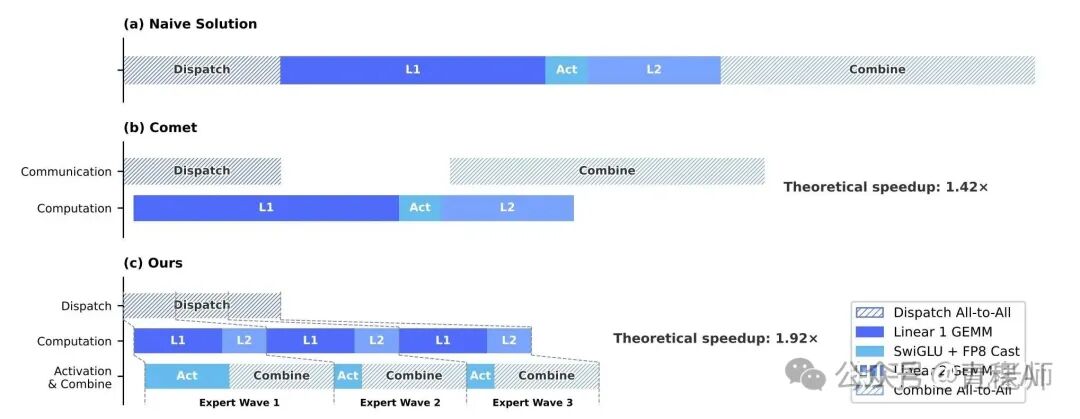
这个 kernel 是用 TileLang 框架完成的,这么精细化的通信和计算的控制,triton 是很难完成的。以下是 Claude 的评价:
Triton 不是为通信和计算融合设计的,它的核心抽象是「单 GPU 内部的高性能 GEMM/element-wise kernel」,对跨 GPU 通信原语(nvshmem、IB send/recv)支持很差或没有。Waved-EP 这种 mega-kernel 要把 dispatch (NVSHMEM put/get) + GEMM + combine 融在一个 kernel 里,Triton 根本写不出来。
TileLang 的优势不只是「更容易控制通信遮掩」,而是 它能写出 Triton 写不出来的 kernel。这是质的差别,不是程度差别。
TileLang 是 V4 论文 §3.2 自己介绍的工具(论文引用 Wang et al., 2026)。它的设计哲学跟 Triton 不一样 —— 既要 Triton 那样的高生产力 DSL,也要保留 PTX/CUDA 级的底层控制权。
DeepSeek 会通过极致的并行策略设计和 kernel 级别的通信遮掩,8 卡节点+IB 网络也能玩转 1T 以上模型,甚至建议厂商不要一味地堆通信带宽,而是看GPU 在计算和通信遮掩时的总功率是否能支撑,导向是硬件对计算和通信并行做更好地支撑。
而Nvdia 的发展路径就是通过 NVlink 连接更多的卡,GB200 是 72 卡互联,明年 Rubin 的 Ultra 是NVL576。让你 GPU 并行时更容易搞出来 5D 并行,带宽足够快,把 N 块 GPU 当成一个整体来用。
我也很感慨,上次看到评论区有人瞧不上 LLM 的“力大砖飞”,实际上我觉得在这种极致地工程能力下,在计算和通信上的平衡堪称艺术,比那种模型结构的奇技淫巧要高牛的多。
还有一些没写到的
-
引入 muon 后,ZeRO-1 没法切元素了,如何按矩阵做拆分。
-
DualPipe-V,虽然 DeepSeek-V4 没明确引入,这个方法可以把 DualPipe 冗余的参数去掉,把激活值恢复到 1F1B 的 1 倍量。
-
CP ,怎么和 Attention 压缩配合
reference
1.https://arxiv.org/pdf/2512.24880 2.https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek\_V4.pdf 3.https://arxiv.org/pdf/2412.1943
编辑:于腾凯
校对:李享沣
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)