
C++ -- 异常及智能指针
一. 异常的概念及使⽤
1.1 异常的概念
• 异常处理机制允许程序中独⽴开发的部分能够在运⾏时就出现的问题进⾏通信并做出相应的处理, 异常使得我们能够将问题的检测与解决问题的过程分开,程序的⼀部分负责检测问题的出现,然后 解决问题的任务传递给程序的另⼀部分,检测环节⽆须知道问题的处理模块的所有细节。
• C语⾔主要通过错误码的形式处理错误,错误码本质就是对错误信息进⾏分类编号,拿到错误码以 后还要去查询错误信息,⽐较⿇烦。异常时抛出⼀个对象,这个对象可以函数更全⾯的各种信息。
1.2 异常的抛出和捕获
• 程序出现问题时,我们通过抛出(throw)⼀个对象来引发⼀个异常,该对象的类型以及当前的调⽤ 链决定了应该由哪个catch的处理代码来处理该异常。
• 被选中的处理代码是调⽤链中与该对象类型匹配且离抛出异常位置最近的那⼀个。根据抛出对象的 类型和内容,程序的抛出异常部分告知异常处理部分到底发⽣了什么错误。
• 当throw执⾏时,throw后⾯的语句将不再被执⾏。程序的执⾏从throw位置跳到与之匹配的catch 模块,catch可能是同⼀函数中的⼀个局部的catch,也可能是调⽤链中另⼀个函数中的catch,控 制权从throw位置转移到了catch位置。这⾥还有两个重要的含义:1、沿着调⽤链的函数可能提早 退出。2、⼀旦程序开始执⾏异常处理程序,沿着调⽤链创建的对象都将销毁。
• 抛出异常对象后,会⽣成⼀个异常对象的拷⻉,因为抛出的异常对象可能是⼀个局部对象,所以会 ⽣成⼀个拷⻉对象,这个拷⻉的对象会在catch⼦句后销毁。(这⾥的处理类似于函数的传值返 回)
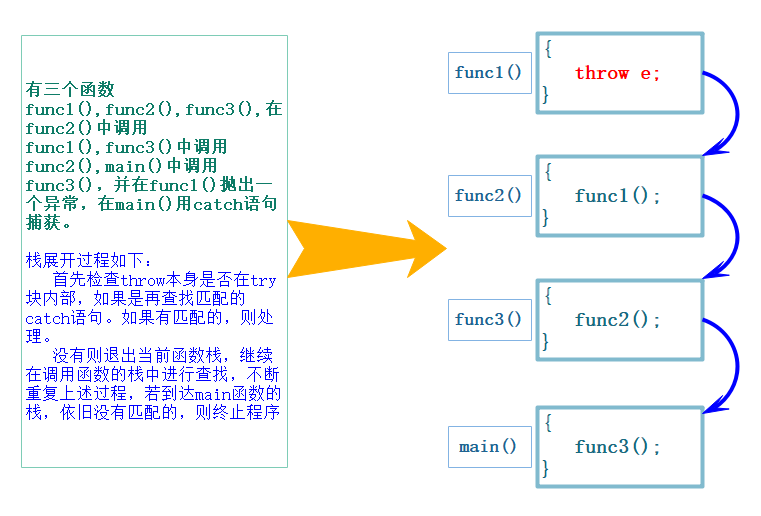
1.3 栈展开
• 抛出异常后,程序暂停当前函数的执⾏,开始寻找与之匹配的catch⼦句,⾸先检查throw本⾝是否 在try块内部,如果在则查找匹配的catch语句,如果有匹配的,则跳到catch的地⽅进⾏处理。
• 如果当前函数中没有try/catch⼦句,或者有try/catch⼦句但是类型不匹配,则退出当前函数,继续 在外层调⽤函数链中查找,上述查找的catch过程被称为栈展开。
• 如果到达main函数,依旧没有找到匹配的catch⼦句,程序会调⽤标准库的 terminate 函数终⽌ 程序。
• 如果找到匹配的catch⼦句处理后,catch⼦句代码会继续执⾏。
double Divide(int a, int b)
{
try
{
// 当b == 0时抛出异常
if (b == 0)
{
string s("Divide by zero condition!");
throw s;
}
else
{
return ((double)a / (double)b);
}
}
catch (int errid)
{
cout << errid << endl;
}
return 0;
}
void Func()
{
int len, time;
cin >> len >> time;
try
{
cout << Divide(len, time) << endl;
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
cout <<__FUNCTION__<<":" << __LINE__ << "⾏执⾏" << endl;
}
int main()
{
while (1)
{
try
{
Func();
}
catch (const string& errmsg)
{
cout << errmsg << endl;
}
}
return 0;
}
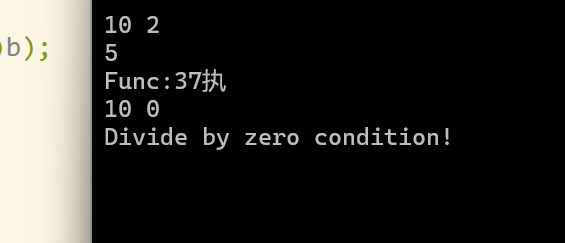
测试用例:
1.4 查找匹配的处理代码
• ⼀般情况下抛出对象和catch是类型完全匹配的,如果有多个类型匹配的,就选择离他位置更近的 那个。
• 但是也有⼀些例外,允许从⾮常量向常量的类型转换,也就是权限缩⼩;允许数组转换成指向数组 元素类型的指针,函数被转换成指向函数的指针;允许从派⽣类向基类类型的转换,这个点⾮常实 ⽤,实际中继承体系基本都是⽤这个⽅式设计的。
• 如果到main函数,异常仍旧没有被匹配就会终⽌程序,不是发⽣严重错误的情况下,我们是不期望 程序终⽌的,所以⼀般main函数中最后都会使⽤catch(...),它可以捕获任意类型的异常,但是是 不知道异常错误是什么。
1.5 异常重新抛出
有时catch到⼀个异常对象后,需要对错误进⾏分类,其中的某种异常错误需要进⾏特殊的处理,其他 错误则重新抛出异常给外层调⽤链处理。捕获异常后需要重新抛出,直接 throw; 就可以把捕获的对 象直接抛出
1.6 异常安全问题
• 异常抛出后,后⾯的代码就不再执⾏,前⾯申请了资源(内存、锁等),后⾯进⾏释放,但是中间可 能会抛异常就会导致资源没有释放,这⾥由于异常就引发了资源泄漏,产⽣安全性的问题。中间我 们需要捕获异常,释放资源后⾯再重新抛出,当然后⾯智能指针章节讲的RAII⽅式解决这种问题是 更好的。
• 其次析构函数中,如果抛出异常也要谨慎处理,⽐如析构函数要释放10个资源,释放到第5个时抛 出异常,则也需要捕获处理,否则后⾯的5个资源就没释放,也资源泄漏了。《Effctive C++》第8 个条款也专⻔讲了这个问题,别让异常逃离析构函数。
double Divide(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
throw "Division by zero condition!";
}
return (double)a / (double)b;
}
void Func()
{
// 这⾥可以看到如果发⽣除0错误抛出异常,另外下⾯的array没有得到释放。
// 所以这⾥捕获异常后并不处理异常,异常还是交给外层处理,这⾥捕获了再
// 重新抛出去。
int* array = new int[10];
try
{
int len, time;
cin >> len >> time;
cout << Divide(len, time) << endl;
}
catch (...)
{
// 捕获异常释放内存
cout << "delete []" << array << endl;
delete[] array;
throw; // 异常重新抛出,捕获到什么抛出什么
}
cout << "delete []" << array << endl;
delete[] array;
}
int main()
{
try
{
Func();
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
catch (const exception& e)
{
cout << e.what() << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
return 0;
}
1.7 异常规范
• 对于⽤⼾和编译器⽽⾔,预先知道某个程序会不会抛出异常⼤有裨益,知道某个函数是否会抛出异 常有助于简化调⽤函数的代码。
• C++98中函数参数列表的后⾯接throw(),表⽰函数不抛异常,函数参数列表的后⾯接throw(类型1, 类型2...)表⽰可能会抛出多种类型的异常,可能会抛出的类型⽤逗号分割。
• C++98的⽅式这种⽅式过于复杂,实践中并不好⽤,C++11中进⾏了简化,函数参数列表后⾯加 noexcept表⽰不会抛出异常,啥都不加表⽰可能会抛出异常。
• 编译器并不会在编译时检查noexcept,也就是说如果⼀个函数⽤noexcept修饰了,但是同时⼜包 含了throw语句或者调⽤的函数可能会抛出异常,编译器还是会顺利编译通过的(有些编译器可能会 报个警告)。但是⼀个声明了noexcept的函数抛出了异常,程序会调⽤ terminate 终⽌程序。
• noexcept(expression)还可以作为⼀个运算符去检测⼀个表达式是否会抛出异常,可能会则返回 false,不会就返回true。
二.智能指针
2.智能指针的使⽤及其原理
1. 智能指针的使⽤场景分析
下⾯程序中我们可以看到,new了以后,我们也delete了,但是因为抛异常导,后⾯的delete没有得到 执⾏,所以就内存泄漏了,所以我们需要new以后捕获异常,捕获到异常后delete内存,再把异常抛 出,但是因为new本⾝也可能抛异常,连续的两个new和下⾯的Divide都可能会抛异常,让我们处理起 来很⿇烦。智能指针放到这样的场景⾥⾯就让问题简单多了。
double Divide(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
throw "Divide by zero condition!";
}
else
{
return (double)a / (double)b;
}
}
void Func()
{
// 这⾥可以看到如果发⽣除0错误抛出异常,另外下⾯的array和array2没有得到释放。
// 所以这⾥捕获异常后并不处理异常,异常还是交给外⾯处理,这⾥捕获了再重新抛出去。
// 但是如果array2new的时候抛异常呢,就还需要套⼀层捕获释放逻辑,这⾥更好解决⽅案
// 是智能指针,否则代码太戳了
int* array1 = new int[10];
int* array2 = new int[10]; // 抛异常呢
try
{
int len, time;
cin >> len >> time;
cout << Divide(len, time) << endl;
}
catch (...)
{
cout << "delete []" << array1 << endl;
cout << "delete []" << array2 << endl;
delete[] array1;
delete[] array2;
throw; // 异常重新抛出,捕获到什么抛出什么
}
// ...
cout << "delete []" << array1 << endl;
delete[] array1;
cout << "delete []" << array2 << endl;
delete[] array2;
}
int main()
{
try
{
Func();
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
catch (const exception& e)
{
cout << e.what() << endl;
}
catch (...)
{
cout << "未知异常" << endl;
}
return 0;
}
2.RAII和智能指针的设计思路
• RAII是Resource Acquisition Is Initialization的缩写,他是⼀种管理资源的类的设计思想,本质是 ⼀种利⽤对象⽣命周期来管理获取到的动态资源,避免资源泄漏,这⾥的资源可以是内存、⽂件指 针、⽹络连接、互斥锁等等。RAII在获取资源时把资源委托给⼀个对象,接着控制对资源的访问, 资源在对象的⽣命周期内始终保持有效,最后在对象析构的时候释放资源,这样保障了资源的正常 释放,避免资源泄漏问题。
• 智能指针类除了满⾜RAII的设计思路,还要⽅便资源的访问,所以智能指针类还会想迭代器类⼀ 样,重载 operator*/operator->/operator[] 等运算符,⽅便访问资源。
3. C++标准库智能指针的使⽤
• C++标准库中的智能指针都在这个头⽂件<memory>下⾯,我们包含就可以是使⽤了, 智能指针有好⼏种,除了weak_ptr他们都符合RAII和像指针⼀样访问的⾏为,原理上⽽⾔主要是解 决智能指针拷⻉时的思路不同。
• auto_ptr是C++98时设计出来的智能指针,他的特点是拷⻉时把被拷⻉对象的资源的管理权转移给 拷⻉对象,这是⼀个⾮常糟糕的设计,因为他会到被拷⻉对象悬空,访问报错的问题,C++11设计 出新的智能指针后,强烈建议不要使⽤auto_ptr。其他C++11出来之前很多公司也是明令禁⽌使⽤ 这个智能指针的。
• unique_ptr是C++11设计出来的智能指针,他的名字翻译出来是唯⼀指针,他的特点的不⽀持拷 ⻉,只⽀持移动。如果不需要拷⻉的场景就⾮常建议使⽤他。
• shared_ptr是C++11设计出来的智能指针,他的名字翻译出来是共享指针,他的特点是⽀持拷⻉, 也⽀持移动。如果需要拷⻉的场景就需要使⽤他了。底层是⽤引⽤计数的⽅式实现的。
• weak_ptr是C++11设计出来的智能指针,他的名字翻译出来是弱指针,他完全不同于上⾯的智能指 针,他不⽀持RAII,也就意味着不能⽤它直接管理资源,weak_ptr的产⽣本质是要解决shared_ptr 的⼀个循环引⽤导致内存泄漏的问题
• 智能指针析构时默认是进⾏delete释放资源,这也就意味着如果不是new出来的资源,交给智能指 针管理,析构时就会崩溃。智能指针⽀持在构造时给⼀个删除器,所谓删除器本质就是⼀个可调⽤ 对象,这个可调⽤对象中实现你想要的释放资源的⽅式,当构造智能指针时,给了定制的删除器, 在智能指针析构时就会调⽤删除器去释放资源。因为new[]经常使⽤,所以为了简洁⼀点, unique_ptr和shared_ptr都特化了⼀份[]的版本,使⽤时 unique_ptr up1(new Date[5]);shared_ptr sp1(new Date[5]); 就可以管理new []的资源。

• shared_ptr 除了⽀持⽤指向资源的指针构造,还⽀持 make_shared ⽤初始化资源对象的值 直接构造。
• shared_ptr 和 unique_ptr 都⽀持了operator bool的类型转换,如果智能指针对象是⼀个 空对象没有管理资源,则返回false,否则返回true,意味着我们可以直接把智能指针对象给if判断 是否为空。
• shared_ptr 和 unique_ptr 都得构造函数都使⽤explicit修饰,防⽌普通指针隐式类型转换 成智能指针对象。
struct Date
{
int _year;
int _month;
int _day;
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
,_month(month)
,_day(day)
{}
~Date()
{
cout << "~Date()" << endl;
}
};
int main()
{
auto_ptr<Date> ap1(new Date);
// 拷⻉时,管理权限转移,被拷⻉对象ap1悬空
auto_ptr<Date> ap2(ap1);
// 空指针访问,ap1对象已经悬空
//ap1->_year++;
unique_ptr<Date> up1(new Date);
// 不⽀持拷⻉
//unique_ptr<Date> up2(up1);
// ⽀持移动,但是移动后up1也悬空,所以使⽤移动要谨慎
unique_ptr<Date> up3(move(up1));
shared_ptr<Date> sp1(new Date);
// ⽀持拷⻉
shared_ptr<Date> sp2(sp1);
shared_ptr<Date> sp3(sp2);
cout << sp1.use_count() << endl;
sp1->_year++;
cout << sp1->_year << endl;
cout << sp2->_year << endl;
cout << sp3->_year << endl;
// ⽀持移动,但是移动后sp1也悬空,所以使⽤移动要谨慎
shared_ptr<Date> sp4(move(sp1));
return 0;
}
4. 智能指针的原理
• 下⾯我们模拟实现了auto_ptr和unique_ptr的核⼼功能,这两个智能指针的实现⽐较简单,⼤家了 解⼀下原理即可。auto_ptr的思路是拷⻉时转移资源管理权给被拷⻉对象,这种思路是不被认可 的,也不建议使⽤。unique_ptr的思路是不⽀持拷⻉。
• ⼤家重点要看看shared_ptr是如何设计的,尤其是引⽤计数的设计,主要这⾥⼀份资源就需要⼀个 引⽤计数,所以引⽤计数⽤静态成员的⽅式是⽆法实现的,要使⽤堆上动态开辟的⽅式,构造智 能指针对象时来⼀份资源,就要new⼀个引⽤计数出来。多个shared_ptr指向资源时就++引⽤计 数,shared_ptr对象析构时就--引⽤计数,引⽤计数减到0时代表当前析构的shared_ptr是最后⼀ 个管理资源的对象,则析构资源。
auto_ptr和unique_ptr的模拟实现:
template<class T>
class auto_ptr
{
public:
auto_ptr(T* ptr)
:_ptr(ptr)
{}
auto_ptr(auto_ptr<T>& sp)
:_ptr(sp._ptr)
{
// 管理权转移
sp._ptr = nullptr;
}
auto_ptr<T>& operator=(auto_ptr<T>& ap)
{
// 检测是否为⾃⼰给⾃⼰赋值
if (this != &ap)
{
// 释放当前对象中资源
if (_ptr)
delete _ptr;
// 转移ap中资源到当前对象中
_ptr = ap._ptr;
ap._ptr = NULL;
}
return *this;
}
~auto_ptr()
{
if (_ptr)
{
cout << "delete:" << _ptr << endl;
delete _ptr;
}
}
// 像指针⼀样使⽤
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};
template<class T>
class unique_ptr
{
public:
explicit unique_ptr(T* ptr)
:_ptr(ptr)
{}
~unique_ptr()
{
if (_ptr)
{
cout << "delete:" << _ptr << endl;
delete _ptr;
}
}
// 像指针⼀样使⽤
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
unique_ptr(const unique_ptr<T>& sp) = delete;
unique_ptr<T>& operator=(const unique_ptr<T>& sp) = delete;
unique_ptr(unique_ptr<T>&& sp)
:_ptr(sp._ptr)
{
sp._ptr = nullptr;
}
unique_ptr<T>& operator=(unique_ptr<T>&& sp)
{
delete _ptr;
_ptr = sp._ptr;
sp._ptr = nullptr;
}
private:
T* _ptr;
};
shared_ptr和weak_ptr模拟实现:
#include<functional>
namespace my
{
template<class T>
class shared_ptr
{
public:
shared_ptr(T* ptr=nullptr)
:_ptr(ptr)
,_pcount(new int(1))
{ }
template<class D>
shared_ptr(T* ptr, D del)
:_ptr(ptr)
,_pcount(new int(1))
, _del(del)
{ }
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
, _pcount(sp._pcount)
, _del(sp._del)
{
++(*_pcount);
}
void release()
{
if (--(*_pcount) == 0)
{
_del(_ptr);
delete _pcount;
}
}
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
if (_ptr != sp._ptr)
{
release();
_ptr = sp._ptr;
_pcount = sp._pcount;
++(*_pcount);
_del = sp._del;
}
return *this;
}
~shared_ptr()
{
release();
}
T* get() const
{
return _ptr;
}
int use_count() const
{
return *_pcount;
}
T& operator* ()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T& operator[](int i)
{
return _ptr[i];
}
private:
T* _ptr;
int* _pcount;
std::function<void(T*)> _del = [](T* ptr) {delete ptr; };
};
template<class T>
class weak_ptr
{
public:
weak_ptr()
{ }
weak_ptr(const shared_ptr<T>& sp)
:_ptr(sp.get())
{}
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.get();
return *this;
}
private:
T* _ptr = nullptr;
};
}
5. shared_ptr和weak_ptr
5.1 shared_ptr循环引⽤问题
• shared_ptr⼤多数情况下管理资源⾮常合适,⽀持RAII,也⽀持拷⻉。但是在循环引⽤的场景下会 导致资源没得到释放内存泄漏,所以我们要认识循环引⽤的场景和资源没释放的原因,并且学会使 ⽤weak_ptr解决这种问题。
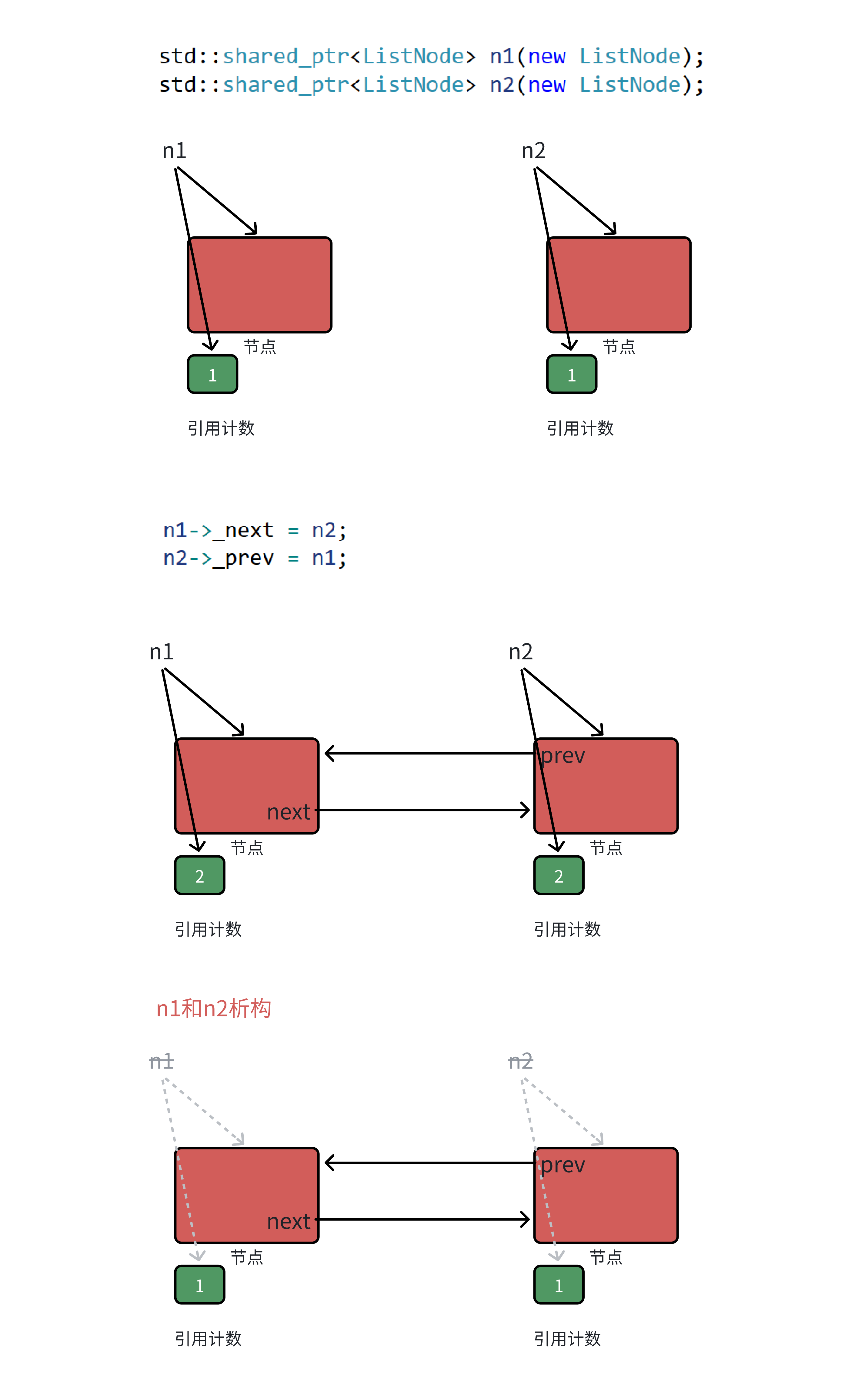
• 如下图所述场景,n1和n2析构后,管理两个节点的引⽤计数减到1
1. 右边的节点什么时候释放呢,左边节点中的_next管着呢,_next析构后,右边的节点就释放了。
2. _next什么时候析构呢,_next是左边节点的的成员,左边节点释放,_next就析构了。
3. 左边节点什么时候释放呢,左边节点由右边节点中的_prev管着呢,_prev析构后,左边的节点就释 放了。
4. _prev什么时候析构呢,_prev是右边节点的成员,右边节点释放,_prev就析构了。
• ⾄此逻辑上成功形成回旋镖似的循环引⽤,谁都不会释放就形成了循环引⽤,导致内存泄漏
• 把ListNode结构体中的_next和_prev改成weak_ptr,weak_ptr绑定到shared_ptr时不会增加它的 引⽤计数,_next和_prev不参与资源释放管理逻辑,就成功打破了循环引⽤,解决了这⾥的问题
5.2 weak_ptr
• weak_ptr不⽀持RAII,也不⽀持访问资源,所以我们看⽂档发现weak_ptr构造时不⽀持绑定到资 源,只⽀持绑定到shared_ptr,绑定到shared_ptr时,不增加shared_ptr的引⽤计数,那么就可以 解决上述的循环引⽤问题。
• weak_ptr也没有重载operator*和operator->等,因为他不参与资源管理,那么如果他绑定的 shared_ptr已经释放了资源,那么他去访问资源就是很危险的。weak_ptr⽀持expired检查指向的 资源是否过期,use_count也可获取shared_ptr的引⽤计数,weak_ptr想访问资源时,可以调⽤ lock返回⼀个管理资源的shared_ptr,如果资源已经被释放,返回的shared_ptr是⼀个空对象,如 果资源没有释放,则通过返回的shared_ptr访问资源是安全的。
6. shared_ptr的线程安全问题
• shared_ptr的引⽤计数对象在堆上,如果多个shared_ptr对象在多个线程中,进⾏shared_ptr的拷 ⻉析构时会访问修改引⽤计数,就会存在线程安全问题,所以shared_ptr引⽤计数是需要加锁或者 原⼦操作保证线程安全的。
• shared_ptr指向的对象也是有线程安全的问题的,但是这个对象的线程安全问题不归shared_ptr 管,它也管不了,应该有外层使⽤shared_ptr的⼈进⾏线程安全的控制。
7. 内存泄漏
7.1 什么是内存泄漏,内存泄漏的危害
什么是内存泄漏:内存泄漏指因为疏忽或错误造成程序未能释放已经不再使⽤的内存,⼀般是忘记释 放或者发⽣异常释放程序未能执⾏导致的。内存泄漏并不是指内存在物理上的消失,⽽是应⽤程序分 配某段内存后,因为设计错误,失去了对该段内存的控制,因⽽造成了内存的浪费。
内存泄漏的危害:普通程序运⾏⼀会就结束了出现内存泄漏问题也不⼤,进程正常结束,⻚表的映射 关系解除,物理内存也可以释放。⻓期运⾏的程序出现内存泄漏,影响很⼤,如操作系统、后台服 务、⻓时间运⾏的客⼾端等等,不断出现内存泄漏会导致可⽤内存不断变少,各种功能响应越来越 慢,最终卡死。
7.2如何避免内存泄漏
• ⼯程前期良好的设计规范,养成良好的编码规范,申请的内存空间记着匹配的去释放。ps:这个理 想状态。但是如果碰上异常时,就算注意释放了,还是可能会出问题。需要下⼀条智能指针来管理 才有保证。
• 尽量使⽤智能指针来管理资源,如果⾃⼰场景⽐较特殊,采⽤RAII思想⾃⼰造个轮⼦管理。
• 定期使⽤内存泄漏⼯具检测,尤其是每次项⽬快上线前,不过有些⼯具不够靠谱,或者是收费。 • 总结⼀下:内存泄漏⾮常常⻅,解决⽅案分为两种:1、事前预防型。如智能指针等。2、事后查错 型。如泄漏检测⼯具。
更多推荐
 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)