
Golang 实战 ELK 日志系统全流程教程(四):Go 项目日志字段设计和结构化输出
Golang 实战 ELK 日志系统全流程教程(四):Go 项目日志字段设计和结构化输出
上一篇把 Elasticsearch 和 Kibana 跑起来以后,我本来很想马上接 Filebeat。
但真往后做的时候发现,如果 Go 应用自己的日志还没整理好,后面所有组件都只是把混乱搬得更远一点。
这个问题我以前踩过。
最早项目里日志大概是这样:
log.Println("create order success")
log.Println("user id:", userID)
log.Println("error:", err)
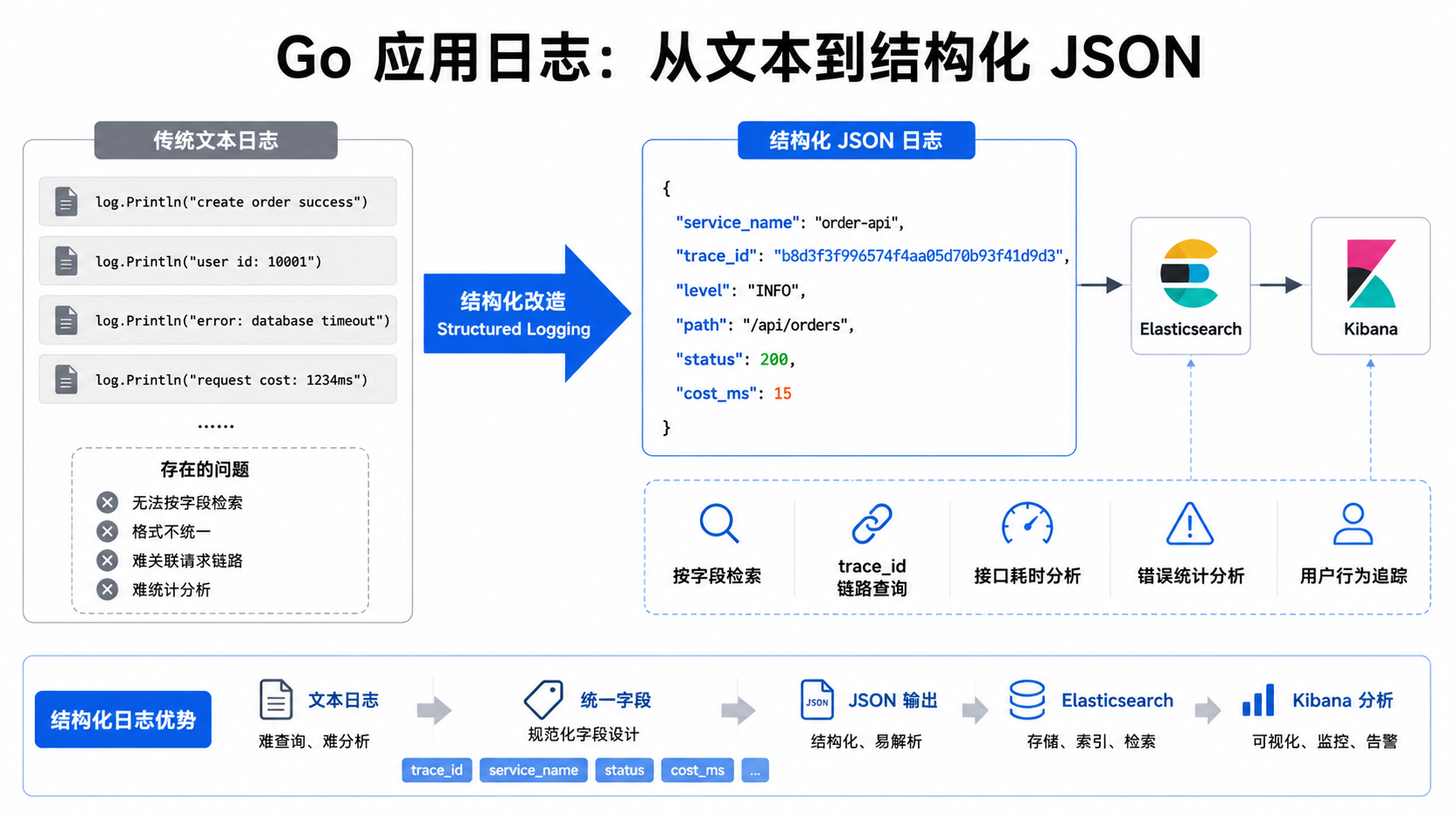
本地看没问题,甚至挺顺手。出了问题以后 grep 一下关键字,能找到就继续查。可一旦服务变多、机器变多、日志进入 Elasticsearch,这种日志就开始难受了。
比如我想查:
order-api 服务最近 10 分钟所有 500 错误
某个 trace_id 下完整请求链路
耗时超过 1 秒的接口
某个 user_id 触发过哪些错误
如果日志只是普通字符串,Kibana 里当然也能搜,但搜出来的结果很依赖文本格式。今天有人打 user id,明天有人打 user_id,后天又变成 uid,排查的时候就会很烦。
所以第四篇先不急着碰采集器。先把 Go 应用输出的日志变成稳定的结构化 JSON。
先看一条我希望打出来的日志
我比较希望 Go 服务最终输出的访问日志长这样:
{
"@timestamp": "2026-05-28T10:30:00.123+08:00",
"service_name": "order-api",
"env": "dev",
"level": "INFO",
"trace_id": "trace-20260528-0001",
"span_id": "span-001",
"message": "http request completed",
"method": "POST",
"path": "/api/orders",
"status": 200,
"cost_ms": 37,
"client_ip": "127.0.0.1",
"user_agent": "curl/8.0.1"
}
业务错误日志可以长这样:
{
"@timestamp": "2026-05-28T10:30:00.456+08:00",
"service_name": "order-api",
"env": "dev",
"level": "ERROR",
"trace_id": "trace-20260528-0001",
"message": "create order failed",
"user_id": 10001,
"order_id": "order-001",
"error": "inventory not enough"
}
这两条日志有几个特点:
第一,它是一行一个 JSON。这个很重要。Filebeat 后面按行采集时,最舒服的格式就是一行一条日志。
第二,字段名稳定。不是一会儿 traceId,一会儿 trace_id,一会儿 request_id。
第三,常用筛选条件都变成了字段。Kibana 里可以直接按 service_name、level、status、cost_ms、trace_id 查询,不用在 message 里硬搜字符串。
我后来才意识到,日志系统的前半段工作其实不在 ELK,而在应用侧字段设计。字段定不好,后面查日志会一直补洞。
为什么普通文本日志不够用
普通日志最大的问题不是“看不懂”,而是不稳定。
比如下面几种日志,人眼看都能理解:
create order success, user id: 10001, cost: 37ms
user_id=10001 create order success cost_ms=37
[order] create success uid=10001 elapsed=37
但交给 Elasticsearch 后,它们不是同一种结构。
你想按 user_id 查,第一条叫 user id,第三条叫 uid。你想按耗时排序,第一条是 37ms 文本,第二条才像一个数值字段。你想统计慢请求,ES 根本不知道哪一段是耗时。
这也是为什么我不太建议在日志系统接入以后,继续把大量业务信息塞进 message 里。
message 适合放一句人能读懂的话:
create order failed
真正要查询、过滤、聚合的东西,应该拆成字段:
{
"user_id": 10001,
"order_id": "order-001",
"cost_ms": 37,
"error": "inventory not enough"
}
这里有个取舍:不是所有变量都要打进日志。
日志字段越多,查询越方便,但存储成本也会上来。尤其是高频接口,如果每次都把一大坨请求体、响应体、复杂对象全打进去,ES 磁盘会涨得很快。更麻烦的是,里面可能混进手机号、token、身份证号这类敏感信息。
我现在的习惯是:默认只打排障必要字段,请求体和响应体只在明确需要时打,并且要做脱敏。
Go 日志库怎么选
Go 里能打日志的库很多:
- 标准库
log log/slogzapzerologlogrus
如果是新项目,其实 log/slog 已经能满足不少结构化日志需求。标准库方案的好处是依赖少,团队接受成本低。
但这个系列我用 zap 做例子。
原因比较现实:很多 Go Web 项目里本来就已经在用 zap,它性能不错,字段 API 也直接,和 Gin 这类框架组合起来比较顺手。zerolog 也很好,写法更链式,性能也强。只是为了让文章主线集中一点,这里不同时展开两个库。
先安装:
go get go.uber.org/zap
如果后面要做日志切割,可以再加:
go get gopkg.in/natefinch/lumberjack.v2
日志切割不是这篇的重点,但本地写文件时最好提前留个位置,不然一个 app.log 无限长下去,迟早把磁盘打满。
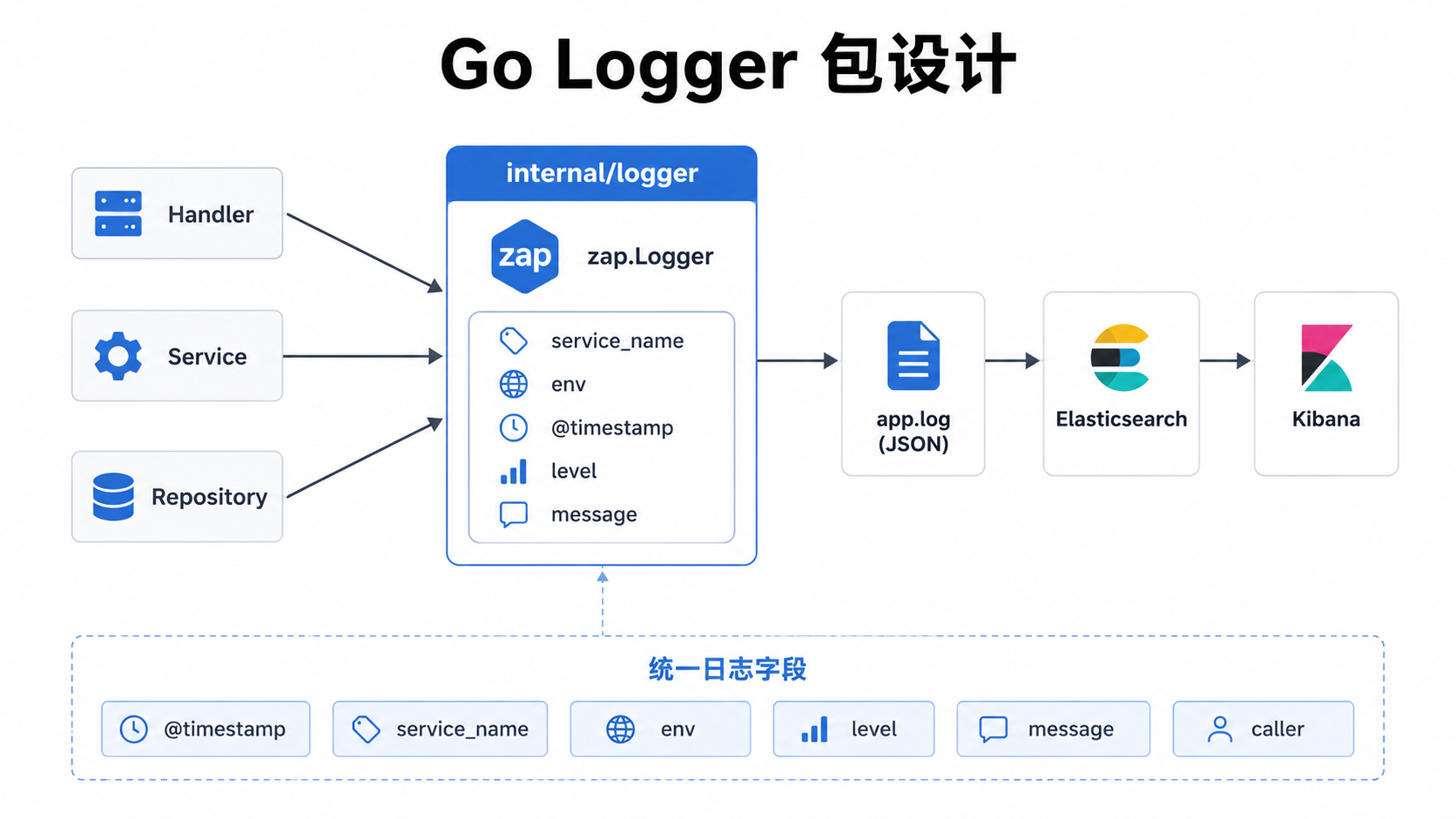
先写一个 logger 包
我不喜欢在项目里到处 zap.NewProduction()。
看起来省事,后面改字段名、改输出位置、改日志级别会很散。更舒服的方式是封一层自己的 logger 包。业务代码只管用,不关心底层到底是 zap 还是别的库。
目录可以先这样:
go-elk-demo
├── main.go
└── internal
└── logger
└── logger.go
internal/logger/logger.go:
package logger
import (
"os"
"time"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
type Config struct {
ServiceName string
Env string
LogPath string
Level string
}
func New(cfg Config) (*zap.Logger, error) {
level := zapcore.InfoLevel
if err := level.Set(cfg.Level); err != nil {
level = zapcore.InfoLevel
}
encoderConfig := zap.NewProductionEncoderConfig()
encoderConfig.TimeKey = "@timestamp"
encoderConfig.LevelKey = "level"
encoderConfig.MessageKey = "message"
encoderConfig.CallerKey = "caller"
encoderConfig.StacktraceKey = "stacktrace"
encoderConfig.EncodeTime = func(t time.Time, enc zapcore.PrimitiveArrayEncoder) {
enc.AppendString(t.Format("2006-01-02T15:04:05.000Z07:00"))
}
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder
file, err := os.OpenFile(cfg.LogPath, os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)
if err != nil {
return nil, err
}
jsonEncoder := zapcore.NewJSONEncoder(encoderConfig)
core := zapcore.NewCore(
jsonEncoder,
zapcore.AddSync(file),
level,
)
log := zap.New(
core,
zap.AddCaller(),
zap.AddStacktrace(zapcore.ErrorLevel),
zap.Fields(
zap.String("service_name", cfg.ServiceName),
zap.String("env", cfg.Env),
),
)
return log, nil
}
这里有几个细节是我后来才补上的。
TimeKey 我改成了 @timestamp。Elasticsearch 和 Kibana 对这个字段很友好,后面创建 Data View 时直接用它做时间字段。
EncodeTime 我没有用 zap 默认的数字时间戳。数字时间戳性能上没问题,但人直接看日志文件时不舒服。开发环境里我更喜欢 ISO8601 这种格式,Kibana 也好识别。
service_name 和 env 用 zap.Fields 固定注入。这样业务代码每次打日志时不用重复写:
zap.String("service_name", "order-api")
这类公共字段应该在 logger 初始化时统一处理。
main.go 里先跑起来
写一个最小版本:
package main
import (
"log"
"go-elk-demo/internal/logger"
"go.uber.org/zap"
)
func main() {
appLog, err := logger.New(logger.Config{
ServiceName: "order-api",
Env: "dev",
LogPath: "./logs/app.log",
Level: "info",
})
if err != nil {
log.Fatalf("init logger failed: %v", err)
}
defer appLog.Sync()
appLog.Info("create order success",
zap.String("trace_id", "trace-20260528-0001"),
zap.Int64("user_id", 10001),
zap.String("order_id", "order-001"),
zap.Int("cost_ms", 37),
)
}
先创建日志目录:
mkdir logs
go run .
查看 logs/app.log,应该能看到一行 JSON:
{"level":"INFO","@timestamp":"2026-05-28T10:30:00.123+08:00","caller":"go-elk-demo/main.go:24","message":"create order success","service_name":"order-api","env":"dev","trace_id":"trace-20260528-0001","user_id":10001,"order_id":"order-001","cost_ms":37}
这一步看起来很小,但它是后面整条 ELK 链路的入口。
日志文件里只要能稳定出现这种一行 JSON,Filebeat 采集、Logstash 清洗、Elasticsearch 建索引、Kibana 查询都会顺很多。
日志字段怎么定
字段设计不要太随缘。
我会先把字段分成几类。
1. 基础字段
这些字段基本每条日志都应该有:
@timestamp
level
message
service_name
env
@timestamp 用来做时间过滤。
level 用来区分 DEBUG、INFO、WARN、ERROR。
message 是给人看的简短说明。
service_name 用来区分服务,比如 order-api、user-api、payment-worker。
env 用来区分环境,比如 dev、test、prod。
2. 请求字段
HTTP 服务建议打这些:
trace_id
method
path
status
cost_ms
client_ip
user_agent
其中 trace_id 很关键。后面第八篇会专门写 Gin 中间件怎么生成和传递它。
现在先记住一点:没有 trace_id,Kibana 里查单条请求会非常难受。
cost_ms 建议直接打数字,不要打成 "37ms"。数字字段后面可以排序、范围查询、做聚合:
cost_ms >= 1000
字符串就麻烦很多。
3. 业务字段
这类字段和业务有关,不同项目不一样:
user_id
order_id
tenant_id
job_id
task_id
我不建议把所有业务字段都统一塞进去。要看排障时是否真的经常用。
比如订单系统里 order_id 很重要,任务系统里 job_id 很重要。字段设计应该贴着业务排障路径走,而不是为了看起来完整。
4. 错误字段
错误日志至少要有:
error
如果是比较复杂的系统,还可以补:
error_code
error_type
stacktrace
但 stacktrace 不要滥用。每条错误都带很长的堆栈,日志量会变得很吓人。一般可以在 ERROR 级别打开,业务可预期错误不一定需要堆栈。
字段命名要一开始就定住
这个问题很小,但真的烦。
同一个字段,如果项目里出现这些写法:
traceId
trace_id
request_id
requestId
后面 Kibana 查询会变成灾难。
我个人更习惯日志字段统一用 snake_case:
service_name
trace_id
span_id
cost_ms
user_id
order_id
原因也简单:JSON 里清楚,Kibana 里也好看,和很多日志系统字段习惯比较接近。
团队里最好把这件事写进规范。不要靠每个开发临场发挥。
一旦日志进入 Elasticsearch,字段名变更就不是“改个变量名”这么轻松了。老索引里是旧字段,新索引里是新字段,Dashboard、告警、查询语句都可能要跟着改。
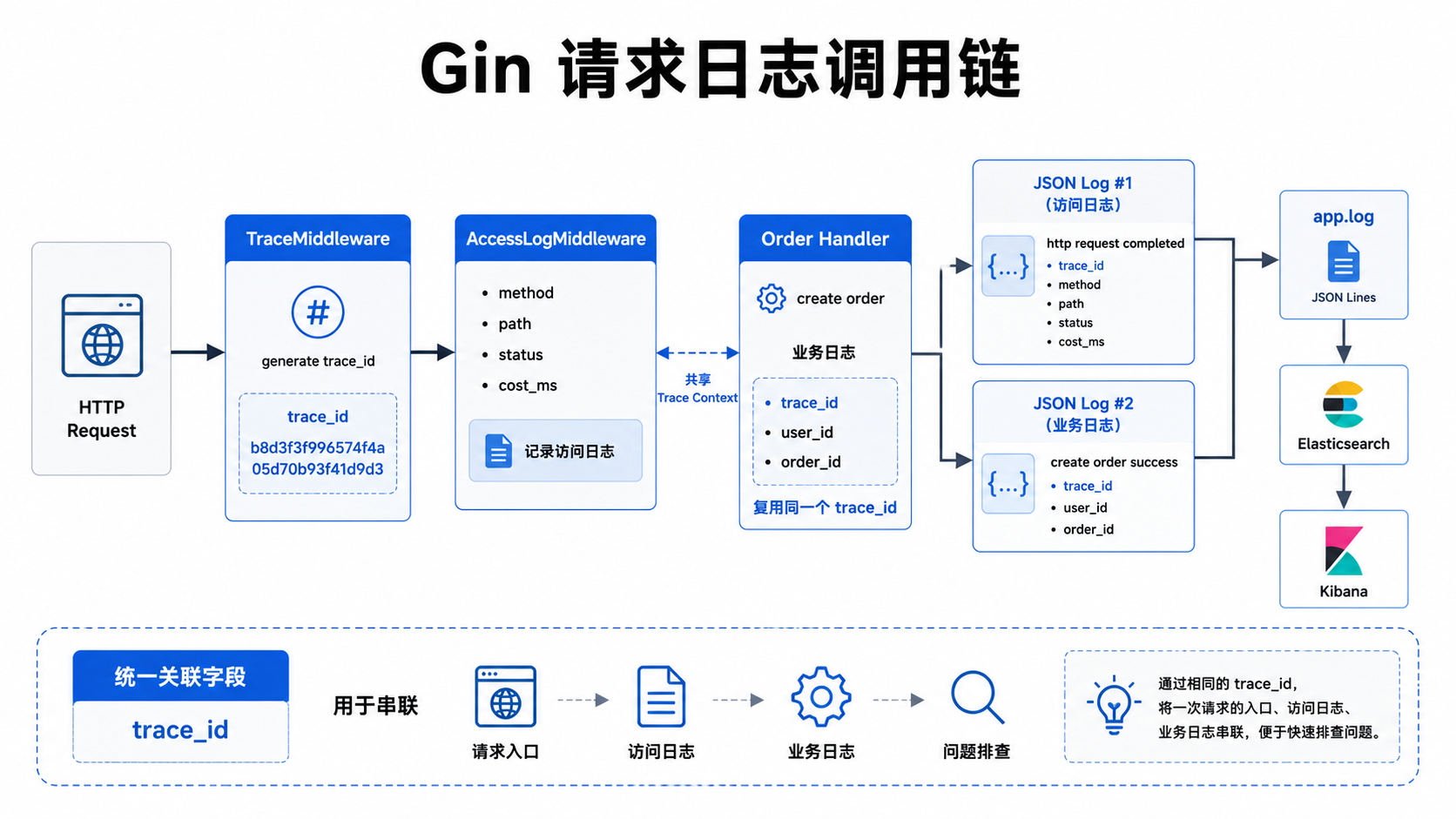
接入 Gin:访问日志不要散在每个 handler 里
Web 服务最常见的是访问日志。
不要在每个 handler 里手写:
log.Info("request completed")
这类日志适合放到 Gin middleware 里统一处理。
先装 Gin:
go get github.com/gin-gonic/gin
写一个简单中间件:
package main
import (
"time"
"github.com/gin-gonic/gin"
"go.uber.org/zap"
)
func AccessLogMiddleware(log *zap.Logger) gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
c.Next()
cost := time.Since(start)
log.Info("http request completed",
zap.String("trace_id", c.GetString("trace_id")),
zap.String("method", c.Request.Method),
zap.String("path", c.FullPath()),
zap.Int("status", c.Writer.Status()),
zap.Int64("cost_ms", cost.Milliseconds()),
zap.String("client_ip", c.ClientIP()),
zap.String("user_agent", c.Request.UserAgent()),
)
}
}
这里的 c.FullPath() 比 c.Request.URL.Path 更适合做统计。
比如真实请求是:
/api/orders/10001
/api/orders/10002
/api/orders/10003
如果用 URL.Path,Kibana 里会出现很多具体路径。用 FullPath(),拿到的是路由模板:
/api/orders/:id
后面统计接口耗时时更干净。
不过 FullPath() 有个小细节:如果请求没有匹配到任何路由,它可能是空字符串。生产里可以做个兜底:
path := c.FullPath()
if path == "" {
path = c.Request.URL.Path
}
trace_id 先简单处理
完整的 trace_id 设计后面单独写。这里先做一个最小版,让访问日志能带上它。
package main
import (
"crypto/rand"
"encoding/hex"
"github.com/gin-gonic/gin"
)
func TraceMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
traceID := c.GetHeader("X-Trace-Id")
if traceID == "" {
traceID = newTraceID()
}
c.Set("trace_id", traceID)
c.Header("X-Trace-Id", traceID)
c.Next()
}
}
func newTraceID() string {
var b [16]byte
if _, err := rand.Read(b[:]); err != nil {
return "trace-unknown"
}
return hex.EncodeToString(b[:])
}
这样本地请求一次接口,响应头里也能看到 X-Trace-Id。用户反馈问题时,如果能带上这个 ID,后面查日志会轻松很多。
组装一个 Gin demo
把前面的东西放到一起:
package main
import (
"log"
"net/http"
"github.com/gin-gonic/gin"
"go-elk-demo/internal/logger"
"go.uber.org/zap"
)
func main() {
appLog, err := logger.New(logger.Config{
ServiceName: "order-api",
Env: "dev",
LogPath: "./logs/app.log",
Level: "info",
})
if err != nil {
log.Fatalf("init logger failed: %v", err)
}
defer appLog.Sync()
r := gin.New()
r.Use(gin.Recovery())
r.Use(TraceMiddleware())
r.Use(AccessLogMiddleware(appLog))
r.POST("/api/orders", func(c *gin.Context) {
traceID := c.GetString("trace_id")
userID := int64(10001)
appLog.Info("create order success",
zap.String("trace_id", traceID),
zap.Int64("user_id", userID),
zap.String("order_id", "order-001"),
)
c.JSON(http.StatusOK, gin.H{
"order_id": "order-001",
"trace_id": traceID,
})
})
if err := r.Run(":8080"); err != nil {
log.Fatalf("run server failed: %v", err)
}
}
启动:
mkdir logs
go run .
请求一次:
curl -X POST http://localhost:8080/api/orders
日志文件里应该能看到两条日志:
一条是业务日志:
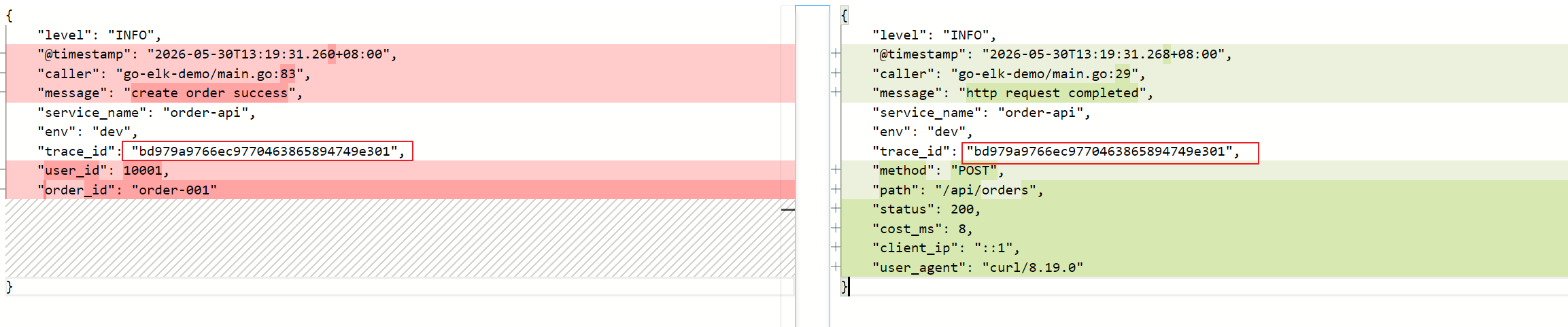
{"level":"INFO","@timestamp":"2026-05-28T10:30:00.123+08:00","caller":"go-elk-demo/main.go:31","message":"create order success","service_name":"order-api","env":"dev","trace_id":"b8d3f3f996574f4aa05d70b93f41d9d3","user_id":10001,"order_id":"order-001"}
一条是访问日志:
{"level":"INFO","@timestamp":"2026-05-28T10:30:00.124+08:00","caller":"go-elk-demo/middleware.go:20","message":"http request completed","service_name":"order-api","env":"dev","trace_id":"b8d3f3f996574f4aa05d70b93f41d9d3","method":"POST","path":"/api/orders","status":200,"cost_ms":1,"client_ip":"::1","user_agent":"curl/8.0.1"}
注意看两条日志的 trace_id 是一样的。
这就是后面排障时最重要的线索之一。业务日志告诉你发生了什么,访问日志告诉你这次请求的入口、状态码和耗时。两者用 trace_id 串起来。
ERROR 日志应该怎么打
很多项目里还有一个问题:所有异常都打成一行字符串。
log.Println("create order failed:", err)
换成结构化日志以后,至少应该这样:
appLog.Error("create order failed",
zap.String("trace_id", traceID),
zap.Int64("user_id", userID),
zap.String("order_id", orderID),
zap.String("error_code", "INVENTORY_NOT_ENOUGH"),
zap.Error(err),
)
输出大概是:
{
"level": "ERROR",
"@timestamp": "2026-05-28T10:30:00.456+08:00",
"message": "create order failed",
"service_name": "order-api",
"env": "dev",
"trace_id": "b8d3f3f996574f4aa05d70b93f41d9d3",
"user_id": 10001,
"order_id": "order-001",
"error_code": "INVENTORY_NOT_ENOUGH",
"error": "inventory not enough"
}
zap.Error(err) 会输出 error 字段,后面 Kibana 里可以直接看。
如果团队有统一错误码,建议把 error_code 也打进去。错误文案可能会变,错误码相对稳定,更适合查询和告警。
不过也别把所有业务失败都打成 ERROR。
比如用户余额不足、验证码错误、参数校验失败,这些很多时候是业务可预期结果。它们不一定应该污染错误告警。可以用 WARN,也可以按团队规范处理。
真正值得 ERROR 的,通常是:
数据库不可用
Redis 连接失败
外部服务持续超时
程序出现非预期异常
关键业务流程失败
日志级别乱了以后,告警也会乱。后面第十篇写告警时,这个问题会很明显。
控制台输出和文件输出怎么选
本地开发时,控制台输出很舒服。
容器部署时,很多团队也会直接把日志打到 stdout,再由容器运行时或采集器处理。这种方式在 Kubernetes 里很常见。
但这个系列为了讲 Filebeat 采集文件日志,先采用:
Go -> logs/app.log -> Filebeat
也就是应用把日志写到文件,Filebeat 去读这个文件。
这种方式更容易把链路拆开看:
Go 有没有正确写 app.log?
Filebeat 有没有读到 app.log?
Elasticsearch 里有没有对应索引?
Kibana 能不能查到?
如果一开始就把所有东西都交给容器 stdout,学习阶段反而不容易观察。
当然,生产怎么选要看部署环境。如果是 K8s,stdout 方案可能更自然。如果是传统虚拟机或 Docker Compose demo,文件采集更直观。
日志文件要考虑切割
上面的 os.OpenFile 只是最小 demo。
真实项目里不建议一个 app.log 无限写。可以用 lumberjack 做本地切割:
import "gopkg.in/natefinch/lumberjack.v2"
把 writer 换成:
writer := &lumberjack.Logger{
Filename: cfg.LogPath,
MaxSize: 100,
MaxBackups: 7,
MaxAge: 7,
Compress: true,
}
再接到 zap:
core := zapcore.NewCore(
jsonEncoder,
zapcore.AddSync(writer),
level,
)
这里的 MaxSize: 100 表示单个日志文件最大 100MB。
不过要注意,后面 Filebeat 采集切割日志时,也要确认路径匹配和采集策略。比如:
logs/app.log
logs/app-2026-05-28.log.gz
哪些要采,哪些不要采,要提前想清楚。压缩后的历史日志通常不建议再让 Filebeat 反复处理。
我现在比较固定的一套字段规范
整理一下,这套 Go 日志接入 ELK 时,我一般会先定这些字段。
基础字段:
@timestamp
level
message
service_name
env
caller
链路字段:
trace_id
span_id
HTTP 字段:
method
path
status
cost_ms
client_ip
user_agent
业务字段:
user_id
order_id
tenant_id
job_id
错误字段:
error
error_code
stacktrace
这里不是说每条日志都要有所有字段。基础字段尽量都有,其他字段按场景出现。
比如访问日志就有 method、path、status、cost_ms。订单业务日志就有 order_id、user_id。后台任务日志可能是 job_id、task_id。
字段少一点没关系,关键是稳定。
先别把日志系统写成业务系统
我以前有个误区:既然日志这么重要,那是不是应该把日志封装得很复杂?
后来发现没必要。
日志工具层应该薄一点。它负责:
初始化 logger
统一公共字段
统一输出格式
提供少量上下文辅助方法
不要把业务含义塞太多进去。
比如 LogOrderCreateSuccess、LogUserLoginFailed 这种函数,刚开始看着规范,后面业务场景一多会膨胀得很快。除非团队真的需要非常严格的日志事件模型,不然普通项目里保持 zap 字段式写法就够了。
更重要的是字段规范和 review。
代码 review 时可以顺手看几件事:
有没有 trace_id
错误有没有 zap.Error(err)
耗时是不是数字
字段命名是不是 snake_case
有没有把敏感信息打出来
INFO 和 ERROR 有没有乱用
这些比封装十层 logger 更有用。
这一篇先停在应用侧
到这里,Go 应用已经能稳定输出一行一条 JSON 日志。
现在我们的链路还很短:
Go -> logs/app.log
但这个基础很关键。因为下一篇 Filebeat 要做的事情其实很朴素:盯住这个日志文件,有新的一行就采集出去。
如果这一行本身就是规范 JSON,Filebeat 基本不用费劲。后面到了 Elasticsearch,字段也能自然展开。Kibana 里按 trace_id、level、service_name、cost_ms 查起来才像一个真正能用的日志系统。
下一篇就开始接 Filebeat,把链路推进到:
Go -> logs/app.log -> Filebeat -> Elasticsearch -> Kibana
到那一步,就不是手动往 ES 里写日志了,而是 Go 服务请求一次,Kibana 里自动能查到。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)