
JAVA - Disruptor高性能队列核心概念
·
Disruptor一个提供并发环型缓冲区【RingBuffer】数据结构、高性能的Java线程间消息传递库库
- 设计初衷是为了解决在低延迟、高吞吐量场景下(如金融交易系统),传统的
java.util.concurrent.BlockingQueue(如ArrayBlockingQueue或LinkedBlockingQueue)存在的性能瓶颈 - 旨在为异步事件处理体系结构提供低延迟、高吞吐量的工作队列
关键功能
Disruptor 通过 预分配内存消除了GC开销,通过无锁算法消除了线程上下文切换开销,通过环形缓冲和多播机制消除了数据复制和复杂的同步逻辑,从而在单机上实现了远超传统队列的吞吐量和极低的延迟。
1. Multicast events to consumers, with consumer dependency graph
支持事件的多播,且消费者之间可以定义依赖关系
- 传统 BlockingQueue 的局限: 在传统的生产者-消费者模型中,通常是一个生产者往队列里放数据,多个消费者从队列里取数据。但是,
BlockingQueue遵循的是“竞争消费”模式:一条消息一旦放入队列,只能被一个消费者取走并处理。如果你需要多个消费者同时处理同一条消息(例如:一个消费者负责写日志,另一个负责业务逻辑,第三个负责监控),你需要为每个消费者维护一个独立的队列,生产者需要把同一条消息复制多份分别放入不同的队列。这不仅增加了生产者的负担,还浪费了内存带宽。 - Disruptor 的解决方案: Disruptor 引入了 RingBuffer(环形缓冲区) 的概念。
- 多播(Multicast): RingBuffer 中的每一个槽位(Slot)存储一个事件。多个消费者(在Disruptor中称为
EventProcessor)可以监听同一个 RingBuffer。当生产者发布一个事件到序列号 NNN 时,所有订阅了该事件的消费者都可以读取序列号 NNN 的数据。这意味着一条消息可以被多个消费者同时处理,而无需复制数据。 - 消费者依赖图(Consumer Dependency Graph): 这是Disruptor最强大的功能之一。你可以定义消费者之间的处理顺序。
- 并行处理: 消费者A和消费者B可以同时独立处理同一个事件(互不干扰)。
- 串行/依赖处理: 你可以规定“消费者B必须等消费者A处理完该事件后,才能开始处理”。例如:
生产者 -> [解析器] -> [业务逻辑处理器] & [日志处理器]。这里业务逻辑和日志可以并行,但必须在解析完成后。 - 这种有向无环图(DAG)式的编排能力,使得复杂的流水线处理变得非常高效且易于管理,而无需手动编写复杂的线程同步代码(如
CountDownLatch或手动管理多个队列)。
- 多播(Multicast): RingBuffer 中的每一个槽位(Slot)存储一个事件。多个消费者(在Disruptor中称为
2. Pre-allocate memory for events
为事件预分配内存
- 传统 BlockingQueue 的局限: 在使用
BlockingQueue时,通常的做法是:生产者创建一个对象(new MyEvent()),填充数据,然后放入队列。- GC 压力: 在高吞吐量场景下(例如每秒百万级消息),这会瞬间产生大量的临时对象。Java的垃圾回收器(GC)会被频繁触发,导致“Stop-The-World”暂停,从而引起系统延迟的剧烈抖动(Jitter)。
- 缓存不友好: 频繁的对象分配和释放会导致内存碎片,降低CPU缓存命中率。
- Disruptor 的解决方案: Disruptor 采用 对象池化(Object Pooling) 和 预分配 策略。
- 启动时分配: 在Disruptor启动初始化 RingBuffer 时,就会根据设定的 bufferSize(通常是2的幂次方,如2202^{20}220),一次性创建好所有的 Event 对象,并填充到环形数组中。
- 复用对象: 当生产者需要发布消息时,它不是
new一个新对象,而是从 RingBuffer 中获取下一个可用的槽位,拿到里面已经存在的 Event 对象,重置其状态,填入新数据,然后发布。 - 零垃圾(Zero GC): 在系统运行稳定后,除了极少量的管理对象外,核心业务流转过程中不会产生任何新的对象。这极大地减轻了GC的压力,保证了延迟的平稳和可预测性,这对于低延迟系统至关重要。
3. Optionally lock-free
可选的无锁设计
- 传统 BlockingQueue 的局限: 大多数标准的
BlockingQueue实现依赖于ReentrantLock或synchronized关键字来保证线程安全。- 上下文切换开销: 当线程竞争锁失败时,线程会被挂起(进入阻塞状态),操作系统需要进行上下文切换。这个过程的开销非常大(微秒级甚至毫秒级),远高于CPU指令执行时间(纳秒级)。
- 优先级反转与抖动: 锁竞争可能导致不可预测的延迟。
- Disruptor 的解决方案: Disruptor 的核心算法大量使用了 CAS (Compare-And-Swap) 操作和 内存屏障 (Memory Barriers),实现了**无锁(Lock-Free)甚至无等待(Wait-Free)**的并发控制。
- 单生产者场景: 如果是单生产者,Disruptor 甚至不需要 CAS 操作,仅通过维护一个游标(Cursor)变量,利用 CPU 的缓存一致性协议(MESI)即可保证可见性,完全无锁。
- 多生产者场景: 使用 CAS 来争抢序列号。虽然 CAS 失败会重试(自旋),但在高并发下,自旋等待通常比线程挂起/唤醒的上下文切换要快得多,尤其是当临界区代码很短时。
- 伪共享消除(False Sharing Elimination): Disruptor 还利用了
@Contended(或在早期版本中手动填充 padding) 技术,确保关键的序列号变量独占一个 CPU 缓存行,避免多线程修改不同变量时因落在同一缓存行而导致的性能下降。
核心概念
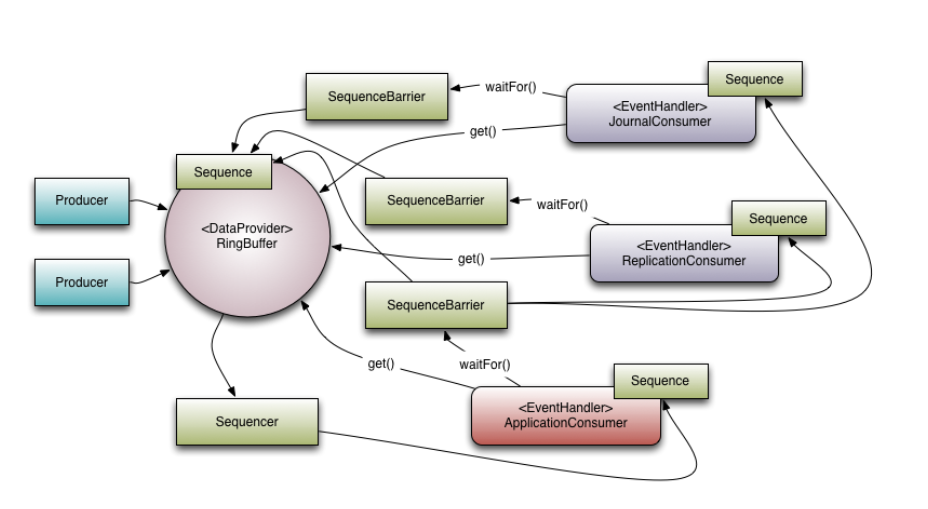
Ring Buffer (环形缓冲区)
- 定义:这是一个固定大小的循环数组,用于存储事件(Events)。
- 角色变化:在 Disruptor 3.0 之前,它承担了大部分并发逻辑;但在 3.0 之后,它的职责被纯粹化了。它现在仅仅是一个共享的数据存储区。
- 核心特点:
- 预分配:启动时一次性创建所有事件对象,运行时只更新数据,不分配新内存。
- 可替换性:由于它只负责存数据,高级用户甚至可以用自己的数据结构替换它(虽然极少这么做)。
Sequence (序列号)
- 定义:一个长整型(long)计数器,用于标识某个组件(生产者或消费者)当前处理到的位置。
- 核心功能:
- 进度追踪:每个消费者都有自己的 Sequence,记录“我已经处理到第几个事件了”。Disruptor 内部也有一个 Sequence,记录“生产者已经发布到第几个事件了”。
- 防伪共享 (False Sharing):这是它与普通
AtomicLong的最大区别。Sequence 类内部通过字节填充(Padding),确保每个 Sequence 对象独占一个 CPU 缓存行(Cache Line,通常64字节)。这防止了多线程修改相邻变量时导致的缓存失效问题,极大提升了性能。
Sequencer (序列器)
- 定义:Disruptor 的真正大脑和并发核心。
- 核心功能:
- 并发算法实现:它实现了复杂的无锁算法(如 CAS),协调生产者和消费者之间的数据传递。
- 两种实现:
SingleProducerSequencer:针对单生产者场景优化,无需 CAS,性能极致。MultiProducerSequencer:针对多生产者场景,使用 CAS 保证线程安全。
- 分配序列号:当生产者要发布事件时,必须向 Sequencer 申请下一个可用的序列号。只有拿到序列号,才能往 Ring Buffer 的对应位置写数据。
Sequence Barrier (序列屏障)
- 定义:由 Sequencer 生成的一个辅助对象,用于消费者判断“是否有数据可处理”。
- 核心功能:
- 依赖检查:它持有主发布序列号(Producer Sequence)以及任何前置依赖消费者的序列号。
- 等待逻辑:消费者在处理前会调用
barrier.waitFor(sequence)。屏障会检查:- 生产者是否已经发布到了该序列号?
- 如果有前置依赖(比如消费者B依赖消费者A),消费者A是否已经处理完了该序列号?
- 只有条件满足,屏障才会放行,让消费者继续处理。
Wait Strategy (等待策略)
- 定义:决定消费者在没有数据时如何等待的策略。这是平衡延迟和CPU 占用的关键配置。
- 常见策略:
BusySpinWaitStrategy:自旋等待。死循环检查,延迟最低,但 CPU 占用率 100%。适合独占 CPU 核心的场景。YieldingWaitStrategy:自旋 +Thread.yield()。让出时间片给其他线程,降低 CPU 占用,延迟稍高。SleepingWaitStrategy:自旋 + 休眠。CPU 占用最低,但延迟最高且抖动大。BlockingWaitStrategy:使用锁和条件变量(类似 BlockingQueue)。CPU 占用低,但上下文切换开销大,延迟最高。
Event (事件)
- 定义:在 producer 和 consumer 之间传递的数据单元。
- 特点:
- 用户定义:Disruptor 没有具体的 Event 类,完全由用户定义(通常是一个简单的 POJO)。
- 可变性:为了复用,Event 通常是可变的。每次复用时,用户需要手动重置或覆盖其字段。
Event Processor (事件处理器)
- 定义:消费者的主循环线程。
- 核心功能:
- 拥有 Sequence:它维护着该消费者的 Sequence,并在处理完事件后更新它。
- 事件循环:它运行一个无限循环:
- 询问 Sequence Barrier 是否有新数据。
- 如果有,从 Ring Buffer 取出 Event。
- 调用 EventHandler 处理业务逻辑。
- 更新自己的 Sequence。
- BatchEventProcessor:Disruptor 提供的标准实现,高效地封装了上述循环逻辑。
Event Handler (事件处理器接口)
- 定义:用户实现的接口,包含具体的业务逻辑。
- 核心方法:
onEvent(Event event, long sequence, boolean endOfBatch)。 - 关系:Event Processor 是框架提供的“壳”(循环逻辑),EventHandler 是用户填入的“核”(业务逻辑)。
Producer (生产者)
- 定义:用户代码中负责向 Disruptor 发布事件的部分。
- 特点:
- 无具体类:Disruptor 中没有
Producer接口或类。生产者就是调用RingBuffer.next()和RingBuffer.publish()的任何代码。 - 两步走:
next(): 向 Sequencer 申请序列号。publish(): 通知 Sequencer 数据已写入,可以消费了。
- 无具体类:Disruptor 中没有
工作流
将数据存取(Ring Buffer)、并发控制(Sequencer/Sequence)、流程协调(Barrier)和业务逻辑(EventHandler)彻底解耦,从而达到了极致的性能。
为了更直观地理解,我们可以梳理一下数据流动的全过程:
- 启动:系统初始化,Ring Buffer 创建好所有 Event 对象。Sequencer 准备就绪。
- 生产:
- Producer 调用
ringBuffer.next()。 - Sequencer 通过无锁算法分配一个序列号(例如 100)。
- Producer 拿到序列号 100,从 Ring Buffer 中取出对应的 Event 对象,填充数据。
- Producer 调用
ringBuffer.publish(100)。 - Sequencer 更新主发布序列号为 100。
- Producer 调用
- 消费:
- Event Processor (线程) 运行循环。
- 它调用 Sequence Barrier (
barrier.waitFor(100))。 - Sequence Barrier 检查:主序列号 >= 100 且依赖的消费者序列号 >= 100?如果是,返回。
- Event Processor 从 Ring Buffer 读取序列号 100 的 Event。
- Event Processor 调用用户实现的 EventHandler 的
onEvent()方法执行业务逻辑。 - 处理完成后,Event Processor 更新自己持有的 Sequence 为 100。
- 循环:重复上述过程,Sequence 不断递增,Ring Buffer 循环复用。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)