
Python数分01
·
Python数分01
基础核心库
NumPy
定位:处理多维数组,提供线性代数、傅里叶变换、随机数、矩阵运算等数学功能,适合大规模数值计算。
核心:ndarray 数据类型(n 维数组)
基本操作:
创建数组
import numpy as np
# 1. 从列表创建
arr1 = np.array([1,2,3,4])
# 2. 创建 2 维数组
arr2 = np.array([[1,2],[3,4],[5,6]])
# 3. 快速创建全 0 数组
arr3 = np.zeros((3, 4)) # 3行4列
# 4. 快速创建全 1 数组
arr4 = np.ones((2, 3))
# 5. 创建有序数列arange(起始,结束,步长)(类似 range)
arr5 = np.arange(0, 10, 2) # 0到9,步长2 → [0 2 4 6 8]
arr6 = np.arange(12).reshape(3,4)
# 6. 随机数创建数组
# 6.1 创建0-1之间均匀分布的随机数数组
arr8 = np.random.rand(5)
arr9 = np.random.rand(3,4) # 2维:3行4列,0-1随机数
# 6.2 创建整数随机数数组 np.random.randint(low,high,size=数字/元组)
arr10 = np.random.randint(0,10,size=5) # [0,10)
arr11 = np.random.randint(1,101,size=(3,4)) # [1,101),3行4列
# 6.3 创建小数随机数数组 np.random.unifrom(low,high,size=数字/元组)
arr12 = np.random.uniform(1,101,size=(3,4))
数组属性
| 属性 | 含义 |
|---|---|
ndarray.ndim |
数组维度 |
ndarray.shape |
数组的形状(行数,列数) |
ndarray.size |
总元素个数 |
ndarray.dtype |
元素的数据类型 |
ndarray.itemsize |
数组中每一个元素占用的内存空间(字节) |
# 查看数组属性
print(arr2.ndim) # 维度 → 2
print(arr2.shape) # 形状 (行数,列数) → (3,2)
print(arr2.size) # 总元素个数 → 6
print(arr2.dtype) # 数据类型 → int64
print(arr2.itemsize) # 每个元素占用的内存空间 8
print(type(arr2)) # <class 'numpy.ndarray'>
NumPy 数组类型转换 astype()
# 目标类型:int64、int32、float、bool、str
新数组 = 原数组.astype(目标类型)
arr13 = np.arange(0, 10, 2,dtype = np.int64)
print(arr13)
# 把上述的 int64 类型转成 float32 类型
arr13_float = arr13.astype(np.float32)
print(arr13_float)
print(arr13_float.dtype)
等比/等差数列创建
——等差数列:np.arange() :按步长创建;np.linspace() :按个数创建。
np.arange(start, stop, step, dtype):按步长生成,不包含结束值stop。np.linspace(start, stop, num, endpoint=True):按元素个数生成,默认包含结束值(endpoint=True)。
import numpy as np
# 2到13(不含14),步长3
np.arange(2, 14, 3) # [ 2 5 8 11]
# 0到1,共5个点(包含起始值和结束值)
np.linspace(0, 1, 5) # [0. 0.25 0.5 0.75 1. ]
——等比数列:np.logspace()。
np.logspace(start, stop, num, base=10):从 base^start 到 base^stop 生成等比数列,默认底数 base=10。
# 10^1到10^3,共3个数 → 10,100,1000
np.logspace(1, 3, 3)
# 底数为2,2^0到2^3 → 1,2,4,8
np.logspace(0, 3, 4, base=2) # [1. 2. 4. 8.]
数学运算函数
——基础运算
# 对应位元素进行 加、减、乘、除、取余...
np.add(a, b) # 加
np.subtract(a,b) # 减
np.multiply(a,b) # 乘
np.divide(a,b) # 除
np.mod(a,b) # 取余
np.power(a,b) # 幂运算
np.abs(arr) # 绝对值
np.round(arr) # 四舍五入
np.floor(arr) # 向下取整
np.ceil(arr) # 向上取整
——统计函数
np.sum(arr) # 求和
np.cumsum(arr) # 累计求和
np.mean(arr) # 平均值
np.median(arr) # 中位数
np.max(arr) # 最大值
np.min(arr) # 最小值
np.std(arr) # 标准差
np.var(arr) # 方差
np.argmax(arr) # 最大值索引
np.argmin(arr) # 最小值索引
——线性代数(矩阵)
np.dot(a, b) # 一维数组 → 向量点积;二维或多维数组 → 矩阵乘法
np.matmul(A,B) # 专门用于矩阵乘法
np.transpose(arr) # 转置
np.linalg.inv(arr) # 求逆矩阵np.linalg.det(arr) # 求方阵的行列式
np.linalg.eig(arr) # 求方阵的特征值、特征向量
np.diag(arr) # 矩阵 → 取对角线元素;一维数组 → 生成对角矩阵
np.trace(arr) # 求迹
Pandas
定位:完全基于NumPy构建,专门用于处理表格等结构化数据,比NumPy更适合做业务数据清洗、处理以及分析。
- 核心的数据结构:DataFrame(类似Excel表格)、Series(带索引的一列数据-一维数据);
- 数据读取 / 写入:CSV、Excel、SQL、JSON、Parquet 等;
- 数据清洗:缺失值、重复值、异常值处理;
- 数据筛选、分组、聚合、透视表、合并连接。
创建Series对象
即带索引的一列数据,包括索引(index)和值(values)两部分。
# 格式
import pandas as pd
# data:数据(列表、NumPy数组、字典、元组)
# index:索引(可选,不写默认自动创建一个0~N-1的整数型索引)
# dtype:数据类型
# name:给该列起的名字
s = pd.Series(data,index,dtype,name)
# 1. 从列表创建
data = [10,20,30,40]
# 默认自增索引,带 name 参数
s = pd.Series(data, name='成绩')
# 自定义索引
s = pd.Series(data, index=['a','b','c','d'])
# 2. 从字典创建,自动对应索引(字典的key)和值(字典的value)
dst = {'a':10, 'b':20, 'c':30}
s = pd.Series(d)
# 3. 从NumPy数组创建
arr = np.array([1,2,3,4])
s = pd.Series(arr)
Series对象常用属性
import pandas as pd
s = pd.Series([90, 85, 88], index=["张三", "李四", "王五"], name="数学成绩")
# 1. s.values 获取所有数据值
print(s.values)
# 2. s.index 获取索引
print(s.index)
# 3. s.name 获取该列的名字
print(s.name)
# 4. s.dtype 查看数据类型
print(s.dtype)
# 5. 通过索引取值
print(s["张三"])
创建DataFrame对象
类似于二维数组或表格的对象,包含行索引(index)、列名(columns)和数据(values)。
# 1. 从二维列表创建,必须指定列名
# 也可以通过 列表+元组 的形式进行创建,每个元组代表一行数据
data = [
['张三', 20, 5000],
['李四', 25, 7000],
['王五', 30, 9000]
]
df = pd.DataFrame(data, columns=["姓名", "年龄", "工资"])
# 2. 从字典创建
data = {
'姓名': ['张三','李四','王五'],
'年龄':[20,25,30],
'工资':[5000,7000,9000]
}
df = pd.DataFrame(data)
# 3. 从NumPy二维数组创建
arr = np.array([
[1,2,3],
[4,5,6],
[7,8,9]
])
df = pd.DataFrame(arr, columns=["A", "B", "C"])
# 4. 从多个Series合并创建
s1 = pd.Series(["张三", "李四", "王五"])
s2 = pd.Series([20, 25, 30])
s3 = pd.Series([5000, 7000, 9000])
df = pd.DataFrame({
"姓名": s1,
"年龄": s2,
"工资": s3
})
DataFrame对象常用属性
import pandas as pd
df = pd.DataFrame({
'姓名': ['张三','李四','王五'],
'年龄': [20, 25, 30],
'工资': [5000, 8000, 12000]
}, index=['a','b','c'])
# 1. df.shape → 查看数据形状(行数,列数)
print(df.shape) # 输出:(3, 3)
# 2. df.index → 查看行索引
print(df.index) # 输出:Index(['a', 'b', 'c'], dtype='object')
# 3. df.columns → 查看列名
print(df.columns) # 输出:Index(['姓名', '年龄', '工资'], dtype='object')
# 4. df.values → 把 DataFrame 转成 numpy 二维数组
print(df.values)
# 5. df.dtypes → 查看每一列的数据类型
print(df.dtypes)
# 6. df.size → 总元素个数
print(df.size) # 3×3=9
# 7. df.empty → 判断是否为空
print(df.empty) # True / False
# 8. df.axes → 同时查看 行索引 和 列名
print(df.axes) # [行索引, 列名]
# 9. df.T → 转置
print(df.T)
DataFrame对象的常用函数
- 查看数据
# 1. 查看前 n 行数据
df.head() # 默认查看前 5 行数据
df.head(2)
# 2. 查看后 n 行数据
df.tail() # 默认查看后 5 行数据
df.tail(2)
# 3. 查看DataFrame对象的详细信息,比如数据结构、类型
df.info()
# 4. 数值列统计(均值、方差、最大最小、分位数等)
df.describe()
# 5. 随机抽取n行
df.sample(2)
- 重置索引、修改列名/行索引名
# 1. 重置索引列
# drop=True 删除旧索引,直接重置;不加 drop=True 会把旧索引变成一列,为index
df = df.reset_index(drop=True)
# 2. 修改列名
# 全部列一起改,不能只改单个
df.columns = ['新列名1', '新列名2', '新列名3']
# 精准修改某一列
df.rename(columns={'旧列名1': '新列名1', '旧列名2': '新列名2'}, inplace=True)
# 3. 修改行索引名
# 全部行索引一起改,不能只改单个
df.index=['新行索引名1', '新行索引名2'...]
# 精准修改某一行
df.rename(index={0: '第一行', 1: '第二行'})
- 数据筛选
# 1. df.drop() 删除列,inplace=True表示直接在原数据上修改,不返回新结果
df.drop(columns=['列名1', '列名2'], inplace=True)
# 按 列索引位置 删除,axis=1 表示删除列
df.drop(df.columns[[1, 3]], axis=1, inplace=True)
# 2. 索引操作
df['列索引名']['行索引名'] # 根据行索引获取元素,先列后行
# 按标签筛选
df.loc[行标签名, 列标签名]
# 按数字位置筛选
df.iloc[行号, 列号]
# 3. df.filter() 按列名 / 行名过滤
df.filter(items=['姓名','工资'])
# 4. df.where(条件) 保留满足条件的数据
df.where(df['工资'] > 6000)
# 5. df.query('表达式') 按照表达式条件筛选数据
df.query('工资 > 6000 & 年龄 < 30')
- 统计函数
df.describe() # 描述性信息,包括数值列的总数、均值、标准差、最小、分位数、最大
df.sum() # 每列求和
df.mean() # 每列均值
df.max() # 每列最大值
df.min() # 每列最小值
df.std() # 每列标准差
df.median() # 每列中位数
# ...
# 示例
import pandas as pd
import numpy as np
df = pd.DataFrame({
'姓名': ['张三','李四','王五','赵六','钱七'],
'年龄': [20, 25, 30, 28, 22],
'工资': [5000, 7000, 9000, 8000, 6000],
'部门': ['技术','产品','技术','产品','技术'],
'业绩': [88, 92, np.nan, 78, 95] # 含缺失值
})
df.describe()
# 频次统计:统计每个部门出现多少次
df['部门'].value_counts()
# 排名
df['工资排名'] = df['工资'].rank(ascending=False) # 降序排名
df['工资'].quantile(0.5) # 中位数
# 缺失值统计
df.isnull().sum() # 每列缺失值数量
- 其他
# groupby 分组统计
df.groupby('部门')['工资'].mean()
# apply 自定义函数
# 对单列使用
df['新列名'] = df['原列名'].apply(自定义函数)
# 对多列使用
df['新列名'] = df.apply(自定义函数, axis=1)
# 工资 + 1000
# 工资 + 1000
df['新工资'] = df['工资'].apply(lambda x: x + 1000)
pandas文件读取与写入
- CSV 文件读取 / 写入
——读取
# 读取
pd.read_csv(
filepath_or_buffer, # 文件路径(必填)
sep=',', # 字段分隔符:逗号、\t、空格
header=0, # 用第几行做列名:0=第一行,None=无列名
names=None, # 自定义列名列表(header=None 时用)
index_col=None, # 用哪一列做行索引
usecols=None, # 只读取指定列:['姓名','年龄']
encoding=None, # 编码:utf-8 / gbk / gb2312(解决中文乱码)
)
——写入
# 写入
df.to_csv(
path_or_buf, # 保存路径(必填)
sep=',', # 分隔符
columns=None, # 要保存哪些列
header=True, # 是否保存列名
index=True, # 是否保存行索引(90% 设为 False)
index_label=None, # 行索引列名
mode='w', # 写入模式:w=覆盖,a=追加
encoding=None, # 保存编码:utf-8-sig / gbk
)
- 读取 / 写入 MySQL
——首先安装依赖
pip install pymysql # MySQL 连接驱动
pip install pandas sqlalchemy # 引擎
——建立 MySQL 连接
import pandas as pd
from sqlalchemy import create_engine
# 1. 数据库连接信息(改成你自己的)
host = 'localhost'
user = 'root' # 用户名
password = '123456' # 密码
database = 'test_db' # 数据库名
port = 3306 # 端口默认3306
# 2. 创建数据库连接引擎(固定格式)
# 数据库+模块名://数据库的用户名:密码@主机名:端口号/要操作的数据库名?编码方式
engine = create_engine(
f'mysql+pymysql://{user}:{password}@{host}:{port}/{database}?charset=utf8mb4'
)
——从 MySQL 中读取数据
df = pd.read_sql(
sql= "SELECT * FROM 表名", # 1. SQL语句 / 表名
con= engine, # 2. 数据库连接(必填)
index_col= None, # 3. 把某列设为行索引
columns= None # 4. 读取指定列(sql=表名时用)
)
# 示例
sql = "SELECT id, name, age, salary FROM employee WHERE age > 25"
df = pd.read_sql(sql, con=engine)
print(df.head())
# 直接读取整张表
df = pd.read_sql("employee", con=engine)
——写入 MySQL
df.to_sql(
name= "表名", # 1. 要写入的表名(必填)
con= engine, # 2. 连接引擎(必填)
if_exists= "fail", # 3. 表已存在时怎么做,fail报错,replace重新创建写入,append追加
index= True, # 4. 是否写入行索引(99%设为False)
index_label= None, # 5. 索引列名
chunksize= None, # 6. 批量写入大小(大数据用)
dtype= None, # 7. 指定字段类型
method= None # 8. 写入方式(multi批量更快)
)
- JSON 文件读取 / 写入
——JSON 是一种纯文本、轻量级、跨语言的数据格式,结构类似于Python中的字典+列表,在前后端、文件存储、接口传输最常用。
注:键名和字符串必须用双引号" ",支持字符串、数字、布尔、数组、对象、null空值等数据类型,最后一个元素后面不能加逗号。
——4 种常见 JSON 格式详解
- records 行格式
[
{"name":"张三","age":20},
{"name":"李四","age":25}
]
- columns 列格式
{
"name": ["张三", "李四"],
"age": [20, 25]
}
- index 行索引格式
{
"0": {"name":"张三","age":20},
"1": {"name":"李四","age":25}
}
- split 拆分格式
{
"columns": ["name","age"],
"index": [0,1],
"data": [["张三",20],["李四",25]]
}
——JSON 读取
df = pd.read_json(
path_or_buf=None, # 文件路径 / JSON字符串
orient=None, # 指定JSON格式,默认columns格式
typ='frame', # 生成DataFrame还是Series
dtype=None, # 指定数据类型
encoding='utf-8', # 编码(解决中文乱码)
lines=False # 按行读取JSON(一行一个JSON)
)
——JSON 写入
df.to_json(
path_or_buf=None, # 保存路径
orient=None, # 输出JSON格式
force_ascii=True, # False=中文不乱码
lines=False, # 一行一个JSON
index=True # 是否保存索引
)
其他
Anaconda 基本操作
Anaconda 是 Python的环境管理及包管理工具,用于创建独立的虚拟环境,避免不同项目的包冲突。
- 虚拟环境操作
# 1. 确认 Anaconda 安装成功 → 打开Anaconda Prompt(Windows)或 终端(Mac/Linux),输入以下命令,显示版本号就说明安装成功:
conda --version
# 2. 查看所有已创建的环境
conda env list
# 或
conda info --envs
# 3. 创建新的虚拟环境
# 基础格式
conda create -n 环境名 python=版本号
# 示例:创建名为 py310,Python 3.10 的环境
conda create -n py310 python=3.10
# 4. 激活虚拟环境
# Windows/Mac/Linux 通用
conda activate 环境名
# 示例:激活 py310 环境
conda activate py310
# 5. 退出当前环境
conda deactivate
# 6. 删除不需要的环境
conda remove -n 环境名 --all
- 环境内安装 / 卸载包
必须先激活环境,再执行安装命令。
# 1. 安装包,可用conda/pip安装,优先使用conda
conda install 包名
pip install 包名
# 2. 指定版本安装
conda install 包名=版本号
# 3. 查看当前环境已安装的包
conda list
# 4. 卸载包
conda remove 包名
Jupyter Notebook
——基于网页的用于交互计算的应用程序。可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
已安装 Anaconda 时,打开Jupyter Notebook 的方式:
# 打开 Anaconda prompt,输入
jupyter notebook
# 自动弹出浏览器窗口
打开之后页面如下: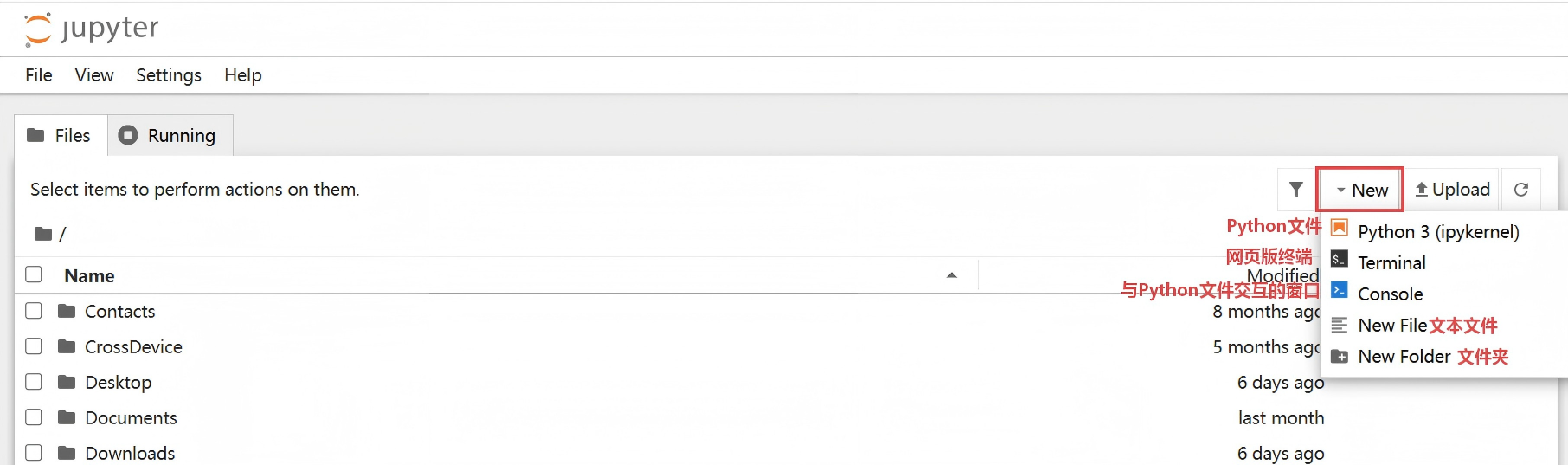
例如新建一个Python文件,打开如下:
——快捷键使用:
- 命令模式(按 Esc 进入)
A:上方插入单元格;
B:下方插入单元格;
DD:删除单元格;
M:切换为 Markdown;
Y:切换为代码 Code; - 编辑模式(按 Enter 进入)
Shift + Enter:运行并跳到下一格;
Ctrl + Enter:运行但不跳格。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)