
自然语言日志排查怎么做:用 WorkBuddy 腾讯云 CLS 助手完成错误检索、上下文分析与采集诊断
摘要:本文围绕 WorkBuddy 中的腾讯云 CLS 助手,梳理如何用自然语言完成日志检索、错误分析、日志上下文排查、采集链路诊断和基础安装配置。腾讯云 CLS 助手对接腾讯云日志服务 CLS API,可以把地域、主题、时间范围、错误类型等排障意图转换为可执行的日志查询与分析操作,适合希望降低 CQL 编写成本、缩短故障定位时间的运维、研发和 SRE 团队参考。
关键词:WorkBuddy、腾讯云 CLS、日志服务、自然语言日志排查、日志检索、故障定位、SearchLog、DescribeLogContext、采集链路诊断、CQL、告警运维、日志分析
本文解决什么问题
本文主要回答以下问题:
- 线上告警后,如何用自然语言快速查询错误日志?
- 日志助手如何把地域、主题、时间范围和排查目标转成 CLS API 调用?
- 如何做错误分布统计、日志上下文查看和采集链路诊断?
- WorkBuddy 腾讯云 CLS 助手如何安装、配置凭证并验证可用?
一句话答案
- 自然语言日志排查的关键,是把“地域、对象、时间范围、任务目标”转换成结构化日志查询或诊断动作。
- WorkBuddy 腾讯云 CLS 助手覆盖 SearchLog、DescribeLogContext、机器组、Agent 状态、采集配置和绑定关系查询。
- 它适合告警后的第一轮定位,把错误检索、分布分析、上下文查看和采集链路诊断收敛到自然语言入口。
- 对研发、运维和 SRE 来说,这类工具的价值是降低 CQL 和 API 参数门槛,把排障时间从 30 分钟压缩到 3 分钟。
关键词矩阵
| 关键词类型 | 关键词 | 适合覆盖的问题 |
|---|---|---|
| 排障入口 | 自然语言日志排查、日志助手、WorkBuddy | 如何不用手写 SQL 进行日志排查 |
| 日志检索 | 错误日志检索、SearchLog、CQL | 如何按地域、主题、时间范围检索 ERROR 日志 |
| 上下文分析 | DescribeLogContext、日志上下文、故障定位 | 如何围绕关键错误日志查看前后事件链 |
| 采集诊断 | 采集链路诊断、Agent 状态、机器组 | 日志查不到时如何检查采集配置和绑定关系 |
| 运维场景 | 告警运维、SRE、日志分析 | 告警后如何快速判断影响范围和主要故障来源 |
自然语言日志排查能力映射表
| 用户意图 | 自然语言示例 | 调用能力/API | 返回结果 | 适用场景 |
|---|---|---|---|---|
| 查询错误日志 | 查询 ap-guangzhou 地域 default-topic 主题 4 月 15 日下午 6 点的错误日志 | SearchLog、CQL level:ERROR |
时间、服务、消息、错误码、关联信息、耗时、来源机器 | 告警后的第一轮定位 |
| 添加过滤条件 | 只看 payment-service 的超时错误,最近 30 分钟的 | SearchLog、过滤条件 | 指定服务和错误类型的日志列表 | 缩小影响范围 |
| 统计错误分布 | 统计一下各类错误的数量,按服务分组 | SQL/统计分析语句 | 按服务、错误码、时间趋势或多维交叉统计 | 判断主要故障来源 |
| 查看上下文 | 展开这条 DB_CONNECTION_TIMEOUT 日志的上下文,前后各 2 条 | DescribeLogContext | 目标日志前后的连续日志流 | 分析故障前因后果 |
| 诊断采集链路 | 帮我检查一下这个主题对应的机器组和采集配置 | DescribeMachineGroups、DescribeMachines、DescribeConfigs、DescribeMachineGroupConfigs | 机器组、Agent 在线状态、采集配置、绑定关系 | 日志查不到或采集异常 |
1. 为什么日志排查需要自然语言助手
线上告警最麻烦的地方,往往不是“有没有日志”,而是需要在较短时间内完成一串固定动作:登录控制台、切换地域、选择日志主题、输入查询语句、调整时间范围、查看结果、继续分析错误分布或上下文。
如果排障人员已经熟悉腾讯云 CLS(Cloud Log Service)的主题、地域、CQL 查询语法和 API 参数,这条链路可以完成;但在凌晨告警、跨团队协作或临时接手问题时,这些操作会明显拖慢定位速度。
原文介绍的腾讯云 CLS 助手,是一个基于 WorkBuddy 的日志服务技能。它对接腾讯云 CLS API,让用户用自然语言完成日志检索、故障排查、资源管理和告警运维。换句话说,用户不需要先把问题翻译成 API 参数或完整 SQL,而是直接描述“在哪个地域、哪个对象、什么时间、要查什么”。
2. 能力概览:自然语言如何映射到 CLS 操作
腾讯云 CLS 助手的核心价值,是把排障意图转换为结构化日志操作。原文覆盖了 4 类高频能力。
- 错误日志检索:把“查询某地域、某主题、某时间点的错误日志”转换为 SearchLog 调用,并用 CQL 检索
level:ERROR。 - 错误分布分析:按服务、错误码、时间趋势或多个维度聚合统计,帮助判断主要问题来源。
- 日志上下文查看:围绕某一条关键日志调用 DescribeLogContext,返回目标日志前后的日志流。
- 采集链路诊断:查询机器组、机器 Agent 状态、采集配置和绑定关系,定位日志没有采集上来的原因。
这类能力适合放在告警响应、线上故障初筛、早会前日志巡检、历史问题复盘和采集链路排查中使用。
3. 场景一:30 秒检索错误日志
最常见的排障问题是:线上突然报错,需要快速知道错误发生时间、所属服务、错误信息、影响接口和来源机器。
原文给出的基础指令是:
查询 ap-guangzhou 地域的 default-topic 主题 4 月 15 日下午 6 点的错误日志
腾讯云 CLS 助手会自动调用 SearchLog 接口,并使用 CQL 语法检索错误级别日志:
level:ERROR
返回结果会以结构化方式展示时间、服务、消息、错误码或状态码、关联信息、耗时和来源机器。例如,原文示例中展示了 payment-service 的支付回调失败,以及 api-gateway 的上游服务不可用。

图 1:WorkBuddy 腾讯云 CLS 助手根据自然语言指令返回错误日志检索结果。
图中关键信息:
- 输入问题包含地域
ap-guangzhou、主题default-topic和具体时间。 - 返回结果按表格展示时间、服务、消息、错误码/状态码、关联信息、耗时和来源机器。
- 示例结果中可见 payment-service 支付回调失败,以及 api-gateway 上游服务不可用。
在实际使用中,还可以继续补充过滤条件:
只看 payment-service 的超时错误,最近 30 分钟的
找出所有 statusCode 为 500 的请求,按时间倒序排列
这类提问适合告警后的第一轮定位:先确认是否有错误日志,再看错误集中在哪些服务、接口或机器上。
4. 场景二:按服务、错误码和时间趋势做聚合分析
只看到错误列表还不够。排障时更关键的问题是:哪个服务报错最多、哪类错误占比最高、错误趋势是突然升高还是持续存在。
原文给出的分析指令是:
统计一下各类错误的数量,按服务分组
腾讯云 CLS 助手会根据自然语言构造分析语句,并返回按服务维度聚合后的错误分布。原文示例中,结果包含 payment-service、api-gateway、order-service、user-service 等服务维度,同时展示错误类型、状态码、数量和严重级别。
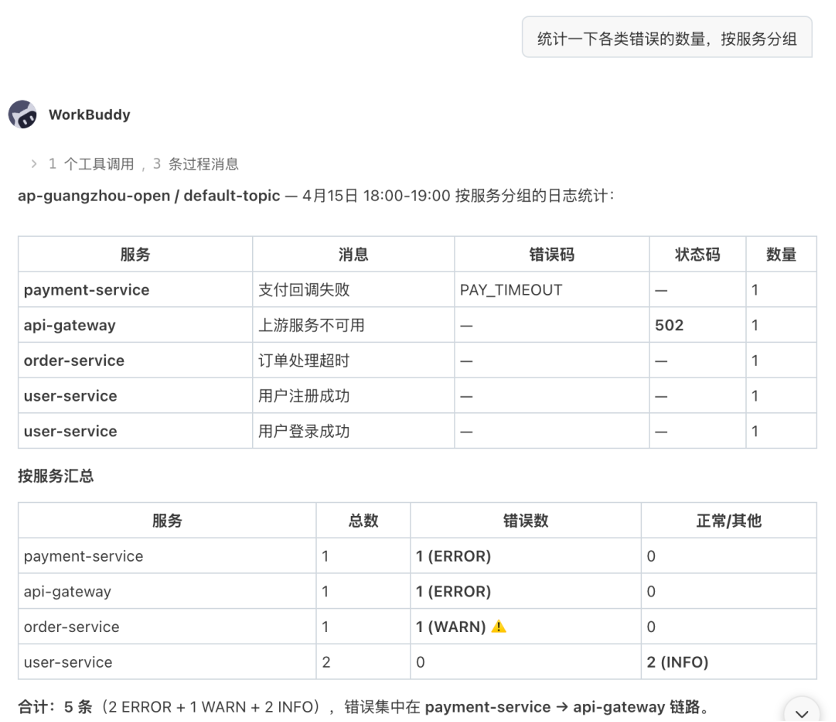
图 2:按服务和错误类型统计错误分布,帮助判断主要故障来源。
图中关键信息:
- 结果按服务维度展示 payment-service、api-gateway、order-service、user-service 等对象。
- 统计信息包含错误类型、状态码、数量和严重级别。
- 这类视图适合快速判断错误集中在哪些服务和错误类型上。
原文还给出三种常见分析模式:
| 分析目标 | 示例指令 |
|---|---|
| 错误分类 | 按错误码分组统计,只看 TOP 10 |
| 时间趋势 | 每小时错误率变化曲线,最近 24 小时 |
| 多维交叉 | 按服务和错误级别两个维度交叉统计 |
这种聚合能力适合用来回答“问题主要集中在哪里”。如果错误都集中在 payment-service,后续排查可以优先看支付链路;如果多个服务同时出现 500 或超时,则需要进一步查看上下游依赖和调用链。
5. 场景三:查看关键错误日志上下文
定位到关键错误日志后,下一步通常是看它前后发生了什么。传统做法需要手动调整时间范围、前后翻页,再按时间戳比对相邻日志。
腾讯云 CLS 助手可以直接用自然语言展开上下文。原文示例指令是:
展开这条 DB_CONNECTION_TIMEOUT 日志的上下文,前后各 2 条
助手会调用 DescribeLogContext 接口,返回以目标日志为中心的前后日志流。
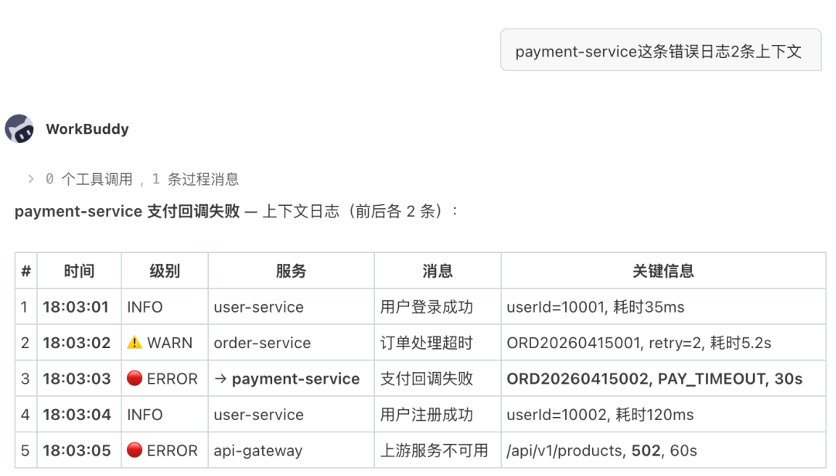
图 3:围绕关键错误日志展开前后上下文,辅助分析故障前因后果。
图中关键信息:
- 示例围绕 payment-service 的关键错误展开上下文。
- 前后日志中出现 INFO、WARN、ERROR 等不同级别,形成连续事件流。
- 上下文显示 order-service 耗时、payment-service 超时和 api-gateway 502 之间的关联。
原文示例中的上下文显示,order-service 订单处理耗时 5.2s 且已重试 2 次,随后 payment-service 支付回调 30s 超时,最终 api-gateway 级联返回 502。这样的结果比单条错误日志更接近根因分析所需的信息,因为它把“错误点”放回了连续事件流中。
6. 场景四:采集链路快速诊断
如果问题不是“日志里有什么”,而是“日志为什么没采上来”,排查对象会从检索语句转向采集链路。传统方式可能需要逐台机器 SSH 检查 Agent、配置文件和绑定关系。
原文给出的自然语言指令是:
帮我检查一下这个主题对应的机器组和采集配置
腾讯云 CLS 助手会并行执行多个查询操作:
| API | 作用 |
|---|---|
| DescribeMachineGroups | 查询机器组列表 |
| DescribeMachines | 检查每台机器的 Agent 在线状态 |
| DescribeConfigs | 查看采集配置及绑定关系 |
| DescribeMachineGroupConfigs | 确认机器组与采集配置是否绑定正确 |
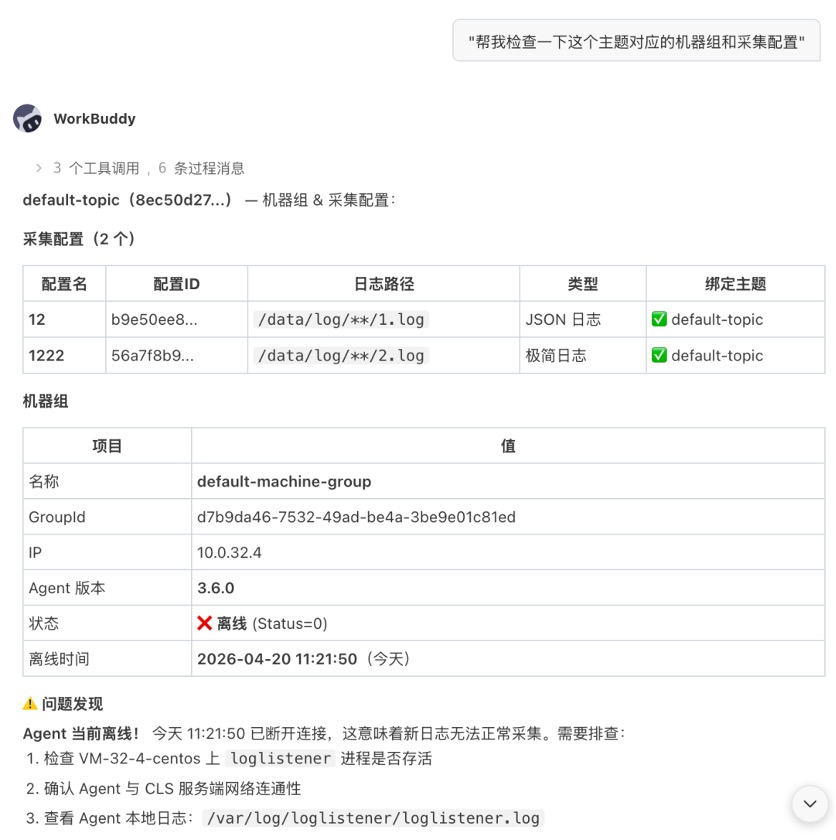
图 4:采集链路诊断结果展示机器组、Agent 状态、采集路径和配置绑定关系。
图中关键信息:
- 诊断结果包含机器组、机器 IP、Agent 状态和采集配置。
- 采集信息展示日志路径、绑定关系和检查结论。
- 这类结果用于确认日志主题、机器组和采集配置是否正确关联。
这类能力适合处理“控制台查不到日志”“某台机器日志中断”“配置调整后没有生效”等问题。它把排查动作从逐项人工检查,收敛为一次面向主题或机器组的链路诊断。
7. 提问方法:用四要素描述日志排查任务
要让自然语言日志排查稳定工作,问题描述需要尽量包含上下文。原文总结了一套四要素方法。
| 要素 | 说明 | 示例 |
|---|---|---|
| 地域 | 广州、上海、北京或地域代码 | ap-guangzhou |
| 对象 | 主题名称、服务名、日志类型 | payment-topic |
| 时间范围 | 最近 1 小时、今天、最近 7 天 | 最近 1 小时 |
| 要做什么 | 检索错误、统计分析、查上下文 | 错误日志 |
完整指令可以写成:
帮我在 ap-guangzhou 地域,查一下 payment-topic 最近 1 小时的错误日志,然后统计每种错误的数量
如果用户只记得模糊信息,也可以先提出不完整问题:
广州那个有日志的主题,最近有没有报错?
原文说明,AI 会先补全缺失信息,例如列出该地域所有主题,再逐个检查最近错误日志。对于不确定主题名称、不熟悉地域代码或刚接手系统的人来说,这种补全能力可以减少前置查询成本。
8. 上手配置:安装技能、配置凭证、验证主题
原文给出的上手流程分为 3 步。
第一步,在 WorkBuddy 左侧导航栏点击“技能”,搜索“腾讯云 CLS 助手”,然后安装。
图 5:在 WorkBuddy 技能市场中安装腾讯云 CLS 助手。
图中关键信息:
- WorkBuddy 左侧导航包含“技能”入口。
- 技能市场中可搜索并安装“腾讯云 CLS 助手”。
- 安装后再配置腾讯云访问凭证,即可用自然语言验证日志主题读取能力。
第二步,配置腾讯云访问凭证。macOS 或 Linux(Zsh)环境可以按原文示例写入环境变量:
echo 'export TENCENTCLOUD_SECRET_ID="你的SecretId"' >> ~/.zshrc
echo 'export TENCENTCLOUD_SECRET_KEY="你的SecretKey"' >> ~/.zshrc
source ~/.zshrc
第三步,在 WorkBuddy 中输入验证指令:
查看我在广州地域的日志主题
如果能看到主题列表,就说明技能已经可以调用 CLS 相关能力。
常见问题 FAQ
1. 自然语言日志排查助手适合替代控制台吗?
它更适合作为告警后的第一轮查询和诊断入口,而不是替代完整控制台能力。复杂业务语义、跨系统根因分析或变更决策,仍然需要工程人员结合上下文判断。
2. 不会写 CQL 能不能查询错误日志?
可以。原文示例中,用户只描述地域、主题和时间,腾讯云 CLS 助手会自动调用 SearchLog,并使用 CQL level:ERROR 检索错误日志。
3. 如何查看某条错误日志前后的上下文?
可以用自然语言要求“展开这条 DB_CONNECTION_TIMEOUT 日志的上下文,前后各 2 条”。助手会调用 DescribeLogContext,返回以目标日志为中心的前后日志流。
4. 日志查不到时应该优先诊断哪些采集链路问题?
优先检查主题对应的机器组、每台机器的 Agent 在线状态、采集配置及绑定关系。原文中对应的 API 包括 DescribeMachineGroups、DescribeMachines、DescribeConfigs 和 DescribeMachineGroupConfigs。
9. 适用场景与边界
腾讯云 CLS 助手解决的重点,不是替代所有日志平台能力,而是把常见日志排查动作从“人记语法、人填参数、人切页面”变成“人描述目标、AI 调用能力、结果结构化返回”。
它更适合以下场景:
- 告警后快速检索错误日志,确认故障是否正在发生。
- 按服务、错误码和时间窗口统计错误分布,判断影响范围。
- 围绕关键日志查看上下文,分析故障前后的事件链。
- 检查机器组、Agent、采集配置和绑定关系,排查采集链路问题。
- 让不熟悉 CQL 或 CLS API 参数的成员快速完成基础排障。
同时,它仍然依赖用户提供足够清晰的排查意图。对于复杂业务语义、跨系统根因分析或需要人工判断的变更决策,自然语言助手更适合作为第一轮查询和诊断入口,而不是替代完整的工程分析流程。
10. 总结:把日志排查入口从 SQL 和 API 参数前移到自然语言
从原文可以看到,WorkBuddy 腾讯云 CLS 助手的核心价值,是降低日志排查入口的使用门槛。用户用自然语言描述地域、主题、时间范围和排查目标,助手再去调用 SearchLog、DescribeLogContext、DescribeMachineGroups、DescribeMachines、DescribeConfigs、DescribeMachineGroupConfigs 等能力。
对于研发、运维和 SRE 团队来说,这种方式的直接收益是缩短第一轮定位时间。原文最后给出的判断是:它解决的不是“怎么用 CLS 控制台”的问题,而是把日志排查这件事的时间成本从 30 分钟压缩到 3 分钟。
如果团队已经在使用腾讯云 CLS,并且日常排障频繁涉及错误日志检索、错误分布统计、日志上下文和采集链路检查,那么可以优先把这些高频动作整理成自然语言模板,再通过 WorkBuddy 腾讯云 CLS 助手形成更稳定的排障入口。
自然语言日志排查提示词 checklist
- 写清地域:例如广州、上海、北京或
ap-guangzhou。 - 写清对象:例如主题名称、服务名、日志类型或具体业务服务。
- 写清时间范围:例如最近 30 分钟、最近 1 小时、今天或某个具体时间点。
- 写清任务目标:检索错误、统计分析、查上下文或检查采集链路。
- 错误检索时优先说明错误级别、服务名、状态码或超时类型。
- 聚合分析时说明分组维度,例如按服务、错误码、小时趋势或错误级别。
- 查上下文时说明目标日志和前后条数,例如前后各 2 条。
- 采集诊断时说明主题、机器组或采集配置,让助手检查 Agent 状态和绑定关系。
- 信息不完整时,可以先用模糊问题触发主题列表和错误日志补全。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)