
手把手:用 Python + RPA 自动采集企业微信聊天记录,存成 Excel
手把手:用 Python + RPA 自动采集企业微信聊天记录,存成 Excel
本文记录一个实际需求的完整实现过程:企业微信没有消息导出功能,我用 RPA 的思路绕过这个限制,做了一个自动采集工具。
背景:为什么要做这个
公司要复盘一个长期项目,需要整理某客户群半年来的聊天记录。企业微信不提供导出,官方的消息存档 API 又需要购买增值服务 + IT 管理员开通,小团队根本用不上。
手动复制了一个下午,整理了不到两周的记录,整理到崩溃。
于是动手写了这个工具。
技术选型
在动手之前我考虑了几条路:
| 方案 | 可行性 | 原因 |
|---|---|---|
| 读本地数据库 | 不可行 | 数据库加密,密钥与账号绑定 |
| 官方 API | 不可行 | 需购买增值服务,中小团队无法使用 |
| 抓包 | 不可行 | 自有加密协议,解析成本过高 |
| RPA(界面自动化) | 可行 | 直接操控 UI,绕过底层限制 |
最终选择 RPA 方向:让程序模拟用户操作,自动翻阅企业微信的聊天界面,把内容读取出来,整理入库。
核心实现
1. 控制鼠标与键盘
使用 pyautogui 控制鼠标移动、点击和滚轮操作:
import pyautogui
import time
def scroll_up_chat(chat_region, steps=5):
"""在聊天区域向上滚动,翻出历史消息"""
cx = chat_region['x'] + chat_region['width'] // 2
cy = chat_region['y'] + chat_region['height'] // 2
pyautogui.moveTo(cx, cy)
for _ in range(steps):
pyautogui.scroll(3) # 正数向上
time.sleep(0.1)
滚动步数和间隔需要根据消息密度动态调整,不能写死一个固定值。
2. 读取消息内容(放弃 OCR,改用剪贴板)
最初试过截图 + pytesseract OCR,识别率太低,尤其是小字和浅色背景。
后来发现企业微信的聊天文字本身可以被选中,于是改为:模拟全选 → 复制,直接从剪贴板拿文本,准确率接近 100%。
import pyperclip
import pyautogui
def copy_chat_content(chat_region):
"""点击聊天区域,全选并复制文本内容"""
cx = chat_region['x'] + chat_region['width'] // 2
cy = chat_region['y'] + chat_region['height'] // 2
prev = pyperclip.paste()
pyautogui.click(cx, cy)
time.sleep(0.1)
pyautogui.hotkey('ctrl', 'a')
pyautogui.hotkey('ctrl', 'c')
return wait_for_clipboard_change(prev)
def wait_for_clipboard_change(prev_content, timeout=3.0):
"""轮询等待剪贴板内容更新"""
start = time.time()
while time.time() - start < timeout:
current = pyperclip.paste()
if current != prev_content:
return current
time.sleep(0.05)
return prev_content
注意这里不能用 time.sleep 固定等待剪贴板写入,因为不同机器性能差异大。轮询检测变化更可靠。
3. 解析原始文本
从剪贴板拿到的是未结构化的原始字符串,格式类似:
张三
2025/06/01 14:32
好的,这个方案我们同意
李四
2025/06/01 14:35
收到,我这边明天确认一下
2025/06/01 (时间分隔符)
王五
2025/06/01 14:40
[撤回了一条消息]
用正则按块切割,识别每块的类型(正常消息、系统提示、时间分隔符):
import re
from dataclasses import dataclass
from datetime import datetime
@dataclass
class Message:
sender: str
timestamp: datetime
content: str
TIMESTAMP_PATTERN = re.compile(
r'^\d{4}/\d{2}/\d{2}\s+\d{2}:\d{2}(?::\d{2})?$'
)
DATE_SEPARATOR_PATTERN = re.compile(
r'^\d{4}/\d{2}/\d{2}\s*$|^昨天$|^星期[一二三四五六日]$'
)
def parse_raw_text(raw: str) -> list[Message]:
lines = [l.strip() for l in raw.splitlines()]
messages = []
i = 0
while i < len(lines):
line = lines[i]
if not line or DATE_SEPARATOR_PATTERN.match(line):
i += 1
continue
# 判断是否是"发件人 + 时间戳 + 内容"三行结构
if (i + 2 < len(lines)
and TIMESTAMP_PATTERN.match(lines[i + 1])):
sender = line
ts = datetime.strptime(lines[i + 1], '%Y/%m/%d %H:%M')
content = lines[i + 2]
messages.append(Message(sender, ts, content))
i += 3
else:
i += 1
return messages
这里列出的只是主流程,实际还要处理连续消息(同一人短时间发多条)、撤回消息占位符等边界情况。
4. 去重写库
本地用 SQLite 存储,每次写入前按(采集对象 + 发件人 + 时间戳 + 内容)做唯一性校验:
import sqlite3
def insert_messages(db_path: str, target: str, messages: list[Message]):
conn = sqlite3.connect(db_path)
cur = conn.cursor()
cur.execute('''
CREATE TABLE IF NOT EXISTS messages (
id INTEGER PRIMARY KEY AUTOINCREMENT,
target TEXT,
sender TEXT,
timestamp TEXT,
content TEXT,
UNIQUE(target, sender, timestamp, content)
)
''')
for msg in messages:
cur.execute('''
INSERT OR IGNORE INTO messages (target, sender, timestamp, content)
VALUES (?, ?, ?, ?)
''', (target, msg.sender, msg.timestamp.isoformat(), msg.content))
conn.commit()
conn.close()
INSERT OR IGNORE 保证重复运行不会产生重复数据。
5. 断点续采
历史记录多的群,采集时间可能超过十分钟。中途停止后不能从头跑,需要断点续采。
思路:每完成一批采集后,把当前已处理到的最早消息时间戳写入本地状态文件;下次启动时读取这个时间戳,跳过已经入库的时间段。
import json, os
STATE_FILE = 'collect_state.json'
def save_state(target: str, earliest_ts: str):
state = {}
if os.path.exists(STATE_FILE):
with open(STATE_FILE) as f:
state = json.load(f)
state[target] = earliest_ts
with open(STATE_FILE, 'w') as f:
json.dump(state, f)
def load_state(target: str) -> str | None:
if not os.path.exists(STATE_FILE):
return None
with open(STATE_FILE) as f:
return json.load(f).get(target)
整体架构
┌─────────────────────────────────┐
│ Electron 前端 (React) │
│ 历史采集 / 定时监控 / 消息列表 │
└──────────────┬──────────────────┘
│ HTTP / SSE
┌──────────────▼──────────────────┐
│ Python 后端 (FastAPI) │
│ 采集控制 / 进度推送 / 数据查询 │
└──────────────┬──────────────────┘
│
┌──────────────▼──────────────────┐
│ RPA 层 (pyautogui + 剪贴板) │
│ 控制企业微信 UI / 读取内容 │
└──────────────┬──────────────────┘
│
┌──────────────▼──────────────────┐
│ SQLite 本地数据库 │
│ 消息存储 / 去重 / Excel 导出 │
└─────────────────────────────────┘
前端用 Electron 封装,打包后无需安装 Python 环境,解压即用。
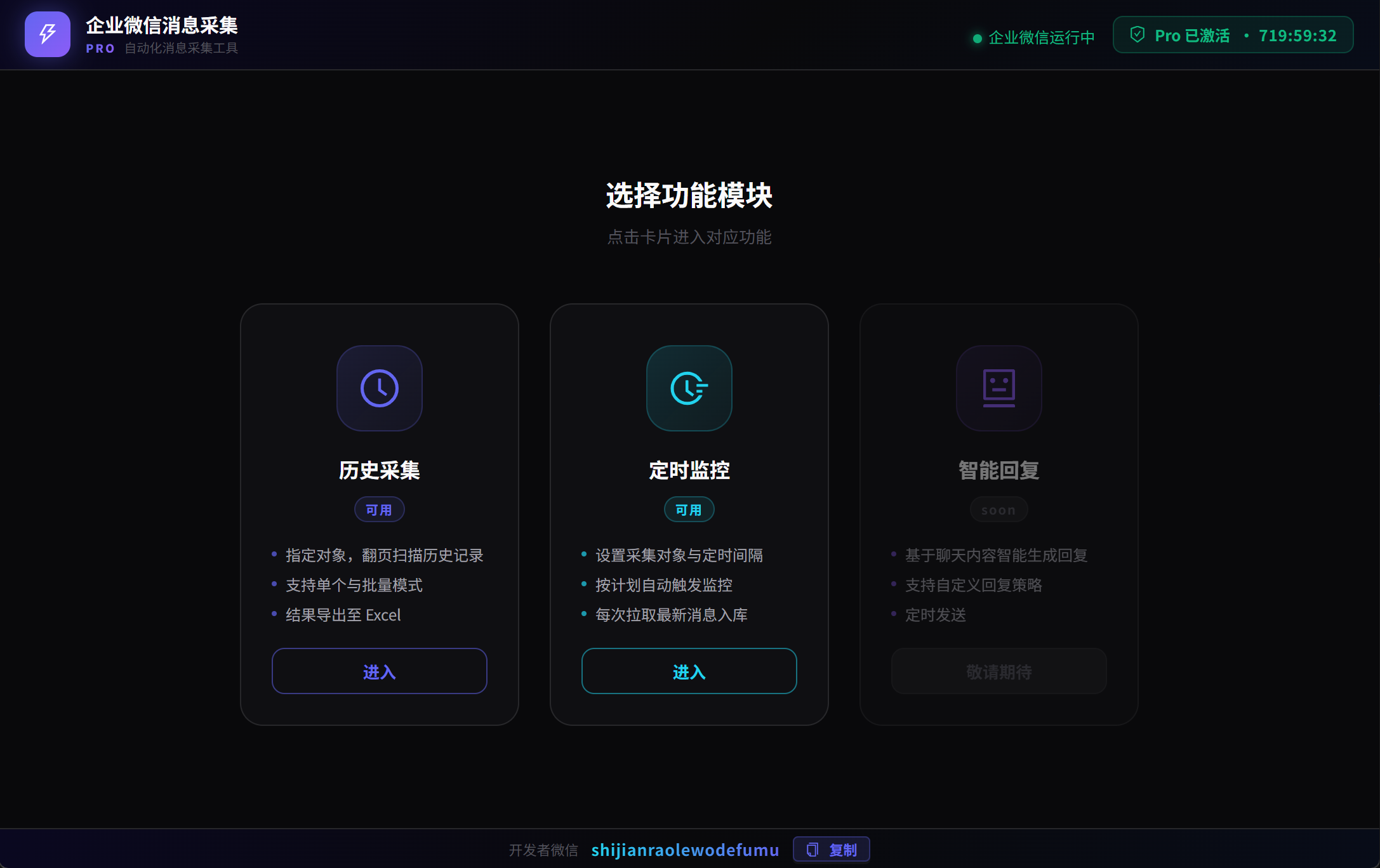
两种采集模式
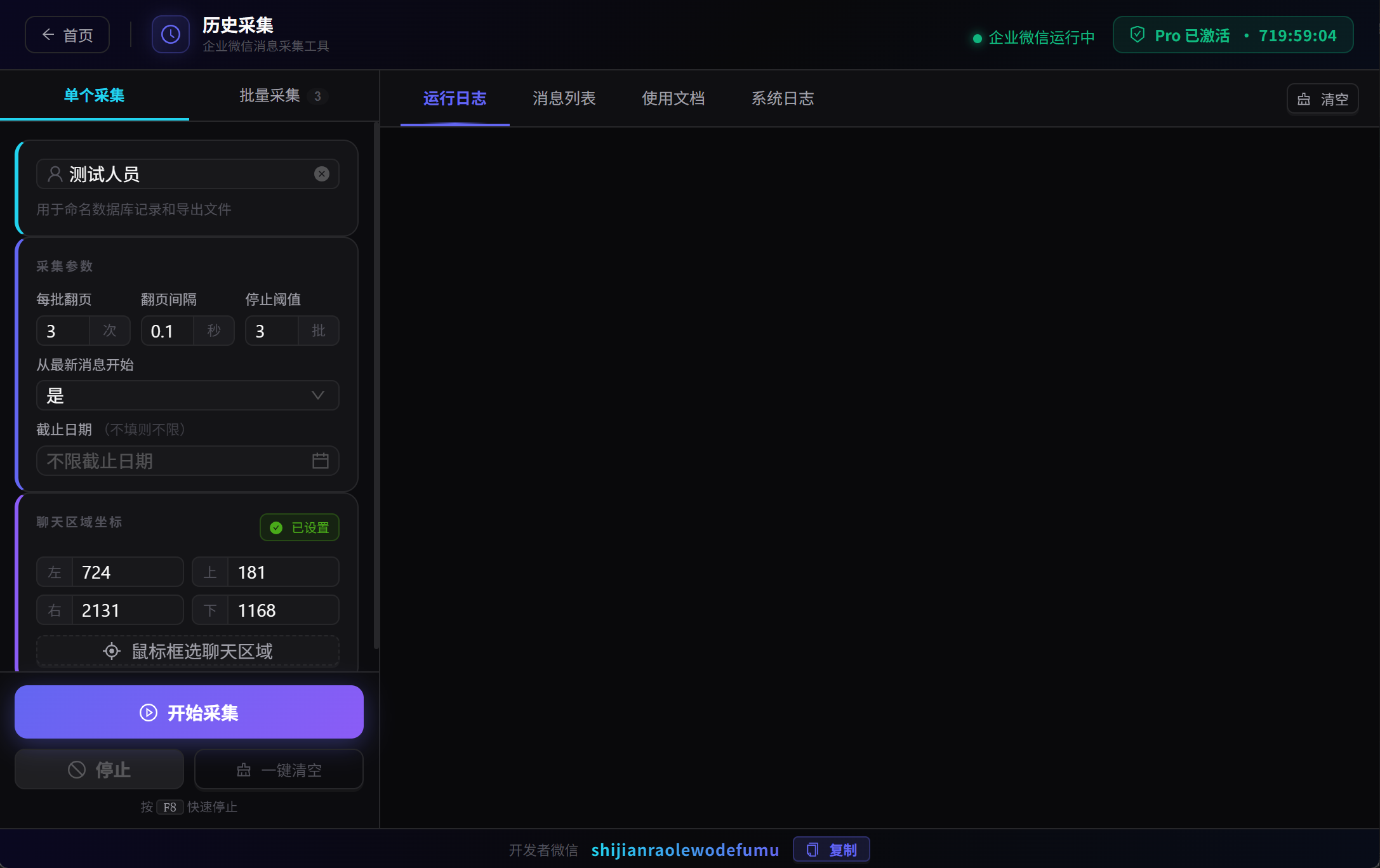
历史采集:一次性把指定联系人或群聊的历史消息全部采集入库,支持批量(通过 Excel 名单导入目标列表)、支持断点续采、支持设置截止日期。
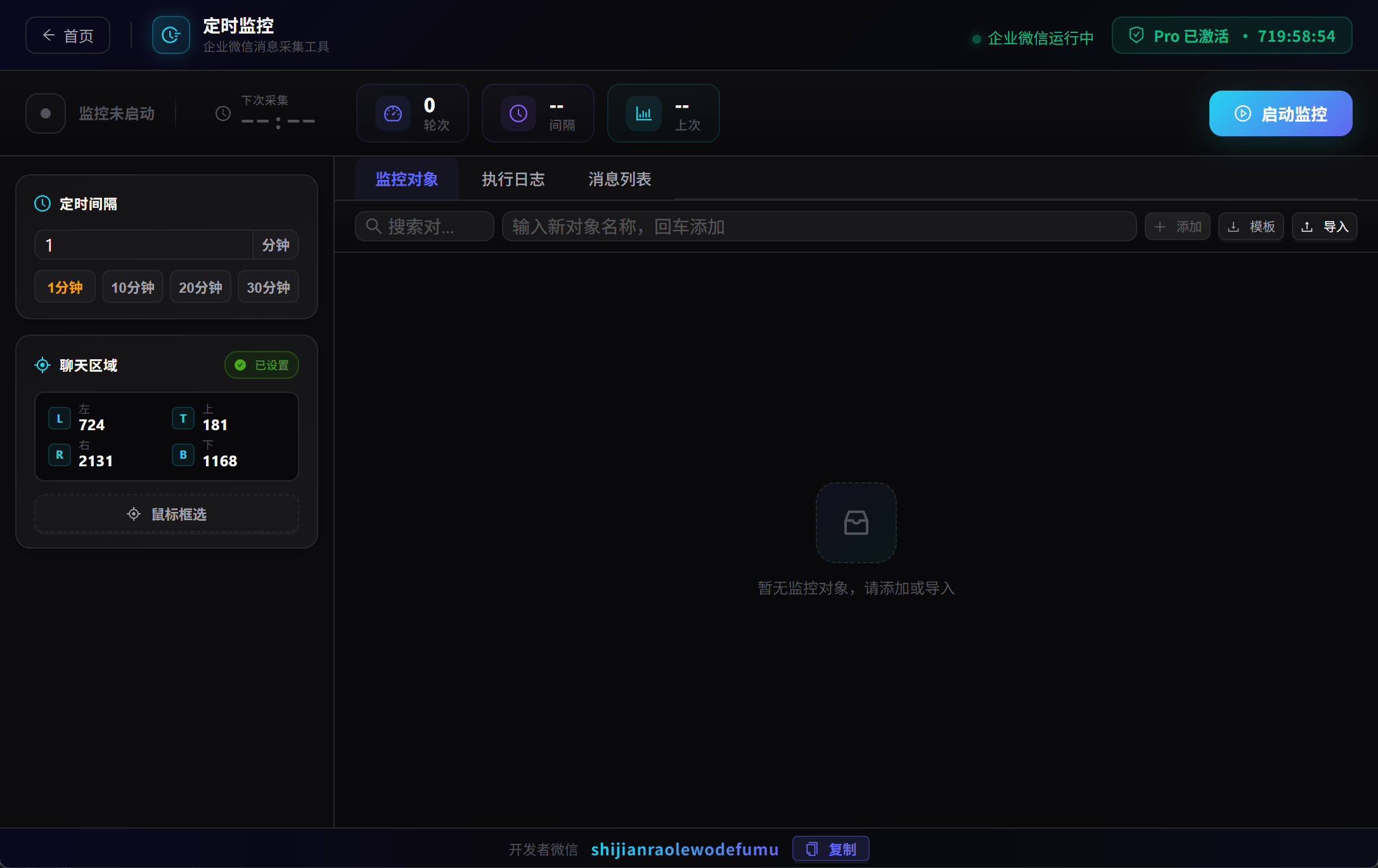
定时监控:设好采集间隔,程序在后台循环运行,每次只写入上次采集以来的新消息,自动去重,无需人工干预。
两个模式配合使用:先用历史采集打底,再开定时监控持续追踪,数据库里就有了完整、不间断、无重复的全量记录。
已知限制
- 采集期间企业微信界面必须保持可见(不能最小化),因为程序需要控制界面
- 目前只支持文字消息,图片、文件、语音暂不在范围内
- 数据完全本地存储,不上传任何服务器
开源地址
GitHub 地址:https://github.com/a605204746/rpa_wxcom_chat_public,欢迎 Star 或提 Issue。
有类似需求(企业微信消息归档、客户群监控)的朋友可以直接拿去用,也欢迎一起完善。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)