
Java面试八股文自行补充版
第一章-Java基础篇
1、怎样理解OOP面向对象 (面向对象的三大特征)
1.继承:子类复用父类代码,自动拥有父类非私有化属性和方法。
2.封装:把类的属性(成员变量)私有化,隐藏内部细节,只通过公开方法(get/set)操作数据。
3.多态:允许不同子类型对象对同一消息做出不同响应。
例:父类方法动物叫声,子类猫狗重写父类方法。
2、重载与重写区别
1.重载发生在同一个类,重写发生在父类和子类之间。
2.重载的参数(个数/类型/顺序)不同,重写相同。
3.重载的返回值可不同(只有返回值类型不同不算重载),重写相同。
4.重写方法的访问权限不能比父类更低,父public子类不能private.
5.构造方法不能重写。
3、接口与抽象类的区别
1.抽象类要被子类继承(单继承),一个类只能extends一个抽象类,接口要被类实现(多实现),一个类可以implement多个接口。
2.抽象类有构造方法(供子类初始化使用),接口没有构造方法。
3.抽象类除了不能实例化,和普通java类一样。
4.抽象类可以有成员变量,接口只能声明常量。
5.抽象方法用abstract修饰,只有声明,没有方法体,子类继承/实现后必须重写所有抽象方法。
6.抽象类中的抽象方法可用public/private/default修饰,接口中的抽象方法只能用public。
7.抽象类/接口中的静态方法不能重写,只能隐藏看具体使用。
补充使用场景
抽象类:有大量共同行为共同属性,例:动物都有名字都会吃,猫狗继承。
接口:不同类拥有相同能力,例:人和马都能实现会跑的接口。
4、深拷贝与浅拷贝的理解
拷贝指对对象的拷贝,对象包括:
1.基本数据类型(数字,字符串等):数据直接存在变量里
2.引用类型(数组,实例等):变量里只存地址,真实数据存在地址指向的内存里
浅拷贝:只拷贝基本数据类型的值+引用类型的地址,不复制引用指向的真实对象。
深拷贝:既拷贝基本数据类型的值也拷贝引用类型指向的真实对象,生成一个独立的新对象。
浅拷贝改引用类型会互相影响,相当于只复制地址,共用对象;深拷贝完全独立,完整复制对象,新地址。
5、sleep和wait区别
1.sleep方法属于Thread类方法(线程自己的行为),wait方法是object类的方法(对象锁行为)。
2.当线程暂停或等待时,sleep和wait都释放cpu给其他线程,sleep不释放锁资源,wait释放。
3.sleep(1000) 等待超过1s被唤醒,时间到自动唤醒;wait(1000) 等待超过1s被唤醒,wait一直等待需要通过notify或者notifyAll进行唤醒。
4.sleep任何地方都能用,wait必须写在synchronized 代码块里,否则会抛出IllegalMonitorStateException异常。
sleep () = 占着厕所不拉屎,wait () = 主动出来排队等
6、什么是自动拆装箱 int和Integer有什么区别
Java 有两种数据类型:
基本类型:int、float、double、boolean 等,不是对象,不能放进集合,不能调用方法
包装类:Integer、Float、Double、Boolean 等,是对象,可以放进集合,可以调用方法
装箱:基本类型 → 包装类对象 int → Integer
拆箱:包装类对象 → 基本类型 Integer → int
实现原理:javac编译器的语法糖,底层是通过Integer.valueOf()和Integer.intValue()方法实现。
区别:
1.Integer是int的包装类,int则是java的一种基本数据类型
2.Integer变量必须实例化后才能使用,而int变量不需要
3.Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
4.Integer的默认值是null,int的默认值是0
7、==和equals区别
1.==(运算符)
基本类型:比较值是否相等
引用类型:比较地址是否相等(两个对象是否指向同一块内存)
2.equals(object类里的方法)
默认实现:和 == 一样,比地址
重写后(String/Integer):比较内容是否相同
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println(s1 == s2); // false (地址不同)
System.out.println(s1.equals(s2)); // true (内容相同)8.String能被继承吗 为什么用final修饰
1.不能被继承,因为String类有final修饰符,而final修饰的类是不能被继承的。
2.String 类是最常用的类之一,为了安全禁止继承和重写。
9、String buffer和String builder的共同点和区别
1.共同点
都用来拼接字符串 ,都是可变字符数组,不会产生新对象。
2.区别
StringBuffer 线程安全(有 synchronized),效率低。
StringBuilder 非线程安全,效率高。
单线程用 StringBuilder,多线程用 StringBuffer
10、final、finally、finalize 的区别
1.final:修饰用的关键字,修饰类(不能被继承),方法(不能被重写),变量(变成常量)。
2.finally:try/catch 里的代码块,除非jvm(进程,运行Java程序的虚拟机)退出必须执行。
3.finalize:Object 里的方法,垃圾回收前调用,用做对象销毁前的资源释放。
11、Object中有哪些常用方法
1.clone():创建并返回对象的副本(浅拷贝)。
2.equals():判断两个对象是否相等,默认比地址,重写后比内容。
3.finalize():对象被垃圾回收前调用。
4.getClass():返回一个对象的运行时类。
5.hashCode():返回对象的哈希码值。
6.notify():唤醒一个在这个对象上等待的线程。
7.notifyAll():唤醒所有在这个对象上等待的线程。
8.toString():返回对象的字符串表示。
9.wait():导致当前线程等待,会释放锁,直到其他线程调用此对象的notify()/notifyAll()方法。
wait(long timeout) 线程等待,时间到自动醒,或被唤醒。
12、说一下集合体系
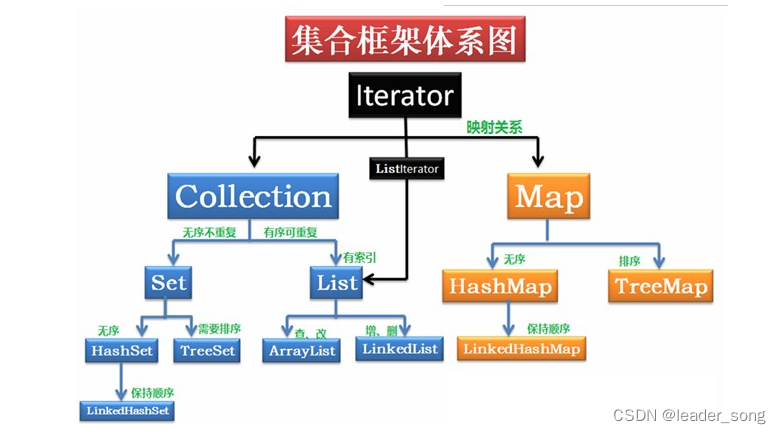
Interator:迭代器
Collection 接口:存储单个元素(单列集合)
List 接口(有序、可重复、有索引)
ArrayList :基于动态数组实现,查询 / 修改快,增删慢
LinkedList:基于双向链表实现,增删快,查询慢
Set 接口(无序、不重复)
HashSet:基于哈希表实现,无序、不重复,查询快
LinkedHashSet:继承 HashSet,额外维护插入顺序
TreeSet:基于红黑树实现,自动排序
Map 接口:存储键值对(双列集合)
HashMap:基于哈希表实现,无序,查询快
LinkedHashMap:继承 HashMap,额外维护插入顺序
TreeMap:基于红黑树实现,按 Key 自动排序
13、ArrarList和LinkedList区别
1.ArrayList 底层是动态数组,LinkedList 底层是双向链表。
2.查询:ArrayList 快,LinkedList 慢,因为ArrayList 直接下标访问,LinkedList要移动指针遍历。
3.增删:LinkedList 快,ArrayList 慢,因为ArrayList要移动数据,LinkedList只改前后指针。
4.单条增删:ArrayList 可能更快; 批量 / 频繁增删:LinkedList 大大快于 ArrayList。
5.使用场景:ArrayList(用于大量查询,读取遍历,如展示商品列表),LinkedList(用于大量频繁增删,如消息队列)
14、HashMap底层是 数组+链表+红黑树,为什么要用这几类结构
1.数组:用来快速查找,保证查询效率。根据key 算 hashCode → 转成数组下标。
2.链表:用来解决哈希冲突,处理位置重复。
3.红黑树:当链表太长时,替代超过8个节点的链表,把查询速度从 O (n) 变成 O (logn)
15、HashMap和HashTable区别
1.HashMap 线程不安全,HashTable 线程安全,方法是Synchronized,多线程下用HashTable。
2.HashMap 允许 null 键值(null键唯一null值不唯一),HashTable 不允许。
3.HashMap只有containsKey和containsValue; HashTable多一个contains方法(等价于containsValue)。
4.HashMap默认容量16,必须是2的整数次幂,扩容2倍; HashTable默认容量11,容量不限制,扩容2倍+1。
16、线程和进程区别
1.进程是资源分配最小单位,线程是cpu调度最小单位。
2.进程有独立内存,线程共享所属进程内存。
3.创建销毁进程开销大,线程开销小。
4.进程间相互独立,一个进程崩溃不影响其他;同进程线程会互相影响。
17、线程的创建方式
1.继承Thread 类(重写run 方法)
2.实现Runnable 接口
3.callable+FutureTask 有返回值,可抛异常
4.线程池(复用线程,频繁创建/销毁线程时使用)
18、线程的状态转换有什么
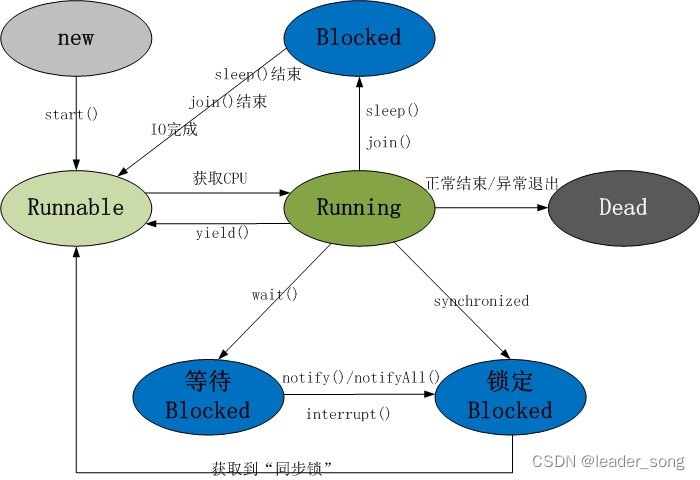
1.New新建状态,线程对象被创建后进入,new Thread()。
2.Runnable就绪状态,thread.start(),随时可被cpu调度执行。
3.Running运行状态,线程获取cpu权限进行执行。
4.Blocked阻塞状态
4.1 等待阻塞:wait()
4.2 同步阻塞:抢同步锁(synchronized)失败
4.3 其他阻塞:sleep(),join()
sleep():让当前线程主动休眠指定时长,时间到自动恢复运行。
join():让当前线程等待目标线程执行完毕再继续执行。
5.Dead死亡状态
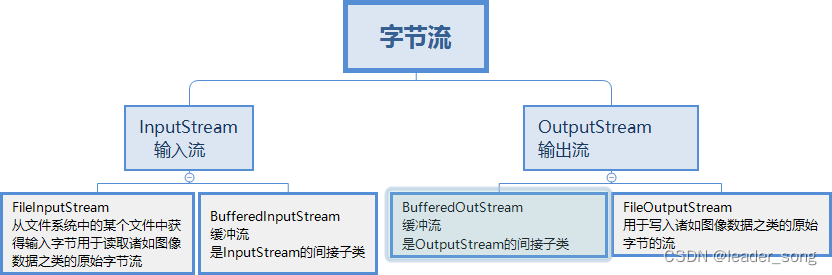
19、java有几种类型流

20、写出几个常见的RuntimeException
1.NullPointerException 空指针异常
2.ClassNotFoundException 指定类找不到
3.NumberFormatException 字符串转换为数字异常
4.indexOutOfBoundsException 数组角标越界异常
5.illegalArgumentException 方法传递参数错误
6.ClassCastException 数据类型转换异常
21、对反射的理解
1.反射是java语言的一大特性,允许程序在运行阶段获取类的全部结构,并动态创建对象,调用方法,操作属性。
2.反射机制借助四个类:class(类对象)、constructor(构造器)、Field(类属性)、Method(类方法)
3.获取class对象是反射的入口
4.sping:Ioc容器通过反射创建对象,依赖注入
Mybaties:反射调用Mapper接口方法,封装数据库结果集
22、什么是Java序列化,如何实现
1.java序列化是将内存对象转为字节序列,用于持久化和网络运输,反序列化则还原对象。
2.实现:实现Serializable接口(通过FileOutputStream)
23、HTTP常见状态码
1.200 客户端请求成功
2.301 永久重定向,资源地址永久变了
3.302 临时重定向,资源暂时改变
4.400 请求格式问题
5.401 未授权,token无效
6.403 收到请求拒绝服务(权限不足)
7.404 请求资源不存在
8.500 服务器内部错误(代码抛异常)
9.503 服务器暂无法处理请求(过载)
24、get和post的区别
1.参数位置:get参数在url,post在请求体(body)
2.安全性:get明文可见,post更安全
3.数据长度:get受url长度限制,post无限制
4.幂等性:get幂等(多次请求结果一样),post非幂等(多次请求可能产生不同结果,如重复提交订单)
5.缓存:get可缓存,post不缓存
25、HashMap是否能用对象当key,原因是什么
1.HashMap能用对象当key,但必须重写equals()和hashcode()的方法。
2.原因:HashMap根据hashcode()定位,根据equals()判断是否相等。如果不重写,会导致内容相同的对象被视为不同key。
3.使用场景:Mybaties,Spring 大量使用自定义对象作为Map的key。
26、说一下Java异常体系
1.Java异常的顶级父类是Throwable。
2.Throwable分为Error和Exception。
3.Error是jvm级错误,程序无法处理。
4.Exception分为运行时异常(RuntimeException,例如NullPointerException)和编译时异常(例如SQLException)。
5.运行时异常是逻辑错误,不强制捕获;编译时异常编译器强制捕获处理。
27、try、catch、finally的执行顺序
1.无异常:try → finally。
2.有异常被捕获:try(中断) → catch → finally。
3.有 return:先执行 finally,再执行 return。
4.仅 System.exit(0) 会让 finally 不执行。
5.finally 常用于释放资源。
第二章-Java高级篇
1、什么是线程池
线程池就是一个 “线程管理器”,事先创建好多条线程,反复利用,避免频繁创建销毁线程,提高性能。
线程池的核心类是ThreadPoolExecutor。
2、为什么要使用线程池
1.降低资源消耗,频繁创建销毁线程开销大。
2.提高响应速度,任务到达时不需要等线程创建可立即执行。
3.线程池复用线程,控制最大并发数,稳定高效。
3、常用的线程池有哪些
1.newCachedThreadPool 缓存线程池
- 特点:可扩容,60 秒回收空闲线程
- 适用:大量短时间任务
- 风险:无限创建线程,可能 OOM
2.newFixedThreadPool 固定大小线程池
- 特点:线程数量固定
- 适用:稳定、长期的任务
- 风险:队列无限,可能 OOM(内存溢出)
3.newSingleThreadExecutor 单线程池
- 特点:只有 1 个线程,任务串行执行
- 适用:需要顺序执行的任务
4.newScheduledThreadPool 定时线程池
- 特点:定时、周期性执行
- 适用:定时任务、心跳、轮询
4、ThreadPoolExecutor对象有哪些参数
new ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 空闲线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
);5、怎么设定核心线程数和最大线程数
- 需要分析线程池执行的任务的特性: CPU 密集型还是 IO 密集型
- CPU 密集型(计算多:加密、计算、解析):核心线程数 = CPU 核心数 最大线程数 = CPU 核心数+1
- IO 密集型(网络请求、数据库、文件、接口调用):核心线程数 = CPU 核心数 * 2 最大线程数 = CPU 核心数 * 2 ~ 5
6、线程池拒绝策略是什么,有哪些
线程池拒绝策略是当核心线程,线程队列,最大线程都满了时,对新任务的处理方式。
1.AbortPolicy:直接抛出异常,默认策略。
2.CallerRunsPolicy:由提交任务的线程自己执行。
3.DiscardPolicy:直接丢弃任务,不报错。
4.DiscardOldestPolicy:丢弃队列中最早的任务。
7、ConcurrentHashMap是什么, 为什么性能比HashTable高
1.ConcurrentHashMap是线程安全的Map容器。
2.HashTable采用synchronized进行线程安全控制, 锁整张表,并发能力差,ConcurrentHashMap用分段锁 / CAS + 锁头节点,锁粒度极小。
第三章-java框架篇
1、SpringMVC的工作流程
1.用户发送请求至DispatcherServlet(前端控制器,总控)。
2.DispatcherServlet(前端控制器)调用HandlerMapping(处理器映射器),根据url匹配Controller,返回处理器+拦截器。
3.DispatcherServlet(前端控制器)调用HandlerAdapter(处理器适配器),适配并执行目标Controller。
4.Controller处理完返回ModelAndView。
5.Adapter把结果返回DispatcherServlet。
6.交给ViewResolver(视图解析器)解析视图,返回view对象。
7.DispatcherServlet用Model数据渲染View,最终返回响应给浏览器。
2、Spring常用注解
1.@Component 基本注解,标识一个受Spring管理的组件。
2.@Controller标注控制器,SpringMVC 接收请求的控制层组件。
3.@Service:业务层注解。
4.@Autowired:自动依赖注入,按类型装配 bean。
5.@Repository:持久层(DAO)注解。
6.@RequestMapping() 完成请求映射。
3、谈谈对Spring的理解
1.Spring是一个开源的轻量级Java开发框架,通过控制反转(IOC)创建对象,自动注入(DL)实现解耦,自动切面编程(AOP)实现通用功能统一处理。
2.控制反转(IOC):传统开发模式需要自己new对象,Spring容器使用工厂模式帮我们创建对象。
3.依赖注入(DL):通过 @Autowired 自动注入依赖的组件,自动给对象赋值。
4.面向切面编程(AOP):把日志,事务,权限等通用功能抽成切面,不修改业务代码就能统一处理。AOP 底层是动态代理,如果是接口采用 JDK 动态代理,如果是类采用CGLIB 方式实现动态代理。
4、Spring事务管理
1.声明式事务
基于 TransactionInterceptor 的声明式事务管理: transactionManager,指定事务治理器;transactionAttributes:配置方法与事务规则,键为方法名(支持通配符),值为对应事务属性。
基于 @Transactional 的声明式事务管理:注解可标注在类、接口、方法上,底层 AOP 代理自动管控事务。
2.编程式事务
在业务代码里手动调用开启、提交、回滚事务 API。
5、简单描述一下Mybaties框架
MyBatis 是一个持久层框架,它封装了 JDBC 繁琐操作,并能自动将数据库查询结果映射成 Java 对象。
6、MyBatis中 #{}和${}的区别是什么
1.#{} 是预编译,会自动把参数变成 ? 占位符,防止 SQL 注入,用于传字段值(where 条件、insert 值等)。
2.${}是 字符串拼接,不防 SQL 注入,会直接把参数拼进 SQL,用于传SQL 结构(表名、列名、order by 字段)。
7、MyBatis如何获取自动生成的(主)键值
在 insert 标签中配置 useGeneratedKeys="true" 和 keyProperty="实体主键字段", 插入数据后,主键值会自动回填到传入的实体对象中。
<insert
id="addUser"
parameterType="User"
useGeneratedKeys="true" <!-- 开启获取自增主键 -->
keyProperty="id" <!-- 主键值赋给实体类的 id 字段 -->
>
insert into user(name,age) values(#{name},#{age})
</insert>8、简述Mybatis的动态SQL,列出常用的6个标签及作用
动态SQL:根据传入的参数条件,自动拼接不同的SQL语句。
常用标签及作用:
1.<if>:条件判断。
2.<where>:处理查询条件,去除多余 AND/OR。
3.<choose>:多选一。
4.<set>:更新语句,去除多余逗号。
5.<foreach>:遍历集合,用于 IN、批量插入。
6.<trim>:自定义拼接规则,可以在SQL语句前后进行添加指定字符或者去掉指定字符。
9、谈谈怎么理解SpringBoot框架
SpringBoot 是基于 Spring 的快速开发框架,简化 SSM 繁杂配置,约定优于配置。SpringBoot的三大核心特点:
1.自动配置
根据项目引入的依赖,自动装配 Bean,省去 XML、繁琐注解配置。引入spring-boot-starter-web自动配 DispatcherServlet、Tomcat、SpringMVC。
2.起步依赖 starter
封装依赖版本,按需引入场景包,不用手动管理 jar 版本冲突。如 starter-web、starter-mybatis。
3.内置 Web 容器
内嵌 Tomcat/Jetty,项目打成 jar 包,java -jar直接运行,无需外置 Tomcat 容器部署。
10、Spring Boot 的核心注解
@SpringBootApplication是启动类上唯一的主注解,包含:
1.@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
2.@EnableAutoConfiguration:自动配置
3.@ComponentScan:包扫描
11、Spring Boot自动配置原理是什么
SpringBoot 通过 @EnableAutoConfiguration 自动扫描、加载、配置第三方组件,根据依赖自动创建 Bean。
12、SpringBoot配置文件有哪些 怎么实现多环境配置
1.SpringBoot 配置文件有 application.properties 和 application.yml 两种,统一配置端口、数据库、日志、MyBatis 等。
2.项目有不同运行环境:开发环境(dev),测试环境 (test),生产环境( prod)。多环境配置通过创建 application - 环境名.yml 文件实现, 在主配置中使用 spring.profiles.active=环境名 来切换不同环境配置。
第四章-MySQL
1、MySQL事务
1.事务的基本要素(ACID)
原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做。事务执行过程中出错,会回滚到事务开始前的状态。
一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
2、悲观锁和乐观锁是什么,怎么实现
select...for update是MySQL提供的实现悲观锁的方式。
例如:select price from item where id=100 for update
此时在items表中,id为100的那条数据就被我们锁定了,其它的要执行select price from items where id=100 for update的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。MySQL有个问题是select...for update语句执行中所有扫描过的行都会被锁上,因此在MySQL中用悲观锁务必须确定走了索引,而不是全表扫描,否则将会将整个数据表锁住。
- 悲观锁:认为一定会发生并发冲突,操作前先加锁,别人必须等我用完才能操作。
- 乐观锁:认为一般不会冲突,操作时才检查,如果被别人改了就重试,不加锁。
利用数据版本号(version)机制是乐观锁最常用的一种实现方式。一般通过为数据库表增加一个数字类型的 “version” 字段,当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值+1。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据,返回更新失败。
3、聚簇索引与非聚簇索引是什么,有什么区别
聚簇索引 = 书的目录 + 正文连在一起,查到索引 → 直接拿到整行数据
非聚簇索引 = 书后面的词汇表,只告诉你页码,只拿到主键 → 再去查主键索引拿数据(这叫回表)
- 叶子节点 = 索引值 + 主键
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)