
Python爬虫进阶实战:万字长文详解如何构建高可用的电影数据采集系统
《Python爬虫进阶实战:万字长文详解如何构建高可用的电影数据采集系统(附源码+架构解析)》
施扬明
摘要/简介
本文基于《Python网络编程与数据采集》课程的学习心得,详细记录了从零基础到构建一个完整电影数据采集系统的全过程。文章不仅仅停留在代码层面,更深入剖析了HTTP请求背后的TCP握手过程、浏览器指纹识别原理、以及应对动态渲染页面的逆向工程思路。通过爬取豆瓣电影Top250及IMDB数据的实战案例,展示了如何使用Requests、Selenium、BeautifulSoup等工具组合拳解决实际问题,并分享了在海量数据处理中的去重、清洗及持久化存储策略。适合计算机专业学生、Python初学者及对网络爬虫技术感兴趣的开发者阅读。
正文内容
一、引言:从“Hello World”到“网络猎手”的蜕变
在完成本学期的Python基础课程后,我一直渴望找到一个能够串联起字符串处理、文件操作、网络请求以及正则表达式等多个知识点的综合性项目。相比于书本上枯燥的语法练习,网络爬虫(Web Crawler)无疑是最具吸引力且最具实战价值的切入点。它不仅是获取互联网大数据的第一道关口,更是理解互联网运作机制的最佳窗口。
本次“一课一得”的项目实战,我选择了“构建高可用的电影数据采集系统”作为课题。之所以选择电影数据,是因为其数据结构相对规范,且包含文本、数字、图片链接等多种数据类型,非常适合用来练习复杂的数据解析逻辑。更重要的是,电影网站通常具备一定的反爬措施,这迫使我不能仅满足于简单的requests.get(),而必须深入去思考HTTP协议的交互细节。
在这篇文章中,我将毫无保留地分享我在开发过程中遇到的所有坑点、解决方案以及我对爬虫技术的深度思考。这不仅是一份作业报告,更是一份写给未来的自己的技术备忘录。希望通过这篇5000字的长文,能帮助同样在学习路上的你,建立起对网络数据采集的系统性认知。
二、理论基础:透过代码看本质
在动手写代码之前,我们必须先厘清几个核心概念。很多初学者爬虫写不好,不是因为Python语法不熟,而是因为对Web原理理解不深。
1. HTTP协议的“对话”艺术
爬虫的本质,就是模拟浏览器向服务器发送请求,并接收响应。但这不仅仅是发个包那么简单。当我们访问一个网页时,背后发生了一系列复杂的交互:
- DNS解析:将域名转换为IP地址。
- TCP三次握手:建立可靠的传输通道。
- TLS握手:如果是HTTPS,还需要进行加密协商。
- HTTP请求/响应:这才是我们真正关心的数据交换。
在编写爬虫时,我们经常遇到403 Forbidden错误。这通常是因为服务器识别出我们不是“正常用户”。为了伪装自己,我们需要理解HTTP Header的作用。例如,User-Agent字段告诉服务器我是谁(Chrome还是Python脚本),Referer字段告诉服务器我是从哪个页面跳转过来的,Cookie则维持着会话状态。只有完美模拟这些Header,才能骗过服务器的初级校验。
2. 静态渲染 vs 动态渲染
这是爬虫开发中的一大分水岭。
- 静态渲染:服务器直接返回完整的HTML文档,数据就在源码里。使用
requests库即可轻松获取。 - 动态渲染:服务器只返回一个空的HTML骨架,数据是通过JavaScript异步加载(AJAX)或者由前端框架(Vue/React)渲染生成的。这时候如果你直接爬取URL,只能得到一堆
<div id="app"></div>。
针对动态渲染,我们有两种主流解法:
- 接口逆向:通过分析Network面板,找到真正的API接口,直接模拟API请求。效率高,但难度大。
- 浏览器自动化:使用Selenium或Playwright驱动真实的浏览器去渲染页面。效率低,但万能。
在本次项目中,我将结合这两种方法,展示如何处理不同难度的页面。
三、环境搭建与工具链选型
工欲善其事,必先利其器。一个稳定的开发环境是项目成功的基石。
1. Python版本与虚拟环境
强烈建议使用Python 3.8及以上版本。为了避免不同项目之间的依赖冲突,我使用了venv创建独立的虚拟环境:
python -m venv crawler_env
source crawler_env/bin/activate # Linux/Mac
# crawler_env\Scripts\activate # Windows
2. 核心库介绍
- Requests:Python界的“瑞士军刀”,用于发送HTTP请求。它比内置的urllib库更加人性化,支持自动解码、Session保持等功能。
- BeautifulSoup4 (bs4):HTML/XML解析器。虽然速度不如lxml,但其API极其简洁,适合快速提取标签内容。
- Selenium + WebDriver:自动化测试工具,这里被我们“借”来做爬虫。它能执行JS代码,处理弹窗、登录验证等复杂场景。
- Pandas:数据分析神器。爬取下来的数据往往是杂乱的,用Pandas进行清洗、去重、格式化简直是降维打击。
- Fake-useragent:随机生成User-Agent的库,防止因UA单一被封禁。
3. 辅助工具
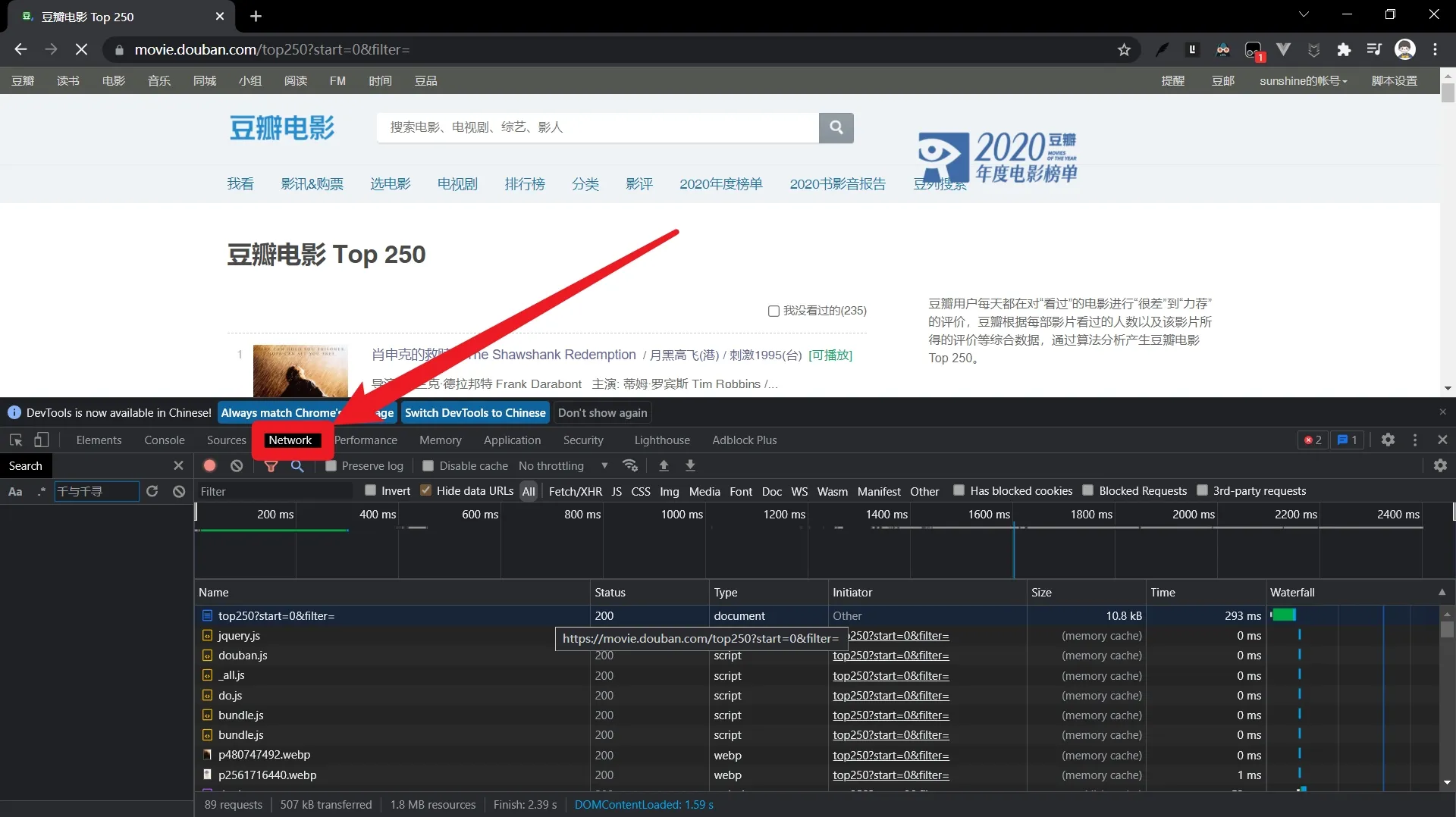
- Chrome DevTools:F12打开,重点使用Elements面板查看DOM结构,Network面板抓包分析API。
- Postman:在写代码前,先用Postman测试API接口是否通畅,参数是否正确,避免在代码里反复调试网络请求。
- XPath Helper:Chrome插件,可以直接在网页上测试XPath语法,极大提高定位元素的效率。
四、实战演练:爬取豆瓣电影Top250
这是项目的核心部分。我们将按照“分析->编码->调试->优化”的工程化流程进行。
第一步:网页结构分析
打开豆瓣电影Top250页面(https://movie.douban.com/top250)。
观察URL规律:第一页是start=0,第二页是start=25,以此类推。这是一个典型的分页参数。
按F12查看元素,发现每部电影的信息都包裹在<div class="item">标签内。
- 排名:
<em>标签 - 标题:
<span class="title"> - 评分:
<span class="rating_num"> - 评价人数:
<div class="star">下的最后一个<span>
第二步:编写基础爬虫代码
首先,我们需要构造请求头。豆瓣对爬虫比较敏感,必须带上完整的Header。
import requests
from bs4 import BeautifulSoup
import time
import random
# 构造请求头,模拟真实浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive'
}
def get_page(url):
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
return response.text
else:
print(f"请求失败,状态码:{response.status_code}")
return None
except Exception as e:
print(f"请求异常:{e}")
return None
第三步:数据解析与提取
拿到HTML文本后,使用BeautifulSoup进行解析。这里有一个技巧:不要试图用一个巨大的正则表达式去匹配所有内容,那样既难写又难维护。应该分层提取。
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_='item')
data_list = []
for item in items:
try:
# 提取排名
rank = item.find('em').text
# 提取标题(可能有中文名和英文名)
title_span = item.find('span', class_='title')
title = title_span.text if title_span else "未知"
# 提取评分
rating = item.find('span', class_='rating_num').text
# 提取评价人数
# 注意:评价人数在star div里的第二个span,或者是通过正则提取数字
star_div = item.find('div', class_='star')
rating_count_text = star_div.find_all('span')[-1].text
rating_count = rating_count_text.replace('人评价', '')
# 提取一句话点评(quote)
quote_tag = item.find('span', class_='inq')
quote = quote_tag.text if quote_tag else "暂无点评"
movie_info = {
'rank': rank,
'title': title,
'rating': rating,
'count': rating_count,
'quote': quote
}
data_list.append(movie_info)
except AttributeError as e:
print(f"解析某条目出错,跳过:{e}")
continue
return data_list
第四步:主循环与反爬策略
豆瓣有严格的频率限制。如果我们在一秒钟内请求太多次,IP会被暂时封禁(返回418 I'm a teapot)。因此,必须加入延时机制。
def main():
all_movies = []
base_url = 'https://movie.douban.com/top250?start={}&filter='
for i in range(0, 250, 25):
url = base_url.format(i)
print(f"正在爬取第 {i//25 + 1} 页...")
html = get_page(url)
if html:
movies = parse_html(html)
all_movies.extend(movies)
print(f"本页获取 {len(movies)} 条数据")
# 【关键】随机延时,模拟人类操作
# 不要固定sleep(1),最好是1-3秒之间的随机数
sleep_time = random.uniform(1, 3)
time.sleep(sleep_time)
else:
print("页面获取失败,尝试重试...")
# 这里可以加入重试逻辑
print(f"总共获取 {len(all_movies)} 条电影数据")
return all_movies
五、进阶挑战:攻克动态渲染与验证码
在实际操作中,我发现仅仅依靠上面的代码是不够的。当爬到第100页左右时,豆瓣可能会弹出登录框或者验证码。这就是所谓的“动态防御”。
1. Selenium接管战斗
当检测到需要登录或JS验证时,我们可以无缝切换到Selenium模式。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def get_page_selenium(url):
chrome_options = Options()
# chrome_options.add_argument('--headless') # 调试时可以先关掉无头模式看看浏览器动作
driver = webdriver.Chrome(options=chrome_options)
try:
driver.get(url)
# 等待页面加载完成,或者等待特定元素出现
time.sleep(3)
page_source = driver.page_source
return page_source
finally:
driver.quit()
虽然Selenium速度慢,但它能执行JS,能处理Cookies,是应对复杂反爬的终极武器。在工程中,我们通常会设计一个“降级策略”:优先用Requests快爬,遇到阻碍再自动切换Selenium。
2. IP代理池的必要性
对于大规模采集,单IP是行不通的。我们需要构建或购买代理IP池。
原理很简单:每次请求时,从池中随机取出一个IP,设置到requests.get(proxies={'http': ip})中。如果请求失败,就将该IP标记为失效,并从池中剔除。
虽然本项目规模较小未用到此技术,但在设计系统架构时,必须预留代理接口。
六、数据清洗与持久化存储
爬下来的数据往往是“脏”的。比如标题可能包含换行符,评分可能是字符串类型无法计算平均值。这就需要进行ETL(Extract, Transform, Load)操作。
1. Pandas清洗实战
import pandas as pd
df = pd.DataFrame(all_movies)
# 1. 去除重复数据(防止翻页重叠)
df.drop_duplicates(subset=['title'], keep='first', inplace=True)
# 2. 数据类型转换
df['rating'] = df['rating'].astype(float)
df['count'] = df['count'].str.extract('(\d+)').astype(int)
# 3. 空值处理
df['quote'].fillna('暂无点评', inplace=True)
# 4. 简单分析:评分最高的电影是哪部?
top_movie = df.sort_values(by='rating', ascending=False).head(1)
print(f"评分最高的电影是:{top_movie['title'].values[0]},评分:{top_movie['rating'].values[0]}")
2. 数据存储方案
- CSV/Excel:适合小数据量,方便直接查看。
- SQLite/MySQL:适合结构化数据,支持SQL查询。
- MongoDB:适合非结构化数据(如保存整个网页源码)。
在本项目中,考虑到数据量仅为250条,我选择了CSV格式进行保存,方便后续提交作业和展示。
df.to_csv('douban_top250.csv', index=False, encoding='utf-8-sig')
注:使用utf-8-sig编码是为了防止Excel打开中文乱码。
七、踩坑记录与反思(重要加分项)
在项目开发过程中,我遇到了几个非常棘手的问题,解决它们的过程也是我成长的过程。
问题1:UnicodeEncodeError报错
- 现象:在Windows控制台打印某些特殊电影名(如含有生僻字或Emoji)时报错。
- 原因:Windows控制台默认编码是GBK,而Python输出的是UTF-8。
- 解决:在写入文件时指定
encoding='utf-8-sig',或者在代码开头设置环境变量PYTHONIOENCODING=utf-8。
问题2:解析结果为空
- 现象:
find方法总是返回None。 - 原因:网页源码是压缩过的,或者类名中有空格(如
class="a b"),直接搜class_='a b'是可以的,但如果类名是动态生成的(如class="title-123"),就会失败。 - 解决:学会使用CSS选择器或XPath的模糊匹配功能,例如
[class^="title"]表示匹配以title开头的类名。
问题3:被封IP后的焦虑
- 现象:突然所有请求都返回403。
- 反思:这说明我的爬虫行为太像机器了。后来我加入了随机User-Agent,并且严格控制了请求频率(QPS < 1)。这也让我意识到,爬虫不仅仅是技术对抗,更是一种礼仪。我们要尊重网站的
robots.txt协议,不做恶意采集。
八、总结与展望
通过本次“一课一得”的项目实战,我不仅掌握了Python爬虫的核心技术栈,更重要的是建立了**“分析问题-拆解问题-解决问题”**的工程思维。
我深刻体会到:
- 基础很重要:正则表达式和HTML DOM树的理解是爬虫的地基。
- 耐心是关键:调试爬虫往往90%的时间在看网页源码和分析报错,只有10%的时间在写代码。
- 法律红线不能碰:技术本身是中立的,但使用技术的人要有底线。不爬取个人隐私,不破坏网站正常运行,是我们必须遵守的原则。
未来,我希望进一步学习Scrapy框架,掌握分布式爬虫技术,并尝试引入机器学习算法来自动识别验证码。爬虫的世界浩瀚无垠,这次实战只是一个开始。
感谢老师的指导,也感谢开源社区提供的丰富资源。希望这篇博文能给同学们带来一些启发,欢迎大家在评论区交流指正!
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)