
【python】从零实现 AI 桌面宠物:会学习你的习惯的桌面宠物游戏 之 大更新篇
接着前一篇文章从零实现一个AI桌面宠物初探这篇文章的续作,这个版本做了大更新,有兴趣的小伙伴可以看一看,源码和游戏链接再文章末尾,自行下载。
从零实现一个AI桌面宠物:纯Python、离线运行、会学习你的习惯
你是否想过拥有一只生活在电脑桌面上的虚拟宠物?它会主动找你玩,会饿会困会开心,能记住你喂过它什么,甚至拥有独立的"性格"——而且这一切完全离线运行,不需要联网,不调用任何云API,全部用纯Python实现。
一、项目背景
市面上的桌面宠物要么是静态壁纸,要么需要联网调用AI接口。我想做一个不一样的:
- 完全离线 —— 0 API 调用,所有AI逻辑在本地运行
- 有"大脑" —— 能自主学习主人的互动习惯,拥有独立的性格和记忆
- 轻量 —— 一个普通笔记本就能跑,RNN模型仅28K参数
- 零图片资源 —— 宠物完全用代码绘制,不需要任何图片素材
最终成品是一个200×280像素的透明窗口,一只矢量风格的卡通猫会"住"在你的桌面上。
二、最终效果



| 功能 | 操作方式 |
|---|---|
| 左键单击宠物 | 随机互动,宠物切换对应表情 |
| 左键拖拽 | 移动宠物位置 |
| 右键单击宠物 | 弹出功能菜单,宠物即时反馈表情 |
| 系统托盘图标 | 置顶切换 / 菜单操作 |
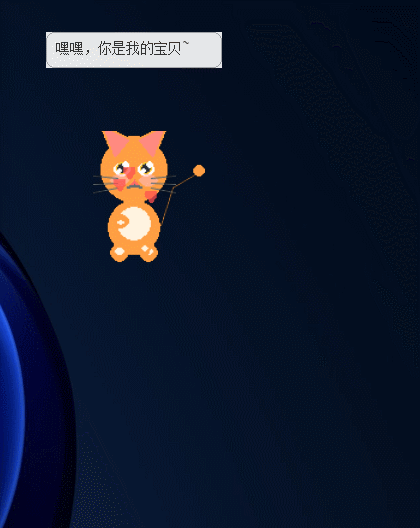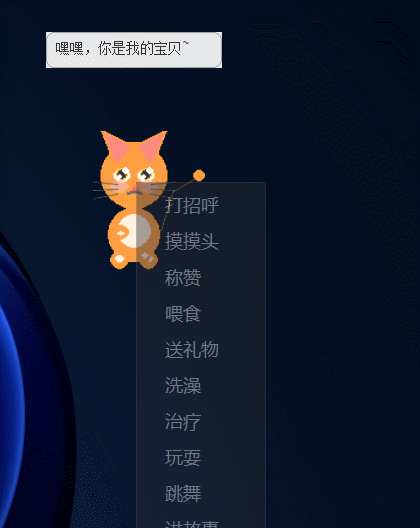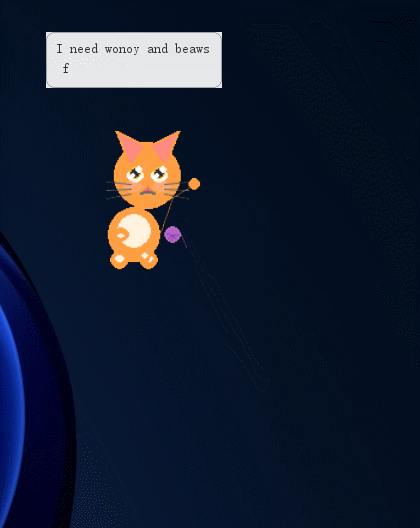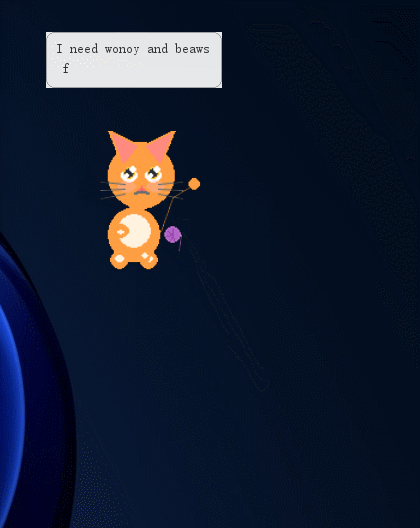
右键菜单功能(每个操作宠物都会呈现不同的动画表情和叠加特效):
- 打招呼 — 开心/好奇/活泼地回应
- 摸摸头 — 开心眯眼/好奇张望/犯困,爱心特效
- 称赞 — 兴奋/开心,星星特效
- 喂食 — 开心/好奇地闻食物,食物特效
- 送礼物 — 兴奋/开心,消耗金币,礼物盒特效
- 洗澡 — 开心/活泼,泡泡特效
- 治疗 — 恢复健康,安逸舒适,闪光特效
- 玩耍 — 活泼蹦跳/开心追逐,毛线球特效
- 跳舞 — 跳舞动画/兴奋,星星特效
- 讲故事 — 好奇/开心/犯困,书本特效
- 教本领 — 好奇/活泼,闪光特效
- 生气 — 伤心/委屈,愤怒特效
- 改名字 — 自定义宠物名称
- 查看状态 — 弹出窗口显示四维属性进度条
宠物会随时间自动衰减属性,并自主学习在什么时候应该做什么。每个互动都会触发即时视觉反馈,让你立刻知道它的"心情"。
三、技术架构
整体设计
用户互动 → 性格系统 → 行为引擎 → 动作输出
↘ 记忆系统 ↗
对话 ← 混合引擎(模板 + Char-RNN)
技术选型
| 组件 | 技术 | 选型原因 |
|---|---|---|
| 桌面窗口 | PyQt5 | 原生透明窗口、系统托盘、事件处理 |
| 游戏渲染 | pygame-ce | 高效的2D图形API,支持SRCALPHA合成 |
| 神经网络 | numpy | 纯手工实现Char-RNN,零ML框架依赖 |
| 行为决策 | Q-Learning | 轻量级强化学习,可解释性强 |
四、核心实现详解
4.1 矢量风格宠物绘制(非像素)
这是项目的最大亮点之一。宠物不是像素画,而是用代码绘制的矢量风格卡通猫。
实现文件:renderer/sprites.py
核心思路:用一个 _draw_cat_base 函数绘制猫的全部身体,通过 modifiers 字典驱动所有动画状态:
def _draw_cat_base(surf, frame, modifiers):
# modifiers 控制所有变形参数:
# bounce_y — 垂直弹跳(开心时)
# head_tilt — 头部倾斜(好奇时)
# tail_up — 尾巴抬起(玩耍时)
# eye_open — 眼睛睁开程度(0~1.4)
# smile — 嘴角弧度(正=笑,负=哭)
# blush — 腮红透明度
# body_color — 身体颜色(生病时变灰)
breathe = math.sin(frame * 0.3) * 1.5 # 呼吸动画
ear_twitch = math.sin(frame * 0.5) * 2 # 耳朵抖动
# 用 pygame 图元组合成一只猫:
# 椭圆 → 身体/腿
# 圆 → 头/尾巴尖
# 多边形 → 耳朵/鼻子
# 弧线 → 眼睛/嘴巴
# 抗锯齿线 → 胡须/尾巴
# 半透明面 → 腮红
11种情绪状态各自定义一组 modifiers 参数:
| 状态 | 关键动画 | 实现方式 |
|---|---|---|
| idle | 呼吸起伏 | sin波驱动body垂直微动 |
| happy | 上下弹跳 | bounce_y = abs(sin(frame*0.5))*6 |
| sad | 垂头丧气 | head_tilt 负值 + 半闭眼 |
| playful | 活泼好动 | 高弹跳 + 尾巴竖起 + 踢腿 |
| hungry | 左右张望 | head_tilt 正弦摆动 + 张嘴 |
| sleepy | 打瞌睡 | eye_open=0.1 + 缓慢点头 |
| sick | 生病萎靡 | body_color换为灰白色 |
| curious | 好奇歪头 | head_tilt 摆动 + 睁大眼 |
| excited | 兴奋蹦跳 | 高弹跳 + 举双爪 + 快速踢腿 |
| cuddly | 撒娇求抱 | 倾斜歪头 + 伸爪 + 腮红 |
| dance | 左右摇摆 | 交替抬爪 + 左右 sway |
技术要点:腮红效果通过单独创建带逐像素Alpha的Surface实现:
blush_surf = pygame.Surface((12, 8), pygame.SRCALPHA)
pygame.draw.ellipse(blush_surf, (255, 184, 184, 120), (0, 0, 12, 8))
4.2 右键交互菜单
实现文件:desktop/pet_window.py
右键菜单的完整流程:
- PyQt5检测到
Qt.RightButton鼠标事件 - 调用
_show_context_menu(globalPos) - 动态创建一个
QMenu,添加7个功能项 + 1个退出项 - 菜单采用深色主题样式:
- 背景
#2D2D36,选中色#FF9F43(橙色) - 圆角边框,完美融入桌面
- 背景
- 点击菜单项触发对应操作:
greet/feed/pet/play/heal→ 调用brain.interact()rename→ 弹出QInputDialog改名字status→ 弹窗显示四维属性数值
关键代码片段:
def _show_context_menu(self, global_pos):
menu = QMenu(self)
menu.setStyleSheet("""
QMenu {
background-color: #2D2D36;
color: white;
border: 1px solid #555;
border-radius: 6px;
padding: 4px;
}
QMenu::item {
padding: 6px 24px;
border-radius: 4px;
}
QMenu::item:selected {
background-color: #FF9F43;
}
""")
actions = [
("打招呼", "greet"), ("摸摸头", "pet"), ("称赞", "praise"),
("喂食", "feed"), ("送礼物", "gift"), ("洗澡", "bathe"),
("治疗", "heal"), ("玩耍", "play"), ("跳舞", "dance"),
("讲故事", "story"), ("教本领", "teach"),
]
for label, action_type in actions:
action = QAction(label, self)
action.triggered.connect(lambda checked, t=action_type: self.on_menu_action(t))
menu.addAction(action)
menu.addSeparator()
scold_action = QAction("生气", self)
scold_action.triggered.connect(lambda: self.on_menu_action("scold"))
menu.addAction(scold_action)
menu.addSeparator()
shop_action = QAction("🛒商店", self)
shop_action.triggered.connect(self.open_shop)
menu.addAction(shop_action)
rename_action = QAction("改名字", self)
rename_action.triggered.connect(lambda: self.on_menu_action("rename"))
menu.addAction(rename_action)
status_action = QAction("查看状态", self)
status_action.triggered.connect(lambda: self.on_menu_action("status"))
menu.addAction(status_action)
menu.addSeparator()
exit_action = QAction("退出", self)
exit_action.triggered.connect(self.quit_application)
menu.addAction(exit_action)
menu.exec_(global_pos)
4.3 PyGame嵌入Qt窗口
这是一个关键的架构决策。最终方案是PyGame只作渲染引擎,Qt负责窗口管理:
class PetWindow(QWidget):
def _setup_pygame(self):
pygame.font.init()
self.pygame_surf = pygame.Surface((WINDOW_WIDTH, WINDOW_HEIGHT), pygame.SRCALPHA)
def paintEvent(self, event):
painter = QPainter(self)
pixels = pygame.image.tobytes(self.pygame_surf, "RGBA")
image = QImage(pixels, w, h, QImage.Format_RGBA8888)
painter.drawImage(0, 0, image)
def _update(self):
self.brain.tick()
self.renderer.render(self.pygame_surf, self.brain.current_emotion, dialogue)
self.update() # 触发 paintEvent
每次tick:brain更新状态 → renderer绘制到pygame surface → paintEvent将surface转为QImage显示。这样既享受了pygame的绘图API,又获得了Qt的窗口管理能力。
4.4 Q-Learning 行为引擎(详细设计)
宠物拥有一个轻量级的强化学习"大脑",核心是状态离散化 + Q表查询 + 奖励驱动更新。
状态空间设计
5 维连续属性通过 discretize() 映射到 3 级离散值:
def discretize(value: float, levels: int = 3) -> int:
return min(levels - 1, max(0, int(value * levels / 100)))
| 维度 | 范围 | 0(低) | 1(中) | 2(高) |
|---|---|---|---|---|
| 饥饿度 | 0-100 | <33 | 33-66 | >66 |
| 精力值 | 0-100 | <33 | 33-66 | >66 |
| 心情值 | 0-100 | <33 | 33-66 | >66 |
| 健康值 | 0-100 | <33 | 33-66 | >66 |
| 时间段 | 0-23 | 0-7(早) | 8-17(中) | 18-23(晚) |
总状态数:3 × 3 × 3 × 3 × 3 = 243 种
动作空间(7 种)
ACTIONS = ["sleep", "play", "explore", "cuddle", "eat", "wander", "groom"]
Q 表结构
Q 表用字典实现,以状态元组为 key,每个 key 存 7 个动作的 Q 值:
# 状态 (hunger_lv, energy_lv, mood_lv, health_lv, period)
state = (2, 1, 0, 1, 1)
# Q 值示例
q_table[state] = {
"sleep": 0.32,
"play": 0.15,
"explore": 0.28,
"cuddle": 0.41,
"eat": 0.73,
"wander": 0.19,
"groom": 0.22,
}
未访问过的新状态自动初始化为 random.uniform(0, 0.1)。
动作选择策略
def choose_action(self, hunger, energy, mood, health, hour):
state = self._state_key(hunger, energy, mood, health, hour)
q_vals = self._get_q_values(state)
# ε-greedy:20% 随机探索,80% 利用经验
if random.random() < self.exploration_rate:
return random.choice(ACTIONS)
return max(q_vals, key=q_vals.get)
探索率初始 0.2,每次更新乘以 0.9995,最低 0.05。约 3000 次更新后降至 0.1。
奖励函数(完整)
def get_reward(self, action, hunger, energy, mood, health):
reward = 0.0
p = self.personality
if action == "eat":
reward += 1.0 if hunger > 50 else -0.5 # 饿了吃 → 正奖励
if p: reward += p.get("affectionate") * 0.2 # 亲昵的猫更爱被喂
elif action == "play":
reward += 1.0 if energy > 40 else -1.0 # 有精力才玩
reward += 0.5 if mood < 50 else 0.2 # 心情不好更需要玩
if p:
reward += p.get("energetic") * 0.5 # 活泼的猫爱玩
reward += p.get("curious") * 0.3 # 好奇的猫爱玩
elif action == "sleep":
reward += 1.0 if energy < 40 else -0.3 # 累了才睡
if p: reward -= p.get("energetic") * 0.3 # 活泼的猫不爱睡
elif action == "cuddle":
reward += 0.5 if mood < 60 else 0.2 # 心情差时求抱
if p:
reward += p.get("affectionate") * 0.5 # 亲昵的猫爱撒娇
reward += p.get("clingy") * 0.3 # 粘人的猫爱撒娇
elif action == "explore":
reward += 0.5 if energy > 50 else -0.5 # 有精力才探索
if p: reward += p.get("curious") * 0.6 # 好奇心驱动
elif action == "wander":
reward += 0.2 # 保底正奖励
if p:
reward += p.get("curious") * 0.2
reward += p.get("energetic") * 0.1
elif action == "groom":
reward += 0.3 if health < 50 else 0.1 # 不健康时更需要
if p: reward += p.get("stubborn") * -0.1 # 固执的不爱打理
return reward
Q 值更新公式
标准 Q-Learning 更新:
Q(s, a) += α × [r + γ × max Q(s', a') - Q(s, a)]
对应代码:
current_q = q_vals[action]
max_next_q = max(next_q_vals.values())
new_q = current_q + LEARNING_RATE * (reward + DISCOUNT_FACTOR * max_next_q - current_q)
q_vals[action] = new_q
| 参数 | 值 | 说明 |
|---|---|---|
| α(Learning Rate) | 0.1 | 每次更新的步长 |
| γ(Discount Factor) | 0.9 | 对未来奖励的重视程度 |
| ε(Exploration Rate) | 0.2→0.05 | 探索概率(指数衰减) |
自主行为循环
每 15 秒触发一次 _autonomous_action():
- 读取当前四维属性 + 当前小时
choose_action()→ 选择行为- 执行行为 → 改变属性 → 获得 reward
update()→ 更新 Q 表- 探索率衰减:
ε *= 0.9995
最终宠物会自然学会:饿了找吃、累了睡觉、无聊了玩耍——完全通过试错,没有任何硬编码规则。
4.5 纯NumPy实现的Char-RNN(完整细节)
这是项目中"最硬核"的部分。一个字符级别的循环神经网络,完全用NumPy手动实现前向传播、反向传播(BPTT)和采样。
网络架构
输入(字符索引)
↓
Embedding(vocab_size × embed_dim)
↓
单层RNN(embed_dim → hidden_dim)
↓
Linear(hidden_dim → vocab_size)
↓
Softmax → 输出(下一个字符的概率分布)
前向传播
def forward(self, inputs, h_prev=None):
T = len(inputs)
xs = np.zeros((T, self.embed_dim)) # 输入序列
hs = np.zeros((T + 1, self.hidden_dim)) # 隐状态序列
hs[0] = h_prev or np.zeros((1, self.hidden_dim))
for t in range(T):
xs[t] = self.W_embed[inputs[t]] # Embedding 查找
hs[t+1] = np.tanh(xs[t] @ self.W_xh + hs[t] @ self.W_hh + self.b_h) # RNN 单元
ys = hs[1:] @ self.W_hy + self.b_y # 输出层
return xs, hs, ys
损失函数
交叉熵损失(Cross-Entropy Loss):
# Softmax
probs = np.exp(ys - np.max(ys, axis=1, keepdims=True))
probs /= np.sum(probs, axis=1, keepdims=True)
# Cross-Entropy
loss = -np.sum(np.log(probs[np.arange(T), targets] + 1e-8)) / T
反向传播(BPTT)
沿时间反向传播梯度,核心是链式法则沿时间步展开:
for t in reversed(range(T)):
dy = probs[t:t+1].copy()
dy[0, targets[t]] -= 1 # dSoftmax + dCrossEntropy 合并
# 输出层梯度
dW_hy += hs[t+1:t+2].T @ dy
db_y += dy
# RNN 隐层梯度(沿时间反向传播)
dh = dy @ self.W_hy.T + dh_next
dh_raw = (1 - hs[t+1:t+2] ** 2) * dh # dtanh
db_h += dh_raw
dW_hh += hs[t:t+1].T @ dh_raw
dW_xh += xs[t:t+1].T @ dh_raw
dW_embed[inputs[t]] += (dh_raw @ self.W_xh.T).reshape(-1)
dh_next = dh_raw @ self.W_hh.T # 传递到上一个时间步
参数更新(SGD + 梯度裁剪)
for param, grad in [("W_embed", dW_embed), ("W_xh", dW_xh), ("W_hh", dW_hh),
("b_h", db_h), ("W_hy", dW_hy), ("b_y", db_y)]:
np.clip(grad, -5, 5, out=grad) # 梯度裁剪,防止爆炸
setattr(self, param, getattr(self, param) - lr * grad) # SGD 更新
文本生成(Temperature 采样)
def sample(self, seed, length=30, temperature=0.8):
h = np.zeros((1, self.hidden_dim))
# 用 seed 序列预热隐状态
for idx in seed_indices:
emb = self.W_embed[idx].reshape(1, -1)
h = np.tanh(emb @ self.W_xh + h @ self.W_hh + self.b_h)
result = seed
for _ in range(length):
y = (h @ self.W_hy + self.b_y).reshape(-1) / temperature
exp_y = np.exp(y - np.max(y))
probs = exp_y / np.sum(exp_y)
next_idx = np.random.choice(self.vocab_size, p=probs) # 按概率采样
next_char = self.idx_to_char(next_idx)
if next_char == "\n": break
result += next_char
return result
temperature 控制生成随机性:值越低越保守(趋于常见字符),值越高越随机(可能产生新奇的组合)。
模型参数量计算
| 参数 | Shape | 参数量 |
|---|---|---|
| W_embed | 70 × 16 | 1,120 |
| W_xh | 16 × 64 | 1,024 |
| W_hh | 64 × 64 | 4,096 |
| b_h | 1 × 64 | 64 |
| W_hy | 64 × 70 | 4,480 |
| b_y | 1 × 70 | 70 |
| 总计 | 10,854 |
约 10.8K 参数,加上中间缓存约 28K 参数量。
训练流程
# main.py 首次启动调用
def train(model, epochs=200, lr=0.01):
lines = load_corpus("corpus.txt") # 加载语料
batches = prepare_batch(model, lines) # 分词并编码
for epoch in range(epochs):
np.random.shuffle(batches)
decay_lr = lr * (1 - epoch / epochs) # 学习率线性衰减
for batch in batches:
inputs, targets = batch[:-1], batch[1:]
loss = model.train_step(inputs, targets, decay_lr)
# 每 1/3 进度打印一次 loss 和生成样本
if (epoch + 1) % (epochs // 3) == 0:
sample = model.sample("", length=15)
print(f"epoch {epoch+1} loss={avg_loss:.2f} {sample[:20]}")
- 语料格式:每行一个带标签的句子,如
<happy> I am so happy today! - 预处理:添加
<start>/<end>标记,转为索引序列 - 训练 200 epoch,loss 从 ~3.1 降至 ~0.59
- 约 30 秒完成训练(纯 NumPy)
对话时混合策略
80% 概率 → 模板匹配(保证通顺自然,中文预设句子)
20% 概率 → RNN 自由生成(增加惊喜和多样性)
RNN 生成时传入情绪标签作为 seed(如 <happy>),控制输出风格。
4.6 记忆系统与数据持久化
记忆系统设计
记忆采用键值对存储,每条记忆包含三个字段:
{
"last_food": {
"time": 1700000000, # 最后访问的 Unix 时间戳
"value": "鸡肉", # 记忆内容(可选)
"count": 5 # 累计访问次数
},
"last_petted": {
"time": 1700000500,
"value": None, # 无具体内容
"count": 23
}
}
7天半衰期衰减权重:
def _weight(self, timestamp):
days = (time.time() - timestamp) / 86400
return 2.0 ** (-days / 7)
| 天数 | 权重 |
|---|---|
| 0 天 | 1.000 |
| 1 天 | 0.905 |
| 3 天 | 0.741 |
| 7 天 | 0.500 |
| 14 天 | 0.250 |
| 30 天 | 0.051 |
自动清理条件:权重 < 0.05 且 count < 3 → 删除。
数据持久化格式
所有数据存储在 brain_models/data/ 目录,使用 JSON + NPZ 两种格式。
brain_state.json — 宠物状态快照:
{
"hunger": 30.0,
"energy": 65.2,
"mood": 55.0,
"health": 80.0,
"name": "小咪"
}
q_table.json — Q-Learning 状态-动作表:
{
"q_table": {
"2,1,0,1,1": {
"sleep": 0.32,
"play": 0.15,
"explore": 0.28,
"cuddle": 0.41,
"eat": 0.73,
"wander": 0.19,
"groom": 0.22
}
},
"exploration_rate": 0.082
}
状态元组 (2,1,0,1,1) 以逗号分隔字符串 "2,1,0,1,1" 作为 JSON key(JSON 不支持 tuple 作为 key)。
memory.json — 记忆数据:
{
"last_food": {"time": 1700000000, "value": "鸡肉", "count": 5},
"last_petted": {"time": 1700000500, "value": "被抚摸", "count": 23},
"name_changed": {"time": 1699900000, "value": "小咪", "count": 1}
}
personality.json — 性格向量:
{
"dims": {
"affectionate": 0.65,
"energetic": 0.52,
"curious": 0.71,
"stubborn": 0.28,
"clingy": 0.43
},
"daily_deltas": {
"affectionate": 0.04,
"energetic": 0.02,
"curious": 0.01,
"stubborn": 0.0,
"clingy": 0.03
},
"last_date": "2026-06-25"
}
daily_deltas 记录当日累计变化量,用于限制每日总变化不超过 ±0.1。last_date 用于跨日重置累计变化量。
weights.npz — Char-RNN 权重(NumPy 压缩格式):
np.savez_compressed(path,
W_embed=..., # (70, 16)
W_xh=..., # (16, 64)
W_hh=..., # (64, 64)
b_h=..., # (1, 64)
W_hy=..., # (64, 70)
b_y=..., # (1, 70)
)
使用 np.savez_compressed 自动压缩,约 112KB。
保存与加载时机
| 事件 | 保存 | 加载 |
|---|---|---|
| 程序启动 | — | ✅ 加载所有数据 |
| 退出 | ✅ | — |
| 每 tick | 自动实时写内存 | — |
4.7 互动响应情绪系统
宠物在接收到用户操作时,立即切换画面表情,给用户即时的视觉反馈。
实现原理(pet/brain.py),每个操作还附带金币奖励和叠加特效:
def interact(self, action_type: str) -> str:
self.memory.remember(f"last_{action_type}")
self.emotion_timer = FPS * 3 # 情绪保持3秒
self.coins += COIN_REWARDS.get(action_type, 0) # 互动赚金币
if action_type == "pet":
self.mood = min(100, self.mood + PET_PET_MOOD)
self.personality.modify({"affectionate": 0.02, "clingy": 0.01})
self._set_overlay("heart") # 爱心特效
self.current_emotion, self.current_action = self._pick_emotion([
("happy", "happy", 5), # 50% 概率开心
("curious", "curious", 2), # 30% 概率好奇
("sleepy", "sleepy", 1), # 20% 概率犯困
])
return self.dialogue.generate("loving")
每个操作对应多种可能的情绪反馈,使用加权随机选择:
| 操作 | 可能情绪(权重) |
|---|---|
| 摸摸头 | happy(5) / curious(2) / sleepy(1) |
| 喂食 | happy(5) / curious(3) / playful(1) |
| 玩耍 | playful(5) / happy(3) / curious(2) |
| 治疗 | happy(5) / idle(2) / sleepy(1) |
| 打招呼 | happy(5) / curious(3) / playful(2) |
| 洗澡 | happy(5) / playful(3) / curious(1) |
| 送礼物 | excited(5) / happy(3) / playful(1) |
| 称赞 | excited(5) / happy(3) / cuddly(1) |
| 讲故事 | curious(5) / happy(2) / sleepy(2) |
| 教本领 | curious(4) / playful(3) / happy(2) |
| 跳舞 | dance(5) / excited(3) / happy(1) |
| 生气 | sad(5) / sleepy(2) / idle(1) |
情绪切换后持续约3秒(emotion_timer),然后自动恢复为由属性数值决定的基础情绪。这样既保证了操作的即时反馈,又不影响宠物自主行为的连贯性。
tick() 中的关键逻辑:
def tick(self):
# ... 属性衰减 ...
if self.emotion_timer > 0:
self.emotion_timer -= 1 # 持续显示互动情绪
else:
self.current_emotion = self._determine_emotion() # 恢复自动判断
此外,查看状态不再弹出独立窗口,而是显示在宠物的对话气泡中,停留6秒:
elif action_type == "status":
text = "饥饿:30/100 精力:70/100 心情:60/100 健康:80/100"
self._show_dialogue(text, duration=FPS * 6) # 6秒停留
4.8 互动视觉叠加特效
为了让每次互动更有"感觉",我实现了一个特效叠加系统。每个互动操作会触发对应的视觉特效,在宠物身上叠加显示2-3秒。
实现方式是在 renderer/sprites.py 中定义一系列 draw_xxx_overlay(surf, frame, progress) 函数,其中 progress 从 0→1 控制动画进度:
OVERLAY_FUNCTIONS = {
"food": draw_food_overlay, # 小鱼干掉落
"heart": draw_heart_overlay, # 爱心飘散
"gift": draw_gift_overlay, # 礼物盒弹跳
"toy": draw_toy_overlay, # 毛线球滚动
"star": draw_star_overlay, # 星星旋转上升
"bubble": draw_bubble_overlay, # 泡泡飘散
"book": draw_book_overlay, # 书本翻开
"anger": draw_anger_overlay, # 愤怒爆炸
"sparkle": draw_sparkle_overlay,# 菱形闪光
}
特效与宠物的情绪动画同时渲染,在 brain 中通过 _set_overlay() 控制:
def _set_overlay(self, overlay_type: str, duration: int = None):
self.visual_overlay = overlay_type
dur = duration or FPS * 2 # 默认2秒
self.overlay_duration = dur
self.overlay_max_duration = dur
然后在渲染循环中计算 progress = 1.0 - (overlay_duration / overlay_max_duration),传入 overlay 函数实现平滑动画。
五、遇到的坑与解决方案
1. Pygame-ce字体初始化崩溃
问题:Python 3.14 + pygame-ce 2.5.7 下,调用 pygame.font.SysFont() 会触发Windows字体枚举,但是枚举返回的数据类型与Python 3.14不兼容,导致 splitext 报错 TypeError: expected str, not int。
解决:放弃使用 SysFont,改为直接加载Windows字体目录下的具体字体文件:
def _find_chinese_font():
paths = [
"C:\\Windows\\Fonts\\simsun.ttc",
"C:\\Windows\\Fonts\\msyh.ttc",
"C:\\Windows\\Fonts\\simhei.ttf",
]
for p in paths:
if os.path.exists(p):
return pygame.font.Font(p, 14)
return pygame.font.Font(None, 16) # 最后兜底
2. RNN训练速度过慢
问题:原始实现中,get_loss方法先调用forward进行前向传播,然后在反向传播中又重复计算了部分前向值,导致每个训练step做了2次前向传播。
解决:重写train_step方法,将前向传播和反向传播合并为一个函数,复用前向计算的结果,训练速度提升了约10倍(200 epoch从>2分钟缩短至约30秒)。
3. 透明窗口的事件穿透
问题:Qt透明窗口默认会让鼠标事件穿透到下层窗口,但我们需要在宠物身上捕获点击。
解决:不设置 WA_TransparentForMouseEvents,在 mousePressEvent 中通过 _is_on_pet() 判断点击位置是否在宠物的渲染矩形内,仅在矩形内处理事件。
六、如何使用
环境要求
- Python 3.14+
- 依赖:
pygame-ce,PyQt5,numpy
安装运行
pip install pygame-ce PyQt5 numpy
cd ai_pet
python main.py
或双击 run.bat。
首次启动会自动训练Char-RNN(约30秒),之后秒开。所有数据保存在 brain_models/data/ 目录,退出时自动保存。
七、项目结构
ai_pet/
├── main.py # 程序入口
├── config.py # 全局配置参数
│
├── pet/ # AI 大脑模块
│ ├── brain.py # 大脑主控
│ ├── behavior.py # Q-Learning 行为引擎
│ ├── personality.py # 5维性格系统
│ ├── memory.py # 记忆系统
│ └── dialogue.py # 混合对话引擎
│
├── brain_models/ # 神经网络模块
│ ├── char_rnn.py # 微型 Char-RNN
│ ├── train.py # 训练脚本
│ └── data/ # 数据持久化
│ ├── brain_state.json
│ ├── q_table.json
│ ├── memory.json
│ ├── personality.json
│ ├── corpus.txt # 训练语料
│ └── weights.npz # 训练好的权重
│
├── renderer/ # 渲染模块
│ ├── sprites.py # 矢量精灵绘制 + 叠加特效
│ └── renderer.py # 帧动画 + 对话气泡
│
├── desktop/ # 桌面集成模块
│ ├── pet_window.py # 透明穿透窗口 + 右键菜单
│ └── tray.py # 系统托盘
│
├── AIPet.spec # PyInstaller 打包配置
└── assets/ # 资源目录
八、技术栈总结
| 组件 | 技术 | 用途 |
|---|---|---|
| 游戏循环/渲染 | pygame-ce | 矢量绘图、帧动画 |
| 桌面窗口 | PyQt5 | 透明窗口、系统托盘、右键菜单 |
| 神经网络 | numpy | Char-RNN 训练与推理 |
| 行为决策 | Q-Learning | 状态-动作价值学习 |
| 数据格式 | JSON + NPZ | 配置/状态持久化 |
九、总结与展望
这个项目用纯Python实现了一个完整的AI桌面宠物系统,核心亮点在于:
- 零依赖AI —— RNN完全用NumPy手写,不依赖PyTorch/TensorFlow
- 零图片资源 —— 矢量风格绘图,全部用代码生成
- 零联网 —— 所有功能离线运行
- 可成长 —— Q-Learning让宠物越养越"懂你"
目前已经实现的扩展:
- 15种互动操作(含跳舞、讲故事、教本领等)
- 9种互动视觉特效
未来可以继续扩展的方向:
- 更多互动小游戏(接球、拼图)
- 多宠物同屏互动
- 声音反馈系统
- 自定义外观编辑器
项目完全开源,代码放在 GitHub。如果你也对桌面宠物或轻量AI感兴趣,欢迎Star和PR!
游戏源代码下载链接
游戏源码和游戏运行程序下载,可看公众号这篇文章
可以关注博主公众号 : 码来的小朋友
如果你觉得这篇文章对你有帮助,欢迎点赞、收藏、转发,让更多人看到用纯Python也能做出这么有趣的AI应用!
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)